📄 UJCodec: An End-to-end Unet-Style Codec for Joint Speech Compression and Enhancement
#语音增强 #端到端 #低资源 #实时处理 #语音大模型
✅ 7.5/10 | 前25% | #语音增强 | #端到端 | #低资源 #实时处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Pincheng Lu(北京理工大学)
- 通讯作者:未说明
- 作者列表:Pincheng Lu(北京理工大学)、Peng Zhou(北京理工大学)、Xiaojiao Chen(北京理工大学)、Jing Wang(北京理工大学)、Zhong-Qiu Wang(南方科技大学)
💡 毒舌点评
这篇论文的亮点在于其“问题导向”的设计非常清晰:用UNet的跳跃连接对抗传统编解码器的信息丢失(这是字词遗漏的元凶之一),再用精心设计的三阶段训练“教会”模型先学压缩、再学抗噪、最后适应,思路流畅且有效。然而,短板也很明显:论文声称解决了“字词遗漏”问题,但模拟潜在帧损坏的策略相对简单(随机替换帧),可能无法覆盖所有真实的、复杂的编码器错误模式;此外,实验部分缺乏与更多最新、更强基线(如近期基于扩散或流匹配的增强模型)的正面比较,说服力稍弱。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开预训练模型。
- 数据集:论文使用了多个公开数据集(LibriTTS, VCTK, AISHELL-3, VoiceBank+DEMAND, DNS-Challenge),但未说明是否会发布处理好的实验数据集。
- Demo:论文提供了在线演示页面链接:https://ukitenzai.github.io/UJCodec.demopage。
- 复现材料:论文给出了一些训练细节,如各阶段迭代数、批次大小、损坏模拟参数,但缺失关键信息如完整的学习率调度、优化器、模型具体超参数(层数、维度等)。
- 论文中引用的开源项目:依赖的开源工作/模型包括:SoundStream, DAC, L3AC, FSQ, MP-SENet, GTCRN, Whisper-tiny(用于WER计算)。
📌 核心摘要
- 问题:现有端到端神经语音编解码器通常在干净语音上训练,导致其在噪声环境下性能下降,且解码语音常出现严重的“字词遗漏”失真,极大影响可懂度。
- 方法核心:提出UJCodec,一种采用UNet风格架构(包含跳跃连接)的端到端联合语音压缩与增强模型。核心是一个三阶段训练策略:(1) 在干净语音上训练基础编解码器;(2) 仅对编码器进行对齐微调,使其从噪声语音生成接近干净语音的离散表示;(3) 固定编码器,微调解码器以适应新的表示分布。此外,在训练后期引入“潜在帧损坏模拟”,增强解码器对编码器错误的鲁棒性。
- 创新:(1) 将UNet架构引入语音编解码器,利用跳跃连接保留关键细节;(2) 设计了分阶段、逐步增强鲁棒性的训练策略,而非直接在噪声数据上端到端训练;(3) 明确针对字词遗漏问题,提出训练时的潜在帧损坏模拟方法。
- 主要实验结果:在750bps至6kbps的比特率范围内,UJCodec在VoiceBank+DEMAND和DNS-Challenge数据集上的PESQ(感知语音质量评估)和WER(字错误率)均优于所比较的端到端和级联基线。例如,在750bps、噪声条件下,UJCodec的PESQ为1.793,WER为13.89%,优于SDCodec(1.626, 14.77%)和NRVRVQ(1.697, 14.68%)。主观MUSHRA和MOS评分也一致显示UJCodec优势,尤其在低比特率下。
- 实际意义:为低比特率、高噪声的实时语音通信场景(如工业、物联网、边缘设备)提供了一种高效且可懂度高的编解码方案,其模型效率(RTF<1)满足实时处理要求。
- 主要局限性:(1) 与SOTA基线的对比范围有限;(2) 潜在帧损坏模拟策略相对简单;(3) 训练细节(如完整学习率策略)公开不全,限制了完全复现。
🏗️ 模型架构
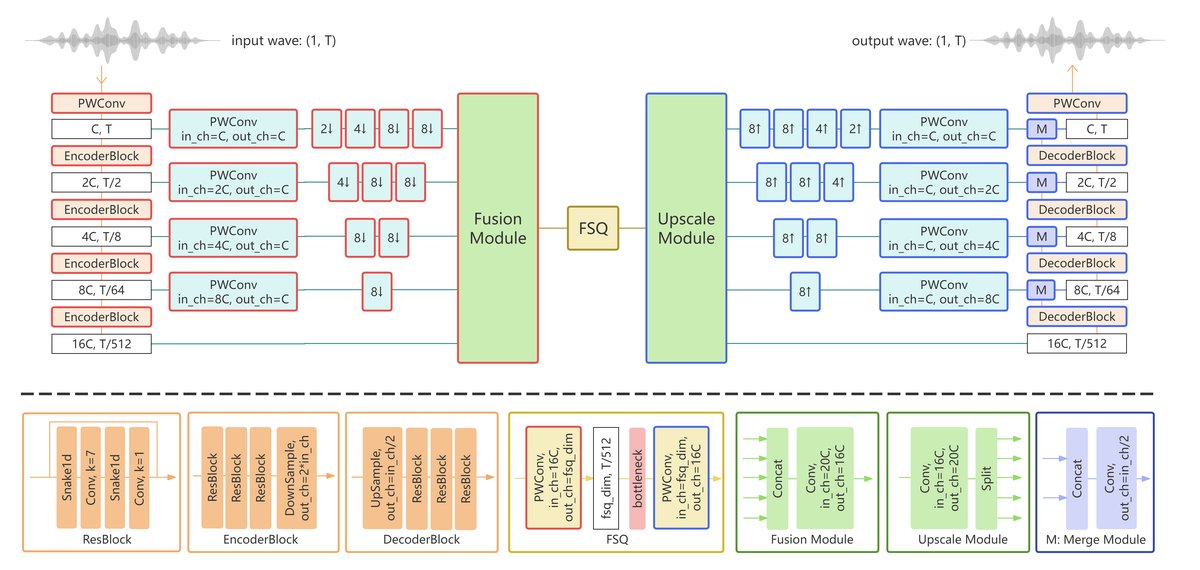
UJCodec采用端到端的编码器-量化器-解码器架构,并融入了UNet风格的跳跃连接。
- 整体输入输出:输入为含噪语音波形(或干净语音),输出为重建的(增强后的)语音波形。
- 编码器 (EN):其作用是逐步下采样输入语音,提取多尺度特征,并映射到低帧率的离散潜表示。结构上,它是一系列下采样层(如跨步卷积)和残差块的堆叠。图2中红色边框模块(EN)代表了第二阶段微调的对象。编码器包含一个融合模块(Fusion Module),用于融合不同尺度特征图的信息。
- 量化瓶颈 (Q(·)):采用有限标量量化(FSQ)。编码器输出的连续向量被投影到一个更低维空间,经
tanh缩放后,在一个均匀网格上进行量化(公式3)。FSQ相比残差向量量化(RVQ)能提供更稳定、更易于对齐的离散表示。 - 解码器 (DN):镜像编码器结构,通过上采样(如转置卷积)逐步恢复语音细节。其核心创新是使用了跳跃连接,将编码器对应层的多尺度特征图直接传递到解码器相应层。这种设计能有效保留低级语音细节和高级语义信息,有助于减轻编解码过程中的信息丢失和语音增强中的失真。图2中蓝色边框模块(DN)代表了第三阶段微调的对象。
- 数据流与交互:语音依次经过EN下采样生成多尺度特征,这些特征被融合后投影至量化空间,经FSQ离散化得到潜帧。解码器DN接收潜帧,并利用从EN通过跳跃连接传递来的多尺度特征图进行上采样,最终重建语音波形。整个过程中,跳跃连接在编码和解码的多个层级建立了直接的数据通道。
💡 核心创新点
- UNet风格语音编解码架构:是什么:在语音编解码器的编码器和解码器之间引入多尺度跳跃连接。局限:传统编码器-解码器(如SoundStream)在逐层下采样和上采样中容易丢失关键的语音细节,这在增强任务中会加剧字词遗漏。如何起作用:跳跃连接直接将编码器的底层特征(如共振峰、谐波结构)传递给解码器,辅助其在重建时保留更精细的语音结构。收益:消融实验显示,去除类似FSQ(代表更优量化)会降低PESQ并增加WER,间接证明了良好特征保留与量化对质量的重要性。
- 三阶段渐进式训练策略:是什么:(1) 干净语音基础训练;(2) 仅编码器对齐微调;(3) 仅解码器自适应微调。局限:直接在噪声数据上端到端训练整个编解码器,会导致噪声信息污染量化器和解码器,训练不稳定且收敛慢。如何起作用:第一阶段建立纯净的压缩能力。第二阶段固定解码器和量化器,强制编码器学习将噪声语音映射到干净语音的潜空间,任务专注且高效。第三阶段让解码器适应由新编码器生成的、略有不同的潜表示。收益:消融实验表明,去掉分阶段训练,模型性能大幅下降(PESQ降低0.126,WER增加0.37%),且需要更长的训练时间(约1.4倍)才能达到基线水平。
- 训练时潜在帧损坏模拟:是什么:在训练后期,随机将编码器输出的一部分潜帧替换为静音帧、噪声帧或同一语句其他位置的帧。局限:编码器可能因噪声误判而错误地删除语音成分,导致输出潜帧“损坏”,解码器对此类损坏缺乏鲁棒性,从而产生字词遗漏。如何起作用:通过主动在训练中引入类似的“损坏”模式,迫使解码器学习从不完整或受损的潜表示中恢复出完整的、可懂的语音。收益:消融实验显示,禁用该策略会导致明显的字词遗漏(WER增加0.83%),PESQ也下降。
🔬 细节详述
- 训练数据:
- Stage 1(基础训练):使用LibriTTS、VCTK、AISHELL-3的训练集,包含英文和中文干净语音。
- Stage 2 & 3(微调):使用VoiceBank+DEMAND和DNS-Challenge数据集。其中DNS-Challenge的噪声语音通过将干净语音与噪声库片段混合生成,信噪比(SNR)在-5 dB到20 dB之间均匀采样。所有数据下采样至16 kHz。
- 损失函数:
- Stage 1 & 3:使用与DAC [3] 相同的损失组合,包括重建损失(L1距离)、特征损失(多尺度判别器特征匹配)和对抗损失。因使用FSQ,无需承诺损失。
- Stage 2:仅使用编码器对齐损失(公式1):
\ell_a = E[ (EN(x_n) - Q(EC(x_c)))^2 ],即强制含噪输入经EN编码后的输出,接近干净输入经冻结编码器EC编码并量化后的结果。
- 训练策略:
- 迭代次数:Stage 1:150k;Stage 2:50k;Stage 3:50k。
- Batch Size:16。
- 硬件:单张RTX 4090 GPU。
- 学习率、优化器、调度策略:论文中未说明。
- 潜在帧损坏模拟细节:仅在Stage 1和Stage 3的最后20,000次迭代中应用。在前10,000次迭代中,替换比例从0逐渐增加到5%,之后固定为5%。替换类型在Stage 1为等概率的静音帧或同一语句其他帧;在Stage 3为更具挑战性的纯噪声帧或来自噪声语音的随机帧。
- 关键超参数:
- 比特率:通过调整FSQ的量化级数K实现,论文实验了750 bps, 3 kbps, 6 kbps。
- 模型大小、层数、隐藏维度:论文中未说明。
- 训练硬件:单张NVIDIA RTX 4090 GPU。
- 推理细节:论文未详细说明解码策略、温度、beam size等,但强调了模型支持实时处理,RTF在移动级CPU上测量。
- 正则化/稳定训练技巧:潜在帧损坏模拟作为一种数据增强技巧,用于稳定训练并提升模型鲁棒性。FSQ的使用本身也通过提供稳定的量化目标,有助于稳定第二阶段的对齐训练。
📊 实验结果
主要对比实验:论文在VoiceBank+DEMAND(噪声部分)和DNS-Challenge测试集上,对比了多种端到端和级联方案。
表1:联合语音压缩与增强性能的目标评估
| Model | Bitrate (bps) | Clean PESQ↑ | Noisy PESQ↑ | Noisy WER(%)↓ |
|---|---|---|---|---|
| UJCodec | 750 | 2.093 | 1.793 | 13.89 |
| SDCodec [8] | 750 | 1.786 | 1.626 | 14.77 |
| NRVRVQ [12] | 750 | 1.927 | 1.697 | 14.68 |
| G-L3AC [14, 4] | 750 | 1.894 | 1.556 | 16.24 |
| M-L3AC [15, 4] | 750 | 1.894 | 1.704 | 13.61 |
| G-DAC [14, 3] | 750 | 1.774 | 1.506 | 15.37 |
| M-DAC [15, 3] | 750 | 1.774 | 1.577 | 14.54 |
| UJCodec | 3k | 3.091 | 2.711 | 11.34 |
| SDCodec | 3k | 2.892 | 2.392 | 12.63 |
| NRVRVQ | 3k | 2.930 | 2.480 | 12.08 |
| G-L3AC | 3k | 2.853 | 2.293 | 13.17 |
| M-L3AC | 3k | 2.853 | 2.693 | 11.44 |
| G-DAC | 3k | 2.875 | 2.153 | 13.09 |
| M-DAC | 3k | 2.875 | 2.687 | 11.55 |
| UJCodec | 6k | 3.572 | 3.152 | 9.95 |
| SDCodec | 6k | 3.392 | 2.802 | 10.75 |
| NRVRVQ | 6k | 3.440 | 2.925 | 10.44 |
| G-L3AC | 6k | 3.428 | 2.663 | 11.04 |
| M-L3AC | 6k | 3.428 | 3.063 | 10.15 |
| G-DAC | 6k | 3.431 | 2.887 | 11.24 |
| M-DAC | 6k | 3.431 | 3.051 | 10.22 |
注:G-表示使用GTCRN增强,M-表示使用MP-SENet增强。
关键结论:在所有测试比特率下,UJCodec在干净和噪声条件下的PESQ以及噪声条件下的WER上均优于所有对比方法。优势在最低的750 bps比特率下最为显著。
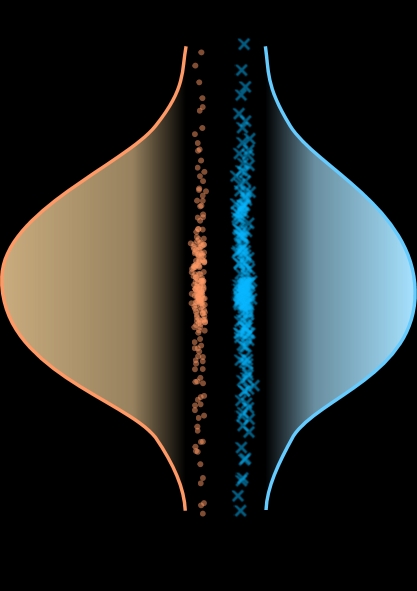 图5说明:左图为MUSHRA(干净语音质量),右图为MOS(噪声语音综合质量)。在750 bps、3 kbps、6 kbps下,UJCodec(红色)的分数均高于其他基线,与目标评估结论一致。
图5说明:左图为MUSHRA(干净语音质量),右图为MOS(噪声语音综合质量)。在750 bps、3 kbps、6 kbps下,UJCodec(红色)的分数均高于其他基线,与目标评估结论一致。
表2:消融实验结果 (基准为UJCodec@6kbps)
| Model | PESQ↑ | WER(%)↓ |
|---|---|---|
| baseline@6kbps | 3.152 | 9.95 |
| w/o FSQ (replaced by RVQ) | -0.232 | +0.27 |
| w/o stage-wise training | -0.126 | +0.37 |
| w/o corruption simulation | -0.058 | +0.83 |
关键结论:移除任何一项核心设计(FSQ量化器、三阶段训练、潜在帧损坏模拟)都会导致性能下降,其中对WER影响最大的是损坏模拟(+0.83%),对PESQ影响最大的是FSQ(-0.232)。
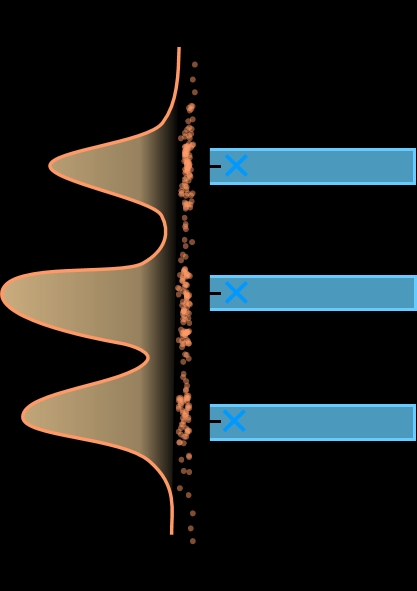 图6说明:在6 kbps下,横轴为实时因子(RTF,越低越快),纵轴为PESQ。圆圈大小代表参数量。UJCodec位于左上方(低延迟、高质量),在效率与质量的权衡上优于SDCodec、NRVRVQ及所有级联方法(右侧,延迟高)。红色竖线(RTF=1)左侧支持实时推理。
图6说明:在6 kbps下,横轴为实时因子(RTF,越低越快),纵轴为PESQ。圆圈大小代表参数量。UJCodec位于左上方(低延迟、高质量),在效率与质量的权衡上优于SDCodec、NRVRVQ及所有级联方法(右侧,延迟高)。红色竖线(RTF=1)左侧支持实时推理。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个设计精巧、针对性强的模型来解决具体问题(联合压缩增强与字词遗漏)。技术方案(UNet连接、三阶段训练、损坏模拟)合理且有效,实验设计较为全面,包含了多比特率对比、消融实验和主观评估。扣分点在于:1)与最新、最强SOTA的对比不够充分;2)部分关键训练超参数(如学习率、优化器)未公开,影响可复现性判断。
- 选题价值:1.5/2:联合语音压缩与增强是神经语音编解码器研究的前沿和关键方向,对提升真实场景下的低比特率通信质量具有重要价值。选题直接、明确,应用前景广阔。
- 开源与复现加成:0.5/1:论文提供了演示页面链接,增强了可信度。但未提供代码、模型权重和详细的训练配置,复现门槛较高。加成有限。