📄 Transferable Audio Lottery Tickets: Gradient Accumulation for Extreme Sparsity
#音频分类 #迁移学习 #模型压缩 #鲁棒性
✅ 7.0/10 | 前25% | #音频分类 | #迁移学习 | #模型压缩 #鲁棒性
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Hyunjae Kim(KAIST 文化技术研究生院)
- 通讯作者:未明确指定,论文通讯邮箱列表包含 {present, juhan.nam, kmlee2}@kaist.ac.kr
- 作者列表:Hyunjae Kim(KAIST 文化技术研究生院)、Juhan Nam(KAIST 文化技术研究生院)、Kyung Myun Lee(KAIST 文化技术研究生院;KAIST 数字人文与计算社会科学学院)
💡 毒舌点评
亮点:论文提出了一个简单而有效的梯度累积策略(GA-LTH),显著提升了在极端稀疏(<1%参数保留)条件下发现可训练“中奖票”的能力,并验证了这些子网络在语音、音乐、环境声等不同音频子任务间的可迁移性,为音频模型的超轻量化部署提供了新思路。短板:技术贡献更侧重于对训练过程的调优而非根本性理论突破,且只在ResNet18上验证,对于更复杂的模型(如Transformer)的适用性未做探讨,理论解释相对薄弱。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开数据集(ESC-50, Speech Commands, GTZAN等),论文中说明了数据集来源和划分方式。
- Demo:未提供在线演示。
- 复现材料:论文在第4节“EXPERIMENTAL SETUP”中给出了相对详细的实现细节(数据集、预处理、模型架构、优化器参数、训练轮数等),但未提供完整的配置文件或训练日志。
- 论文中引用的开源项目:提到了ResNet18架构,但未指明具体引用哪个开源实现。依赖的数据集(如ESC-50)是公开的。
📌 核心摘要
问题:大型神经网络在音频领域性能优异但计算负担重,轻量化需求迫切。彩票假设(LTH)揭示了稀疏子网络的潜力,但其在跨音频子领域(如语音、音乐、环境声)的有效性和如何发现极端稀疏的“中奖票”尚未被充分探索。
方法核心:提出在LTH的子网络搜索(剪枝)阶段引入类似动量的梯度累积(GA-LTH)。该策略通过额外累加历史梯度来增强极稀疏网络的梯度信号,从而更稳定地找到可训练子网络。
与已有方法相比新在哪里:首次系统性地在三大音频子领域验证LTH,并提出GA-LTH策略。与传统LTH和一次性剪枝(UMP, LMP)相比,GA-LTH在极端稀疏(剩余参数<1%)时能发现不发生层崩溃、性能鲁棒的子网络,并证明了这些子网络可跨子领域迁移。
主要实验结果:
- 在三个源数据集(ESC-50, Speech Commands, GTZAN)上,GA-LTH在超过99%剪枝率后,性能下降远小于标准LTH和基线方法,在ESC-50上甚至以0.08%的参数保留了接近密集模型的精度(见图2a)。
- 迁移实验(表1)显示,在极端稀疏(剩余0.13%)条件下,从ESC-50迁移的GA-LTH子网络在UrbanSound8k等目标数据集上仅损失2-5%的绝对精度,而其他方法性能崩溃至随机水平。
源数据集 目标数据集 GA-LTH (0.13%) LTH (0.13%) UMP (0.13%) LMP (0.13%) ESC-50 UrbanSound8k 66.2% 12.0% 12.0% 13.2% Speech Commands LibriCount 50.5% 8.4% 8.4% 9.9% GTZAN Nsynth 34.3% 1.3% 1.4% 1.1% (注:数值为分类绝对精度) 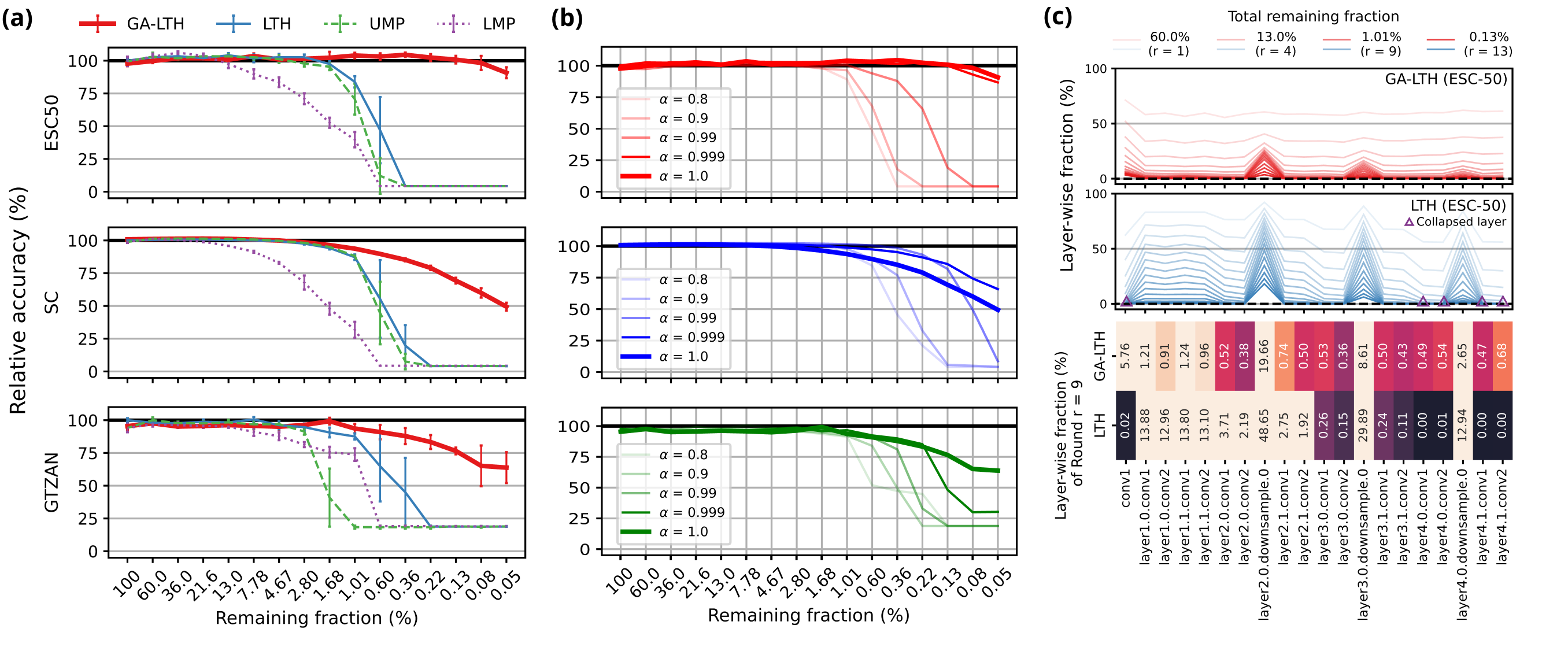
- 图2(a)显示GA-LTH在极高稀疏度下性能显著优于其他方法。图2(c)的热力图对比表明,标准LTH会出现层崩溃(黑色区域),而GA-LTH保持了更均衡的层稀疏度分布。
实际意义:证明了通过改进训练策略,可以在音频分类任务中找到极端稀疏且可跨任务迁移的模型结构,为在资源受限的边缘设备上部署多种音频分析模型(如同时用于语音唤醒和环境声识别)提供了可能性。
主要局限性:研究局限于ResNet18架构和特定的音频分类任务,未在语音识别、生成等任务或更复杂的模型上验证。梯度累积策略的理论理解有待深化,且最优衰减因子α可能因任务而异。
🏗️ 模型架构
论文的核心贡献在于训练策略而非模型架构本身。所使用的基线模型是ResNet18,其架构如下:
- 输入:将原始音频波形转换为单通道的梅尔频谱图(64个梅尔滤波器组,32ms窗长,8ms步长)。
- 主干网络:标准的ResNet18卷积神经网络。论文中仅对卷积层进行结构化/非结构化剪枝,保持全连接层(输出头)完整,以便在迁移学习时替换以适应不同目标数据集的标签空间。
- 输出层:一个全连接分类头,其神经元数量与具体任务的类别数匹配。
- 数据流:梅尔频谱图输入ResNet18的卷积层提取特征,最终经过全局平均池化和全连接层输出分类logits。
- 关键设计选择:选择ResNet18是因为其在音频任务上已被广泛验证,且便于与已有LTH研究对比。剪枝仅应用于卷积层是为了确保子网络结构在不同音频任务间迁移时,特征提取部分(卷积层)的权重和掩膜可以复用。
💡 核心创新点
- 梯度累积提升中奖票搜索效率(GA-LTH):针对极端稀疏网络梯度流差、优化不稳定的问题,在剪枝搜索阶段引入了动量式梯度累积(公式1和2)。这是对标准LTH训练流程的一个简单但关键的改进,使优化过程能更好地利用历史梯度信息,从而在>99%的剪枝率下仍能找到可训练的子网络。
- 发现极度稀疏且性能鲁棒的音频子网络:证明了在ESC-50等数据集上,通过GA-LTH可以发现仅保留原模型0.08%-1.0%参数,却能保持密集模型90%以上性能的子网络,且避免了“层崩溃”现象。这在音频LTH领域达到了新的稀疏度水平。
- 跨音频子领域的中奖票迁移:系统性地验证了从环境声(ESC-50)、语音(SC)、音乐(GTZAN)任务中发现的稀疏子网络,可以成功迁移到其他不同的音频子领域任务(UrbanSound8k, LibriCount, NSynth),并保持一定的性能。这表明这些稀疏子网络可能编码了某种音频通用表示。
🔬 细节详述
- 训练数据:
- 源数据集:ESC-50(环境声,50类,2000样本)、Speech Commands v0.02(语音命令,35类,105829样本)、GTZAN(音乐流派,10类,1000样本)。
- 目标数据集(用于迁移):UrbanSound8k(环境声,10类,8732样本)、LibriCount(说话人计数,11类,5720样本)、NSynth-pitch(乐器音高,88类,5000样本)。
- 预处理:所有音频降采样至16kHz,转换为梅尔频谱图。训练时随机裁剪1秒片段,测试时使用固定中心裁剪(NSynth例外,从开头裁剪)。未提及额外的数据增强。
- 损失函数:论文中未明确提及,推测为标准的交叉熵损失(用于分类任务)。
- 训练策略:
- 优化器:AdamW(β1=0.9, β2=0.999, 学习率=1e-4, 权重衰减=3e-4)。
- 训练时长:模型训练5000次迭代,使用早停法(patience=2000)。
- 批大小:64。
- LTH剪枝流程:迭代幅度剪枝,共15轮(r=15),每轮保留60%权重(p=0.6),最终稀疏度可达约0.05%。剪枝仅作用于卷积层。GA-LTH的默认衰减因子α=1.0,标准LTH对应α=0.0。
- 关键超参数:模型为ResNet18。GA-LTH的关键超参数是衰减因子α(在0.0-1.0之间实验)。
- 训练硬件:论文中未说明具体GPU型号和数量。
- 推理细节:未提及特殊推理策略(如量化、蒸馏等),使用训练好的模型进行前向推理。
- 正则化:使用了权重衰减(3e-4)和早停法。
📊 实验结果
- 主要Benchmark与结果:
- 稀疏模型发现(图2a):在三个源数据集上,当剪枝率超过99%(剩余<1%)时,GA-LTH的相对精度显著高于标准LTH和基线(UMP, LMP)。例如,在ESC-50上,GA-LTH在剩余0.08%参数时仍保持约90%的密集模型精度。
- 迁移学习(表1):这是论文的核心结果之一。表格完整展示了在不同稀疏度下,四种方法(GA-LTH, LTH, UMP, LMP)从三个源数据集迁移到三个目标数据集的绝对分类精度。
源数据集 目标数据集 GA-LTH (13.0%) GA-LTH (1.01%) GA-LTH (0.13%) LTH (0.13%) UMP (0.13%) LMP (0.13%) ESC-50 UrbanSound8k 68.1% 68.3% 66.2% 12.0% 12.0% 13.2% ESC-50 LibriCount 58.9% 58.1% 54.2% 8.4% 8.4% 9.9% ESC-50 Nsynth 74.8% 73.8% 70.3% 1.3% 1.4% 1.1% Speech Commands UrbanSound8k 67.9% 66.0% 58.4% 12.0% 12.0% 13.2% Speech Commands LibriCount 59.0% 57.1% 50.5% 8.4% 8.4% 9.9% Speech Commands Nsynth 74.4% 73.7% 64.4% 1.3% 1.4% 1.1% GTZAN UrbanSound8k 67.8% 65.5% 49.8% 12.0% 12.0% 13.2% GTZAN LibriCount 57.6% 56.2% 45.7% 8.4% 8.4% 9.9% GTZAN Nsynth 74.9% 73.6% 34.3% 1.3% 1.4% 1.1% - 关键结论:在剩余13%参数时,各方法差异不大。在剩余1.01%时,LTH系方法(GA-LTH, LTH)已显示出优于单次剪枝基线(UMP, LMP)的趋势。在极端的0.13%剩余时,GA-LTH展现了惊人的鲁棒性,尤其是从ESC-50迁移的子网络,性能下降幅度很小;而其他所有方法的性能基本崩溃至随机猜测水平。
- 消融实验与分析:
- 衰减因子α的影响(图2b):在ESC-50上,α=1.0时性能最佳;在Speech Commands上,α=0.99时性能最佳,α=1.0略有下降。表明梯度累积的强度需要根据数据集微调。
- 层稀疏度分析(图2c):热力图显示标准LTH在某些层几乎全部被剪枝(黑色区域),即发生“层崩溃”;而GA-LTH的稀疏度分布更均匀,避免了结构性瓶颈。
⚖️ 评分理由
- 学术质量:7.0/7。论文逻辑清晰,实验设计全面(涵盖多个音频子领域、多种稀疏度、多种对比基线),数据结果有力地支持了其结论。创新点(GA-LTH)是有效的技术改进,但属于工程优化范畴,理论新颖性一般。
- 选题价值:1.5/2。将LTH与梯度累积结合解决音频模型极端稀疏化和跨域迁移问题,选题切中边缘计算部署的实际需求,具有明确的应用前景和价值。
- 开源与复现加成:-0.5/1。论文详细描述了数据集、模型、训练流程和关键超参数,但未提供代码仓库、预训练模型权重或训练脚本。复现者需要自行准备数据集和实现GA-LTH训练流程,存在一定门槛。