📄 Triage Knowledge Distillation for Speaker Verification
#说话人验证 #知识蒸馏 #模型压缩 #课程学习 #语音
✅ 7.5/10 | 前25% | #说话人验证 | #知识蒸馏 | #模型压缩 #课程学习
学术质量 6.8/7 | 选题价值 1.5/2 | 复现加成 -0.3 | 置信度 高
👥 作者与机构
- 第一作者:Ju-ho Kim(Samsung Research, AI Solution Team)
- 通讯作者:未说明
- 作者列表:Ju-ho Kim(Samsung Research, AI Solution Team)、Youngmoon Jung(Samsung Research, AI Solution Team)、Joon-Young Yang(Samsung Research, AI Solution Team)、Jaeyoung Roh(Samsung Research, AI Solution Team)、Chang Woo Han(Samsung Research, AI Solution Team)、Hoon-Young Cho(Samsung Research, AI Solution Team)
💡 毒舌点评
亮点:TRKD方法设计直观有效,将“评估-优先-关注”的分诊思想系统地应用于知识蒸馏,并通过动态τ课程调度巧妙地平衡了训练稳定性与后期聚焦难度,实验结果在各种架构组合上的一致性提升很有说服力。短板:论文对方法的局限性探讨不足,例如,累积概率阈值τ的最终值(0.05)和调度曲线(γ=0.001)是经验选择,其对不同数据集和任务规模的敏感性与最优性缺乏理论分析或更广泛的实验验证。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及。
- 数据集:使用公开的VoxCeleb1/VoxCeleb2数据集,获取方式为官方申请。
- Demo:未提供。
- 复现材料:详细说明了训练数据、数据增强、损失函数、优化器、学习率调度、τ课程调度等训练细节和关键超参数,但未提供可直接运行的代码或配置文件。
- 论文中引用的开源项目:引用了WeSpeaker toolkit [24]用于模型实现,以及MUSAN [25]、RIR模拟 [26]等数据增强工具。
📌 核心摘要
- 问题:在大规模说话人验证(SV)任务中,将高容量教师模型的知识高效迁移到资源受限的学生模型是一个挑战。传统知识蒸馏(KD)损失会耦合目标类置信度和非目标类结构信息,而改进的解耦KD(DKD)虽然分离了这两者,但对所有非目标类一视同仁,容易受到大规模分类中低概率“长尾”类的噪声干扰。
- 方法核心:论文提出“分诊知识蒸馏”(TRKD),其核心是“评估-优先-关注”三步流程。首先,使用累积概率阈值τ评估每个样本的难度,将教师输出后验分为目标类、高概率非目标“混淆集”和低概率非目标“背景集”。其次,优先传输混淆集内的类间关系信息(通过条件分布对齐)和三元质量(目标/混淆/背景的质量占比),丢弃背景集。最后,通过τ的课程调度(从大到小)聚焦学习,初期传递广泛的非目标上下文,后期则专注于最难混淆的非目标类。
- 创新点:相比DKD和GKD,TRKD创新在于(1)引入了动态的三质量(目标/混淆/背景)划分与传输;(2)实现了基于混淆集的精细化条件对齐;(3)设计了τ课程调度以稳定训练并逐步提升蒸馏难度。该方法无需改变模型架构或引入额外数据。
- 实验结果:在VoxCeleb1的O/E/H三个标准评测集上,TRKD在6种不同的教师-学生架构组合(包括异构架构,如RN152→MNV2)中,均取得了最优的等错误率(EER)。以最强基线(DKD或GKD)为对比,TRKD平均相对降低EER达14.0%;相对于无蒸馏的学生模型基线,平均相对改善达18.7%。消融实验证实了τ课程调度对训练稳定性的关键作用,以及三元质量项(LTMKD)和混淆集条件项(LCFKD)的互补增益。
- 实际意义:TRKD为在移动设备等边缘计算平台上部署高精度说话人验证模型提供了一种更有效的知识压缩方案,能够显著降低学生模型的参数量和计算量,同时保持接近大教师模型的性能。
- 主要局限性:方法依赖于超参数τ的初始值、终值和调度策略的选择,其通用调参指南或自适应策略未被探讨。此外,论文未涉及在更复杂的场景(如变长语音、远场识别)下的验证。
🏗️ 模型架构
本文的核心贡献并非提出一种新的神经网络模型,而是提出一种通用的知识蒸馏损失函数框架(TRKD),可应用于多种现有的说话人验证模型架构。其整体流程如下:
- 输入:教师模型和学生模型在同一输入语音上产生的logit向量(
z_t,z_s)。 - 核心组件:
- 三质量划分器:根据教师logit的softmax概率
p_t,按累积概率阈值τ(k)对非目标类进行排序和划分,得到混淆集F和背景集B。τ(k)随训练步骤k进行课程调度。 - 损失函数计算器:基于上述划分,计算三个主要损失项:
- 三元质量KL散度(
L_TMKD):衡量教师与学生在[目标概率,混淆集总概率,背景集总概率]这个粗糙三元分布上的匹配程度。 - 混淆集条件KL散度(
L_CFKD):衡量教师与学生在混淆集内部归一化分布上的精细匹配程度。 - 背景集条件KL散度(
L_BGKD):论文中定义了但明确丢弃此项,以抑制长尾噪声。
- 三元质量KL散度(
- 三质量划分器:根据教师logit的softmax概率
- 数据流:
教师logit → Softmax → 基于τ(k)的三质量划分 → 计算L_TMKD和L_CFKD → 加权求和得到LTRKD → 与标准分类损失L_AAM相加作为总损失。该框架不改变教师/学生的内部结构,仅修改训练目标。
由于论文提供的图片中没有明确的TRKD架构示意图,但图1(pdf-image-page2-idx0)清晰对比了KD、DKD与TRKD的损失函数结构,可以说明TRKD的工作原理。
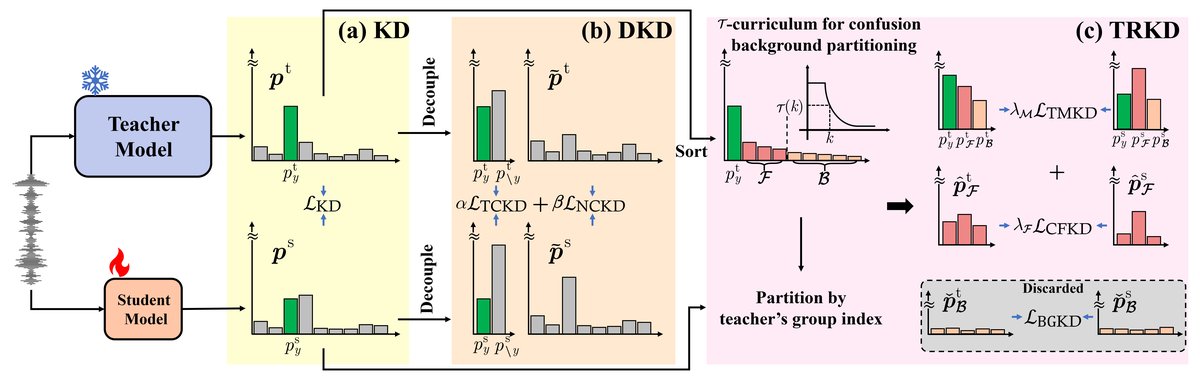 图1 (c)展示了TRKD如何将教师后验概率划分为三部分(y, F, B),并仅传输与y和F相关的监督信号。
图1 (c)展示了TRKD如何将教师后验概率划分为三部分(y, F, B),并仅传输与y和F相关的监督信号。
💡 核心创新点
- 基于累积概率的动态三质量划分:通过阈值
τ将非目标类动态分为“混淆集”和“背景集”。这解决了DKD对所有非目标类一视同仁导致的长尾噪声问题,也区别于GKD使用的静态硬阈值(如固定top-k)。 - 混淆集条件分布对齐:在划分基础上,TRKD不仅传输粗糙的三元质量(
L_TMKD),还特别强调对混淆集内部归一化分布(L_CFKD)的精细对齐,从而更有效地传递最具信息量的类间相似性结构。 - 课程学习调度(τ-课程):将
τ从大到小进行指数调度。训练初期τ大,混淆集包含较多非目标类,传递广泛的背景知识;后期τ减小,混淆集收缩至最难混淆的类,引导学生模型聚焦学习,平滑了训练过程并提升了最终性能。这是将课程学习思想应用于蒸馏损失设计的创新。
🔬 细节详述
- 训练数据:使用VoxCeleb2开发集进行训练。输入为2秒的对数梅尔频谱图。数据增强包括:MUSAN添加噪声、模拟房间冲激响应进行卷积、速度扰动(0.9x, 1.1x)。
- 损失函数:总损失为
L = L_AAM + L_TRKD。L_AAM:加性角度间隔softmax损失,参数为scale s=32,margin m=0.2。L_TRKD = λ_M L_TMKD + λ_F L_CFKD,论文中设置λ_M=1,λ_F=8。对比基线DKD设置α=1,β=8。
- 训练策略:
- 训练轮数:150 epochs。
- 批大小:512(全局)。
- 优化器:SGD(动量0.9)。
- 学习率:前6个epoch从0线性预热到0.1,之后指数衰减至
5×10^{-5}。 - 蒸馏温度:对于logit级KD方法,温度设置为4。
- τ课程调度:
τ从1.0指数衰减到0.05,调度发生在第10个epoch到第60个epoch之间,曲率参数γ=0.001。
- 关键超参数:温度
T=4;DKD权重α=1, β=8;TRKD权重λ_M=1, λ_F=8;τ调度τ_init=1.0,τ_final=0.05,γ=0.001,调度阶段k_start=10,k_stop=60(epoch)。 - 训练硬件:未说明具体硬件型号,但提及在4块A100 GPU上进行。
- 推理细节:论文中未提及推理时的特殊解码策略或流式设置,通常说话人验证使用余弦相似度或分数归一化。
- 模型架构:论文探索了多种师生架构对,包括ECAPA-TDNN(1024/400)、ResNet(18/34/152)、ReDimNet(B5/B2)、CAM++、X-vector、MobileNetV2、SAM-ResNet50、Res2Net34。嵌入维度多为256,X-vector和CAM++为512。
📊 实验结果
主要实验在VoxCeleb1的original (O), extended (E), hard (H)三个评测协议上进行,评估指标为等错误率(EER, %)。关键结果汇总如下表:
表1:不同教师→学生组合下各方法在VoxCeleb1上的EER(%)对比(部分关键列)
| T→S (教师→学生) | 方法 | VoxCeleb1-O | VoxCeleb1-E | VoxCeleb1-H | 平均相对改进 ∆(%) vs Student |
|---|---|---|---|---|---|
| ECAPA1024→ECAPA400 | w/o KD (Student) | 1.351 | 1.395 | 2.607 | – |
| DKD | 1.101 | 1.200 | 2.159 | +16.7% | |
| GKD | 1.058 | 1.218 | 2.183 | +16.7% | |
| TRKD | 0.978 | 1.115 | 2.001 | +23.5% | |
| RN152→MNV2 | w/o KD (Student) | 1.479 | 1.449 | 2.603 | – |
| DKD | 1.053 | 1.184 | 2.246 | +18.9% | |
| GKD | 1.047 | 1.210 | 2.296 | +17.7% | |
| TRKD | 0.883 | 1.068 | 2.016 | +28.3% | |
| SAM-RN50→R2N34 | w/o KD (Student) | 1.383 | 1.359 | 2.422 | – |
| DKD | 1.101 | 1.277 | 2.419 | +7.1% | |
| GKD | 1.138 | 1.320 | 2.463 | +4.7% | |
| TRKD | 0.968 | 1.157 | 2.178 | +16.7% |
结论:TRKD在所有18个评测点(6种师生组合 × 3个协议)上均取得了最低的EER,相较于次优的logit级方法(DKD或GKD)和学生基线,展现了稳定且显著的性能提升。
消融实验(基于ReDimNet-B5→ReDimNet-B2, VoxCeleb1-O)
| ID | 方法 | τ调度 | EER(%) | 相对DKD改进 ∆(%) |
|---|---|---|---|---|
| #1 | DKD (基线) | 固定1.0* | 0.729 | – |
| #2 | LTCKD → LTMKD | 固定0.05 | 训练发散 | – |
| #3 | LTCKD → LTMKD | 1.0→0.05 | 0.691 | +5.2% |
| #4 | LNCKD → LCFKD | 1.0→0.05 | 0.654 | +10.3% |
| #5 | TRKD (LTMKD + LCFKD) | 1.0→0.05 | 0.627 | +14.0% |
*注:DKD等价于τ=1.0时的TRKD。 结论:消融实验证实,直接替换损失项而不使用τ课程调度会导致训练不稳定(ID#2)。τ课程调度对于稳定训练至关重要(ID#3)。同时,替换背景集条件项(LNCKD)为混淆集条件项(LCFKD)带来的增益(ID#4)大于仅使用三元质量项(ID#3),而两者结合(ID#5)效果最优,证明了各组件的互补性。
图2(pdf-image-page4-idx1)展示了固定教师为ReDimNet-B5时,不同学生模型规模下TRKD与最强基线(DKD/GKD中较优者)的EER对比。
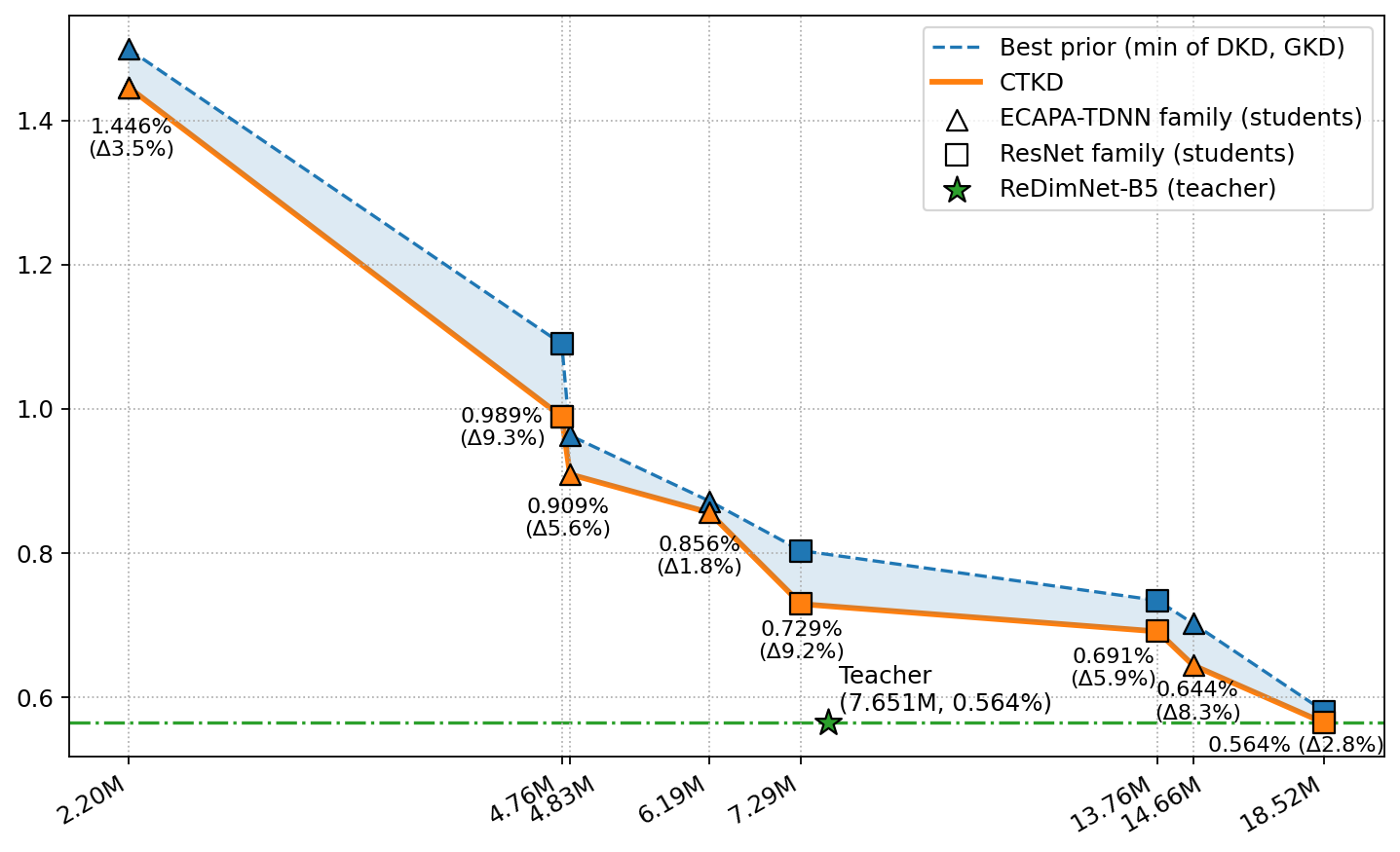 图2显示,TRKD(实线)在所有学生模型规模上均优于最强基线(虚线),平均相对改进约5.8%,尤其在中等规模学生(如RN18, RN34)上增益明显,甚至将大容量学生(如RN101)的性能提升至与教师持平。
图2显示,TRKD(实线)在所有学生模型规模上均优于最强基线(虚线),平均相对改进约5.8%,尤其在中等规模学生(如RN18, RN34)上增益明显,甚至将大容量学生(如RN101)的性能提升至与教师持平。
⚖️ 评分理由
- 学术质量:6.8/7
- 创新性(1.8/2):提出了TRKD框架,将动态分区、混淆集对齐和课程调度有机结合,是KD领域有价值的技术演进。
- 技术正确性(2.0/2):从经典KD推导至TRKD的数学逻辑严谨,消融实验设计合理,验证了各组件贡献。
- 实验充分性(1.5/2):实验规模大(6种师生对,3个评测集),覆盖异构架构,对比方法全面(含经典KD、DKD、GKD及嵌入级方法)。
- 证据可信度(1.5/2):所有实验基于公开标准数据集和评测协议,结果具有可比性。未提供代码稍影响完全可信度。
- 选题价值:1.5/2
- 前沿性(0.8/1):模型压缩与知识蒸馏是持续的热点,该研究针对说话人验证的具体挑战提出了解决方案,具��时效性。
- 潜在影响与应用空间(0.7/1):直接服务于边缘设备上部署高精度SV模型的需求,工业应用潜力明确。对于语音领域的研究者,其方法论(动态分区+课程学习)也可能启发其他任务的蒸馏工作。
- 开源与复现加成:-0.3/1
- 代码与模型(0.0/1):论文中未提及代码仓库链接或公开的模型权重。
- 复现细节(0.0/1):虽给出了详细的训练配置和超参数,但未提供代码、配置文件或预训练检查点,完全复现仍需较大工作量。
- 依赖项目(-0.3/1):使用了公开的WeSpeaker工具包,但未明确说明复现是否完全依赖其默认流程,可能增加环境配置的复杂性。