📄 USVexplorer: Robust Detection of Ultrasonic Vocalizations with Cross Species Generalization
#音频事件检测 #端到端 #生物声学 #时频分析
🔥 8.0/10 | 前25% | #音频事件检测 | #端到端 | #生物声学 #时频分析
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yilan Wei (Northwestern University, Evanston, USA)
- 通讯作者:未说明
- 作者列表:Yilan Wei(Northwestern University, Evanston, USA)、Kumiko Long(Northwestern University, Evanston, USA)、Arielle Granston(Northwestern University, Evanston, USA)、Adrian Rodriguez-Contreras(Northwestern University, Evanston, USA)
💡 毒舌点评
亮点在于架构设计清晰(CNN+Transformer)并系统验证了其跨物种泛化能力,音视频同步的“锦上添花”功能也显示了对实际研究需求的理解。短板是实验部分虽然全面,但对比的基线方法(DeepSqueak, VocalMat等)相对较旧且并非在所有指标上都处于SOTA,论文未能提供在这些具体数据集上更新、更强的基线对比,削弱了“state-of-the-art”宣称的绝对说服力。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/weiyilan9/USVexplorer。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文使用了四个公开数据集(DeepSqueak, MarmAudio, NABat),并详细说明了数据来源。RatPup数据集为作者自行收集,但根据伦理声明,应遵循IACUC规定。未提及是否将自收集数据集开源。
- Demo:未提供在线演示。
- 复现材料:论文提供了详细的训练协议(学习率、优化器、调度、损失函数)、模型架构参数(Transformer层�数、头数等)、数据预处理步骤和评估指标,复现信息较为充分。
- 引用的开源项目:论文未明确列出依赖的开源工具/模型。但根据方法描述,实现必然依赖PyTorch、STFT计算工具、FFmpeg(用于音视频同步)等常见库。
📌 核心摘要
- 要解决的问题:现有的超声波发声(USV)检测方法存在跨物种泛化能力差、依赖人工干预、无法有效将声音信号与动物行为数据同步对齐等问题,限制了对动物声音-行为关系的深入理解。
- 方法核心:提出USVexplorer,一个端到端的USV检测框架。其核心是一个四阶段架构:输入音频的STFT频谱图先经过“BandGate”自适应频率加权模块,然后通过“Conv1dSub”进行时间降采样和特征扩展,接着由“TransEnc”(8层Transformer编码器)进行长程依赖建模,最后通过分类头输出检测结果。此外,框架包含一个可选的音视频同步模块。
- 新在哪里:与以往方法(如基于Faster R-CNN的DeepSqueak)相比,USVexplorer系统地结合了1D CNN的局部特征提取与Transformer的全局上下文建模能力;其“BandGate”模块被设计用于动态适应不同物种的频带分布和噪声,增强了跨物种泛化能力;框架首次整合了可选的音视频同步功能,支持多模态分析。
- 主要实验结果:USVexplorer在两个大鼠数据集(RatPup, DeepSqueak)上取得了最优的F1和MCC分数。在跨物种测试中(绒猴MarmAudio和蝙蝠NABat数据集),其F1分数均超过0.99,展示了强大的泛化能力。消融实验证明了移除Conv1dSub或TransEnc模块会导致性能下降(例如,在RatPup上移除TransEnc使Precision从0.970降至0.913)。具体关键结果见下表:
| 物种 | 数据集 | 方法 | F1 | MCC | Precision | Recall |
|---|---|---|---|---|---|---|
| 大鼠 | RatPup | USVexplorer | 0.924 | 0.901 | 0.970 | 0.881 |
| ContourUSV | 0.868 | 0.823 | 0.868 | 0.868 | ||
| DeepSqueak | USVexplorer | 0.877 | 0.784 | 0.888 | 0.866 | |
| ContourUSV | 0.727 | 0.612 | 0.911 | 0.605 | ||
| 绒猴 | MarmAudio | USVexplorer | 0.997 | - | 0.996 | 0.998 |
| 蝙蝠 | NABat | USVexplorer | 0.998 | - | 0.998 | 0.997 |
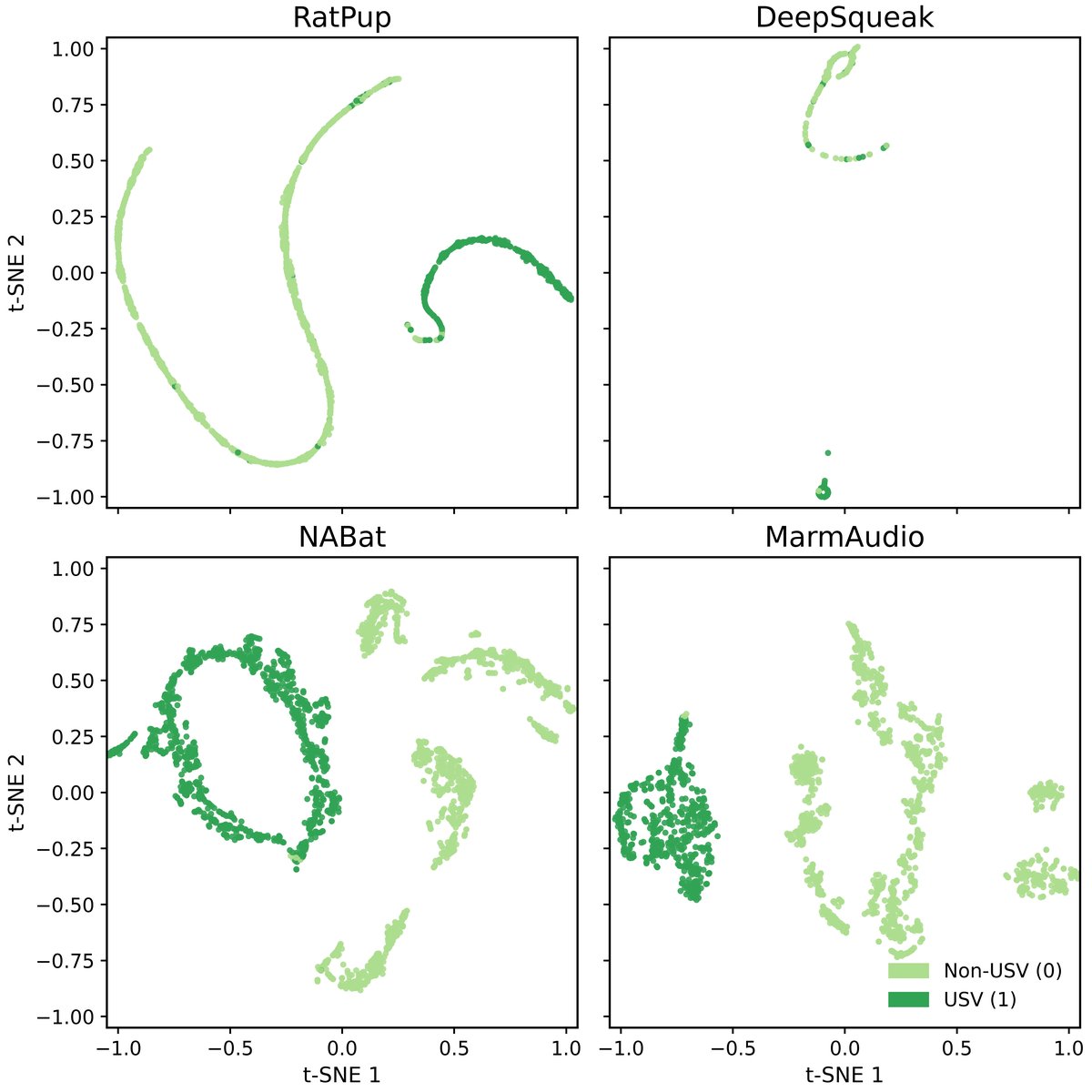 图2:不同数据集上学习到特征的t-SNE可视化。图中显示了同物种内USV模式的清晰聚类以及不同物种间的明显分离,表明模型能够捕获物种不变的基本声学特征和物种特异性变异。
图2:不同数据集上学习到特征的t-SNE可视化。图中显示了同物种内USV模式的清晰聚类以及不同物种间的明显分离,表明模型能够捕获物种不变的基本声学特征和物种特异性变异。
- 实际意义:为神经科学、行为生态学等领域的研究人员提供了一个更鲁棒、自动化且能跨物种使用的USV检测工具,并初步支持了声音与行为的多模态对齐分析,有助于更全面地理解动物交流。
- 主要局限性:虽然实现了跨物种检测,但音视频同步功能仅在3.29±0.66ms精度上得到验证,其实际效用和与其他行为分析软件的集成度未充分评估;模型相比更简单的CNN可能计算复杂度更高,在资源受限场景下的适用性未讨论;论文中未提供USVexplorer与更新、更强基线方法(如更新版的DeepSqueak或其他音频事件检测SOTA模型)的直接对比。
🏗️ 模型架构
USVexplorer是一个四阶段的端到端框架,处理流程如下:
- 输入与预处理:原始音频信号(重采样至250 kHz)被分割为220毫秒的片段,计算STFT频谱图(N_FFT=1024, hop=256, window=1024),得到形状为 [T, 513] 的幅度谱图,再进行频率轴归一化,最终输入张量X ∈ R^{T×513}。
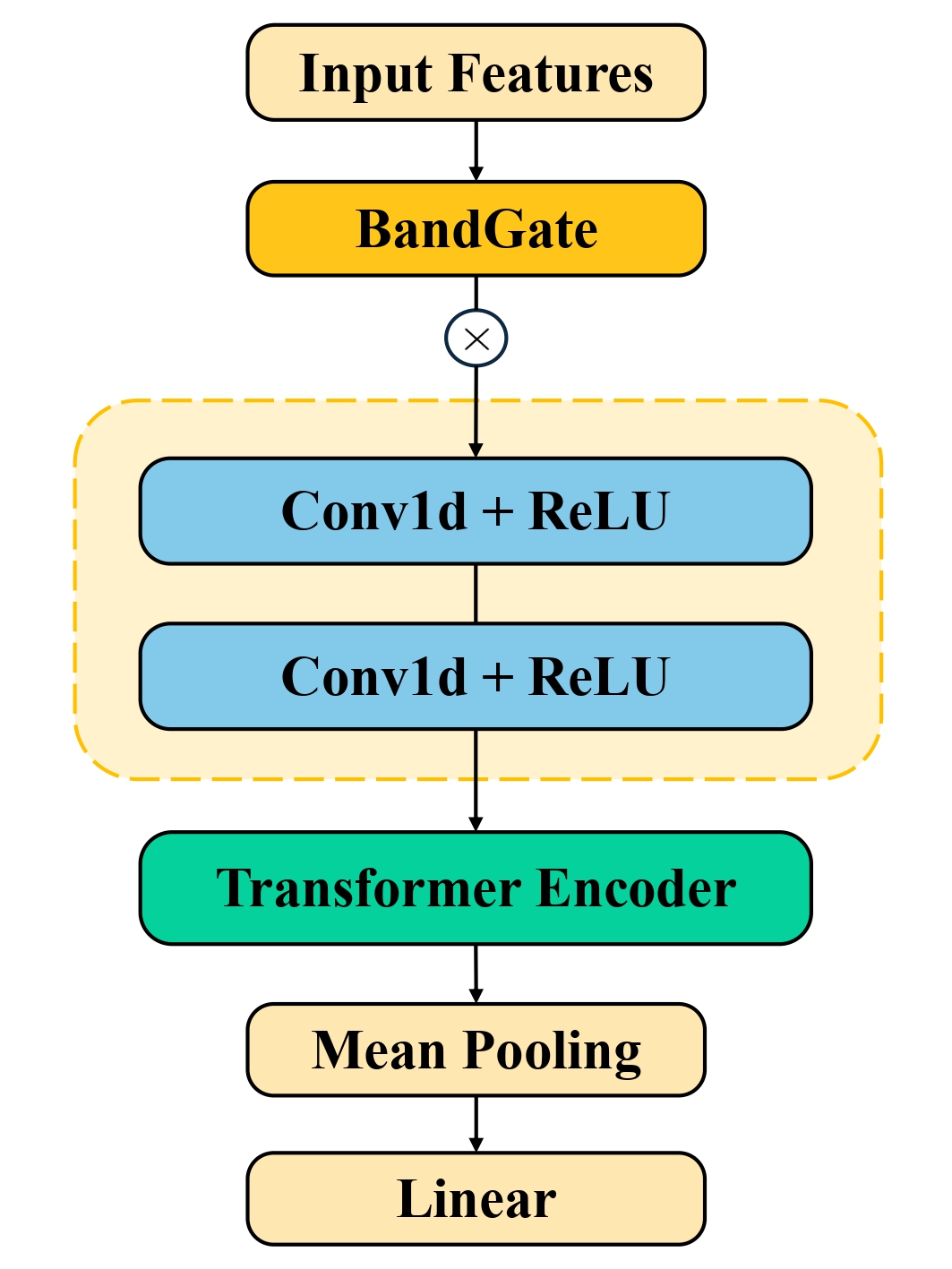 图1:USVexplorer的检测架构图。数据从左向右流动,依次经过四个主要模块。
图1:USVexplorer的检测架构图。数据从左向右流动,依次经过四个主要模块。
BandGate模块(自适应频率加权):
- 功能:动态调整不同频率带的重要性,以应对不同物种的USV频带差异和环境噪声污染,是跨物种泛化能力的关键设计。
- 结构:采用Squeeze-and-Excitation架构。输入X ∈ R^{B×T×D} (此处D=513)首先经过全局平均池化(GAP)得到通道统计量g̅ ∈ R^D。然后通过两个全连接层(W1 ∈ R^{D/16×D}, W2 ∈ R^{D×D/16},中间用ReLU激活,缩减比r=16)生成通道注意力向量g ∈ R^D,最后经Sigmoid激活后与原始特征X进行逐元素相乘(⊙),得到加权特征 ̂X = X ⊙ g。
- 动机:使模型能够自动关注对当前物种或噪声环境最相关的频段。
Conv1dSub模块(时间子采样):
- 功能:对时间维度进行下采样,减少计算量,同时扩展特征维度以学习更丰富的表示。
- 结构:两个连续的1D卷积块,每个块使用3×3卷积核,步长为2,激活函数为ReLU。这导致时间维度T变为T/4,特征维度从513扩展到768。
- 动机:USV检测需要处理长音频序列,此模块在保持关键信息的同时提高了计算效率。
TransEnc模块(长程依赖建模):
- 功能:捕获USV序列中复杂的长程时间模式,以区分背景噪声和其他声学事件。
- 结构:一个8层的Transformer编码器,包含12个注意力头,每个头的维度d_k=64,前馈网络维度d_ff=3072。它通过多头自注意力机制在所有时间步上进行全局信息交互。
- 动机:USV信号的时序模式复杂,且存在长距离依赖关系,Transformer擅长建模此类关系。
分类头:
- 功能:将时间维度的信息聚合,并输出最终的二元分类结果(是/否USV)。 结构:对Transformer的输出进行均值池化,得到一个768维的向量c。然后通过一个线性层映射为一个标量,用于二元分类:ŷ = W_cls c + b_cls。
- 动机:均值池化具有置换不变性,适合序列分类任务。
组件交互:频谱图依次流经上述四个模块。BandGate在频域进行自适应增强;Conv1dSub在时域进行压缩并深化特征;TransEnc在更抽象的特征空间进行全局时序建模;最后分类头做出决策。整个流程是可微分的,支持端到端训练。
💡 核心创新点
- 混合CNN-Transformer架构:创新性地将1D卷积(用于局部时序特征提取和降采样)与Transformer编码器(用于全局长程依赖建模)系统结合应用于USV检测任务。这种组合借鉴了语音识别领域的成功经验,但针对USV的高噪声、多样模式等特有挑战进行了适配和优化。
- 自适应频率加权模块(BandGate):提出了一个轻量级的、基于通道注意力的BandGate模块。该模块能根据输入信号动态学习不同频率带的重要性权重,显著提升了模型在跨物种(不同USV频带分布)和不同噪声环境下工作的鲁棒性。
- 跨物种泛化能力:通过上述架构设计,USVexplorer首次在多个物种(大鼠、绒猴、蝙蝠)和不同采样率(96kHz-500kHz)的数据集上验证了强大的、近乎开箱即用的跨物种检测能力(F1 > 0.99),解决了现有方法物种依赖性强的痛点。
- 端到端框架与可选多模态扩展:提出了一个完整的端到端流水线,并设计了可选的音视频同步模块。该模块能将USV事件的时间戳与视频帧对齐,生成复合可视化文件,为声音-行为关联研究提供了初步的工具支持,这是现有USV检测工具所缺乏的。
🔬 细节详述
- 训练数据:
- RatPup(大鼠):26只Wistar幼鼠,超过11,000个USV片段,250kHz采样,配有视频。
- DeepSqueak(大鼠):超过2,700个音频片段,190kHz采样。
- MarmAudio(普通绒猴):20个个体,超过17,000个音频片段,96kHz采样(使用技术验证子集)。
- NABat(北美蝙蝠-小棕蝠):超过56,000个音频片段,采样率192-500kHz。
- 预处理:所有数据统一重采样至250kHz,分割为220ms片段。计算STFT频谱图(N_FFT=1024, hop=256, window=1024),进行频率轴min-max归一化。
- 数据增强:为平衡类别,在蝙蝠和绒猴数据集中,利用噪声录音构建负样本。
- 划分:训练/验证/测试集按70%/20%/10%比例使用分层抽样划分,同时提供基于片段和基于文件的划分评估。
- 损失函数:加权二元交叉熵损失。正样本权重与类别频率的倒数成正比,以解决类别不平衡问题。
- 训练策略:
- 优化器:AdamW,初始学习率1e-4,权重衰减1e-2。
- 学习率调度:线性warmup后采用余弦退火衰减至最小1e-6,共8000步。
- 批量大小:64。
- 训练稳定性:使用混合精度计算(FP16)、自动梯度缩放和梯度裁剪。
- 模型选择:基于验证集上每100步间隔的F1分数选择最佳模型。
- 关键超参数:Transformer编码器:8层,12个注意力头,d_k=64,d_ff=3072。Conv1dSub:两个卷积块,核大小3,步长2。BandGate:缩减比r=16。
- 训练硬件:NVIDIA H100 GPU。
- 推理细节:论文未明确说明解码策略、温度等参数。由于是片段级二元分类,推理过程即对每个音频片段进行一次前向传播。
- 正则化/稳定技巧:使用了权重衰减、学习率warmup、梯度裁剪、混合精度训练。
📊 实验结果
- 主要基准与指标:在四个USV数据集(RatPup, DeepSqueak, MarmAudio, NABat)上,评估指标包括Precision、Recall、F1分数、MCC、PR-AUC和ROC-AUC。
- 与基线对比:USVexplorer在两个大鼠数据集上与DeepSqueak、VocalMat、ContourUSV进行对比(表1)。在RatPup(片段划分)上,USVexplorer以F1=0.924和MCC=0.901显著超越所有基线。在DeepSqueak数据集上,USVexplorer的MCC(0.784)也最高。在跨物种测试中(表2),USVexplorer在绒猴(MarmAudio)和蝙蝠(NABat)数据集上的F1值分别高达0.997和0.998,且同时保持了高精度和高召回率。
- 消融实验:在RatPup数据集上的消融研究(表3)显示,移除Conv1dSub模块,F1从0.924降至0.905,Precision从0.970降至0.938;移除TransEnc模块,F1降至0.917,Precision显著下降至0.913。这证明了两个组件对模型整体性能(尤其是精度)的重要性。
| 方法 | F1 | Precision | Recall |
|---|---|---|---|
| USVexplorer | 0.924 | 0.970 | 0.881 |
| w/o Conv1dSub | 0.905 | 0.938 | 0.875 |
| w/o TransEnc | 0.917 | 0.913 | 0.922 |
表3:在RatPup数据集上的消融实验结果。
- 跨物种与细分结果:论文明确展示了在不同物种(大鼠、绒猴、蝙蝠)和不同数据划分(片段划分与文件划分)下的稳健性能(表1和表2)。文件划分(后缀F)通常更难,但USVexplorer仍保持高性能。
- 可视化证据:图2的t-SNE可视化直观地展示了USVexplorer学到的特征在不同物种间具有可分性,且同物种的USV特征能良好聚类,这从特征表示层面解释了其跨物种泛化能力。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性(2.0/3):架构设计(CNN+Transformer+BandGate)的组合与适配有一定新意,特别是BandGate模块针对USV特点的设计。将音视频同步整合到USV检测框架中是一个有价值的工程创新。但核心思想(混合架构、注意力机制)并非全新。
- 技术正确性(2.0/2):方法描述清晰,公式明确,实验设置合理。消融实验验证了各组件作用。音视频同步精度有量化指标(3.29±0.66ms MAE)。
- 实验充分性(1.5/1.5):实验设计全面,覆盖了多个数据集、多种评估指标(包括适合不平衡数据的MCC)、消融研究和可视化分析。提供了代码链接。
- 证据可信度(0.5/0.5):所有声称的性能提升均有具体数字支撑,且通过消融和可视化提供了多层次证据。
- 选题价值:1.5/2
- 前沿性(0.5/0.5):USV检测是生物声学和神经行为学的研究前沿,自动化和跨物种泛化是该领域的明确需求。
- 潜在影响(0.5/0.5):工具可直接服务于行为神经科学研究,促进对动物交流和情感的理解,应用空间明确。
- 实际应用空间(0.3/0.5):作为研究工具,受众相对专业但刚需。音视频同步功能提升了其实用性。
- 与读者相关性(0.2/0.5):对从事音频事件检测、生物声学、多模态分析的读者有直接参考价值,对更广泛的语音/音频领域读者,其架构设计思想也有一定借鉴意义。
- 开源与复现加成:0.5/1
- 代码与细节:提供了明确的代码仓库链接(https://github.com/weiyilan9/USVexplorer),并给出了训练细节(优化器、学习率��批量大小、调度策略等)、关键超参数和评估方法。这极大地增强了可复现性。
- 扣分原因(-0.5):虽然提供了代码,但论文未提及是否提供预训练模型权重,也未明确说明依赖的开源工具列表(除数据集外)。这稍微限制了立即应用和对比的便利性。