📄 Variational Low-Rank Adaptation for Personalized Impaired Speech Recognition
#语音识别 #领域适应 #多语言 #少样本 #低资源
✅ 7.5/10 | 前50% | #语音识别 | #领域适应 | #多语言 #少样本
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Niclas Pokel(苏黎世大学/苏黎世联邦理工学院神经信息学研究所;慕尼黑工业大学计算机、信息与技术学院)
- 通讯作者:未明确说明(论文中未单独列出通讯作者信息)
- 作者列表:Niclas Pokel(苏黎世大学/苏黎世联邦理工学院神经信息学研究所;慕尼黑工业大学计算机、信息与技术学院),Pehuén Moure(苏黎世大学/苏黎世联邦理工学院神经信息学研究所),Roman Boehringer(苏黎世大学/苏黎世联邦理工学院神经信息学研究所),Shih-Chii Liu(苏黎世大学/苏黎世联邦理工学院神经信息学研究所),Yingqiang Gao(苏黎世大学计算语言学系)
💡 毒舌点评
论文在解决一个具有社会意义的实际问题(受损语音识别)上方法扎实、实验设计相对全面,特别是在低资源设置下的性能提升和定性错误模式分析颇具亮点;但其核心方法——贝叶斯LoRA——并非全新思想,且新发布的数据集(BF-Sprache)仅包含单个说话人,这极大地限制了结论的泛化性和说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开经过VI LoRA微调的模型权重。
- 数据集:已公开:德语BF-Sprache数据集。论文未说明具体获取方式,但提供了作者联系邮箱。UA-Speech和Common Voice为已有公开数据集。
- Demo:未提及。
- 复现材料:提供了核心方法框架描述、部分超参数(LoRA秩r=32, KL权重10%)、损失函数公式、以及数据集构成描述,但缺少完整的训练脚本、环境配置和详细超参数列表。
- 论文中引用的开源项目:主要依赖 Whisper (OpenAI) 作为骨干模型。此外,引用了 Common Voice 数据集。
📌 核心摘要
- 问题:患有先天性疾病(如脑瘫)或获得性脑损伤(如中风)导致的语音障碍,使得现有先进的ASR模型(如Whisper)识别性能严重下降。这主要是由于相关语音数据稀缺、声学变异性高,且数据收集与标注困难。
- 方法核心:提出一种基于贝叶斯低秩适应(Variational Low-Rank Adaptation, VI LoRA)的个性化微调框架。该方法在标准LoRA的基础上引入变分推断,为低秩适配矩阵学习概率分布(高斯分布),并通过最小化负ELBO进行训练,以正则化微调过程并捕获不确定性。此外,论文提出一种数据驱动的先验估计方法,利用预训练权重标准差的双峰分布来为不同层设置合适的先验方差。
- 与已有方法相比新在哪里:
- 贝叶斯LoRA框架:不同于标准LoRA(确定性)或仅用于后验分析的贝叶斯LoRA,本方法将变分推断作为动态训练正则化器,旨在提升在低数据、高变异场景下的鲁棒性。
- 数据驱动先验:通过对预训练权重标准差的分析,发现其呈双峰分布(如图1),据此为不同层设置不同的先验方差,比统一的先验更合理。
- 应用与验证:将该方法应用于受损语音识别这一挑战性任务,并在新的德语数据集BF-Sprache和英文UA-Speech上进行跨语言验证。
- 主要实验结果:
- 在德语BF-Sprache数据集上,VI LoRA(双峰先验)在非规范语音上取得了最低的CER(20.09%)和WER(42.86%),同时在规范语音(Common Voice)上保持了最佳的性能(CER 2.15%,WER 6.05%),显著优于标准LoRA、MoRA和全参数微调(见表1)。
- 在低资源设置下(训练数据减少至25%),VI LoRA的优势更为明显(见表3)。
- 定性分析显示,全参数微调模型容易产生基于语法的“幻觉”转录,而VI LoRA的转录更贴近语音本身的音素(见表4)。
- 实际意义:为沟通障碍人群提供了一种更精准、数据高效的语音识别个性化路径,有助于推动包容性语音技术的发展,特别是在低资源语言环境。
- 主要局限性:
- 方法依赖于对变分分布的简化假设(如均值场近似、矩阵元素独立),可能无法完全捕获参数间的复杂依赖。
- 新发布的BF-Sprache数据集仅包含单个说话人,数据规模小,限制了方法泛化能力的评估。
- 论文未提供完整的训练代码和模型权重,影响可复现性。
🏗️ 模型架构
论文提出的方法是一个针对ASR模型微调的适配框架,而非一个独立的端到端ASR模型。
- 骨干模型:使用开源的大规模预训练ASR模型 Whisper-Large V3 作为基础。
- 适配模块:在Whisper的特定层(如多头注意力层的查询、键、值投影矩阵)插入 低秩适配(LoRA)模块。每个LoRA模块包含两个低秩矩阵 A 和 B,其更新量为 ΔW = α (B A) / r。
- 贝叶斯化核心:将确定性的LoRA参数(A, B)扩展为概率分布。采用 变分推断(VI) 方法,假设后验分布 q_ϕ(A, B) 可分解为两个独立的对角高斯分布:q_ϕA(A) 和 q_ϕB(B)。每个分布的均值(µ)和方差(σ²)是可学习的变分参数。
- 训练目标:通过最小化 负证据下界(ELBO) 来学习变分参数。损失函数由两部分组成:
- 任务损失:即标准Whisper的交叉熵损失,通过从当前变分分布中采样参数计算得到(蒙特卡洛估计)。
- KL散度正则项:KL[q_ϕ(A, B) || p(A, B)],衡量学习到的分布与预定义先验分布之间的差异。论文中使用该KL项的10%作为整体损失的一部分,以平衡适应与泛化。
- 数据驱动先验:先验 p(A, B) 不是固定的,而是根据预训练权重动态设置。具体来说,对于每一层的权重矩阵 W₀,计算其经验标准差 ĝσₚ。通过分析所有目标层的标准差,发现其呈双峰分布(见图1),于是使用高斯混合模型拟合出两个峰的中心点。然后,为每一层分配其所属峰对应的先验方差 (σₚ⁽ˡ⁾)²,而先验均值 (µₚ) 设为0。
- 输出与推理:训练完成后,对于新输入的语音,从学到的变分分布 q_ϕ(A, B) 中采样一组参数(或使用均值),得到适配后的权重 W₀ + α (B A) / r,然后进行前向推理,输出文本转录。论文的定性分析提到,其随机性(多次前向传播的边际化)可能有助于产生更关注语音本身的预测。
整体流程:输入受损语音 -> Whisper编码器提取特征 -> 经过插入了VI LoRA模块的Transformer层(参数从变分分布采样) -> Whisper解码器 -> 输出转录文本。训练时,损失反向传播以更新变分参数 (µ, σ)。
💡 核心创新点
- 贝叶斯LoRA框架(VI LoRA):将贝叶斯深度学习思想与参数高效的LoRA微调相结合。之前局限:标准LoRA在数据稀缺时易过拟合;现有的贝叶斯LoRA多用于静态分析或效率优化(如量化、剪枝)。如何起作用:通过为LoRA权重引入概率分布,并以KL散度作为正则项,鼓励模型学习更鲁棒、不确定性更低的适应,从而在少样本情况下减少过拟合,提升对高变异受损语音的泛化能力。
- 基于预训练权重的双峰先验估计:之前局限:为所有层的LoRA权重使用统一的先验(如标准正态分布)可能不合理,因为不同层的预训练权重本身具有不同的尺度。如何起作用:通过对预训练权重标准差的经验分析(图1),识别出双峰分布,为不同尺度的层分配不同的先验方差,使得正则化更加贴合模型自身的特性。
- 语义重链数据增强:在UA-Speech数据集上,使用一种名为“语义重链”的方法,将孤立词级的转录组装成语义连贯的句子级语音,以改善仅在孤立词上训练的模型的流畅性。收益:为评估提供了更接近自然对话的测试数据。
- 新德语受损语音数据集(BF-Sprache):收集并发布了来自一名结构性语音障碍者的德语孤立词及自发语音数据集。收益:为跨语言、低资源的受损语音识别研究提供了新的、宝贵的评估资源。
🔬 细节详述
- 训练数据:
- 英语:UA-Speech 数据集,包含19名不同严重程度的构音障碍患者和13名对照者的录音,约66小时,主要为孤立词。实验中仅使用障碍者语音。
- 德语:新发布的 BF-Sprache 数据集,来自一名说话人,训练集为孤立词(总时长约2小时),测试集为自发语音。
- 规范语音评估:使用 Mozilla Common Voice 数据集的德语和英语部分,用于衡量微调后模型在正常语音上的“遗忘”程度。
- 损失函数:最终损失
L_VI = -Eq[log p(D|A,B)] + β * KL[q||p]。其中第一项是任务损失(Cross-Entropy),第二项是KL散度正则项。β在论文中设为0.1(即10%权重)。 - 训练策略:
- 基础模型:Whisper-Large V3。
- LoRA秩(r):主要实验选择
r=32,并测试了其他值(如64)。高秩(r=64)会加剧对规范语音的遗忘。 - MoRA基线:为匹配参数量,其秩设为320。
- 权重衰减(WD):作为对照,部分实验添加了权重衰减。
- 优化器:未明确说明。
- 学习率、Batch Size、训练轮数:论文中未提供具体数值。
- 关键超参数:
- LoRA适用层:目标层数量N=288(来自Whisper的注意力层)。
- KL散度计算:为避免数值不稳定,损失中的KL项是对当前优化步骤中KL值为有限值(非NaN/Inf)的层取平均。
- 先验方差 (σₚ⁽ˡ⁾)²:从预训练权重标准差的双峰分布(图1)中通过高斯混合模型/ k-means 聚类得到两个中心点,再分配给各层。
- 训练硬件:论文中未说明。
- 推理细节:
- 解码策略:未明确说明。
- 语义重链:在评估时,将孤立词转录组装成句子进行测试,以模拟更自然的语音。
- 正则化技巧:核心正则化手段是KL散度项。此外,实验对比了添加传统权重衰减(WD)的效果。
📊 实验结果
主要Benchmark:UA-Speech(英语,非规范语音)、BF-Sprache(德语,非规范语音)、Common Voice(英语/德语,规范语音)。 主要指标:字错误率(WER)和字符错误率(CER)。
表1:在BF-Sprache(非规范)和Common Voice(规范)上的结果(微调数据为BF-Sprache训练集)
| Setup | 非规范 CER | 非规范 WER | 规范 CER | 规范 WER |
|---|---|---|---|---|
| 0-shot Inference | 40.38 ± 0.00 | 82.11 ± 0.00 | 2.01 ± 0.00 | 6.18 ± 0.00 |
| Full Fine-tuning | 22.60 ± 1.85 | 46.43 ± 2.74 | 2.40 ± 0.34 | 7.83 ± 0.72 |
| + WD | 22.53 ± 1.55 | 46.17 ± 2.66 | 2.38 ± 0.27 | 7.66 ± 0.49 |
| Standard LoRA | 23.85 ± 0.51 | 46.64 ± 1.47 | 2.42 ± 0.21 | 7.11 ± 0.40 |
| + WD | 23.11 ± 0.44 | 46.18 ± 1.29 | 2.40 ± 0.19 | 6.98 ± 0.38 |
| MoRA | 25.87 ± 0.66 | 49.11 ± 1.44 | 2.54 ± 0.15 | 7.80 ± 0.23 |
| + WD | 26.43 ± 0.57 | 48.53 ± 1.47 | 2.33 ± 0.14 | 6.97 ± 0.23 |
| DP VI LoRA + KL | 20.09 ± 0.41 | 42.86 ± 1.48 | 2.15 ± 0.13 | 6.05 ± 0.23 |
| + WD | 31.42 ± 1.62 | 55.36 ± 3.51 | 8.21 ± 0.72 | 16.82 ± 1.17 |
| SP VI LoRA + KL | 21.33 ± 0.51 | 44.85 ± 1.87 | 2.02 ± 0.18 | 6.05 ± 0.27 |
| +WD | 26.02 ± 1.06 | 50.29 ± 2.09 | 2.33 ± 0.35 | 7.62 ± 0.65 |
| 关键结论:双峰先验VI LoRA(DP VI LoRA + KL)在非规范语音上取得最佳WER(42.86%),且在规范语音上性能损失最小(WER 6.05%),实现了最佳平衡。添加WD会严重损害性能。 |
表2:在UA-Speech上的相对性能(以全参数微调为100%基准)
| Setup | Speech Type | rel. CER | rel. WER |
|---|---|---|---|
| 0-shot | Non-Normative | 271.30% | 328.80% |
| LoRA | Non-Normative | 105.32% | 106.81% |
| SP VI LoRA | Non-Normative | 91.07% | 91.74% |
| DP VI LoRA | Non-Normative | 88.94% | 90.24% |
| 0-shot | Normative | 43.50% | 46.94% |
| LoRA | Normative | 78.55% | 81.21% |
| SP VI LoRA | Normative | 44.17% | 47.29% |
| DP VI LoRA | Normative | 49.87% | 55.36% |
| 关键结论:在UA-Speech上,VI LoRA方法(特别是DP VI LoRA)相比全参数微调,在非规范语音上降低了约11%的相对WER,同时在规范语音上的相对WER(即遗忘)显著低于LoRA,再次证明其在平衡适应与泛化上的优势。 |
表3:在BF-Sprache上,不同训练数据比例下的性能对比
| Train Data | VI LoRA CER | VI LoRA WER | Full Fine-tuning CER | Full Fine-tuning WER | LoRA CER | LoRA WER |
|---|---|---|---|---|---|---|
| 100% | 19.86 | 42.42 | 22.28 | 48.02 | 23.66 | 47.55 |
| 75% | 22.32 | 44.75 | 24.38 | 49.01 | 25.91 | 51.10 |
| 50% | 24.77 | 50.40 | 28.95 | 66.04 | 28.02 | 58.43 |
| 25% | 28.08 | 56.35 | 33.07 | 70.43 | 31.29 | 66.94 |
| 关键结论:随着训练数据减少,VI LoRA的优势越来越明显,尤其在25%数据时,其WER(56.35%)远低于全参数微调(70.43%),证明其卓越的数据效率。 |
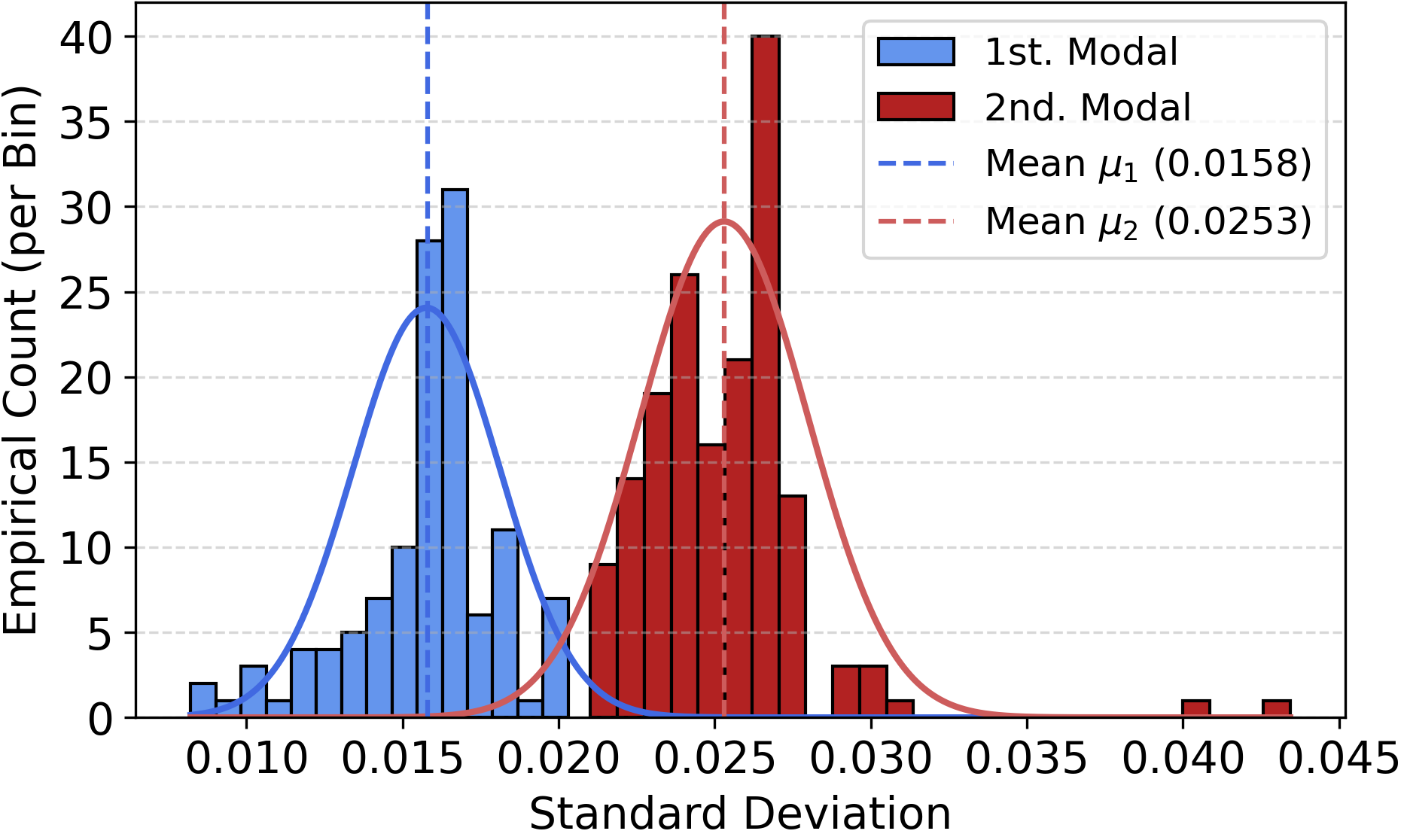 图1:此图展示了N=288个目标LoRA层预训练权重 W₀ 的经验标准差 ĝσₚ 的分布直方图。虚线标出了通过k-means识别出的两个模式的均值。这证明了为不同层采用不同尺度的先验方差(双峰先验)是合理的,支持了论文的核心设计。
图1:此图展示了N=288个目标LoRA层预训练权重 W₀ 的经验标准差 ĝσₚ 的分布直方图。虚线标出了通过k-means识别出的两个模式的均值。这证明了为不同层采用不同尺度的先验方差(双峰先验)是合理的,支持了论文的核心设计。
表4:对分布外短语的转录定性分析
| System | Transcription Output | PER/CER |
|---|---|---|
| Ground Truth: “Wiedikon, Enge, Thalwil, Baar.” | - | - |
| Full Fine-tuning | “Wie die kann, eine, teilweise, war.” | 56.0 / 45.7 |
| VI LoRA (ours) | “Vidikon, Enne, Talwil, Borg.” | 20.0 / 25.0 |
| Ground Truth: “Higashirinkan.” | - | - |
| Full Fine-tuning | “Ein Gassi rennt da.” | 86.7 / 63.2 |
| VI LoRA (ours) | “Higashirenpa.” | 26.7 / 25.0 |
| 关键结论:全参数微调模型在遇到未知词汇时倾向于生成语法通顺但语义错误的句子(“结构化幻觉”),而VI LoRA的输出虽然不完美,但更忠实于输入的语音音素,错误更具可解释性。这表明贝叶斯方法带来的随机性可能有助于抑制模型对先验语言模式的过度依赖。 |
⚖️ 评分理由
- 学术质量:6.0/7 - 创新性明确,将贝叶斯框架与LoRA结合应用于新领域;技术实现合理,实验设计包含多维度对比(方法、数据量、语言、受损程度);结果支持其主张。扣分点在于:贝叶斯LoRA非完全原创思想,且实验完全基于Whisper这一单一骨干模型,未探索其在其他ASR架构上的普适性;新数据集规模极小(单说话人),削弱了结论的泛化强度。
- 选题价值:1.5/2 - 研究针对真实且重要的社会需求(无障碍沟通),具有明确的应用前景。在语音识别领域,这是一个有意义且相对前沿的垂直方向。但其直接应用范围局限于受损语音人群,对更广泛语音技术读者的普适性参考价值有限。
- 开源与复现加成:0.5/1 - 论文贡献了一个新的德语受损语音数据集(BF-Sprache),这对其领域是宝贵资产。然而,论文未公开代码、预训练模型或完整的超参数配置(如学习率、batch size),使得精确复现其全部实验细节存在困难。