📄 Via Score to Performance: Efficient Human-Controllable Long Song Generation with Bar-Level Symbolic Notation
#音乐生成 #自回归模型 #音频生成 #开源工具
✅ 7.5/10 | 前25% | #音乐生成 | #自回归模型 | #音频生成 #开源工具
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Tongxi Wang(Southeast University, 中国)
- 通讯作者:Junlang Qian(Nanyang Technological University, 新加坡)
- 作者列表:Tongxi Wang(Southeast University), Yang Yu(Southeast University), Qing Wang(Southeast University), Junlang Qian(Nanyang Technological University)
💡 毒舌点评
这篇论文的“先乐谱后表演”范式巧妙地将复杂音频生成问题解耦为可解释的符号生成和相对成熟的音频渲染问题,在可控性和效率上取得了显著进步,是思路清晰的“曲线救国”方案。然而,其“演奏”阶段严重依赖商用歌声合成软件VOCALOID和通用MIDI合成器FluidSynth,这使得最终音频质量的上限被锁定在这些工具的能力上,论文的“端到端”生成能力并非完全自包含,这在一定程度上削弱了其作为完全自主生成系统的创新性说服力。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/WtxwNs/BACH。代码已开源。
- 模型权重:论文中未提及公开BACH模型的预训练权重。
- 数据集:论文提及所用数据集将在论文发表后开源,但当前未提供获取方式或详细说明。
- Demo:论文中未提及在线演示链接。
- 复现材料:提供了代码仓库,包含示例。但完整的训练细节、配置文件、检查点未在论文中提供,需查阅仓库。
- 论文中引用的开源项目:
- Qwen3.0(用于歌词生成)
- FluidSynth(用于MIDI合成)
- ABC记谱法相关工具
- YuE等基线模型(用于对比)
- 总结:代码开源是主要亮点,但完整的模型复现(尤其是获得相似性能)可能因缺乏预训练权重、具体训练参数以及依赖商业VOCALOID而存在障碍。
📌 核心摘要
- 问题:现有基于音频的歌曲生成方法存在可控性差、可解释性弱、计算开销大的问题。将歌曲生成视为同时学习音乐理论与演奏的“即兴表演”,任务过于复杂。
- 方法核心:提出“先作曲后演奏”的新范式和BACH(Bar-level AI Composing Helper)框架。核心是使用小节(bar)作为语义单元进行符号乐谱生成,再将生成的乐谱渲染为音频。
- 创新点:首次将小节级符号乐谱生成引入歌曲生成;提出小节流分块(bar-stream patching) 和双流预测(Dual-NTP) 方法,分别处理人声与伴奏;引入链式乐谱(Chain-of-Score) 条件化以保持长程结构一致性。
- 实验结果:
- 自动评估(表1):BACH在多个指标上达到SOTA,尤其是内容感知指标(CE、CU)和音频-文本对齐指标(CLaMP3)。其KL散度显著优于商业系统(如0.391 vs Suno的0.620)。
- 人类评估(图4):BACH在音乐性上超越所有开源基线(YuE、YuE-light等),并与Udio有竞争力,略逊于Suno。在可控性(图5)上,其节拍/节奏和人声伴奏平衡表现突出。
- 效率:在RTX 4090上生成3分钟歌曲仅需约5分钟,远快于YuE等模型。
- 实际意义:提供了一种高效、可控、可解释的AI歌曲生成路径,生成的乐谱可被人直接阅读和编辑,极大促进了人机协作创作。代码开源有助于推动该方向研究。
- 主要局限性:最终音频渲染质量受限于外部工具(VOCALOID, FluidSynth),非端到端的纯AI生成;在风格和情感控制等可控性维度上仍有提升空间;论文未公开模型权重和完整训练细节。
🏗️ 模型架构
BACH是一个三阶段的系统流水线:
- 第一阶段:歌词与标签生成。接收用户简要提示(如“写一首关于爱情的流行歌曲”),使用一个大型语言模型(文中提到Qwen3.0)解析生成带有结构标签(如intro, verse, chorus)和风格标签的多语言歌词。
- 第二阶段:符号乐谱生成(BACH核心模块)。接收第一阶段输出的歌词和标签,生成对应的小节级ABC记谱法乐谱。该模块采用嵌套的双层解码器架构:
- 补丁级解码器(Patch-level Decoder):将每个小节(划分为16个字符的补丁)总结为一个上下文状态。
- 字符级解码器(Character-level Decoder):在交叉注意力机制下,将每个补丁状态展开为具体的ABC字符。
- 关键设计:采用小节级分词,将音乐按小节分割并固定为16字符补丁,提升音乐结构感知。采用双流预测(Dual-NTP),在每个时间步(小节补丁索引)同时预测一对人声token和伴奏token,建模联合概率
p(v_t, a_t | v_{<t}, a_{<t})。训练时使用教师强制,推理时自回归生成。通过链式乐谱(Chain-of-Score) 格式将指令、标签、歌词和各分段(包含<SOA>,<EOA>标记的音频token序列)串联成一个序列,以保持长程结构一致性。
- 第三阶段:音频渲染与混合。
- 伴奏:将ABC乐谱转换为MIDI文件,然后使用FluidSynth合成音频。
- 人声:使用VOCALOID软件将乐谱和歌词合成为歌声。
- 混合:将两轨音频混合成最终歌曲。
 图1:展示了传统音频直接生成(即兴表演)与BACH“先作曲后演奏”方法的对比。后者生成可编辑的多轨乐谱,再分别渲染。
图1:展示了传统音频直接生成(即兴表演)与BACH“先作曲后演奏”方法的对比。后者生成可编辑的多轨乐谱,再分别渲染。
 图2:展示了事件级(左)和小节级(右)记谱方式的区别,强调小节级排列更符合音乐理论,听感更和谐。
图2:展示了事件级(左)和小节级(右)记谱方式的区别,强调小节级排列更符合音乐理论,听感更和谐。
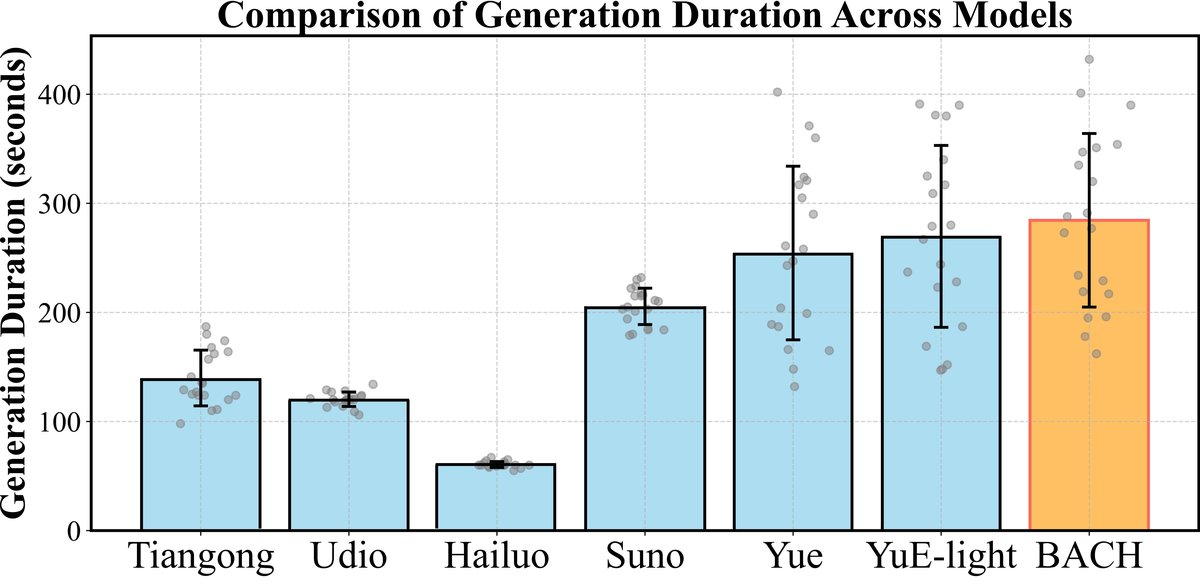 图3:详细展示了BACH的生成序列格式。模型基于指令、标签、歌词,结合Dual-NTP和Chain-of-Score方法,生成包含
图3:详细展示了BACH的生成序列格式。模型基于指令、标签、歌词,结合Dual-NTP和Chain-of-Score方法,生成包含<SOA>, <EOA>标记的音频token序列。
💡 核心创新点
“先作曲后演奏”的歌曲生成新范式:
- 局限:现有方法将歌曲生成视为一步到位的音频合成,任务复杂,可控性和可解释性差。
- 创新与作用:将过程解耦为符号乐谱生成(作曲)和音频渲染(演奏)。乐谱作为中间表示,维度更低、结构更清晰,便于模型学习音乐理论,也允许用户直接编辑。
- 收益:显著提升了生成过程的可解释性、可控性,并大幅降低了计算成本。
小节级符号表示与建模:
- 局限:以往符号化方法多采用事件级(note-level)表示,忽略了小节等高层组织结构,影响音乐连贯性。
- 创新与作用:使用小节作为基本语义单元,并通过小节流分块(bar-stream patching)将其固定长度token化。这自然包含了节奏、节拍、和声框架。
- 收益:生成的音乐结构更稳定,多声部协作更好,模型学习效率更高。
双流预测(Dual-NTP):
- 局限:传统自回归生成是单流序列,难以明确区分和建模人声与伴奏的互动与独立性。
- 创新与作用:在每个预测步同时输出人声和伴奏两个token,形成联合概率分解。这允许对两部分进行独立建模和后处理。
- 收益:更好地捕捉人声与伴奏的细微差别和平衡关系,尤其在配器复杂的段落。提升了可控性和后期制作灵活性。
链式乐谱(Chain-of-Score)条件化:
- 局限:现有音乐生成模型在长序列上容易出现结构退化,难以维持分钟级的连贯性。
- 创新与作用:借鉴LLM的Chain-of-Thought思想,将带有结构标签、歌词和对应音频片段的分段信息,以固定格式串联成训练序列,显式绑定音乐结构。
- 收益:增强了模型对歌曲宏观结构的保持能力,是生成高质量长歌曲的关键。
🔬 细节详述
- 训练数据:论文提及使用公开音乐语料、授权人声数据以及一个合成子集。总计包含约1B条件人声token,约10B无条件音乐token(混合与分轨),以及2B链式乐谱音乐token。预处理后的混合比例为条件:无条件=3:1,音乐:语音=10:1。数据集名称未说明,论文称将在发表后开源。
- 损失函数:BACH模型训练使用带平衡的交叉熵损失(balanced cross-entropy losses),针对补丁级和字符级解码器。具体权重未说明。
- 训练策略:采用多任务学习加多阶段训练(Multitask Learning plus Multiphase Training)。具体学习率、warmup、batch size、优化器、训练步数/轮数、调度策略均未说明。
- 关键超参数:模型名称为BACH-1B,暗示参数规模约为10亿,但论文未明确给出具体参数量。其他如层数、隐藏维度、码本大小(ABC字符集)等未说明。
- 训练硬件:未说明。
- 推理细节:
- 采用强制解码(forced decoding),限制token范围在音频域内,直到模型预测出
<EOA>。 - 生成过程是逐小节补丁自回归进行的。
- 最终音频渲染使用FluidSynth(伴奏)和VOCALOID(人声)。VOCALOID的具体版本、音色库、调优参数未说明。
- 采用强制解码(forced decoding),限制token范围在音频域内,直到模型预测出
- 正则化或稳定训练技巧:未明确说明。
📊 实验结果
主要Benchmark与对比:
- 基线模型:包括多个闭源商业系统(Suno, Udio, Hailuo, Tiangong),开源基线(YuE, YuE-light, SongComposer)。
- 评估指标:
- 分布匹配:KL散度(↓), FAD(↓)。
- 内容感知:CE(↑), CU(↑), PC(↑), PQ(↑)(来自Audio-aesthetics模型)。
- 对齐:CLAP(↑), CLaMP3(↑)。
- 其他:歌曲时长, 人声音域。
关键定量结果(表1):
| Model | Distribution Match | Content Based | Alignment | Overall |
|---|---|---|---|---|
| KL ↓ | FAD ↓ | CE ↑ | CU ↑ | |
| SongComposer | – | – | 6.964 | 7.329 |
| Suno | 0.620 | 1.544 | 7.474 | 7.813 |
| Tiangong | 0.708 | 2.544 | 7.421 | 7.766 |
| Udio | 0.503 | 1.222 | 7.112 | 7.520 |
| Hailuo | 0.756 | 2.080 | 7.350 | 7.737 |
| YuE | 0.372 | 1.624 | 7.115 | 7.543 |
| YuE-light | 0.423 | 1.604 | 7.097 | 7.333 |
| BACH | 0.391 | 1.526 | 7.323 | 7.976 |
| 关键结论:BACH在KL(0.391, 仅次于YuE的0.372), CE, CU, CLaMP3(0.263)上取得最佳或并列最佳,并在综合得分(Overall)上以0.71分显著领先所有基线。 |
人类评估结果(图4, 图5):
- 音乐性A/B测试(图4):热图显示BACH对战多数模型的胜率超过50%,尤其对比Hailuo, Tiangong, YuE-light有显著优势;对比Suno略处下风,但胜率仍在50%附近,表明具有竞争力。
- 可控性维度分析(图5):雷达图显示BACH在“节拍/节奏”和“人声与伴奏平衡”上表现突出,但在“风格”和“情感”上相对较弱。
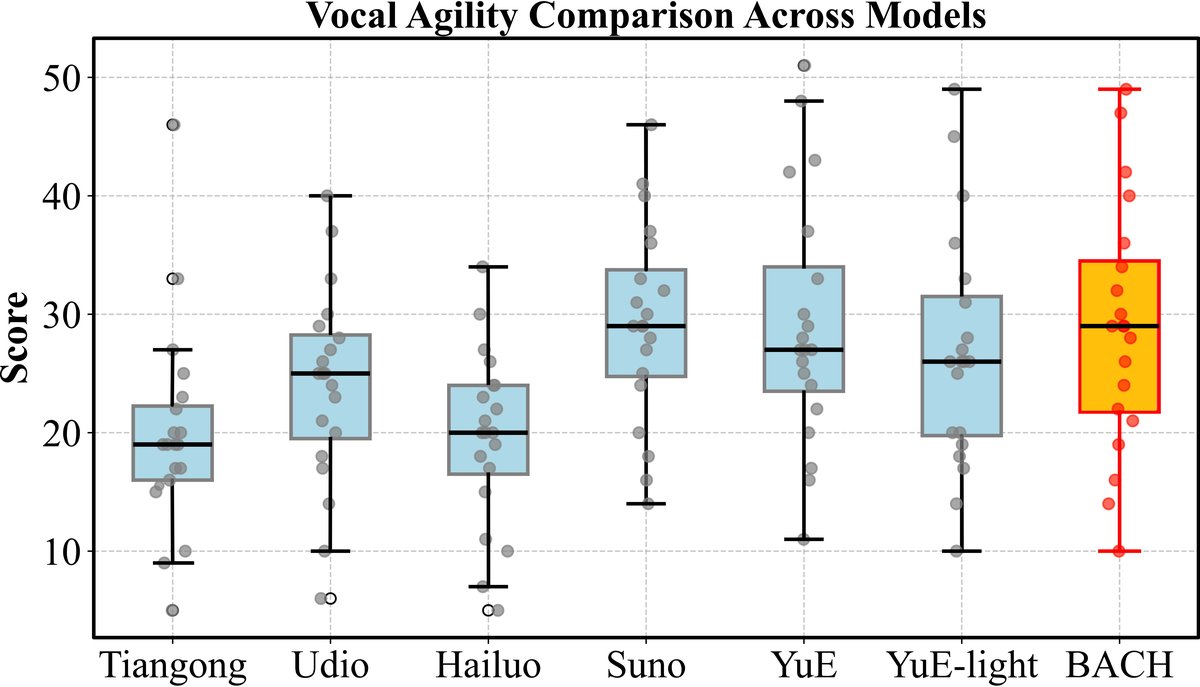 图4:A/B测试胜率热图。BACH(左侧)对阵其他模型(上方)的胜率由颜色和数字表示。红色框突出了BACH的胜率,表明其优于多数基线。
图4:A/B测试胜率热图。BACH(左侧)对阵其他模型(上方)的胜率由颜色和数字表示。红色框突出了BACH的胜率,表明其优于多数基线。
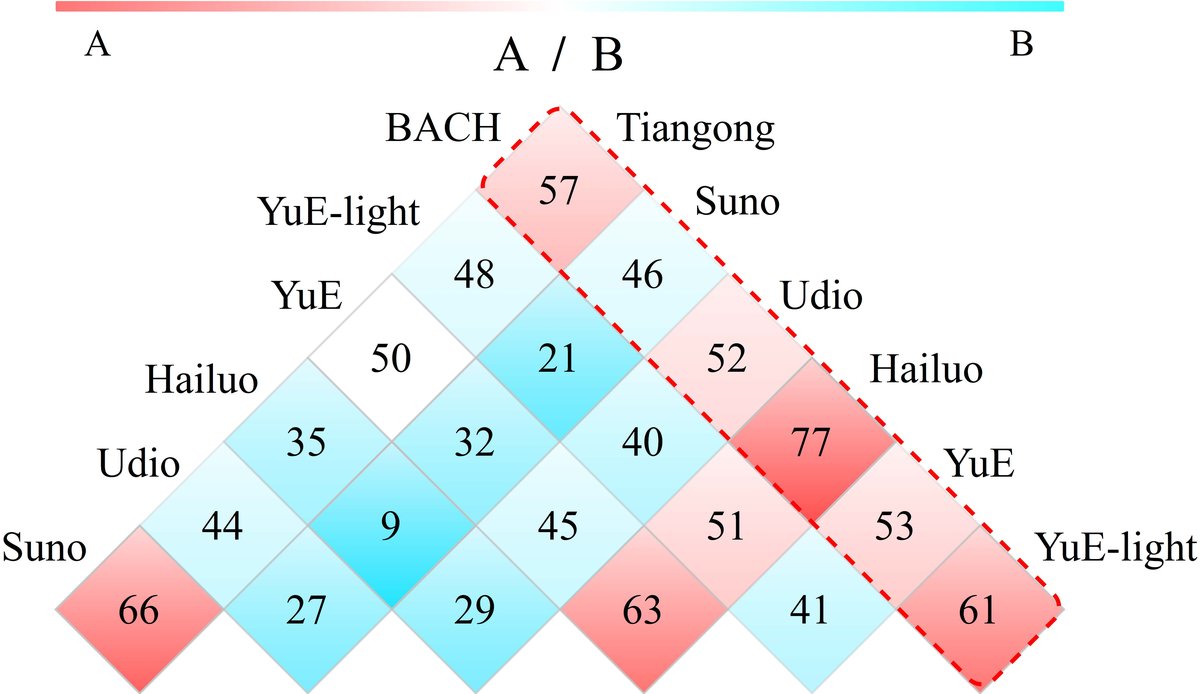 图5:雷达图对比了不同模型在多个音乐质量和可控性维度上的表现。BACH(红色线)在伴奏、人声匹配、节拍/节奏等方面表现突出。
图5:雷达图对比了不同模型在多个音乐质量和可控性维度上的表现。BACH(红色线)在伴奏、人声匹配、节拍/节奏等方面表现突出。
效率与生成能力:
- 时长:BACH生成歌曲的平均时长和最大时长均优于其他模型(图6, 描述见文)。
- 人声音域:BACH的人声音域范围(图7, 描述见文)与最强的商业系统Suno相当。
- 速度:在单张RTX 4090 GPU上,生成一首3分钟歌曲约需5分钟。作为对比,YuE生成30秒片段就需要约360秒且需80GB以上显��。
与最强基线对比:BACH在综合得分上大幅超越所有基线(包括Suno的0.41),在多个单项指标上领先或持平。在人类音乐性评估上,与Suno的差距较小,但已超越所有其他开源和闭源基线。
⚖️ 评分理由
- 学术质量(6.5/7):创新性强,提出了新颖且完整的“符号乐谱生成”范式。技术方案设计合理(小节表示,Dual-NTP, CoS)。实验对比全面,基线强大(包括商业系统Suno),评估指标多样且结果令人信服。扣分点:1) 模型具体架构参数(如层数、维度)未公开;2) 端到端生成依赖外部不可开源的商业软件,影响了系统的完全自主性与学术复现价值。
- 选题价值(1.5/2):处于音乐AI生成前沿,针对现有方法的痛点(可控性、效率、可解释性)提出解决方案,具有明确的学术价值和潜在应用空间(如AI辅助作曲工具)。与音频/AI生成社区读者相关性高。扣分点:音乐生成领域相对专门,其影响力可能不及通用语音或文本生成模型广泛。
- 开源与复现加成(0.5/1):承诺开源代码(已提供GitHub链接)和数据集(将在发表后开源),这是重大贡献。但扣分在于:1) 未公开预训练模型权重;2) 关键依赖(VOCALOID)为商业软件;3) 部分核心训练细节(超参数、硬件)缺失。因此无法给予满分加成。