📄 Vib2Sound: Separation Of Multimodal Sound Sources
#语音分离 #生物声学 #麦克风阵列 #信号处理
✅ 6.5/10 | 前50% | #语音分离 | #麦克风阵列 | #生物声学 #信号处理
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Mai Akahoshi (ETH Zurich and University of Zurich, Institute of Neuroinformatics)
- 通讯作者:Richard H. R. Hahnloser (makahoshi@ethz.ch, {yuhang, zaia, rich}@ini.ethz.ch, 从邮箱和星号标注判断,Hahnloser 和 Zai 为共同资深作者)
- 作者列表:Mai Akahoshi (ETH Zurich and University of Zurich, Institute of Neuroinformatics & Neuroscience Center Zurich), Yuhang Wang (同上), Longbiao Cheng (ETH Zurich and University of Zurich, Institute of Neuroinformatics), Anja T. Zai (同上), Richard H. R. Hahnloser (同上)
💡 毒舌点评
亮点:论文巧妙地将动物佩戴的加速度计信号作为个体身份“锚点”,解决了同种动物发声高度相似导致麦克风阵列分离失效的核心难题,在生物声学领域思路清晰且有效。短板:模型架构是对现有VoiceFilter框架的简单适配与修改,创新深度有限;研究场景(斑胸草雀)和数据集较为垂直,对主流音频/语音处理社区的普适性启发可能不足。
🔗 开源详情
- 代码:提供代码仓库链接 (
https://gitlab.switch.ch/hahnloser-songbird/birdpark/vib2sound)。 - 模型权重:论文未明确提及是否公开预训练模型权重。
- 数据集:论文中使用的干净发声数据集已公开,提供DOI链接 (
https://doi.org/10.3929/ethz-c-000788603)。 - Demo:论文中未提及在线演示。
- 复现材料:提供了详细的训练参数(优化器、学习率、batch size、训练步数)和模型架构描述(CNN层数、LSTM等),有利于复现。
- 引用的开源项目:论文依赖/提到了以下开源项目:WhisperSeg (用于发声检测)、Parselmouth/Praat (用于音高分析)、VoiceFilter (模型基础)、TF-GridNet (对比基线)。
📌 核心摘要
- 问题:在研究动物社交行为时,从复杂环境(多只动物同时发声、背景噪声)中分离出个体的独立发声非常困难。传统麦克风阵列在分离高度相似的同种动物发声时效果有限。
- 方法:提出Vib2Sound神经网络系统,它以多通道麦克风混合音频和对应个体佩戴的加速度计信号作为输入。加速度计信号提供了与发声相关的身体振动,作为分离个体发声的关键线索。模型基于VoiceFilter架构,用加速度计频谱图替代了说话人嵌入,并适配了多通道音频输入。
- 创新:核心创新在于首次系统性地论证并利用穿戴式加速度计作为“接触传感”线索来指导麦克风音频中的声源分离,尤其适用于传统声学方法难以处理的高相似度声源场景。
- 实验:在斑胸草雀数据集BirdPark上进行评估。在人工混合数据上,Vib2Sound在欧氏距离等指标上显著优于最强基线TF-GridNet(如在Dataset2上,欧氏距离从1.032降至0.527)。消融实验证明加速度计信号贡献巨大,而麦克风通道数影响较小。在196个真实重叠叫声的实验中,分离后叫声的音高分布与干净叫声无统计学差异(p=0.283),证明其有效性。
- 意义:为动物行为生态学和生物声学研究提供了一个有力的分析工具,能够从复杂的社交录音中提取干净的个体发声,促进对动物交流的深入理解。
- 局限:严重依赖穿戴式传感器(加速度计),这在野外大规模应用或对无法佩戴设备的动物上存在限制。模型针对特定鸟类数据训练,其跨物种泛化能力未被验证。
🏗️ 模型架构
Vib2Sound是一个端到端的神经网络声源分离模型,其核心目标是:给定包含多个动物发声的混合多通道麦克风信号(Mic)以及每个目标动物佩戴的加速度计信号(Acc),输出分离后的干净发声频谱。
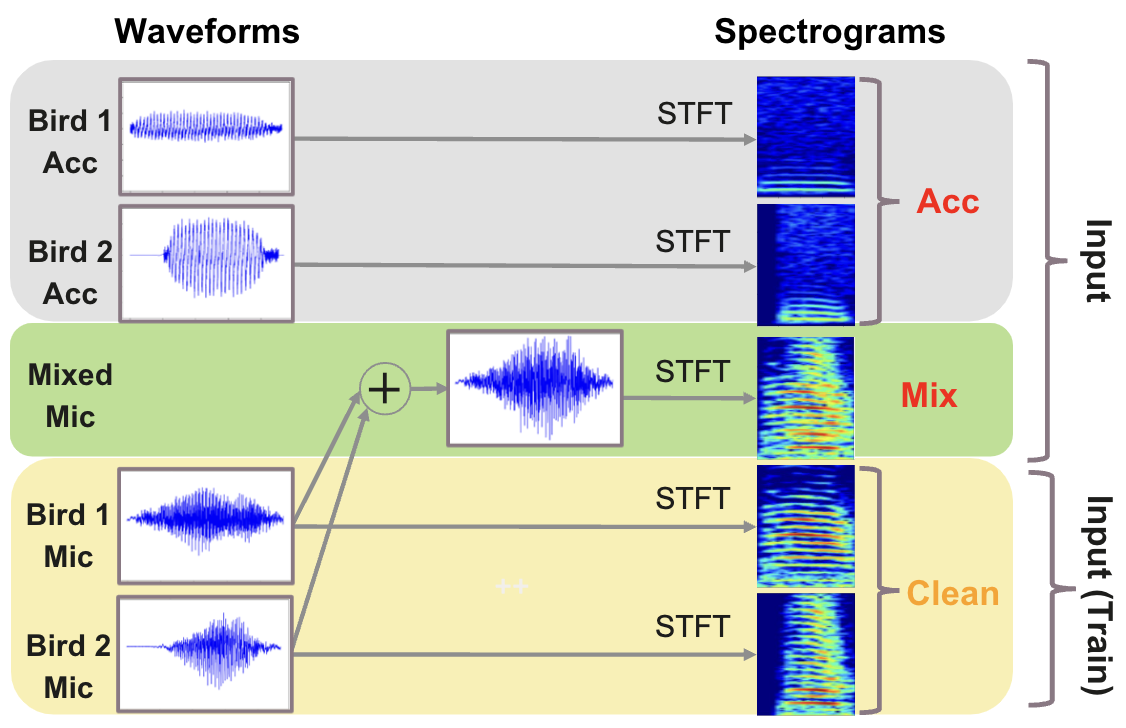 图2:Vib2Sound 模型结构。图中清晰展示了两条输入流:混合音频流(多通道麦克风)和加速度计流。音频流经过CNN处理,加速度计频谱图与其拼接后送入LSTM,最终由全连接层生成掩码,用于从原始混合频谱中估计出两个分离的声源频谱。
图2:Vib2Sound 模型结构。图中清晰展示了两条输入流:混合音频流(多通道麦克风)和加速度计流。音频流经过CNN处理,加速度计频谱图与其拼接后送入LSTM,最终由全连接层生成掩码,用于从原始混合频谱中估计出两个分离的声源频谱。
架构流程详解:
- 输入:两个输入源:(1) 混合音频流:来自多个墙壁麦克风的多通道音频信号。(2) 加速度计流:来自两只鸟各自佩戴的加速度计信号,捕捉发声时的身体振动。
- 特征提取:
- 混合音频流:对所有通道的音频信号进行短时傅里叶变换(STFT),得到复数谱(幅度谱和相位谱)。将所有通道的幅度谱和相位谱输入一个8层的卷积神经网络(CNN),用于提取具有空间信息的声学特征。
- 加速度计流:同样进行STFT,提取每只鸟的加速度计信号的幅度谱。
- 特征融合:将CNN提取的音频特征与两只鸟各自的加速度计幅度谱在特征维度上拼接。这一步是关键,它将“个体特异性振动线索”与“混合声学场景特征”结合。
- 序列建模:将融合后的特征输入一个单层长短期记忆网络(LSTM),用于捕捉时间上的依赖关系。
- 掩码生成:LSTM的输出连接一个两层的全连接(FC)块,最终输出两个软掩码(Soft Mask)。这两个掩码分别对应两只鸟的声源。
- 声源估计与波形合成:将生成的软掩码应用于原始混合信号第一个麦克风通道的幅度谱,分别预测出两只鸟的干净发声幅度谱。最后,利用原始混合信号的相位,通过逆短时傅里叶变换(iSTFT)将估计的幅度谱转换为时域波形。
- 训练目标:模型通过最小化预测的源频谱图与真实干净源频谱图之间的均方误差(MSE)来进行端到端训练。
关键设计选择:
- 用加速度计代替说话人嵌入:这是与VoiceFilter的核心区别,利用了生物信号而非纯声学信号作为个体标识线索。
- 多通道输入但最终使用单通道掩码:虽然输入多通道信息以丰富CNN特征,但掩码最终应用于单通道频谱进行分离,简化了输出并降低了对多通道麦克风同步的严格要求。
💡 核心创新点
- 引入穿戴式加速度计作为分离线索:针对生物声学中同种动物发声高度相似的难题,创新性地利用动物佩戴的加速度计所捕捉的发声相关身体振动,作为区分不同个体的可靠“指纹”,解决了传统麦克风阵列在声学特征相似时分离失效的问题。
- 多模态特征融合框架:提出将反映发声个体身份的加速度计信号与反映声场空间信息的多通道麦克风信号进行有效融合。通过在CNN特征后拼接加速度计谱图的方式,让模型同时利用声学线索和物理振动线索。
- 针对生物声学场景的模型适配与验证:对已有的语音分离框架(VoiceFilter)进行针对性改造,使其适用于动物发声场景。并在斑胸草雀数据集上系统验证了接触传感(加速度计)相比纯远场麦克风方法在分离性能上的巨大优势,并将模型扩展到3-4只鸟的群体分离场景。
🔬 细节详述
- 训练数据:
- 名称/来源:数据集构建自BirdPark系统录制的斑胸草雀发声。训练用的干净发声数据公开提供(链接见论文脚注)。
- 规模:Dataset1(14只鸟)包含8894个训练发声;Dataset2(6只鸟)包含8046个训练发声。每个鸟的发声被划分为训练、验证(4.5%)和评估(10%)集。
- 预处理:使用WhisperSeg在加速度计频谱图上自动检测发声段,并人工筛选非重叠的干净发声用于构建训练对。
- 数据增强:通过人工配对混合干净发声来创建训练样本。较短的发声在较长的发声时间跨度内随机对齐,模拟真实的发声时序变化。
- 损失函数:
- 名称:均方误差(MSE)。
- 作用:计算预测的源频谱图与真实干净源频谱图在所有时间频率点上的平均平方差。损失函数是分离出的两个源频谱的MSE之和。
- 训练策略:
- 学习率:0.001
- 优化器:Adam
- Batch size:4
- 训练步数:200, 000步
- 调度策略:论文未提及学习率调度或其他高级训练策略。
- 关键超参数:
- STFT参数:窗长384采样点,跳步96采样点。
- 预处理:对加速度计信号应用200 Hz高通滤波以去除无线电传输低频噪声。
- 模型规模:8层CNN,1层LSTM,2层FC。具体维度未说明。计算量为1.54 GMACs (5通道输入,200ms),参数量为7.99M。
- 训练硬件:论文中未提及训练所用的GPU/TPU型号、数量及训练时长。
- 推理细节:推理时直接输入多通道麦克风混合音频和对应加速度计信号,模型输出掩码并生成分离波形。未提及解码策略、温度或流式设置等。
- 正则化:论文中未提及使用Dropout、权重衰减等具体正则化技巧。
📊 实验结果
论文在人工合成混合数据和真实世界混合数据上进行了评估,主要指标是预测频谱与干净频谱在每个时间频点上的平均距离(欧氏距离、余弦距离、Spearman距离)。距离越小,性能越好。
- 人工混合数据性能对比(关键表格)
| 模型/方法 | 数据集 | 欧氏距离 ↓ | 余弦距离 ↓ | Spearman距离 ↓ | MACs (G) | Params (M) |
|---|---|---|---|---|---|---|
| Mixture (原始混合) | Dataset1 | 1.665 | 0.0450 | 0.212 | - | - |
| Dataset2 | 1.843 | 0.0574 | 0.215 | - | - | |
| TF-GridNet (200k steps) | Dataset1 | 1.269 | 0.0512 | 0.269 | 38.68 | 8.32 |
| Dataset2 | 1.238 | 0.0564 | 0.236 | 38.68 | 8.32 | |
| TF-GridNet (800k steps) | Dataset1 | 1.050 | 0.0415 | 0.221 | 38.68 | 8.32 |
| Dataset2 | 1.032 | 0.0470 | 0.209 | 38.68 | 8.32 | |
| audio-only single-ch Vib2Sound | Dataset1 | 1.377 | 0.0417 | 0.196 | 1.52 | 14.19 |
| Dataset2 | 1.502 | 0.0522 | 0.192 | 1.52 | 14.19 | |
| audio-only multi-ch Vib2Sound | Dataset1 | 1.237 | 0.0396 | 0.189 | 1.52 | 14.19 |
| Dataset2 | 1.197 | 0.0470 | 0.182 | 1.52 | 14.19 | |
| single-channel Vib2Sound | Dataset1 | 0.642 | 0.0249 | 0.147 | 1.53 | 7.98 |
| Dataset2 | 0.534 | 0.0229 | 0.126 | 1.53 | 7.98 | |
| multi-channel Vib2Sound | Dataset1 | 0.637 | 0.0249 | 0.146 | 1.54 | 7.99 |
| Dataset2 | 0.527 | 0.0228 | 0.125 | 1.54 | 7.99 | |
| multi-ch Vib2Sound (3 birds) | Dataset1 | 0.701 | 0.0293 | 0.176 | 2.18 | 7.99 |
| Dataset2 | 0.577 | 0.0277 | 0.148 | 2.18 | 7.99 | |
| multi-ch Vib2Sound (4 birds) | Dataset1 | 0.706 | 0.0325 | 0.194 | 2.31 | 7.99 |
| Dataset2 | 0.572 | 0.0305 | 0.163 | 2.31 | 7.99 |
表1:Vib2Sound、消融实验和基线模型的性能对比。最佳性能以加粗表示。
主要结论:
- Vib2Sound大幅超越基线:完整的多通道Vib2Sound在所有指标上显著优于最强基线TF-GridNet(即使后者训练了更久)。例如在Dataset2上,欧氏距离从TF-GridNet的1.032降低到Vib2Sound的0.527。
- 加速度计信号至关重要:移除加速度计信号(audio-only模型)导致性能严重下降(如Dataset2欧氏距离从0.527升至1.197)。而移除多通道信息(single-channel Vib2Sound)性能几乎不变。
- 可扩展到3-4只鸟:分离3只或4只鸟混合信号时,性能相比2只鸟场景仅有轻微下降,且仍远优于麦克风-only基线。
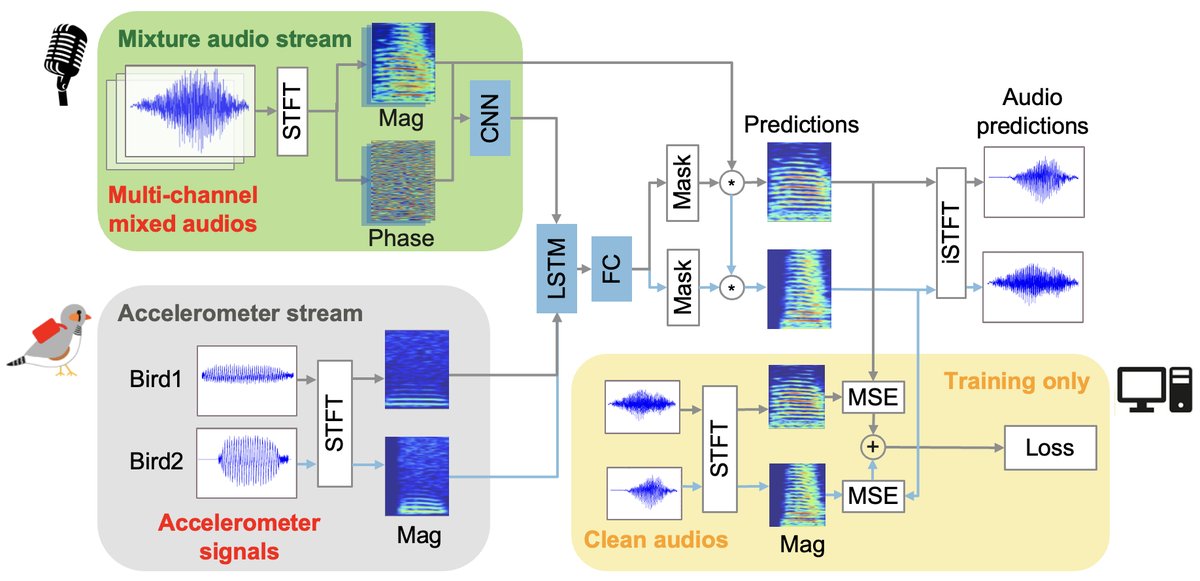 图4:Vib2Sound分离一个人工混合声的示例。从左到右依次为:混合的麦克风输入、对应的加速度计信号、模型预测结果、真实干净信号、预测与真实值的绝对差值。预测频谱与真实值高度吻合,残差极小。
图4:Vib2Sound分离一个人工混合声的示例。从左到右依次为:混合的麦克风输入、对应的加速度计信号、模型预测结果、真实干净信号、预测与真实值的绝对差值。预测频谱与真实值高度吻合,残差极小。
- 真实世界混合数据评估
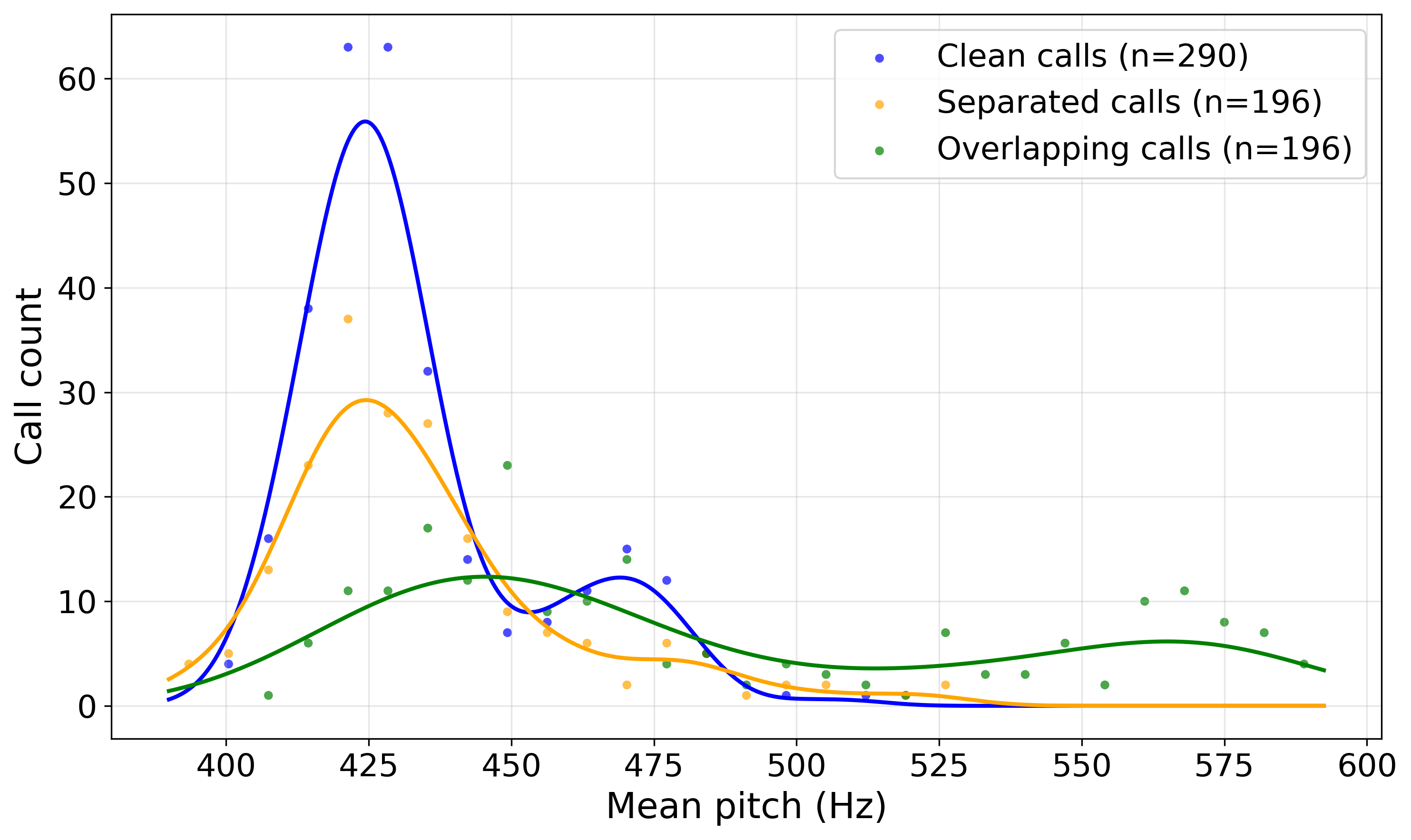 图5:干净叫声、重叠叫声以及Vib2Sound分离后叫声的平均音高分布(核密度估计图)。
图5:干净叫声、重叠叫声以及Vib2Sound分离后叫声的平均音高分布(核密度估计图)。
- 评估对象:196个自然发生的重叠叫声(同一只鸟的一种谐波叫声)。
- 评估方法:比较分离后叫声的音高分布与该鸟290个干净叫声的音高分布是否一致。
- 结果:Kolmogorov-Smirnov检验显示,分离后的叫声音高分布与干净叫声无显著差异 (p = 0.283),而原始重叠叫声的分布则有显著差异 (p < 0.001)。
- 结论:Vib2Sound能有效分离真实重叠叫声,并保持关键的声学特征(如音高),分离结果可用于下游分析。
⚖️ 评分理由
- 学术质量:5.5/7 - 论文问题明确,方法设计合理,实验对比充分(包含多基线、消融、多场景、真实数据验证)。创新性在于将穿戴式传感器线索引入分离任务并取得显著效果,但技术路线(修改现有模型框架)的突破性一般。
- 选题价值:1.0/2 - 该研究为动物行为学和生物声学领域提供了一个切实有用的工具,具有明确的应用价值。然而,该方向相对垂直小众,对更广泛的音频/语音处理社区(如智能设备、会议记录、助听器)的直接启示和影响力有限。
- 开源与复现加成:0.5/1 - 论文提供了完整的代码仓库、数据集链接、模型参数量与计算量,以及关键的训练超参数(优化器、学习率、步数),复现门槛较低。