📄 Vioptt: Violin Technique-Aware Transcription from Synthetic Data Augmentation
#音乐信息检索 #小提琴转录 #数据增强 #多任务学习 #领域适应
✅ 6.5/10 | 前50% | #音乐信息检索 | #数据增强 | #小提琴转录 #多任务学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Ting-Kang Wang (Sony Computer Science Laboratories, Inc., 国立台湾大学研究所)
- 通讯作者:未明确标注。从邮箱和贡献标注看,Ting-Kang Wang和Yueh-Po Peng可能共同负责。
- 作者列表:
- Ting-Kang Wang(Sony Computer Science Laboratories, Inc.;国立台湾大学研究所;中央研究院信息研究所)
- Yueh-Po Peng(伽玛之星原创内容中心;中央研究院信息研究所)
- Li Su(中央研究院信息研究所)
- Vincent K.M. Cheung(Sony Computer Science Laboratories, Inc.) 注:所有作者均标注了隶属于Sony CSL或台湾相关机构,且论文说明工作是在Sony CSL实习期间完成。
💡 毒舌点评
亮点:通过VST虚拟乐器(DAWDreamer + Synchron Solo Violin)自动合成带技巧标注的大规模数据集(MOSA-VPT),巧妙地绕开了需要专家标注的瓶颈,并证明了合成数据训练的模型能有效泛化到真实录音。短板:核心的“转录模块”基本是钢琴转录模型的直接移植,创新有限;整体模型架构(CRNN + 简单特征融合)相对传统,未探索更前沿的序列建模或注意力机制,限制了性能上限。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/y10ab1/VioPTT
- 模型权重:论文中未明确提及是否公开训练好的模型权重文件。仅提及“model and code are available”。
- 数据集:合成数据集MOSA-VPT已发布,提供DOI链接:https://doi.org/10.5281/zenodo.18295471
- Demo:论文中未提及在线演示。
- 复现材料:详细提供了训练步数、batch size、学习率、硬件环境、数据集划分方法等关键训练细节。
- 引用的开源项目:
- DAWDreamer:用于音频合成的Python框架。
- Synchron Solo Violin I:商业级虚拟乐器插件。
- mir_eval:用于音乐信息检索评估的Python库。
- 其他数据集:MOSA, URMP, Bach10, RWC。
📌 核心摘要
- 要解决什么问题:传统自动音乐转录(AMT)系统主要转录音高和时序,忽略了小提琴演奏中至关重要的演奏技巧(如拨弦、跳弓),而标注这些技巧需要昂贵的专业知识,导致大规模数据集稀缺。
- 方法核心是什么:提出VioPTT,一个轻量级级联模型,包含转录模块(预测音高、起始、偏移)和articulation模块(融合声学与转录特征,预测演奏技巧类别)。同时,利用DAWDreamer和虚拟乐器,从MIDI谱自动合成大规模、无需标注的“音符-技巧”对齐数据集MOSA-VPT。
- 与已有方法相比新在哪里:这是首个在统一框架中联合完成小提琴音符转录和演奏技巧预测的工作。核心创新在于数据合成流程,而非模型架构本身。该流程可泛化到其他支持技巧控制的虚拟乐器。
- 主要实验结果如何:
- 音符转录:在URMP数据集上,VioPTT(带增强)的Recall (83.6) 和 F1no (93.1) 达到最佳,整体性能与SOTA模型MUSC持平。在Bach10上,从钢琴预训练微调后性能最好(F1=71.5)。具体数据见下表。
- 技巧分类:在RWC数据集上,使用全部转录特征的VioPTT达到了77.22%的宏平均精度,远超基线MERTech(53.36%)。消融研究显示,不同技巧对音高、起始、力度等特征的依赖不同。
- 实际意义是什么:为音乐信息检索提供了更丰富、表达力更强的小提琴表演符号表示。合成数据集MOSA-VPT为研究社区提供了一个宝贵的资源,以推动无需大量人工标注的乐器表演分析研究。
- 主要局限性是什么:模型架构的创新性有限;所提出的合成数据流程可能引入与真实演奏的域偏移(UMAP可视化有所体现);研究仅限于四种特定技巧,未涵盖更复杂的技巧(如揉弦、颤音)。
实验结果表格: 表1:URMP和Bach10数据集上的音符转录性能对比
| 模型 | URMP | Bach10 | ||||||
|---|---|---|---|---|---|---|---|---|
| P | R | F1 | F1no | P | R | F1 | F1no | |
| Ours w/o aug | 83.4 | 81.2 | 82.2 | 92.8 | 66.7 | 71.3 | 68.9 | 79.0 |
| Ours w/ aug | 86.1 | 83.6 | 84.5 | 93.1 | 68.1 | 71.8 | 69.9 | 79.5 |
| Ours + FT w/o aug | 84.4 | 79.0 | 81.3 | 91.3 | 69.5 | 73.7 | 71.5 | 80.2 |
| Ours + FT w/ aug | 85.0 | 82.1 | 83.3 | 92.9 | 63.3 | 68.4 | 65.7 | 77.8 |
| MUSC [7] | 86.5 | 83.1 | 84.6 | 93.0 | 65.0 | 64.8 | 64.8 | 77.0 |
| MERTech [16] | 26.6 | 33.7 | 29.8 | 30.3 | 27.6 | 53.4 | 36.4 | 36.9 |
表2:RWC数据集上的技巧分类消融研究结果
| 模型配置 | Macro Acc (%) | Flageolet Acc (%) | Détaché Acc (%) | Pizzicato Acc (%) | Spiccato Acc (%) |
|---|---|---|---|---|---|
| Full ablation | 70.46 (± 2.57) | 86.44 (± 4.19) | 51.75 (± 9.97) | 57.06 (± 15.33) | 86.56 (± 2.55) |
| No ablation | 77.22 (± 6.35) | 71.89 (± 14.12) | 63.12 (± 12.59) | 88.80 (± 3.11) | 85.08 (± 4.87) |
| MERTech [16] | 53.36 ± (1.02) | 95.77 ± (2.23) | 58.80 ± (1.63) | 43.27 ± (1.19) | 15.61 ± (2.06) |
实验结果图表描述:
- 图2(混淆矩阵):展示了“无消融”模型在RWC数据集上的分类错误模式。détaché和spiccato之间存在较多的相互误判(尤其是détaché误判为spiccato),而pizzicato由于发声机制独特,误判率很低。
- 图3(UMAP可视化):在articulation模块的倒数第二层特征空间中,四种技巧的表征基本可分,但存在域偏移现象:合成数据训练的détaché簇在特征空间上更靠近flageolet,而真实的spiccato簇则更靠近pizzicato,表明合成数据与真实数据的表征存在差异。
🏗️ 模型架构
VioPTT采用级联(cascade)架构,由两个独立训练的模块组成:转录模块和articulation模块。
整体输入输出流程:
- 输入:单声道音频,转换为多尺度对数梅尔频谱图(STFT窗口长度{512, 768, 1024})。
- 转录模块处理频谱图,输出帧级别的音符激活、起始(onset)、偏移(offset)和力度(velocity)预测。
- 对于转录模块检测到的每个音符(通过onset激活提取),将其对应的声学特征和转录特征输入articulation模块。
- articulation模块为每个音符输出一个技巧类别标签(共5类:détaché, flageolet, spiccato, pizzicato, 无技巧)。
主要组件详解:
转录模块:直接采用并适配自Kong et al. [1]的高分辨率钢琴转录模型。
- 结构:每个输出头(onset, offset, velocity, frame)都由一个CRNN(4个卷积块 + 2层双向GRU)构成。最终通过全连接层和另一组2层双向GRU,输出88维(覆盖小提琴音域)的sigmoid激活值。
- 功能:执行核心的多任务帧级预测。论文中将此模块视为一个整体进行训练和微调。
- 设计动机:利用在大型钢琴数据集(MAESTRO)上预训练的模型架构和可能存在的权重,作为强大的特征提取和预测基础。
articulation(技巧分类)模块:设计用于融合声学特征和转录特征,进行音符级别的技巧分类。
- 声学特征编码器:由4个卷积块(通道数48, 64, 96, 128)加池化和Dropout构成,后接全局平均池化,投影为128维的声学嵌入向量。
- 转录特征编码器:将从转录模块得到的每个音符对应的onset, offset, frame, velocity特征向量,投影为另一个128维的嵌入向量。
- 融合与分类:将两个128维向量拼接,通过一个全连接层(融合模块),输出5个类别的logits。
- 设计动机:显式地融合时域/频域的声学信息(技巧影响音色)和高层音乐结构信息(技巧与音符时序强相关),以提升分类准确性。
模型架构图(图1):
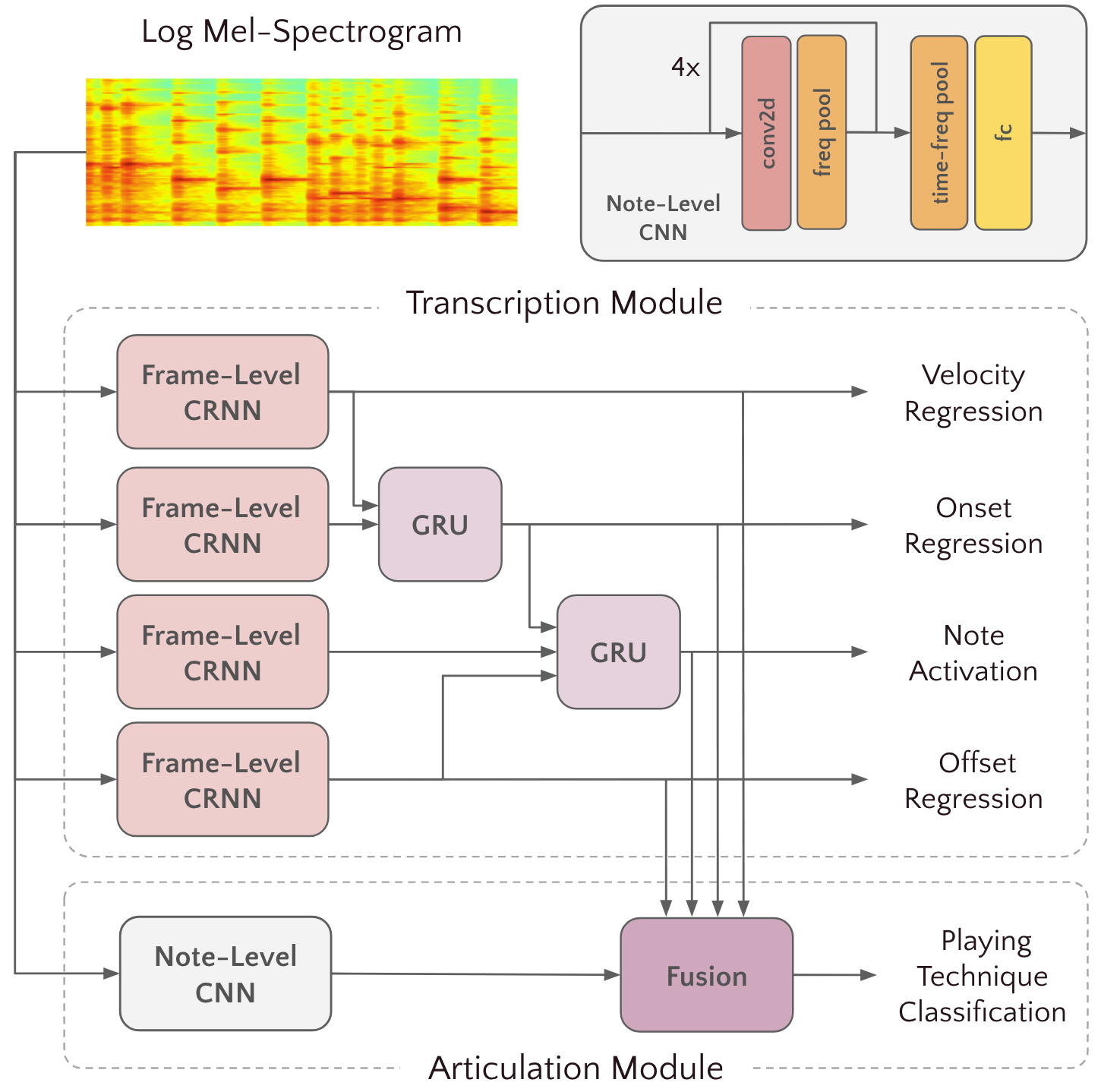 图示内容:左侧为多尺度梅尔频谱输入;中间上方为转录模块(CRNN),输出onset, offset, velocity, frame;下方为articulation模块,分别接收原始频谱(声学特征)和转录模块输出(转录特征),融合后输出技巧类别。
图示内容:左侧为多尺度梅尔频谱输入;中间上方为转录模块(CRNN),输出onset, offset, velocity, frame;下方为articulation模块,分别接收原始频谱(声学特征)和转录模块输出(转录特征),融合后输出技巧类别。
💡 核心创新点
- 合成数据集(MOSA-VPT):核心贡献。利用DAWDreamer和VST虚拟乐器(Synchron Solo Violin),通过自动控制key switches和CCs,从MIDI谱直接渲染出大规模(76小时)、自动对齐(音符-技巧)且无专家标注的训练数据。该方法成本低、可扩展。
- 统一框架:首次将小提琴的音符转录(音高/时序)和演奏技巧分类整合到一个系统中。articulation模块显式融合了来自转录模块的特征,实现了信息共享。
- 技巧感知转录:超越了传统AMT仅输出音符事件的范式,为每个音符附加了技巧标签,提供了更丰富、更具表现力的音乐符号表示,更贴近音乐家的实际需求。
- 跨域泛化能力验证:尽管模型完全在合成数据上训练技巧分类器,但在真实的、非合成的RWC数据集上取得了优异的分类效果,证明了合成数据作为代理标注的有效性。
🔬 细节详述
- 训练数据:
- 音符转录:核心训练集为MOSA(~19小时专业录制独奏)。使用Bach Partita No. 3第一乐章的不同演奏版本作为验证集以防止数据泄露。
- 技巧分类:使用合成数据集MOSA-VPT(76小时,平衡四种技巧)。
- 数据增强:
- 音高与时序增强:在训练音频上应用定制化效果链:音高偏移(±0.1半音)、增益提升(+5 dB)、两个随机带通滤波器、适度混响。
- 技巧合成:见上文创新点1。
- 损失函数:转录模块采用多任务损失:onset, offset, frame使用二元交叉熵(BCE),velocity使用均方误差(MSE),technique使用分类交叉熵(CE)。总损失为各项之和。
- 训练策略:
- 转录模块:训练10,000步,batch size=5,输入10秒片段。使用余弦退火学习率调度器,初始学习率
5e-4。 - articulation模块:单独训练1,000步,batch size=128,输入2秒单音片段。使用相同的优化器和学习率。
- 转录模块:训练10,000步,batch size=5,输入10秒片段。使用余弦退火学习率调度器,初始学习率
- 关键超参数:梅尔频谱图bins=229,跳数=160。转录模块为88维输出(对应钢琴音域,适用于小提琴)。articulation模块投影维度为128。
- 训练硬件:单张NVIDIA RTX 4090 GPU。
- 推理细节:未明确说明推理时的解码策略(如阈值处理)。技巧分类是在音符级别进行,依赖于转录模块首先检测到音符。
- 评估指标:音符转录使用P, R, F1, F1no(mir_eval库);技巧分类使用宏平均准确率和每类准确率。基准数据集为URMP, Bach10, RWC。
📊 实验结果
主要结果已在“核心摘要”中以表格形式列出。以下为详细分析:
音符转录性能(表1):
- 在URMP上,本文最佳模型(Ours w/ aug)在Recall和F1no上达到SOTA,整体F1(84.5)与MUSC(84.6)几乎持平。
- 在Bach10上,钢琴预训练微调(Ours + FT w/o aug)性能最好,表明在数据量较小的情况下,迁移学习仍有帮助。
- 消融显示,数据增强(aug)普遍有益,而钢琴预训练(FT)的效果则因数据集而异。
技巧分类性能(表2及图2、图3):
- 无消融的VioPTT(77.22%)显著优于基线MERTech(53.36%),证明了融合转录特征的有效性。
- 消融研究揭示了不同技巧的特征依赖:
- Pizzicato:强烈依赖力度(velocity)特征,移除后准确率骤降至0.16%。
- Spiccato:依赖多种时序特征(onset, offset),移除任一都会导致显著性能下降。
- Flageolet:主要依赖谐波特征(声学编码器),MERTech在此类上表现更优(95.77%)。
- Détaché:移除帧(frame)特征反而提升准确率,表明二元帧激活可能引入噪声。
- 混淆矩阵(图2)显示détaché和spiccato(均为短弓技巧)易混淆。
- UMAP可视化(图3)显示四种技巧特征基本可分,但存在合成-真实域间的偏移。
⚖️ 评分理由
学术质量:4.5/7
- 创新性:主要创新在于数据合成流程和统一框架的概念,但核心模型架构(特别是转录模块)复用性强,原创性有限。
- 技术正确性:方法实现严谨,实验设计合理(如防止数据泄露的验证集划分、三折交叉验证),多任务训练和特征融合的动机清晰。
- 实验充分性:实验比较全面,包含了与SOTA的对比、不同训练条件的消融、以及对技巧分类的特征重要性分析。使用了多个公开标准数据集。
- 证据可信度:结果可复现性强,提供了详细实现细节和开源链接。结果合理,与相关工作(如技巧的声学特性)一致。
选题价值:1.5/2
- 前沿性:将音乐转录从“音符”扩展到“技巧”是音乐信息检索领域的前沿方向。
- 潜在影响与应用:对音乐教育、乐谱自动生成、音乐表演分析有实用价值。合成数据集的发布能降低该领域的研究门槛。
- 读者相关性:对音频/音乐领域的研究者,尤其是关注乐器分析和细粒度分类的学者,有较高参考价值。但对于更广泛的AI社区,问题较为垂直。
开源与复现加成:+0.5/1
- 代码、合成数据集均开源,训练超参数、评估指标描述清晰,为复现提供了良好基础。论文中引用了多个开源项目(DAWDreamer, mir_eval等)。