📄 Universr: Unified and Versatile Audio Super-Resolution Via Vocoder-Free Flow Matching
#音频超分辨率 #流匹配 #语音增强 #音频生成 #模型评估
🔥 8.0/10 | 前25% | #音频超分辨率 | #流匹配 | #语音增强 #音频生成
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Woongjib Choi(延世大学电气与电子工程系)
- 通讯作者:未说明
- 作者列表:Woongjib Choi(延世大学电气与电子工程系)、Sangmin Lee(延世大学电气与电子工程系)、Hyungseob Lim(延世大学电气与电子工程系)、Hong-Goo Kang(延世大学电气与电子工程系)
💡 毒舌点评
这篇论文最大的亮点是提供了一个优雅且高效的“去vocoder”解决方案,用一个统一的流匹配模型直击频谱,避免了传统两阶段管线的性能天花板,在主观听感上甚至优于vocoded的GT。然而,其核心架构本质是成熟的ConvNeXt V2 U-Net在频域数据上的应用,创新更多体现在任务定义和流程整合上,而非模型架构本身,这使得它更像一个工程上的巧妙优化而非理论上的重大突破。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/woongzip1/UniverSR
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文中提及了训练所用的数据集名称和规模,但未说明是否提供这些数据集的下载或处理脚本。
- Demo:提供在线演示链接:https://woongzip1.github.io/universr-demo
- 复现材料:论文中详细说明了模型架构、训练超参数、损失函数、推理设置等,为复现提供了关键信息。
- 论文中引用的开源项目:未明确提及依赖的具体开源代码库。
📌 核心摘要
- 要解决什么问题:传统的两阶段音频超分辨率方法需要先预测梅尔频谱,再依赖预训练的神经声码器合成波形,导致最终质量受限于声码器性能,且流程复杂。
- 方法核心是什么:论文提出 UniverSR,一个无 vocoder 的端到端框架。它将音频超分辨率视为频谱修复问题,使用流匹配生成模型直接估计低频谱条件下的复数谱系数(包含幅度和相位)的条件分布,然后通过逆短时傅里叶变换(iSTFT)直接恢复波形。
- 与已有方法相比新在哪里:a) 去 vocoder:直接建模复数谱,无需单独的波形合成阶段,简化了流程并突破了性能瓶颈;b) 使用流匹配:相比传统扩散模型,流匹配在较少采样步数(如4步)下即可生成高质量结果,效率更高;c) 统一架构:单一模型可处理语音、音乐、音效等多种音频类型及多种上采样倍率(×2 到 ×6)。
- 主要实验结果如何:
- 在统一模型评估中(Table 1),UniverSR 在音乐和音效领域全面超越 AudioSR 和 FlashSR,在语音领域也达到竞争水平,且参数量(57M)远小于基线(>600M)。
- 在纯语音数据集VCTK上的评估(Table 2)显示,在最具挑战性的8kHz→48kHz任务中,UniverSR 取得了最优的 LSD-HF(1.14)和2f-model(31.41)分数。
- 主观听感测试(图3)表明,在8kHz上采样任务中,UniverSR 的MOS分数最高,甚至高于“经vocoder处理的真实音频(GT (Vocoded))”。
- 定性分析(图4)显示,UniverSR 生成的频谱谐波结构更清晰,高频细节更丰富。
- 消融研究(Table 3)表明,引导尺度 ω 的选择在感知丰富度和客观保真度之间存在权衡。
- 实际意义是什么:该方法为高质量、高效的音频带宽扩展提供了一个更简洁、更统一的解决方案,可广泛应用于提升语音清晰度、修复历史录音、增强流媒体音频质量等场景。其“去 vocoder”范式可能启发其他音频生成任务。
- 主要局限性是什么:论文未明确讨论模型在极度低比特率或极端噪声条件下的鲁棒性;频谱修复方法依赖于STFT/iSTFT,可能引入相位相关的伪影(虽然实验显示听感良好);模型在最困难的语音任务(8kHz→48kHz)上,部分客观指标(如2f-model)略低于某些基线。
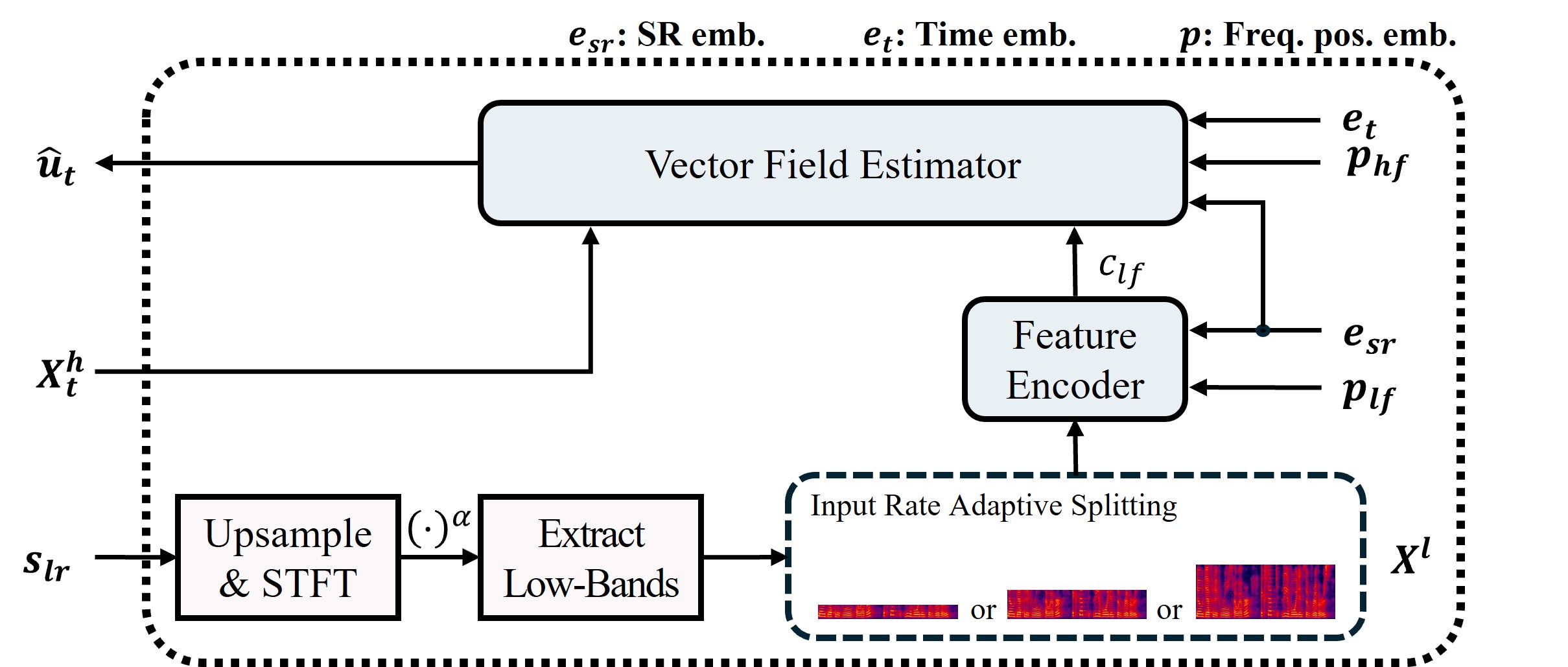
🏗️ 模型架构
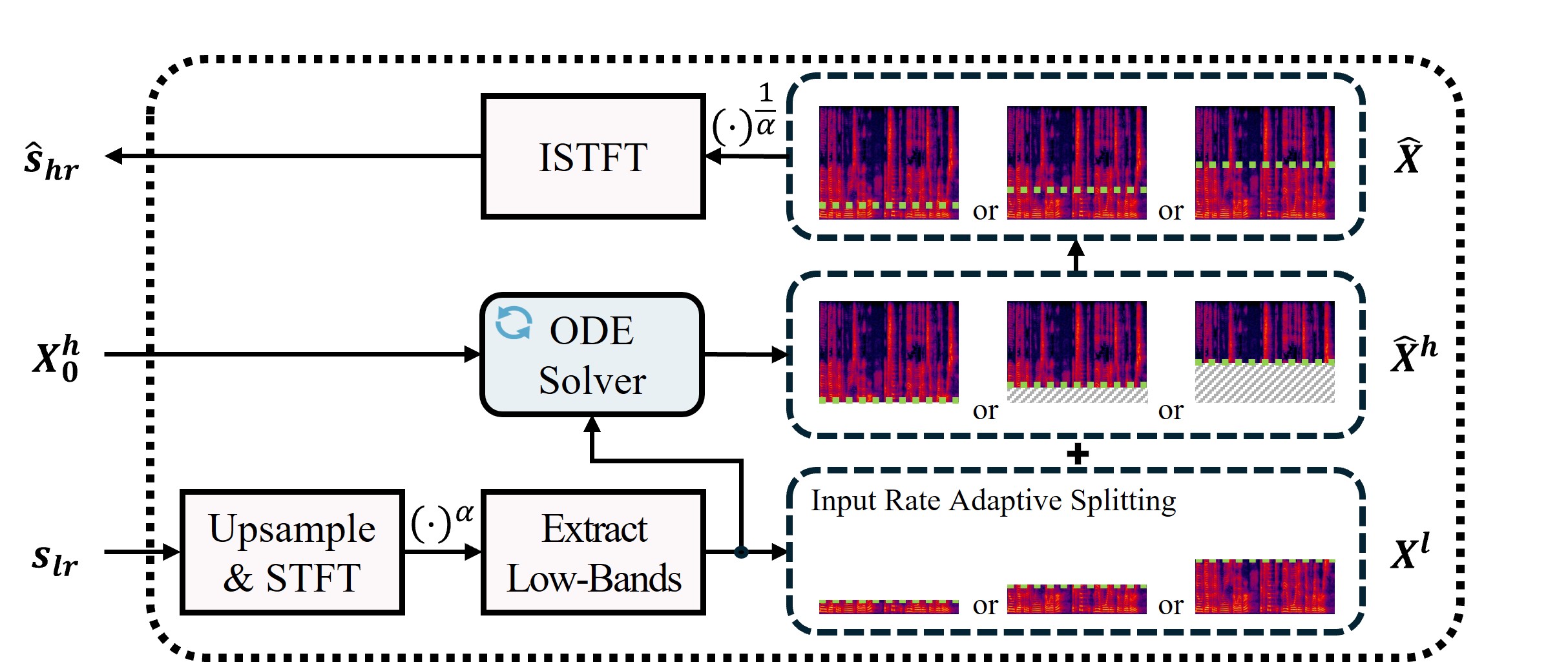
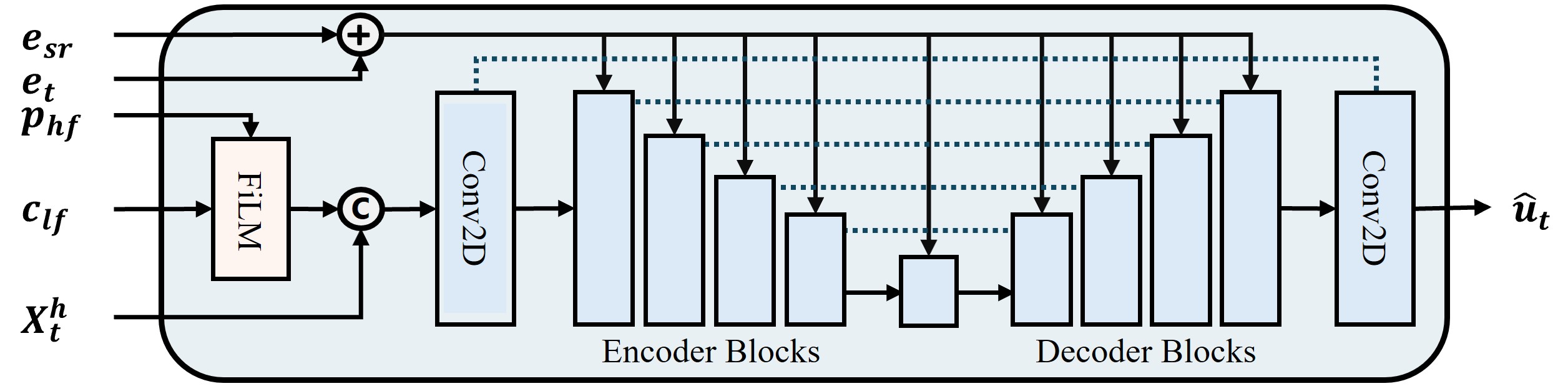 整体流程:模型采用端到端设计。输入为低分辨率(LR)波形
整体流程:模型采用端到端设计。输入为低分辨率(LR)波形 s_lr,首先通过 sinc 插值上采样至目标高分辨率(HR)长度,然后进行STFT得到复数谱。从复数谱中提取包含所有可能高频区域的固定大小高频目标 X_h,以及对应于原始LR带宽的低频谱 X_l。训练时,向量场估计器(VFE)在流匹配目标下学习,以低频谱 X_l 为条件,从高斯噪声中逐步生成 X_h。推理时,从噪声开始,通过ODE求解器迭代生成 X_h,最后与 X_l 拼接成完整频谱,并通过iSTFT得到HR波形。
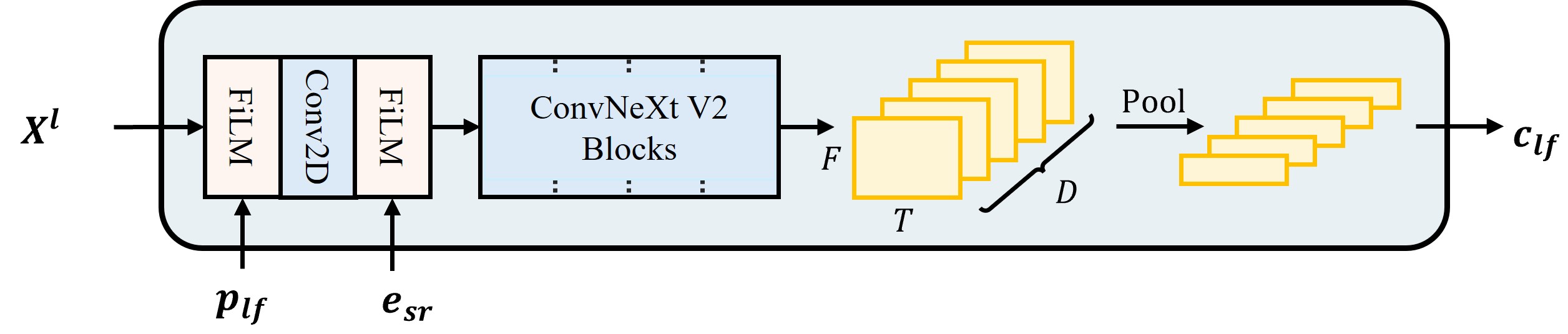 核心组件:
核心组件:
- 向量场估计器 (VFE):模型的主体,是一个U-Net架构,使用2D ConvNeXt V2块作为基本单元。它接收带有时间步信息的噪声高频谱
X_h_t和条件集c作为输入,预测目标向量场。U-Net具有编码器-瓶颈-解码器结构,通过跳跃连接传递特征。 - 条件机制:
- 声学特征:由一个特征编码器处理低频谱
X_l得到,是一个帧级的表示c_lf。该编码器还融合了频率位置嵌入和可学习的采样率嵌入,并通过自适应池化处理不同输入频率分辨率。 - 频率位置嵌入:一个正弦嵌入
p,用于提供频谱位置感知。其中高频部分的嵌入p_hf通过特征线性调制(FiLM)对声学特征c_lf进行调制,生成空间条件图,与X_h_t沿通道维度拼接作为VFE输入。 - 全局上下文嵌入:由时间步嵌入
e_t和采样率嵌入e_sr求和得到,被投影后添加到VFE每个ConvNeXt块的特征图中,提供全局状态信息。
- 声学特征:由一个特征编码器处理低频谱
💡 核心创新点
- Vocoder-Free 频谱修复框架:将音频超分辨率明确建模为复数谱高频段的修复任务,通过iSTFT直接恢复波形,摆脱了对预训练vocoder的依赖,解决了传统两阶段管线的性能瓶颈和优化复杂性问题。
- 基于流匹配的条件复数谱生成:将流匹配生成模型应用于音频频域,直接学习复数谱系数的条件分布。相比传统扩散模型,在保持高质量生成的同时,显著减少了推理所需的采样步数(实验中仅需4步)。
- 统一与多功能架构:通过精心设计的条件机制(融合声学特征、频率位置、采样率)和统一的训练数据,单一模型能够处理从8kHz到24kHz多种输入采样率,并泛化到语音、音乐、环境音效等多个音频领域,无需针对特定场景设计。
🔬 细节详述
- 训练数据:统一模型使用聚合的多领域数据训练:语音(218小时,来自HQ-TTS, EARS, Expresso)、音乐(460小时,来自Good-sounds, MAESTRO等)、音效(53小时,来自FSD50K)。另外训练了一个仅在VCTK(语音数据集)上训练的专用模型用于公平对比。
- 损失函数:采用条件流匹配(CFM)目标函数
L_CFM,即向量场估计器的预测输出与目标向量场u_t之间的均方误差(MSE)。 - 训练策略:使用AdamW优化器,初始学习率 2.0e-4,采用余弦衰减调度和10k步预热。统一模型训练500k迭代,VCTK专用模型训练100k迭代。训练时,每个batch的输入采样率从{8, 12, 16, 24 kHz}中随机选择(概率分别为0.7, 0.1, 0.1, 0.1)。
- 关键超参数:STFT参数:512个频率点,窗口大小1024,重叠50%。功率压缩比 α=0.2。流匹配参数 σ_min=0.1。模型总参数约57M(特征编码器
5M,VFE52M)。分类器自由引导(CFG)训练时,条件丢弃概率为0.1。推理时使用4步中点法ODE求解器,引导尺度 ω=1.5。 - 训练硬件:论文中未提及。
- 推理细节:从高斯噪声开始,使用4步中点法ODE求解器进行采样。应用CFG时,引导公式为 (1-ω) v_θ(x_t, t, c_∅) + ω v_θ(x_t, t, c),其中c_∅为声学特征替换为零嵌入的条件集。
- 正则化技巧:在训练中使用条件丢弃(概率0.1)以实现分类器自由引导。
📊 实验结果
主要对比实验结果(统一模型,对比AudioSR和FlashSR):
| 输入率 | 模型 | Vocoder | 语音 LSD-HF ↓ | 语音 2f ↑ | 音乐 LSD-HF ↓ | 音乐 2f ↑ | 音效 LSD-HF ↓ | 音效 2f ↑ |
|---|---|---|---|---|---|---|---|---|
| 8kHz | AudioSR [17] | ✓ | 1.64 | 30.69 | 1.59 | 11.99 | 1.52 | 22.58 |
| FlashSR [19] | ✓ | 1.41 | 26.14 | 1.31 | 18.01 | 1.33 | 29.52 | |
| Proposed | ✗ | 1.40 | 26.58 | 0.98 | 23.52 | 1.15 | 32.79 | |
| 12kHz | AudioSR [17] | ✓ | 1.74 | 30.69 | 1.51 | 14.22 | 1.53 | 26.00 |
| FlashSR [19] | ✓ | 1.37 | 28.66 | 1.41 | 20.46 | 1.39 | 33.54 | |
| Proposed | ✗ | 1.33 | 32.81 | 0.92 | 27.99 | 1.09 | 38.09 | |
| 16kHz | AudioSR [17] | ✓ | 1.65 | 35.28 | 1.48 | 16.78 | 1.57 | 28.29 |
| FlashSR [19] | ✓ | 1.29 | 33.98 | 1.48 | 24.71 | 1.56 | 37.97 | |
| Proposed | ✗ | 1.30 | 37.08 | 0.93 | 30.19 | 1.05 | 41.66 | |
| 24kHz | AudioSR [17] | ✓ | 1.52 | 44.17 | 1.47 | 20.17 | 1.66 | 34.80 |
| FlashSR [19] | ✓ | 1.22 | 37.79 | 1.62 | 27.36 | 1.50 | 42.48 | |
| Proposed | ✗ | 1.24 | 43.76 | 0.96 | 33.58 | 1.19 | 48.04 |
关键结论:所提模型在音乐和音效的所有采样率和指标上均达到最优(粗体),在语音上也表现竞争力。其参数量(57M)远小于基线(672M,639M)。
纯语音任务对比实验(在VCTK上训练的专用模型):
| 输入率→48kHz | 模型 | Vocoder | LSD-HF ↓ | 2f ↑ |
|---|---|---|---|---|
| 8kHz | Fre-Painter [20] | ✓ | 1.25 | 27.02 |
| FlowHigh [18] | ✓ | 1.19 | 27.88 | |
| NU-Wave2 [11] | ✗ | 1.58 | 27.58 | |
| UDM+ [12] | ✗ | 1.29 | 29.12 | |
| Proposed | ✗ | 1.14 | 31.41 | |
| 24kHz | Fre-Painter [20] | ✓ | 1.07 | 35.16 |
| FlowHigh [18] | ✓ | 1.10 | 35.26 | |
| NU-Wave2 [11] | ✗ | 1.09 | 39.98 | |
| UDM+ [12] | ✗ | 1.00 | 44.85 | |
| Proposed | ✗ | 1.06 | 44.14 |
关键结论:在最具挑战性的8kHz→48kHz任务中,所提模型在两项指标上均取得最优。在24kHz任务中,其2f-model分数与最强单阶段扩散模型UDM+接近。
主观听感测试(MOS):
 关键结论:在8kHz→48kHz任务中,所提模型在语音、音乐、音效三个领域的平均MOS均最高,且语音MOS甚至高于“经vocoder处理的真实音频(GT (Vocoded))”,表明其听感质量超越了vocoder本身的重建能力。
关键结论:在8kHz→48kHz任务中,所提模型在语音、音乐、音效三个领域的平均MOS均最高,且语音MOS甚至高于“经vocoder处理的真实音频(GT (Vocoded))”,表明其听感质量超越了vocoder本身的重建能力。
定性分析:
 关键结论:所提模型生成的频谱高频谐波结构比AudioSR和FlashSR更清晰、更完整。有趣的是,与使用vocoder的真实频谱(GT (Vocoded))相比,所提模型生成的高频部分细节更丰富,表明vocoder在高频重建上存在模糊化倾向。
关键结论:所提模型生成的频谱高频谐波结构比AudioSR和FlashSR更清晰、更完整。有趣的是,与使用vocoder的真实频谱(GT (Vocoded))相比,所提模型生成的高频部分细节更丰富,表明vocoder在高频重建上存在模糊化倾向。
消融研究(引导尺度ω的影响):
| CFG Scale | 语音 | 音乐 | 音效 | 平均 | ||||
|---|---|---|---|---|---|---|---|---|
| L ↓ | 2f ↑ | L ↓ | 2f ↑ | L ↓ | 2f ↑ | L ↓ | 2f ↑ | |
| ω = 1.0 | 1.42 | 29.41 | 0.92 | 25.22 | 1.16 | 32.65 | 1.07 | 28.24 |
| ω = 1.5 | 1.40 | 26.58 | 0.98 | 23.52 | 1.15 | 32.79 | 1.10 | 26.95 |
| ω = 2.0 | 1.53 | 21.99 | 1.09 | 21.32 | 1.21 | 31.46 | 1.20 | 24.65 |
关键结论:ω值增大,LSD-HF(与参考的谱失真)变差,但感知上高频更丰富(如图4(g)所示);ω值减小则相反。ω=1.5是一个平衡点。
⚖️ 评分理由
- 学术质量:6.0/7:论文工作扎实,创新点清晰(去vocoder,流匹配应用于频谱修复),方法完整,实验充分(多数据集、多指标、消融、主观听感),结果具有说服力。扣分点在于模型架构是现有组件的合理组合,原创性未达到顶尖水平。
- 选题价值:1.5/2:音频超分辨率是持续的研究热点,本文提出的统一、高效框架具有明确的应用价值和工程吸引力。但该任务本身属于信号处理中的经典问题,非新兴前沿方向。
- 开源与复现加成:0.8/1:提供了代码仓库和Demo,模型细节清晰,复现友好度高。未公开训练数据和模型权重,且训练硬件未说明,是主要的扣分项。