📄 Uncertainty-Aware 3D Emotional Talking Face Synthesis with Emotion Prior Distillation
#音视频 #生成模型 #不确定性估计 #多模态模型
🔥 8.0/10 | 前25% | #音视频 | #生成模型 | #不确定性估计 #多模态模型
学术质量 6.2/7 | 选题价值 1.8/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Nanhan Shen(天津大学人工智能学院)
- 通讯作者:Zhilei Liu(天津大学人工智能学院)
- 作者列表:Nanhan Shen(天津大学人工智能学院)、Zhilei Liu(天津大学人工智能学院)
💡 毒舌点评
这篇论文精准地指出了3D情感说话人脸生成中“情感对齐差”和“多视图融合粗糙”两大痛点,并给出了模块化的解决方案,特别是首次引入不确定性建模来优化融合策略,思路值得肯定。然而,论文在工程实践上“留白”过多,关键代码和训练细节缺失,使得这个“不确定性”的黑盒更难被学界复现和验证。
🔗 开源详情
- 代码:论文中未提及代码链接。仅提供项目页面,内容未知。
- 模型权重:未提及公开权重。
- 数据集:使用了公开数据集(AD-NeRF, MEAD),但论文未说明是否提供处理后的数据或获取指引。
- Demo:未提及在线演示。
- 复现材料:给出了部分训练细节(迭代次数、损失权重、优化器选择),但缺少模型具体架构参数、完整训练配置、环境依赖、检查点等。论文中未提及开源计划。
- 论文中引用的开源项目:引用了多个开源项目作为基线或组件,如TalkingGaussian [5]、DEGSTalk [30]、EDTalk [22]、StableAvatar [31]、SadTalker [15]、Wav2Vec 2.0 [16]等。
📌 核心摘要
- 问题:现有3D情感说话人脸合成方法存在两大挑战:音视觉情感对齐差(难以从音频提取情感且微表情控制弱);多视图融合采用“一刀切”策略,忽略了不同视图特征质量的不确定性,导致渲染效果受损。
- 方法:提出UA-3DTalk框架,以3D高斯溅射为渲染骨干。其包含三个核心模块:先验提取模块,将音频解耦为内容同步特征和个性特征;情感蒸馏模块,通过多模态注意力融合和4D高斯编码,实现细粒度音频情感提取与表情控制;基于不确定性的变形模块,为每个视图估计偶然不确定性和认知不确定性,实现自适应多视图融合。
- 创新:首次在该领域系统性地建模并利用不确定性;提出不确定性感知的自适应融合策略;通过情感先验蒸馏协同解决情感对齐问题。
- 结果:在常规和情感数据集上的实验表明,UA-3DTalk在情感对齐(E-FID)、唇同步(SyncC)和渲染质量(LPIPS)上均优于SOTA方法。定量结果如下:
| 方法 | 数据集 | LMD↓ | PSNR↑ | LPIPS↓ | SSIM↑ | Sync-C↑ | E-FID↓ |
|---|---|---|---|---|---|---|---|
| UA-3DTalk (本文) | 常规/情感 | 2.492 / 5.407 | 28.923 / 28.408 | 0.032 / 0.067 | 0.928 / 0.938 | 5.750 / 5.152 | 0.072 / 0.145 |
| DEGSTalk | 常规/情感 | 1.960 / 3.923 | 27.104 / 28.051 | 0.042 / 0.162 | 0.891 / 0.924 | 5.663 / 5.007 | 0.076 / 0.154 |
| EDTalk | 常规/情感 | 3.827 / 6.548 | 25.627 / 18.061 | 0.073 / 0.297 | 0.888 / 0.864 | 6.173 / 7.550 | 0.483 / 0.668 |
| TalkingGaussian | 常规/情感 | 3.018 / 5.934 | 26.943 / 25.533 | 0.045 / 0.096 | 0.906 / 0.892 | 5.011 / 4.886 | 0.089 / 0.356 |
| StableAvatar | 常规/情感 | 4.117 / 7.150 | 18.403 / 19.290 | 0.258 / 0.228 | 0.480 / 0.619 | 4.421 / 3.972 | 0.546 / 0.430 |
消融研究(在MEAD情感数据集)显示,各模块均带来性能提升:完整模型(w/ P,E,U)相比基线,在E-FID上从0.356降至0.145,Sync-C从4.886提升至5.152。

- 实际意义:推动了更自然、可控的情感数字人生成技术发展,可应用于虚拟助手、影视特效、在线教育等场景。
- 局限性:未提供代码和完整训练细节,复现难度高;不确定性建模的计算开销和实际收益的权衡分析不足;情感蒸馏模块对不同音频的鲁棒性有待更广泛验证。
🏗️ 模型架构
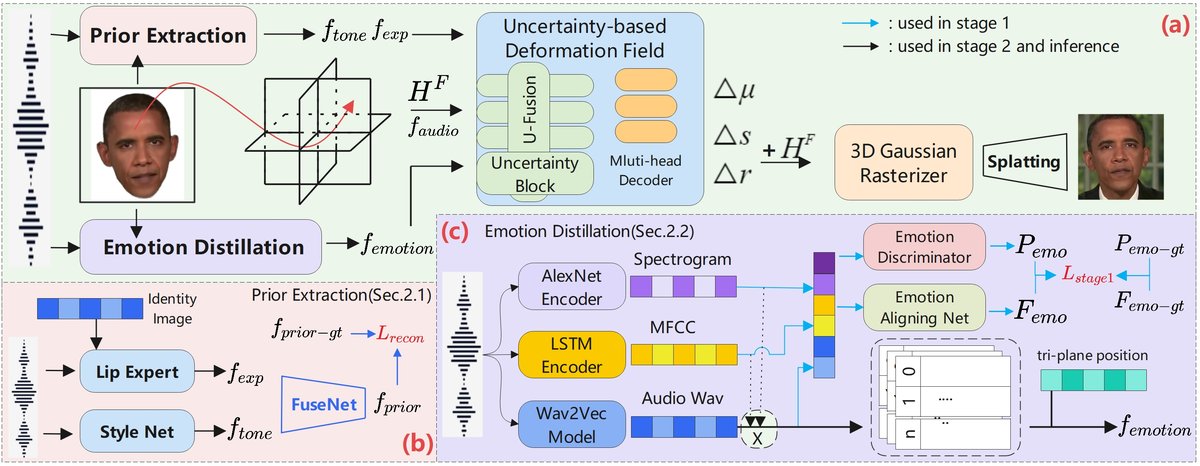
UA-3DTalk的整体架构(图1(a))是一个基于3D高斯溅射(3DGS)的端到端渲染流程。输入为单张人物图像和一段音频,输出为与之同步的动态人脸视频。模型将头部建模为一组静态高斯原语(点云),通过预测每个原语的变形场(位置、缩放、旋转)来生成动态帧。
主要组件与数据流:
- 先验提取模块(图1(b)):处理输入的图像和音频,生成两个关键特征:
- 内容同步特征 (fexp):通过训练唇部专家模型生成唇部运动图像,再经3D先验提取子模块获得,确保音视觉内容对齐。
- 个性互补特征 (ftone):通过基于StyleNet的音频编码器从音频中提取,用于保持说话人身份特征。 两者融合后生成重建的3D面部先验特征(fgen-exp),受重构损失监督。
- 情感蒸馏模块(图1(c)):专注于从音频中提取情感信息,生成情感特征(femotion)。
- 提取组件:将原始音频预处理为频谱图、MFCC和音频波形三种特征。利用AlexNet处理频谱图、LSTM处理MFCC,二者作为注意力键,对音频波形特征进行加权,得到情感感知特征。该组件先在IEMOCAP情感数据集上预训练,再在目标数据集上微调。
- 编码组件:为解决高维情感特征无法直接进行平面网格化的问题,采用多分辨率码本进行离散化,并用Hadamard积替代拼接,最终编码为(femotion)。
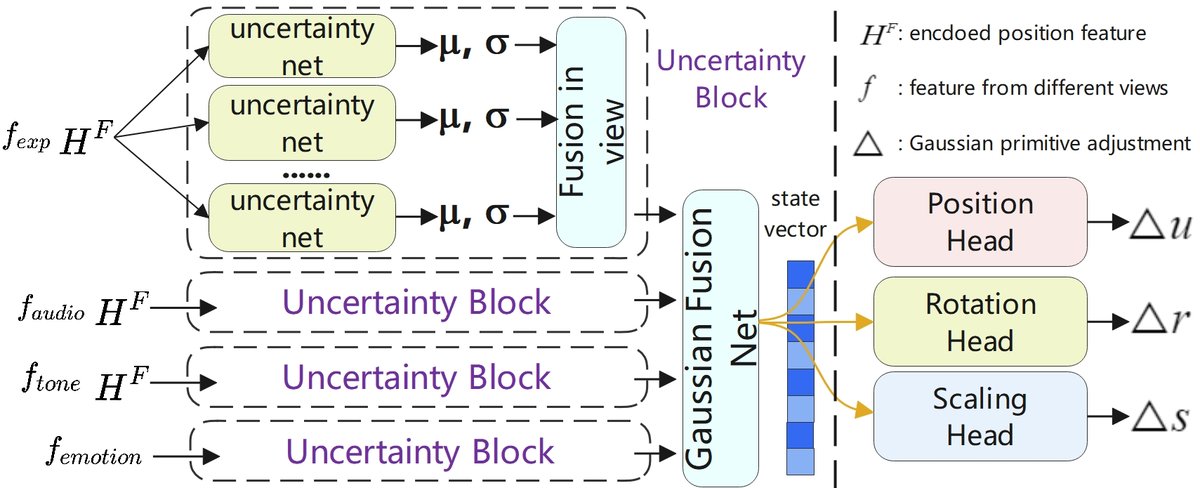
- 基于不确定性的变形模块(图2):核心融合与解码单元。
- 不确定性感知特征融合:为每个特征视图(包括fexp, ftone, femotion等)部署一个不确定性块,该块包含多个不确定性网络。每个网络预测该视图状态向量的均值(μ)和方差(σ),从而分别估计偶然不确定性(AU,来自输入噪声) 和认知不确定性(EU,来自模型参数,通过蒙特卡洛采样近似)。最终,各视图的不确定性(σ⁻¹)作为权重,对它们的预测均值(μ)进行高斯融合,得到最终融合的状态向量。不确定性越高,视图权重越低。
- 多头高斯变形解码器:将融合后的状态向量解码为对静态高斯原语的修改量(Δμ, Δr, Δs),分别调整其位置、旋转和缩放。
- 渲染:使用高斯光栅化器,根据优化后的高斯原语参数渲染出动态面部帧。
分支设计:模型分为面部和嘴部分支。面部支路处理全部特征以生成丰富的表情;嘴部分支排除了情感特征(femotion),且变形场仅输出位置修改量(Δμ),专注于精确的唇部同步。
💡 核心创新点
- 首次在说话人脸生成中系统建模不确定性:针对多视图融合中特征质量不一的问题,创新性地引入不确定性估计(AU和EU),并依据“不确定性高则权重低”的原则进行自适应融合,取代了固定的“一刀切”拼接方式,提升了渲染的鲁棒性和质量。
- 基于不确定性感知的自适应多视图融合策略:设计了包含多个网络的不确定性块来量化每个视图的不确定性,并据此动态计算融合权重,使模型能够优先利用可靠的信息源,改善了最终渲染的细节和一致性。
- 情感先验蒸馏模块:结合先验提取(解决内容同步与个性化)和情感蒸馏(解决细粒度情感提取与控制)两个子模块,协同解决音视觉情感对齐的核心挑战。情感蒸馏模块通过多模态(频谱图、MFCC、波形)注意力机制和多分辨率码本编码,实现了对音频情感更精细的捕捉和对微表情的精确控制。
🔬 细节详述
- 训练数据:
- 常规说话人脸数据集:采用AD-NeRF数据集中的Obama和May子集,视频为256×256分辨率,25 FPS。
- 情感说话人脸数据集:采用MEAD数据集中的M003和M030子集,视频为512×512分辨率,30 FPS。
- 预处理:遵循了NERF-3DTalker和相关工作的流程,对MEAD数据集采用了人脸窗口裁剪方法以减少背景和相机运动干扰。
- 损失函数:
- 先验提取模块重构损失 (Lrecon):fgen-exp与GT特征的L2距离(公式4)。
- 情感蒸馏模块微调损失 (Lstage2):情感标签的交叉熵损失与预测情感特征femo与GT情感特征femo的L2损失之和(公式5)。
- 变形模块训练损失:
- 分支训练损失 (LD):渲染图Irender与遮罩图Imask的L1损失加SSIM损失(公式13)。
- 联合微调损失 (LF):融合输出Ifuse与GT图Ĩ的L1损失加SSIM损失加LPIPS感知损失(公式14)。超参数λ=0.5,γ=0.2。
- 训练策略:
- 两阶段训练:阶段1,分别训练先验提取模块和预训练情感蒸馏模块;阶段2,先分别训练面部和嘴部分支的变形模块(50,000次迭代),再联合微调10,000次迭代。
- 优化器:使用了Adam和AdamW优化器。
- 不确定性估计:每个不确定性块使用T=10个网络进行蒙特卡洛采样以近似认知不确定性(公式9)。
- 关键超参数:
- 面部/嘴部分支迭代次数:50,000。
- 联合微调迭代次数:10,000。
- 损失权重:λ=0.5, γ=0.2。
- 蒙特卡洛采样次数T=10。
- 情感特征编码使用的基础分辨率为64,多分辨率尺度s∈{1,2,4}(公式6)。
- 高斯融合公式(公式12):μ = (Σᵢ σᵢ⁻¹ μᵢ) / (Σᵢ σᵢ⁻¹), Σ = (Σᵢ σᵢ⁻¹)⁻¹。
- 训练硬件:未说明。
- 推理细节:论文未提及推理阶段的特定解码策略或温度设置。
- 正则化或稳定训练技巧:在特征编码中用Hadamard积替代拼接以保留高维信息,避免维度爆炸(公式6,参考[19])。
📊 实验结果
论文在常规和情感两个数据集上进行了广泛实验,并与4个SOTA方法进行了定量比较(Table 1)。指标涵盖几何精度(LMD)、图像质量(PSNR, LPIPS, SSIM)、唇同步(Sync-C)和情感对齐(E-FID)。
主要对比实验结果(完整表格见“核心摘要”部分):
- 情感对齐 (E-FID↓):在情感数据集上,UA-3DTalk(0.145)显著优于次优的DEGSTalk(0.154)和EDTalk(0.668),相对EDTalk提升约78%,相对DEGSTalk提升约5.8%。在常规数据集上也达到最优(0.072)。
- 唇同步 (Sync-C↑):在情感数据集上(5.152)优于DEGSTalk(5.007);在常规数据集上(5.750)与最优的EDTalk(6.173)差距不大,但EDTalk依赖参考视频,而本方法为纯音频驱动。
- 渲染质量 (LPIPS↓):在常规和情感数据集上均取得最优(0.032 / 0.067),显著优于其他方法。
- 其他:在SSIM、PSNR上表现优秀,LMD略逊于DEGSTalk(但后者使用了GT 3DMM参数)。
消融实验结果(Table 2,MEAD情感数据集):
| 模块配置 | LMD↓ | PSNR↑ | LPIPS↓ | SSIM↑ | Sync-C↑ | E-FID↓ |
|---|---|---|---|---|---|---|
| Baseline | 5.934 | 25.53 | 0.096 | 0.892 | 4.886 | 0.356 |
| w/ P | 5.878 | 28.03 | 0.069 | 0.931 | 4.973 | 0.203 |
| w/ E | 5.872 | 25.52 | 0.095 | 0.894 | 4.897 | 0.312 |
| w/ P, U | 5.691 | 28.30 | 0.068 | 0.935 | 5.010 | 0.178 |
| w/ P, E, U | 5.407 | 28.40 | 0.067 | 0.938 | 5.152 | 0.145 |
- 先验提取(P)模块大幅提升几乎所有指标,尤其是E-FID从0.356降至0.203,证明其对音视觉对齐和身份保持的关键作用。
- 情感蒸馏(E)模块单独使用时对E-FID有改善(0.312),与P结合(w/ P, E, U)后效果最佳,表明其对情感微表情控制有贡献。
- 基于不确定性的变形(U)模块在P的基础上引入后(w/ P, U),进一步稳定提升了渲染质量(LPIPS从0.069降至0.068,E-FID从0.203降至0.178),验证了自适应融合策略的有效性。
- 完整模型(w/ P, E, U)在所有指标上达到最优,证明了三个模块的协同增益。
定性结果(Fig. 3):可视化对比显示,UA-3DTalk在唇部运动准确性、眼部动作自然度和情感相关的表情预测(如微笑、惊讶)方面优于对比方法。
⚖️ 评分理由
- 学术质量:6.2/7:论文问题定位准确,提出的模块化解决方案逻辑清晰,技术路线合理(结合3DGS、注意力融合、不确定性建模)。实验设计比较全面,包含定量对比和消融实验,数据和结果可信。主要不足在于部分技术细节(如不确定性网络的具体结构、码本的具体实现)描述不够深入,且缺乏对方法局限性(如计算开销)的深入分析。
- 选题价值:1.8/2:情感说话人脸生成是当前人机交互和数字人领域的热点,具有明确的应用前景。论文直接面向音频-视觉跨模态生成任务,与语音处理(情感识别、唇同步)紧密相关。
- 开源与复现加成:0/1:论文虽然提供了项目页链接(
https://mrask999.github.io/UA-3DTalk/),但未在正文或附录中提供代码、预训练模型、训练脚本、详细超参数配置等关键复现信息,极大地限制了该工作的可复现性和社区跟进。