📄 Two-Stage Language Model Framework for Acoustic Echo Cancellation
#语音增强 #语音大模型 #生成模型 #鲁棒性
✅ 7.5/10 | 前25% | #语音增强 | #语音大模型 | #生成模型 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Kai Xie(西北工业大学,中国)(根据论文署名顺序推断)
- 通讯作者:未说明(论文中未明确指出)
- 作者列表:Kai Xie¹(西北工业大学,中国), Haoyang Li²(南洋理工大学,新加坡), Nana Hou³(独立研究者), Hexin Liu²(南洋理工大学,新加坡), Jie Chen¹(西北工业大学,中国)。上标数字对应论文脚注中的机构编号。
💡 毒舌点评
本文最大的亮点是将“语义”作为解决回声消除中“语音可懂度”问题的关键桥梁,设计了一个从语义到声学的两阶段生成框架,思路新颖且实验效果显著。但稍显遗憾的是,两个语言模型阶段独立训练,可能浪费了联合优化语义与声学表示的机会;此外,作为一个2026年的生成式工作,未开源模型与代码,对于追求快速复现的读者不太友好。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开模型权重。
- 数据集:使用公开的AEC-Challenge数据集(链接:https://github.com/microsoft/AEC-Challenge),但论文未说明具体的预处理或划分方式。
- Demo:未提及在线演示。
- 复现材料:提供了部分训练超参数(学习率、模型层数、隐藏维度、聚类数K),但缺失batch size、训练步数细节、完整优化器参数、硬件环境等关键信息。
- 论文中引用的开源项目/模型:
- WavLM(语义提取器):论文提及使用WavLM Large,并提供了GitHub链接 (https://github.com/microsoft/unilm/tree/master/wavlm)。
- 神经语音编解码器:基于论文[20],但未给出其具体开源仓库链接。
- 总结:论文中未提及完整的开源计划。
📌 核心摘要
这篇论文针对传统声学回声消除(AEC)方法主要操作于特征域、忽略语义信息从而限制语音可懂度与感知质量的问题,首次提出了一种基于语言模型的两阶段生成式AEC框架。其核心方法是:第一阶段(语义建模),通过语义融合模块(融合麦克风与远端参考信号的连续语义特征)和通道级门控机制,利用自回归语义语言模型预测近端语音的离散语义token;第二阶段(声学建模),以预测的语义token链和原始声学token链为条件,利用声学语言模型生成近端语音的离散声学token,最终通过神经语音编解码器重建波形。与已有AEC方法相比,其新在首次将语义理解与生成式语言模型相结合,并采用分治策略(先语义后声学)。主要实验结果显示,在AEC-Challenge数据集上,所提方法在回声抑制(EMOS)、失真控制(DMOS)和回波损耗增强(ERLE)等指标上,尤其在低信回比(SER)和噪声环境下,显著优于DTLN AEC和MTFAA-NET等强基线(例如,在SER=-10dB的双讲场景中,EMOS达到4.48,比MTFAA-NET高0.30)。该工作的实际意义在于为高实时性、高可懂度的未来语音通信系统提供了新的技术路径。主要局限性在于两阶段独立训练可能无法实现全局最优,且论文未报告模型大小与推理延迟,其实用性需进一步验证。
🏗️ 模型架构
该模型整体架构为两阶段框架,如图1所示。

第一阶段:语义建模 (Semantic Modeling)
- 输入:麦克风信号
y(n)和远端参考信号r(n)的波形。 - 语义特征提取与离散化:
- 使用预训练的WavLM Large模型作为语义提取器,分别提取
y(n)和r(n)的高维语义表示(第6层Transformer隐藏状态)。 - 使用K-Means聚类(K=1024)将连续的语义表示离散化为帧级语义token序列
Ysem和Rsem。
- 使用预训练的WavLM Large模型作为语义提取器,分别提取
- 语义融合:引入一个轻量级的CNN语义融合模块,将
y(n)和r(n)对应的连续WavLM特征进行融合,生成融合语义特征Hfus。该模块由点卷积、两个膨胀深度可分离卷积、点卷积和LayerNorm组成,旨在利用两个信号间的相关性。 - 特征整合:为解决离散token
Ysem和连续特征Hfus的不兼容性,采用通道级门控机制 (G)。首先将Ysem通过token嵌入层WTE(·)得到嵌入向量,然后与经过可学习通道权重G门控的Hfus相加,得到最终的融合表示Fsem,作为语言模型的输入提示。 - 语义token预测:使用一个decoder-only的语义语言模型 (LMsem),以
Fsem为条件,以自回归方式预测近端语音s(n)的语义token序列Ssem。训练时使用教师强制(teacher forcing),损失函数为负对数似然(公式4)。
第二阶段:声学建模 (Acoustic Modeling)
- 声学token获取:使用一个神经语音编解码器(基于论文[20]),将波形
r(n),y(n),s(n)分别编码为离散的声学token序列Raco,Yaco,Saco。编解码器包含CNN编码器、单层量化器和CNN解码器。 - 声学token生成:使用另一个decoder-only的声学语言模型 (LMaco)。其输入是一个“token链”,包括所有语义token (
Rsem, Ysem, Ssem) 和所有声学token (Raco, Yaco)。模型以自回归方式,在给定前面所有token的条件下,预测目标近端声学token序列Saco。训练损失同样是负对数似然(公式5)。 - 波形重建:将生成的
Saco输入神经编解码器的解码器,重建最终的近端语音波形s(n)。
关键设计选择:
- 两阶段解耦:将语义理解和声学生成分离,降低了单个语言模型的学习难度,并允许每个阶段使用针对性的监督信号(语义token vs. 声学token)。
- 语义融合与门控:旨在显式建模麦克风与远端信号在语义层面的交互与抵消(回声部分),这是传统AEC难以直接在特征域处理的语义级干扰。
💡 核心创新点
- 首次将语义语言模型引入AEC:传统AEC方法在特征域(如频谱、嵌入)直接回归或掩蔽,忽略了语言高层语义。本文首次将离散语义token预测作为AEC的一个中间步骤,为模型提供了提升语音可懂度和自然度的显式路径。
- 提出语义融合与门控机制:设计了一个专门的模块来融合麦克风和远端信号的连续语义特征,并通过可学习的通道门控机制,将其与离散的麦克风语义token有机结合,为语言模型提供更丰富的提示信息。这解决了离散与连续表示的不兼容问题,并建模了信号间的语义级关系。
- 两阶段生成式框架:采用“先语义,后声学”的生成策略。第一阶段预测语义token作为第二阶段的强条件,第二阶段生成声学token并重建波形。这种层次化的生成过程可能更符合人类语音产生与理解的认知过程。
- 显著的实验性能提升:在极具挑战性的AEC-Challenge数据集上,所提方法在EMOS、DMOS和ERLE指标上全面优于现有先进方法,特别是在低SER和噪声环境下,证明了引入语义信息和生成式建模的有效性。
🔬 细节详述
- 训练数据:使用AEC-Challenge数据集,包含20,000个模拟声学场景,具有多种非线性失真。原始10秒音频被裁剪为9秒,采样率为16kHz。双讲场景的信回比(SER)范围为-10dB到10dB。未说明数据集的具体划分(训练/验证/测试集比例)。
- 损失函数:
- 语义语言模型损失
L_{LMsem}:标准的自回归交叉熵损失(公式4)。 - 声学语言模型损失
L_{LMaco}:同样是标准的自回归交叉熵损失(公式5)。两个损失未说明是否有权重平衡。
- 语义语言模型损失
- 训练策略:
- 优化器:AdamW。
- 学习率调度:预热1000步(从0到1e-4),然后余弦衰减至0,总训练步数约1,000,000步。
- 早停:验证集损失连续5个epoch未下降则停止训练。
- 两个语言模型阶段独立训练。
- 关键超参数:
- 语义提取器:WavLM Large。
- K-Means聚类数
K:1024。 - 两个语言模型(LMsem 和 LMaco):隐藏维度1024,12层Transformer,8个注意力头。
- 未说明 batch size, 各阶段的具体训练步数/epoch数,以及训练使用的GPU型号和数量。
- 推理细节:采用自回归解码。未说明是否使用了束搜索(beam search)或其他解码策略,温度等超参数。
- 正则化/稳定训练技巧:提到了使用LayerNorm(在语义融合模块中),但未明确说明语言模型内部是否使用了Dropout等其他正则化方法。
📊 实验结果
实验在AEC-Challenge数据集上进行,评估指标为AECMOS(包括EMOS和DMOS)和ERLE。主要对比如下表所示。
表1:不同场景下所提方法与基线方法的对比结果
| 对比方法 | 双讲 -10dB | 双讲 -5dB | 双讲 0dB | 双讲 5dB | 单讲 (仅回声) |
|---|---|---|---|---|---|
| EMOS↑ DMOS↑ | EMOS↑ DMOS↑ | EMOS↑ DMOS↑ | EMOS↑ DMOS↑ | ERLE(dB)↑ EMOS↑ | |
| DTLN AEC | 2.58, 3.42 | 3.14, 3.39 | 3.63, 3.31 | 3.92, 3.47 | 16.48, 3.64 |
| MTFAA-NET | 4.18, 2.15 | 4.25, 2.57 | 4.35, 3.15 | 4.37, 3.53 | 33.66, 4.50 |
| Proposed | 4.48, 3.26 | 4.51, 3.34 | 4.50, 3.48 | 4.53, 3.71 | 66.98, 4.63 |
结论:所提方法在所有SER条件下均取得了最高的EMOS和DMOS分数,尤其在低SER(-10dB, -5dB)和单讲场景下优势明显。ERLE指标(66.98 dB)远超基线,表明其极强的回声抑制能力。
图2:不同方法估计的近端语音频谱图对比
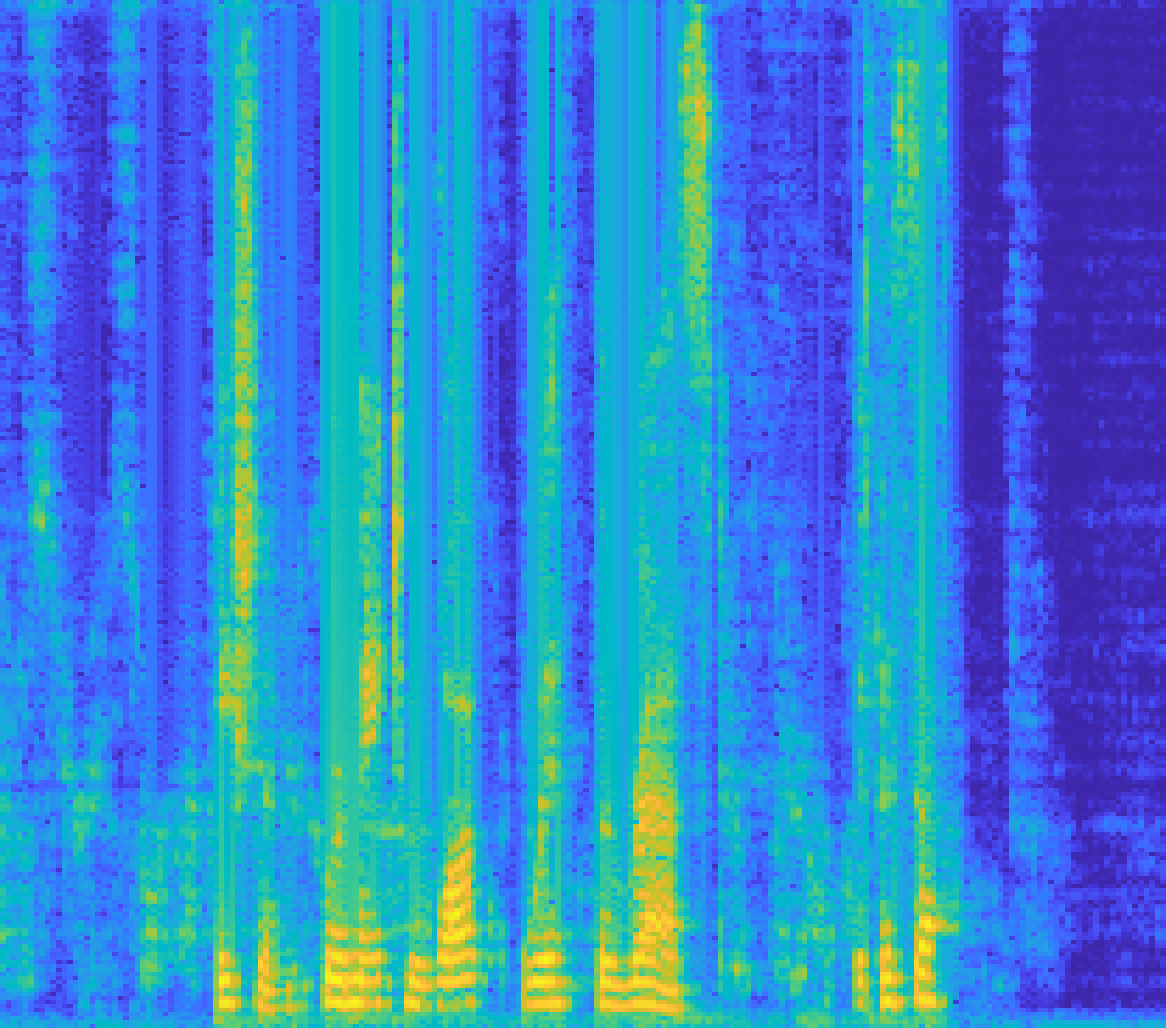 (a) DTLN AEC, (b) MTFAA-NET, (c) Proposed, (d) Ground Truth
结论:从频谱图可以直观看出,本文方法估计的频谱(c)与干净语音(d)在细节结构上最为接近,而其他方法存在更明显的频谱失真或残留回声成分。
(a) DTLN AEC, (b) MTFAA-NET, (c) Proposed, (d) Ground Truth
结论:从频谱图可以直观看出,本文方法估计的频谱(c)与干净语音(d)在细节结构上最为接近,而其他方法存在更明显的频谱失真或残留回声成分。
消融实验(表2)
| 方法 | EMOS↑ | DMOS↑ |
|---|---|---|
| two-stage LM (完整方法) | 4.51 | 3.49 |
| w/o near-end semantic tokens | 4.32 | 2.79 |
结论:去除近端语义token (Ssem) 后,DMOS显著下降(从3.49到2.79),表明近端语义token对保持语音质量和减少失真至关重要,验证了第一阶段语义预测的有效性。 |
不同非线性条件下的结果(表3)
| 非线性条件 | 方法 | EMOS↑ | DMOS↑ |
|---|---|---|---|
| NL0 | DTLN AEC | 3.02 | 3.46 |
| MTFAA-NET | 4.25 | 2.83 | |
| Proposed | 4.46 | 3.40 | |
| NL1 | DTLN AEC | 3.63 | 3.40 |
| MTFAA-NET | 4.35 | 3.08 | |
| Proposed | 4.52 | 3.52 | |
| 结论:方法在NL0和NL1两种非线性条件下均表现最优,展现了良好的鲁棒性。 |
不同噪声条件下的结果(表4)
| 远端噪声 | 近端噪声 | 方法 | EMOS↑ | DMOS↑ |
|---|---|---|---|---|
| ✓ | ✗ | DTLN AEC | 3.48 | 3.42 |
| MTFAA-NET | 4.30 | 3.10 | ||
| Proposed | 4.50 | 3.52 | ||
| ✗ | ✓ | DTLN AEC | 3.49 | 3.39 |
| MTFAA-NET | 4.34 | 2.94 | ||
| Proposed | 4.53 | 3.49 | ||
| ✓ | ✓ | DTLN AEC | 3.38 | 3.35 |
| MTFAA-NET | 4.30 | 2.92 | ||
| Proposed | 4.50 | 3.48 | ||
| 结论:在远端噪声、近端噪声及混合噪声条件下,所提方法均取得了最高的EMOS和DMOS,证明其在复杂噪声环境中依然有效。 |
⚖️ 评分理由
- 学术质量:6.0/7。创新点(语义引入、两阶段生成、融合门控)明确且合理;技术方案描述清晰;实验非常充分,覆盖了多种挑战性场景,并进行了关键消融实验;结果可信度高,与强基线对比有显著提升。扣分点:1)两阶段独立训练可能非最优;2)未与同期其他生成式语音增强/回声消除方法(如基于扩散模型的方法)对比;3)部分训练细节(如batch size)缺失。
- 选题价值:1.5/2。AEC是语音通信的关键瓶颈技术,尤其是在远程会议、智能音箱等全双工场景。论文探索用生成式大模型提升AEC的语音质量���可懂度,方向前沿,潜在应用空间广,对音频/语音社区有参考价值。
- 开源与复现加成:0.0/1。论文未提供代码、预训练模型权重的链接,也未提及开源计划。实验配置细节不全,这严重阻碍了该工作的可复现性和后续研究者的快速跟进。