📄 TVP-UNet: Threshold Variance Penalty U-Net for Voice Activity Detection in Dysarthric Speech
#语音活动检测 #U-Net #阈值方差惩罚 #构音障碍 #半监督学习
✅ 7.0/10 | 前25% | #语音活动检测 | #U-Net | #阈值方差惩罚 #构音障碍
学术质量 5.5/7 | 选题价值 1.2/2 | 复现加成 0.2 | 置信度 高
👥 作者与机构
- 第一作者:Aditya Pandey (School of Computer Science and Engineering, Vellore Institute of Technology, Chennai, India)
- 通讯作者:未明确说明(从贡献描述和作者排序推测,核心研究者为来自IISc的Prasanta Kumar Ghosh)
- 作者列表:Aditya Pandey(VIT Chennai),Tanuka Bhattacharjee, Prasanta Kumar Ghosh(Indian Institute of Science, Bengaluru),Madassu Keerthipriya, Darshan Chikktimmegowda, Dipti Baskar, Yamini BK, Seena Vengalil, Atchayaram Nalini, Ravi Yadav(National Institute of Mental Health and Neurosciences, Bengaluru)。
💡 毒舌点评
亮点:这是首个专门针对构音障碍语音的VAD研究,问题定义精准且临床意义明确;提出的TVP损失通过“阈值方差惩罚”巧妙地稳定了弱分类器在模糊边界上的决策,是一个可解释性强的正则化技巧。 短板:实验基线过于陈旧(2022年的方法),未能与当前先进的自监督、基于变换器的VAD模型对比,削弱了方法在通用场景下竞争力的说服力;且未提供任何代码或模型,在开源盛行的今天,严重阻碍了其影响力扩散。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:数据来自NIMHANS,论文详细描述了数据收集协议、伦理批准和标注过程,但未说明数据集是否公开以及如何获取。
- Demo:未提及。
- 复现材料:论文在方法、实验设置部分提供了详细的训练超参数、损失函数公式和评估方案,可作为复现指南,但缺少代码和预训练模型,实际复现需从头构建。
- 论文中引用的开源项目:提到了Audacity用于标注,无其他关键依赖。
📌 核心摘要
- 解决的问题:传统语音活动检测(VAD)方法在应对构音障碍(如ALS、PD患者)语音时失效,因其具有异常韵律、发音不精准、强度多变等特征,导致误检和漏检。
- 方法核心:提出一个紧凑的1D U-Net自编码器,在重构100ms音频帧的同时,通过一个新颖的“阈值方差惩罚”(TVP)损失,联合学习帧级语音/非语音决策。TVP通过惩罚多个分类阈值下的决策方差,稳定了基于统计量(均值、方差)的弱分类器输出。
- 与已有方法相比新在哪里:a) 问题新颖性:首次将VAD研究聚焦于构音障碍语音;b) 技术创新:提出TVP损失,使模型能在有监督、半监督和无监督等多种标注条件下有效训练,减少对稀缺临床标注数据的依赖。
- 主要实验结果:在自有构音障碍数据集上进行0%~100%标签比例的实验。在最具实用价值的50%标签比例下,该方法平均F1值达到92.46%(精确率95.59%,召回率89.57%),性能接近全监督(100%标签)基线,并显著优于无监督基线。关键对比数据见下表:
| 方法 | 标签比例 | 精确率 (%) | 召回率 (%) | F1值 (%) | AUCROC (%) |
|---|---|---|---|---|---|
| TVP-UNet (本文) | 0% | 84.33 (15.2) | 79.63 (17.5) | 79.3 (1.3) | 68.20 (16.0) |
| TVP-UNet (本文) | 100% | 96.50 (3.2) | 87.86 (1.0) | 91.98 (5.1) | 91.70 (2.8) |
| Mihalache et al. [9] | 100% (监督基线) | 89.01 (7.2) | 93.23 (3.6) | 90.75 (2.6) | 94.79 (0.5) |
| Sarkar et al. [14] | 0% (无监督基线) | 70.55 (1.5) | 71.19 (0.2) | 70.86 (0.8) | 73.30 (0.5) |
- 实际意义:该方法减少了对专业语言病理学家耗时标注的依赖,使得为构音障碍患者开发可靠的语音识别前端、辅助沟通工具或临床监测系统成为可能。
- 主要局限性:a) 对比基线较少且陈旧,未与当前先进的VAD模型对比;b) 实验数据集为自建私有数据集,虽然描述详细,但社区无法直接获取和验证;c) 论文未提供代码和模型权重。
🏗️ 模型架构
模型是一个紧凑的1D U-Net自编码器,输入为100ms的原始音频波形帧,输出为同尺寸的重构波形帧。
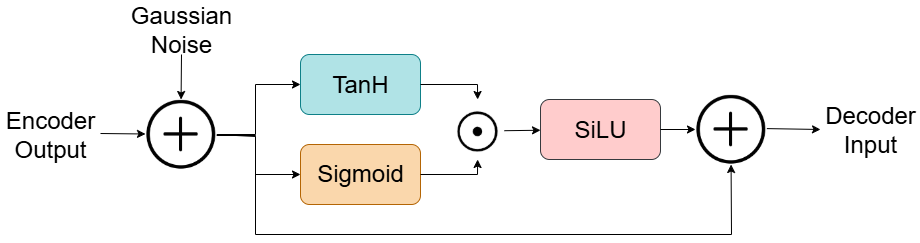
- 编码器(下采样路径):由三个下采样块组成。每个块包含卷积层(核大小3,步长1,无偏置)、最大池化层(步长2)。通道数从输入通道
Cin(应为1)经过f→2f→4f的过程,f初始化为6。 - 瓶颈层:位于编码器和解码器之间,包含层归一化(LayerNorm)、添加标准高斯噪声,以及一个学习到的乘性门控机制(结合tanh/sigmoid和SiLU激活)。
- 解码器(上采样路径):由四个卷积阶段组成(
4f→2f,2f→f,f→f, 最后Conv1D→Cin)。使用最近邻上采样(上采样因子2),并通过加性跳跃连接(Additive Skip Connections)融合编码器对应层的特征。激活函数为GELU。 - 训练机制:如图1所示,输入信号
x送入U-Net得到重构信号ŷ。ŷ同时被送入一个基于统计量的“弱估计器”(公式2)和一个可微的软分数函数(公式3,使用sigmoid),生成不同阈值下的置信度。这些分数与真实标签(或伪标签)一起计算TVP损失,与x和ŷ之间的重构损失组合成总损失,进行端到端训练。
💡 核心创新点
- 首个针对构音障碍的VAD研究:明确指出了现有VAD在病理语音上的失效原因,并首次构建了专用数据集和评估框架,填补了研究空白。
- 提出阈值方差惩罚(TVP)损失:这是核心算法创新。传统VAD损失在单一阈值优化,对阈值敏感。TVP通过惩罚模型输出在多个不同决策阈值下的预测方差,强制模型学习对阈值变化更鲁棒的特征表示,从而稳定在语音/非语音重叠区域的模糊决策。
- 统一的多模式训练框架:通过将TVP与重构损失结合,并利用硬伪标签(由弱估计器在平均阈值下生成)和加权BCE损失,TVP-UNet可以无缝地在有监督、半监督和无监督三种模式下训练,显著降低了对标注数据的依赖。
🔬 细节详述
- 训练数据:来自印度NIMHANS的私有数据集,包含230名ALS、142名PD患者和137名健康对照(HC)的语音录音。总时长约1041分钟。音频由专业人员用Audacity手动标注。
- 损失函数:
- 总损失:
L_total = α L_rec + (1-α) L_tvp,α初始为1.0,在训练中期后衰减至最小值0.4。 - 重构损失 (L_rec):L1和L2损失的线性组合。
- TVP损失 (L_tvp):对有标签样本,计算所有阈值下软分数与真实标签的加权BCE的平均(公式5);对无标签样本,计算软分数与由平均阈值生成的硬伪标签的加权BCE的平均(公式6)。总TVP是两者的加权(公式7)。
- 加权BCE:用于处理类别不平衡,权重β根据正负样本数在线更新。
- 总损失:
- 训练策略:优化器Adam,学习率1e-3,固定100个epoch,batch size 32。
α的衰减在epoch > 50后进行,每轮乘以0.9并截断至0.4。 - 关键超参数:阈值集合 T = [0.05, 0.1, 0.15],平均阈值
τ_bar = 0.1。隐藏通道数f=6。 - 训练硬件:未说明。
- 推理细节:未说明,但根据描述,推理时应使用训练好的重构模型,并在重构后的波形上应用弱估计器(公式2)或软分数进行VAD决策。
- 正则化:初始dropout(p=0.3);瓶颈层的层归一化和高斯噪声注入;TVP本身可视为一种正则化。
📊 实验结果
主要实验结果如上文表格所示。论文还展示了在不同严重程度组(SV, ML, ND, HC)上的细分结果(表3),表明模型在各组均有稳定表现,但HC组性能略低,可能因样本量小导致。图3展示了在不同标签比例(0-100%)下,模型性能指标(F1, Recall, Precision, AUCROC)的变化曲线。关键结论是:性能从0%到25%标签时提升最显著,之后趋于平缓,50%标签已接近全监督性能。
 (图3描述了不同标签比例下模型性能均值与标准差。曲线显示,随着标签比例增加,Precision(精确率)几乎单调上升;F1和Recall在25%后提升放缓;所有指标在50%后基本稳定,且方差减小。这验证了TVP在标签稀缺场景的有效性。)
(图3描述了不同标签比例下模型性能均值与标准差。曲线显示,随着标签比例增加,Precision(精确率)几乎单调上升;F1和Recall在25%后提升放缓;所有指标在50%后基本稳定,且方差减小。这验证了TVP在标签稀缺场景的有效性。)
⚖️ 评分理由
- 学术质量:5.5/7:创新性(TVP)和针对性(构音障碍)明确,技术路线正确,实验设计(多比例、多组别)充分。扣分点在于对比基线不够强(未与SOTA对比)、未提供公开数据或模型影响可复现性。
- 选题价值:1.2/2:在解决特定人群的实际医疗健康问题上价值突出,具有社会意义。但在通用语音处理领域的影响力和直接相关性有限。
- 开源与复现加成:0.2/1:论文提供了非常详细的模型、损失、训练策略描述,理论上可复现。但完全未提供代码、模型权重或公开数据集,这在当代论文中是一个重大缺陷,因此加成很低。