📄 Transfer Learning for Paediatric Sleep Apnoea Detection using Physiology-Guided Acoustic Models
#音频分类 #生物声学 #迁移学习 #多任务学习 #低资源
✅ 7.0/10 | 前25% | #音频分类 | #迁移学习 | #生物声学 #多任务学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Chaoyue Niu(谢菲尔德大学计算机学院)
- 通讯作者:未明确说明(论文第一作者邮箱为 c.niu@sheffield.ac.uk,最后一位作者 Ning Ma 邮箱为 n.ma@sheffield.ac.uk,可能是导师或通讯作者)
- 作者列表:Chaoyue Niu(谢菲尔德大学计算机学院)、Veronica Rowe(谢菲尔德大学计算机学院)、Guy J. Brown(谢菲尔德大学计算机学院)、Heather Elphick(谢菲尔德儿童NHS基金会信托)、Heather Kenyon(谢菲尔德儿童NHS基金会信托)、Lowri Thomas(谢菲尔德儿童NHS基金会信托)、Sam Johnson(Passion for Life Healthcare)、Ning Ma(谢菲尔德大学计算机学院)
💡 毒舌点评
亮点:论文在方法设计上表现出临床问题驱动的巧思,例如将氧气去饱和的时间延迟作为物理先验知识融入多任务学习框架,使模型更符合呼吸生理学过程,这比简单地使用SpO2标签更具说服力。
短板:然而,论文最大的硬伤在于验证的“小作坊”模式——用15个孩子的数据做全部开发和评估,且缺乏外部验证集,这使得所有声称的“改进”都笼罩在严重的过拟合和选择偏倚风险之下,大大削弱了其临床应用的前景。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:儿童数据集因涉及患者隐私,未公开,也未提供获取方式。成人数据集引用自[15],但未说明其是否公开。
- Demo:未提及。
- 复现材料:论文提供了一些训练超参数(如学习率、批量大小、epoch数),但未提供模型具体架构、完整代码或配置文件。
- 论文中引用的开源项目:未提及依赖的开源工具或模型。
📌 核心摘要
- 问题:儿童阻塞性睡眠呼吸暂停(OSA)诊断困难,依赖儿童耐受性差的多导睡眠图,而基于声学的非侵入性筛查方法因儿童数据稀缺难以开发。
- 方法核心:提出一个迁移学习框架,将在大规模成人睡眠声学数据上预训练的CNN模型适配到儿童OSA检测任务中。关键创新是整合了氧饱和度(SpO2)信息,并建模了从呼吸事件发生到血氧下降的生理性时间延迟。
- 新意:系统比较了单任务与多任务学习、编码器冻结与全微调等策略。最核心的创新是将生理延迟(成人中位数为26秒)作为先验知识,通过全局延迟和针对每个儿童的个体化延迟两种方式集成到多任务学习中。
- 主要结果:在15晚儿童数据上的5折交叉验证显示,采用“多任务学习 + 全微调 + 个体化延迟”的最佳模型,其预测AHI与临床金标准AHI的平均绝对误差(MAE)为2.81,均方根误差(RMSE)为3.86。这显著优于不进行迁移学习的成人基线模型(MAE:4.45,RMSE:6.81)。关键对比数据如下表所示:
模型配置(缩写说明) MAE RMSE 成人单任务无微调 (S-NF) 4.45 6.81 成人多任务无微调 (M-NF) 3.64 6.30 最佳:多任务全微调个体化延迟 (M-UF-SD) 2.81 3.86 - 实际意义:证明了利用成人数据进行迁移学习,并整合生理学知识,可以有效缓解儿童数据稀缺问题,为开发低成本、居家友好的儿童OSA智能手机筛查工具提供了可行路径。
- 主要局限性:研究的核心局限在于验证数据集规模极小(仅15名儿童),缺乏外部验证,模型泛化能力存疑。此外,数据收集于单一中心,可能无法代表更广泛的儿童人群。
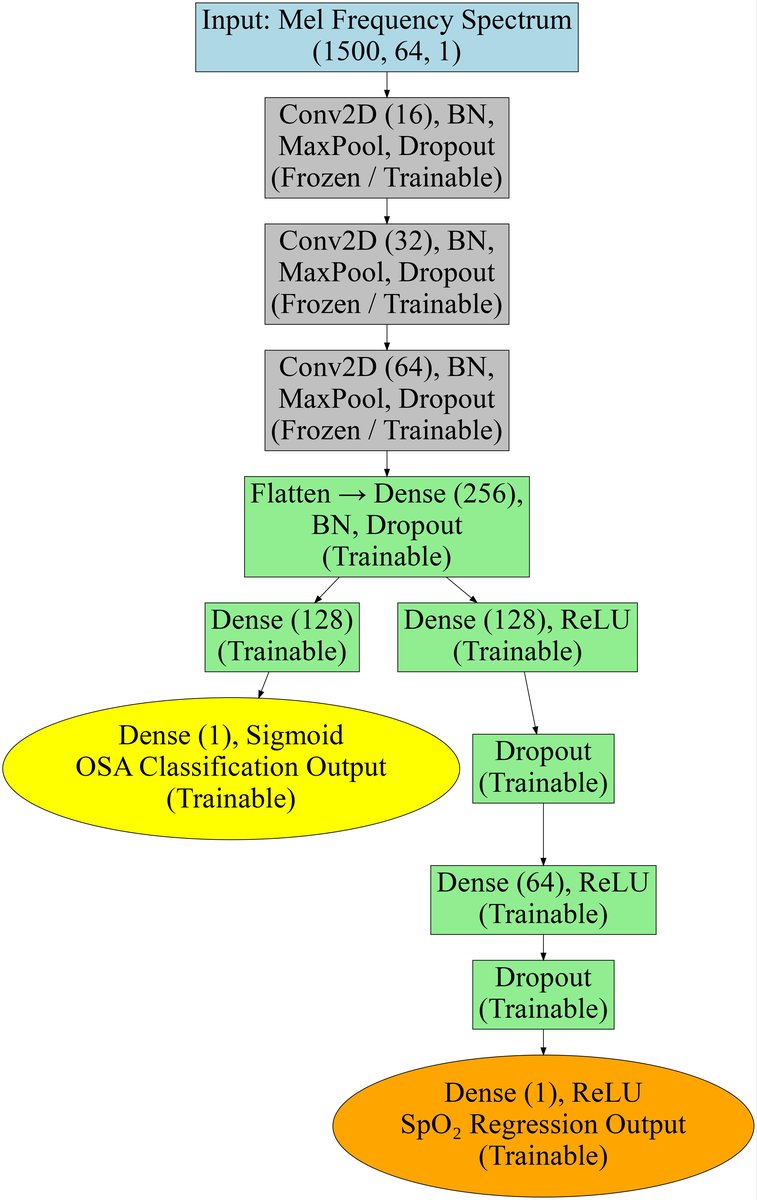
🏗️ 模型架构
模型整体是一个基于CNN的声学特征提取与预测框架,旨在从呼吸声音的梅尔频谱图中预测OSA事件和相关的生理信号(SpO2去饱和度)。
完整流程:
- 输入:30秒的音频片段,经短时傅里叶变换和梅尔滤波器组处理,得到对数梅尔频谱图
M(t, m)。 - 编码器(Encoder):一个CNN网络
g_θ,负责从频谱图中提取高维特征嵌入。 - 预测头(Prediction Head):一个任务特定的网络
h_ϕ,将特征嵌入映射到最终输出。 - 输出:根据任务设置不同,可以是:
- 单任务学习(STL):仅输出一个OSA概率
ŷ ∈ [0, 1]。 - 多任务学习(MTL):同时输出OSA概率
ŷ和SpO2去饱和比例ŝ ∈ [0, 1]。
- 单任务学习(STL):仅输出一个OSA概率
关键组件与设计选择:
- 编码器
g_θ:在预训练阶段于大规模成人数据集上训练,学习通用的呼吸声学特征表示。这是迁移学习的基础。 - 预测头
h_ϕ:在迁移学习阶段根据儿童数据进行更新。其设计体现了两种策略:- 策略1(冻结编码器):固定
g_θ的参数,仅在儿童数据上训练h_ϕ。动机是保护从成人数据学到的泛化声学特征,避免小数据集上的过拟合。 - 策略2(全微调):同时更新
g_θ和h_ϕ的参数。动机是让整个模型更好地适应儿童声音的细微差别。
- 策略1(冻结编码器):固定
- 生理延迟整合:在多任务学习中,SpO2标签
s^C的生成并非简单对齐当前30秒窗口,而是考虑了一个时间延迟Δt(如图2和图3所示)。该延迟表示从声学事件(如呼吸暂停开始)到可检测到血氧下降之间的时间差。模型通过使用延迟后的SpO2窗口(例如,将一个15秒的去饱和窗口向后平移26秒)来计算每个声学片段的监督标签ŝ。这确保了声学特征与它真正引起的生理后果在时间上对齐,提供了更符合生理规律的监督信号。
架构图:论文中的图1展示了数据收集和模型开发的完整流水线,包括预训练和微调过程。
💡 核心创新点
- 针对儿童OSA检测的迁移学习框架:首次系统性地探索了将成人睡眠声学模型迁移到儿童领域的方法。解决了儿童OSA领域数据极度稀缺、深度学习模型难以训练的核心瓶颈。
- 生理延迟建模(Physiological Delay Modelling):创新性地将“呼吸事件发生与血氧下降之间的时间延迟”这一生理先验知识形式化,并整合到模型训练中。通过比较全局延迟和个体化延迟,验证了精准的生理对齐对提升检测性能的重要性。
- 系统性多策略对比研究:设计了一个全面的实验矩阵,比较了单/多任务学习、编码器冻结/全微调、以及不同SpO2标签策略(即时/延迟/个体化延迟)的组合。这种系统性的消融研究为该类迁移学习问题提供了方法论上的参考。
- 临床相关性的评估指标:没有仅停留在事件检测,而是通过模型预测的OSA事件来推算预测AHI(呼吸暂停低通气指数),并直接与临床诊断金标准AHI进行误差分析(MAE, RMSE),使得评估结果更具临床参考意义。
🔬 细节详述
- 训练数据:
- 成人数据集:103名参与者,157晚,约1094小时数据。由SOMNOtouch™RESP设备和智能手机采集。具体预处理和增强未说明。
- 儿童数据集:15名儿童(1-15岁),15晚,约120小时数据。设备同上。由注册多导睡眠图技师手动评分。音频质量以鼾声-非鼾声比(SNR)衡量(见Table 1)。预处理包括分段(30秒窗口,10秒滑动)、短时傅里叶变换(50ms Hann窗,20ms hop)、64通道梅尔滤波器组、对数压缩和梅尔-bin归一化。
- 损失函数:多任务学习采用联合损失:
L = L_BCE(y, ŷ) + L_MSE(s, ŝ),其中L_BCE是二元交叉熵(用于OSA分类),L_MSE是均方误差(用于SpO2比例回归)。论文未说明两个损失项的权重。 - 训练策略:
- 成人预训练:50 epochs,批次大小1024,学习率
1e-3,Adam优化器。 - 儿童微调:20 epochs,批次大小8,学习率
1e-5,早停(patience=5 epochs)。使用了15折交叉验证(每折12晚训练,3晚测试)。
- 成人预训练:50 epochs,批次大小1024,学习率
- 关键超参数:音频分段长度30秒,步长10秒;梅尔滤波器组64通道;SpO2去饱和定义基于AASM指南(夜间基线下降3%),窗口大小15秒。模型具体CNN层数、通道数等细节未说明。
- 训练硬件:NVIDIA RTX 8000 GPU(48GB)。
- 推理细节:未具体说明。预测AHI通过将模型预测为OSA事件的片段进行聚合,并除以总睡眠时间得到。
- 正则化技巧:除了早停,未提及其他正则化方法。
📊 实验结果
主要评估指标为预测AHI与参考AHI之间的平均绝对误差(MAE)和均方根误差(RMSE)。实验在儿童数据集的5折交叉验证上进行,关键结果汇总于Table 1中。
Table 1: 不同模型配置在15名儿童受试者上的AHI预测误差(MAE和RMSE)
| 患者ID | 性别 | 年龄 | BMI | 参考AHI | 预测AHI (S-NF) | 预测AHI (M-NF) | 预测AHI (M-F-FD) | 预测AHI (M-UF-SD) | … (其他配置省略) |
|---|---|---|---|---|---|---|---|---|---|
| 003 | F | 5 | 15.1 | 4 | 0.11 | 0.11 | 0.11 | 0.75 | … |
| 014 | M | 8 | 28.45 | 21 | 1.56 | 19.9 | 30.1 | 23.85 | … |
| … | … | … | … | … | … | … | … | … | … |
| MAE | 4.45 | 3.64 | 3.29 | 2.81 | |||||
| RMSE | 6.81 | 6.30 | 4.55 | 3.86 |
表注:S/M: 单/多任务学习;NF/F/UF: 无微调/冻结编码器/全微调编码器;FD/SD: 固定延迟(全局中位数延迟)/个体化延迟(按夜计算)。加粗数值为该列最优。
关键结论:
- 迁移学习有效:所有微调过的模型(M-F, M-UF)的MAE和RMSE均显著低于未适应的基线模型(S-NF, M-NF),证明了迁移学习的必要性。
- 多任务学习优于单任务:在相同微调策略下,多任务学习(M-F, M-UF)通常比单任务学习(对应S-F, S-UF, 表中未完全列出)表现更好,说明联合建模OSA和SpO2能提供更丰富的信息。
- 生理延迟建模提升性能:在多任务学习框架中,使用延迟SpO2标签(FD或SD)比使用即时标签能进一步降低误差。其中,使用个体化延迟(SD)的模型取得了最佳整体性能(M-UF-SD, MAE=2.81, RMSE=3.86)。
- 全微调 vs. 冻结编码器:当不使用个体化延迟时,冻结编码器(M-F-FD)和全微调(M-UF-FD)性能相近或冻结略优,表明在生理对齐不够精确时,保留预训练特征可能有益。但当加入更精准的个体化延迟后,全微调(M-UF-SD)能达到最优。
- 临床意义:最佳模型(M-UF-SD)能更准确地识别严重OSA患者(如ID 014, 参考AHI=21, 预测23.85),同时对正常/轻度患者预测误差较小,展示了改善严重度分层的潜力。
图表分析:
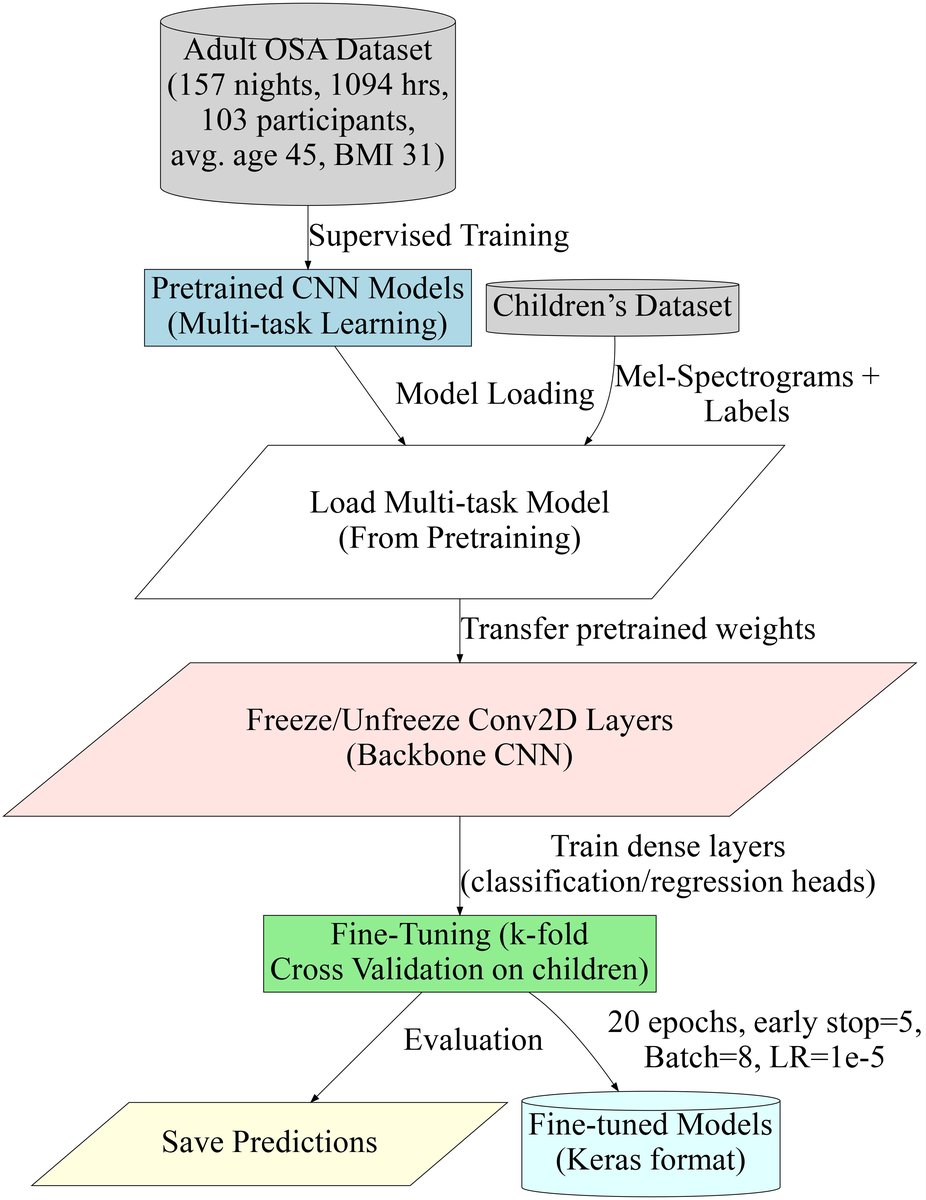 图3展示了非OSA、OSA和低通气片段在不同时间延迟下,15秒窗口内低于基线血氧的时间百分比。OSA和低通气事件的去饱和度显著高于非OSA事件,且在一定延迟(约20-30秒)后差异最为明显,这为建模生理延迟提供了实证基础。
图3展示了非OSA、OSA和低通气片段在不同时间延迟下,15秒窗口内低于基线血氧的时间百分比。OSA和低通气事件的去饱和度显著高于非OSA事件,且在一定延迟(约20-30秒)后差异最为明显,这为建模生理延迟提供了实证基础。
 图2示意了如何通过滑动一个15秒的氧去饱和窗口(红色虚线框)来寻找与声学事件(梅尔频谱)在时间上最匹配的生理信号。
图2示意了如何通过滑动一个15秒的氧去饱和窗口(红色虚线框)来寻找与声学事件(梅尔频谱)在时间上最匹配的生理信号。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个完整且有临床洞察力的技术框架,方法论系统(迁移学习+多任务学习+生理建模),实验设计包含丰富的消融对比。主要扣分点在于验证的脆弱性:整个研究建立在仅15例儿童数据的交叉验证上,没有外部测试集,这使得所有性能数字和结论的可靠性都大打折扣。这是医学AI论文的常见短板,但对本文影响尤为突出。
- 选题价值:1.5/2:选题精准切入儿童OSA诊断的临床痛点,具有明确的社会价值和应用前景。将声学、迁移学习与生理学知识结合的方向具有启发性。然而,问题领域相对垂直,受众和直接影响力有限。
- 开源与复现加成:0/1:论文完全没有提及任何代码、模型权重��数据集的公开计划。训练细节(如具体的CNN架构)也未提供,这几乎完全阻止了他人复现和验证其工作,是重大的扣分项。