📄 Understanding the Strengths and Weaknesses of SSL Models for Audio Deepfake Model Attribution
#音频深度伪造检测 #自监督学习 #语音合成
✅ 7.0/10 | 前50% | #音频深度伪造检测 | #自监督学习 | #语音合成
学术质量 7.0/7 | 选题价值 1.2/2 | 复现加成 0.3 | 置信度 中
👥 作者与机构
- 第一作者:Gabriel Pîrlogeanu(POLITEHNICA Bucharest大学,Speech and Dialogue Research Laboratory)
- 通讯作者:未说明(论文未明确指定通讯作者)
- 作者列表:Gabriel Pîrlogeanu(POLITEHNICA Bucharest大学,Speech and Dialogue Research Laboratory)、Adriana Stan(POLITEHNICA Bucharest大学 Speech and Dialogue Research Laboratory 及 Technical University of Cluj-Napoca Communications Department)、Horia Cucu(POLITEHNICA Bucharest大学,Speech and Dialogue Research Laboratory)
💡 毒舌点评
亮点在于其严谨的控制变量实验设计,像“实验室”一样剖析了SSL特征在音频归因任务中的敏感点,尤其是“零初始化检查点”的验证为“模型架构指纹”的存在提供了有趣证据;短板是研究停留在对已有方法的分析与验证,未提出更强的归因模型或更鲁棒的特征,且对更复杂的实际场景(如多说话人、商业系统)测试不足,结论的普适性有待验证。
🔗 开源详情
- 代码:论文中未提及自有归因系统或实验代码的开源仓库链接。但承诺提供训练模型和生成数据。
- 模型权重:论文中明确说明将提供所有从头训练的TTS模型检查点和说话人适应后的模型权重(upon request)。
- 数据集:论文中使用了公开的LJSpeech数据集和HiFi-TTS的部分数据。生成的跨架构、跨检查点音频样本集承诺提供。
- Demo:未提及。
- 复现材料:提供了详细的训练配置(单卡T4,batch size 32,迭代次数)、超参数选择过程(k值选择)、评估协议(数据划分比例)。论文依赖的开源项目(FastPitch, VITS, Grad-TTS, Matcha-TTS, HiFi-GAN)均提供了官方代码和预训练模型链接。
- 论文中引用的开源项目:
- TTS架构:FastPitch [11], VITS [12], Grad-TTS [13], Matcha-TTS [14]
- 声码器:HiFi-GAN [15](及NGC预训练版本)
- SSL模型:wav2vec2-xls-r-2b, w2v-bert-2.0 (论文中未提及具体代码库,但为Hugging Face等平台标准模型)
- 数据集:LJSpeech [10], HiFi-TTS (部分)
📌 核心摘要
- 要解决什么问题:现有音频深度伪造检测研究多聚焦于二分类(真/假),而用于法律问责的“模型归因”(识别生成该音频的具体系统/模型)更具挑战性,尤其是当生成模型更新、重训练时,归因系统的鲁棒性尚不明确。
- 方法核心是什么:作者系统性地利用自监督学习(SSL)模型(wav2vec2-xls-r-2b 和 w2v-bert-2.0)提取音频特征,并搭配简单的kNN分类器,构建了一个轻量级的归因系统。通过严格控制变量(模型检查点、文本提示、声码器、说话人身份),对四个主流TTS架构(FastPitch, VITS, Grad-TTS, Matcha-TTS)进行受控实验,以剖析SSL特征的归因能力及其弱点。
- 与已有方法相比新在哪里:与以往利用复杂DNN分类器或未控制变量的归因研究不同,本文的核心创新在于实验设计的系统性:1) 从头训练并保存多个阶段的模型检查点;2) 显式隔离并操控文本、声码器、说话人等关键变量;3) 首次对比分析了两个不同SSL模型在归因任务上的互补特性;4) 探索了模型随机初始化对归因的影响。
- 主要实验结果如何:实验结果表明:a) 在域内(ID)任务中,架构级归因非常准确(F1
0.98),但检查点级归因较难(F10.5);b) 文本提示对检查点归因影响显著;c) 声码器匹配对归因至关重要,跨声码器归因性能骤降;d) 说话人微调会严重干扰归因,其中w2v-bert-2.0因预训练数据更多而更鲁棒;e) 未训练的“零初始化”模型输出噪声,但能被完美归类到各自架构类别。关键数据见表1。
表1:不同条件下模型归因的宏F1分数(关键部分)
| 实验条件 | 查询集检查点 | 提示词划分 | 声码器类型 | wav2vec2-xls-r-2b (检查点/架构) | w2v-bert-2.0 (检查点/架构) |
|---|---|---|---|---|---|
| 1. 基线 (域内) | PT+9个检查点 | 不相交 | 默认 | 0.519 / 0.976 | 0.450 / 0.983 |
| 5. 依赖文本提示 | PT+9个检查点 | 混合 | 默认 | 0.432 / 0.973 | 0.367 / 0.978 |
| 6. 依赖声码器 (同) | PT+9个检查点 | 不相交 | 统一 | 0.504 / 0.941 | 0.436 / 0.943 |
| 7. 依赖声码器 (异) | PT+9个检查点 | 不相交 | 混合 | n/a / 0.634 | n/a / 0.551 |
| 9. OOD (仅PT归因) | 微调模型 | 不相交 | 默认 | n/a / 0.361 | n/a / 0.657 |
| 11. 零初始化 (ID) | 零初始化 | 不相交 | 默认 | 0.874 / 1.000 | 0.859 / 1.000 |
| 12. 零初始化归因PT+9 | PT+9个检查点 | 不相交 | 默认 | n/a / 0.100 | n/a / 0.100 |
(表1数据来自论文Table 1,展示了多个关键实验的结果对比。)
- 实际意义是什么:本研究为基于SSL的音频深度伪造归因系统提供了重要的鲁棒性指南:a) 架构级归因可靠;b) 检查点级归因易受内容、声码器、说话人变化影响;c) 部署时需考虑文本和声码器的多样性;d) 不同SSL模型可互补。这有助于设计更可靠的数字取证工具。
- 主要局限性是什么:a) 实验局限于四种TTS架构和一个单说话人数据集(LJSpeech),未测试多说话人、零样本克隆、多实现等更复杂场景;b) 声码器变化实验(表1行7)结论不明确;c) 仅分析了特征层面,未提出提升归因鲁棒性的新方法;d) 对“零初始化”实验的解释(模型未见过噪声数据)略显牵强。
🏗️ 模型架构
本文的核心并非提出一个全新的复杂模型,而是分析和验证一个由SSL特征提取器与简单分类器组成的现有归因系统的特性。其架构流程如下:
- 输入:由不同TTS系统生成的音频波形。
- 特征提取:使用预训练的SSL模型(wav2vec2-xls-r-2b 或 w2v-bert-2.0)处理音频。论文指出,他们使用SSL模型特定层(wav2vec2第8层,w2v-bert第4层)的输出。
- 特征聚合:对提取的帧级特征进行时域平均池化,得到一个固定维度的向量(wav2vec2为1920维,w2v-bert为1024维),作为整个音频样本的表示。
- 归因分类器:使用一个k-近邻(kNN)分类器。在支持集中存储已知音频片段的特征向量及其对应的类别(检查点或架构)。对于查询音频,计算其特征向量与支持集中所有向量的距离,选择最近的k个邻居,通过多数投票确定其类别。
- 输出:预测的音频来源类别(具体检查点或所属架构)。
关键设计选择:选择kNN而非更复杂的深度神经网络(DNN)作为分类器,是为了优先分析SSL特征本身的判别力,避免分类器的复杂性干扰对特征的洞察。这是一个重要的方法论选择。
💡 核心创新点
- 控制变量实验范式的建立:针对深度伪造归因研究难以控制生成条件的问题,本文建立了一套从头训练、保存多阶段检查点、并严格操控文本、声码器、说话人等变量的实验流程。这为系统分析任何归因特征的鲁棒性提供了方法论模板。
- 对SSL特征“指纹”敏感性的全面剖析:系统性地量化了文本内容、声码器类型、说话人身份、模型训练阶段等多种扰动对基于SSL的归因性能的影响,揭示了其优势(架构归因稳定)和弱点(检查点归因脆弱、对跨系统变化敏感)。
- SSL模型间特性的对比与互补发现:首次在归因任务上对比了两个大型SSL模型(wav2vec2, w2v-bert),发现它们具有非重叠的弱点(如w2v-bert更受文本影响但对说话人更鲁棒),为通过特征融合提升鲁棒性提供了思路。
- “零初始化”检查点验证实验:一个巧妙的控制实验,证明了即使是未训练模型产生的噪声音频,其输出也被SSL特征捕获了明确的“架构固有偏差”,为模型归因的理论基础提供了有趣证据。
🔬 细节详述
- 训练数据:
- 主数据集:LJSpeech(单说话人女性,24小时)。用于训练所有TTS模型和生成评估音频。
- 声码器微调数据:HiFi-TTS speaker 9136的500个样本,用于说话人适应实验。
- 音频生成:使用600个固定的文本提示,分别由四种TTS架构生成音频。
- 损失函数:未在论文中详细说明。论文重点在于分析,而非提出新损失。
- 训练策略:
- TTS模型训练:每个架构在LJSpeech上从头训练500k次迭代。保存早期(50k,75k,100k)、中期(250k,275k,300k)和后期(450k,475k,500k)共9个检查点,加上官方预训练检查点,共10个。
- 声码器微调(说话人适应):在预训练模型基础上,使用500样本微调10k次迭代。
- SSL归因系统:使用kNN,最优邻居数k在验证集上选择,最终固定为k=56。
- 关键超参数:
- TTS训练:统一硬件(单块NVIDIA T4 GPU),批大小32,其他参数使用各架构官方默认设置。
- kNN:邻居数k。
- 训练硬件:单块NVIDIA T4 GPU(用于TTS模型训练)。SSL特征提取的硬件未说明。
- 推理细节:未说明。TTS推理使用默认设置生成音频。归因推理即kNN分类。
- 正则化或稳定训练技巧:未说明。使用各TTS架构的默认训练设置。
📊 实验结果
论文的主要贡献体现在其详尽的实验结果中,尤其是表1和图2。
主要基准与指标:宏F1分数(Macro F1-score),在40个类别(4架构*10检查点)上评估。
关键实验结果(基于表1和正文):
- 基线性能(域内):架构归因非常准(~0.98),检查点归因较难(~0.5),但远超随机水平(0.025)。VITS的检查点更容易区分(图2)。
- 跨域(OOD)归因:当支持集和查询集无共同检查点时,架构归因性能下降,但仍保持在较高水平(0.86-0.97)。增加支持集检查点多样性可提升性能。
- 文本提示依赖性:当提示词在支持/查询集间混合时,检查点归因性能显著下降(wav2vec2: 0.519→0.432),但架构归因几乎不变。表明SSL特征捕获了大量语言内容信息。
- 声码器依赖性:
- 使用相同声码器(表1行6):性能轻微下降。
- 使用混合声码器(表1行7):架构归因严重下降(wav2vec2: 0.976→0.634),表明SSL特征对声码器差异极为敏感。
- 说话人依赖性:用新说话人微调模型后,若支持集无该说话人样本,架构归因性能暴跌(表1行9/10)。w2v-bert-2.0(0.657)比wav2vec2(0.361)更鲁棒。微调模型常被归因到早期检查点或跨架构错误(如Grad-TTS→Matcha-TTS)。
- 零初始化实验:未训练模型(输出噪声)在架构归因上达到完美F1=1.0,但用这些噪声模型去归因正常训练模型则完全失败(F1=0.1),验证了架构固有偏差的存在。
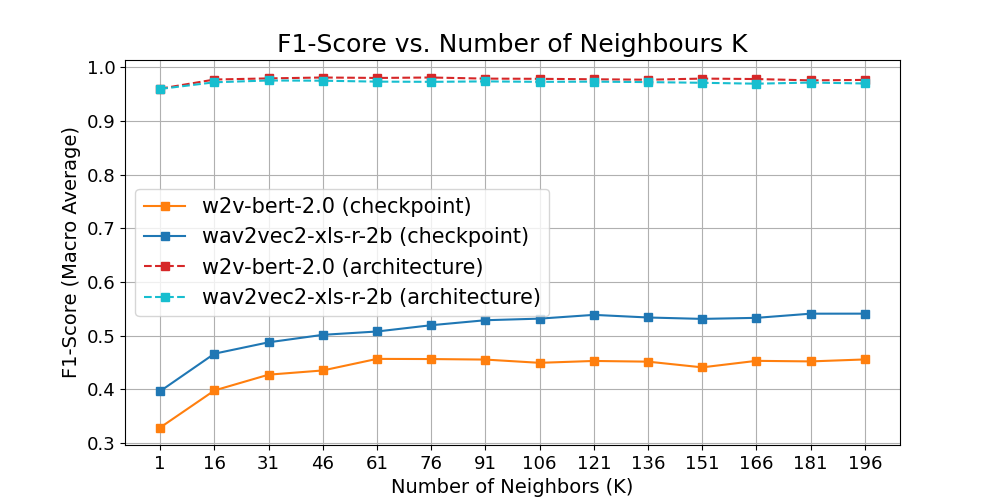 图1显示,随着邻居数k增加,检查点归因和架构归因的F1分数均先上升后趋于平稳。架构归因性能在两个SSL模型间差异不大,而wav2vec2在检查点归因上持续优于w2v-bert。
图1显示,随着邻居数k增加,检查点归因和架构归因的F1分数均先上升后趋于平稳。架构归因性能在两个SSL模型间差异不大,而wav2vec2在检查点归因上持续优于w2v-bert。
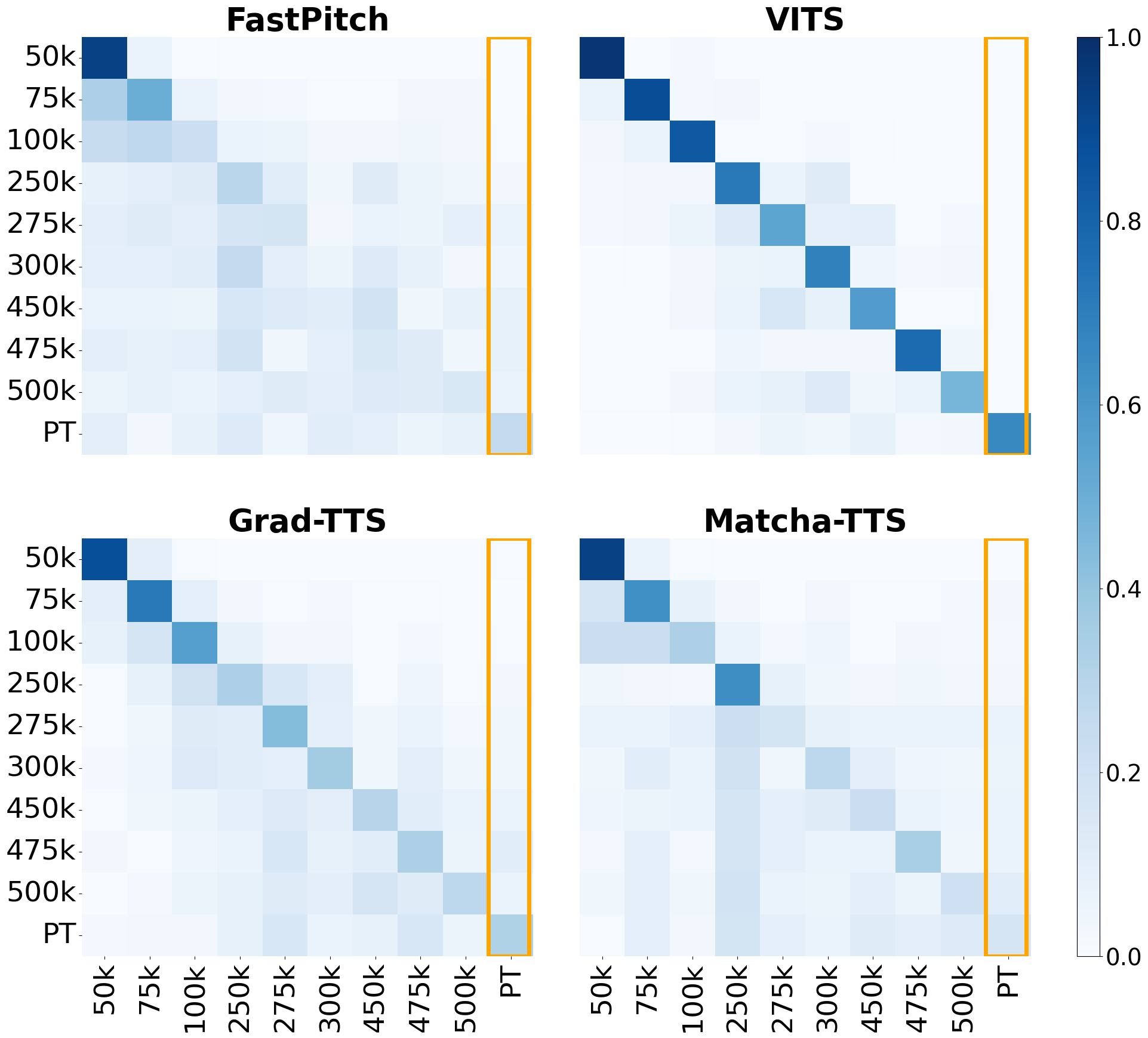 图2展示了40个检查点间的归因混淆矩阵。对角线颜色越深表示归因正确率越高。可见VITS的检查点(右侧块)整体区分度较好,而FastPitch等架构在后期检查点间混淆增多。跨架构的混淆非常少。
图2展示了40个检查点间的归因混淆矩阵。对角线颜色越深表示归因正确率越高。可见VITS的检查点(右侧块)整体区分度较好,而FastPitch等架构在后期检查点间混淆增多。跨架构的混淆非常少。
⚖️ 评分理由
- 学术质量:6.0/7:论文逻辑清晰,实验设计严谨且富有洞察力,控制变量的方法值得借鉴。结论基于大量数据,可信度高。扣分点在于创新性更多体现在分析角度而非方法突破,部分实验(如声码器混合)结论待深入挖掘。
- 选题价值:1.2/2:音频深度伪造归因是重要的安全课题,论文对其核心方法(SSL特征)进行了深度剖析,对学界和工业界均有明确的参考价值。但归因本身是一个相对细分的子任务。
- 开源与复现加成:0.3/1:论文明确承诺提供训练好的模型和生成的音频数据集,并详细列出了所有依赖的开源TTS/声码器项目及其官方链接。实验环境(GPU、batch size)描述清晰。扣分是因为未提供自身归因系统(如特征提取、kNN代码)的完整代码仓库。