📄 Training Dynamics-Aware Multi-Factor Curriculum Learning for Target Speaker Extraction
#语音分离 #课程学习 #音频安全 #数据集
✅ 7.0/10 | 前25% | #语音分离 | #课程学习 | #音频安全 #数据集
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Yun Liu(日本国立信息学研究所;综合研究大学院大学)
- 通讯作者:未说明(论文未明确指定通讯作者,通常根据邮箱判断,此处多个邮箱并列)
- 作者列表:Yun Liu(日本国立信息学研究所 & 综合研究大学院大学)、Xuechen Liu(日本国立信息学研究所)、Xiaoxiao Miao(昆山杜克大学自然科学与应用科学部)、Junichi Yamagishi(日本国立信息学研究所 & 综合研究大学院大学)
💡 毒舌点评
亮点:将“训练动态可视化”(Dataset Cartography)引入TSE任务,并创新性地结合多因子(SNR、说话人数、重叠率、数据来源)联合调度,克服了传统课程学习依赖预设单一难度指标的缺陷,在复杂多说话人场景下取得了显著的性能增益。 短板:实验仅在单一数据集(Libri2Vox)和一种相对简单的BLSTM模型上验证,未在更先进的模型架构(如基于Transformer的)和更多元的数据集上测试其通用性;TSE-Datamap区域的划分比例(30%,50%,20%)是经验值,缺乏理论支撑或自动优化机制。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:提及了使用Libri2Vox数据集及其合成变体,并引用了相关数据集论文,但未提供本工作生成的数据或脚本。
- Demo:未提及。
- 复现材料:提供了较详细的训练配置(优化器、学习率调度、早停)、数据采样参数、模型架构描述,但缺少超参数网格搜索细节、具体的数据预处理脚本和硬件信息。
- 论文中引用的开源项目:ECAPA-TDNN(预训练说话人模型)、SALT(语音合成模型)、SynVox2(语音匿名化/合成模型)。
- 论文中未提及开源计划。
📌 核心摘要
问题:现有针对目标说话人提取(TSE)的课程学习方法通常单独处理不同难度因子(如SNR、说话人数),无法建模因子间的复杂交互,且依赖可能不符合模型实际学习情况的预设难度指标。
方法核心:提出多因子课程学习策略,联合调度SNR、干扰说话人数、时间重叠比和干扰源类型(真实/合成)四个因子;同时提出TSE-Datamap框架,通过跟踪训练过程中每个样本的损失置信度和变异性,在二维空间将数据分为“易学习”、“模糊”和“难学习”三个区域,以指导数据选择。
创新:相较于传统单因子、预设规则的课程学习,本文方法实现了多因子协同渐进式学习,并首次将训练动态可视化(TSE-Datamap)应用于TSE,使课程设计基于模型实际学习行为。
实验结果:在Libri2Vox数据集上,所提多因子课程学习相比随机采样基线,在2、3、4个干扰说话人的测试集上iSDR分别提升0.84 dB、1.52 dB、2.05 dB(相对提升约24.5%)。基于TSE-Datamap的“易-模糊-难”(E/A/H)课程顺序表现最佳,在4说话人场景下比手工设计的多因子课程再提升0.11 dB。关键实验数据见下表:
实验设置 iSDR (dB) - 2spk iSDR (dB) - 3spk iSDR (dB) - 4spk 基线 (随机采样) 12.38 8.56 7.16 多因子课程 (手工设计) 13.22 10.08 9.21 TSE-Datamap (E/A/H) 13.15 9.85 9.32 注:E/A/H策略在更复杂的4说话人场景下表现最优。 实际意义:为TSE等复杂语音处理任务提供了一种更智能、数据驱动的训练范式,能有效提升模型在极端条件(多说话人、低信噪比)下的性能和鲁棒性。
主要局限:研究局限于单一模型架构和单一数据集;TSE-Datamap分析需要额外的训练周期来收集动态信息,增加了前期计算成本;课程设计区域划分标准(如30%模糊样本)仍具有启发性。
🏗️ 模型架构
论文采用的模型架构相对标准,重点在于训练策略而非模型创新。
- 整体流程:输入为单通道混合语音信号
y和目标说话人参考语音c。模型输出为目标语音的估计★_star。 - 主要组件:
- 特征提取:使用80维log-mel滤波器组特征作为声学输入。使用预训练且冻结的ECAPA-TDNN模型从参考语音
c中提取说话人嵌入向量,作为辅助信息。 - 核心网络:采用两层256维双向LSTM(BLSTM)网络,处理时频特征,捕获时间依赖性。
- 掩码估计与输出:BLSTM后接全连接层,生成时频掩码,用于从混合语音中估计目标语音的频谱。
- 特征提取:使用80维log-mel滤波器组特征作为声学输入。使用预训练且冻结的ECAPA-TDNN模型从参考语音
- 数据流与交互:参考语音
c的嵌入向量与混合语音的特征在输入或网络中间层进行融合(论文未详细说明融合方式),以指导模型“关注”目标说话人。网络输出掩码,应用于混合语音特征,得到估计的目标语音特征,再经逆变换(未说明,通常为iSTFT)得到时域波形。 - 设计动机:使用ECAPA-TDNN提供强说话人判别能力,BLSTM擅长建模语音的序列特性,这是一种已被验证有效的TSE基础架构。论文强调其课程学习策略对不同架构具有可迁移性。
- 架构图:论文中未提供模型架构图。
💡 核心创新点
- 多因子联合课程学习策略:是什么:同时考虑并协同调度SNR、干扰说话人数、时间重叠比、干扰源类型四个复杂度因子来安排训练数据。之前局限:传统CL仅沿单一维度(如SNR)调整难度,忽略了因子间非线性交互对实际难度的影响。如何起作用:使模型能平滑地从简单(如高SNR、单干扰、低重叠)场景过渡到复杂(如低SNR、多干扰、高重叠)场景,避免学习不稳定。收益:在更复杂的多说话人测试场景中(3、4个干扰者)获得了比单因子课程更大的性能提升。
- TSE-Datamap:基于训练动态的数据选择框架:是什么:通过跟踪训练过程中每个样本的损失均值(置信度)和标准差(变异性),在二维平面上映射样本,划分出“易学习”、“模糊”、“难学习”三个区域。之前局限:CL的难度因子基于人工预设,可能与模型实际感知的难度不匹配。如何起作用:直接利用模型训练过程中的反馈信息来定义样本难度,使课程设计“因材施教”。收益:实验表明,基于此框架的“易->模糊->难”课程顺序是最优的,验证了先建立可靠决策边界、再处理模糊和困难样本的策略有效性。
- 系统性实验证明多因子优于单因子:是什么:通过详尽的对照实验,比较了仅改变SNR、仅改变说话人数、仅改变重叠比等单因子课程与多因子课程的效果。之前局限:缺少对不同因子贡献度及其交互作用的定量分析。如何起作用:为多因子课程的优越性提供了直接的实验证据。收益:清晰地显示多因子课程在全部测试条件(尤其是复杂条件)下均取得最佳性能,且性能增益随任务复杂度增加而放大。
🔬 细节详述
- 训练数据:
- 数据集:Libri2Vox(主数据集),由LibriTTS(目标)和VoxCeleb2(干扰)混合而成。包含真实和合成(使用SALT, SynVox2生成)干扰语音。
- 规模:训练集约250小时混合语音(149,691个话语),验证集8.97小时,测试集8.56小时。
- 预处理/增强:训练时,四个难度因子从指定范围均匀采样:SNR ∈ {0, 5, 10, 15} dB,重叠比 ∈ {0, 0.2, 0.4},干扰说话人数 ∈ {1, 2, 3},干扰源类型 ∈ {真实,合成,混合}。
- 损失函数:SNR-based Loss。对于样本
i,损失M_i = -10 log10( ||★_star,i||^2 / ||★_star,i - ★_star,i||^2 ),即估计语音与真实语音的信噪比(单位dB)的负数。作用是最大化输出语音质量。 - 训练策略:
- 优化器:Adam,初始学习率2e-4。
- 学习率调度:预热5000步至1e-3(指数增长),随后采用Noam调度(与步长倒数平方根成比例衰减),最终衰减至1e-5。
- 训练轮数:TSE-Datamap分析跟踪50个epoch的动态。主实验的总epoch数未明确说明,但采用了早停策略(验证集损失耐心为6个epoch)。
- 批次大小:未说明。
- 关键超参数:BLSTM层数:2;隐藏维度:256;输入特征:80维log-mel滤波器组;说话人嵌入:冻结的ECAPA-TDNN预训练模型。
- 训练硬件:未说明。
- 推理细节:未说明具体解码策略。评估指标为SDR和iSDR(输入混合语音与估计语音的SDR之差)。
- 正则化/稳定训练:使用了早停策略防止过拟合。学习率调度本身有助于稳定训练。
📊 实验结果
论文在Libri2Vox数据集上进行了全面实验,所有测试集使用真实干扰语音,重叠比为0.0。
主要对比实验结果(iSDR,单位dB):
| 方法 | 2个干扰说话人 | 3个干扰说话人 | 4个干扰说话人 |
|---|---|---|---|
| 基线(随机采样) | 12.38 | 8.56 | 7.16 |
| 基线-CL(单因子:说话人数) | 12.58 | 8.78 | 7.40 |
| 单因子课程:SNR | 13.04 | 9.71 | 8.62 |
| 单因子课程:重叠比 | 12.62 | 9.87 | 8.76 |
| 单因子课程:干扰源(合成) | 11.22 | 8.43 | 9.19 |
| 单因子课程:干扰源(混合) | 12.73 | 9.51 | 8.96 |
| 单因子课程:说话人数(固定为1) | 12.80 | 7.79 | 6.73 |
| 多因子课程(手工设计) | 13.22 | 10.08 | 9.21 |
| 结论:多因子课程在所有场景下均优于单因子课程和基线,在最复杂的4说话人场景下相对基线提升约24.5%。 |
TSE-Datamap课程顺序对比实验(iSDR,单位dB):
| 顺序 | 2spk | 3spk | 4spk |
|---|---|---|---|
| 基线 | 12.38 | 8.56 | 7.16 |
| 多因子课程 | 13.22 | 10.08 | 9.21 |
| E/A/H | 13.15 | 9.85 | 9.32 |
| E/H/A | 12.93 | 9.63 | 9.18 |
| A/E/H | 12.82 | 9.61 | 9.22 |
| A/H/E | 12.96 | 9.72 | 9.17 |
| H/E/A | 12.77 | 9.54 | 9.32 |
| H/A/E | 12.90 | 9.63 | 9.10 |
| E/A/H (遗忘) | 8.83 | 5.43 | 5.52 |
| 结论:E/A/H(易->模糊->难)是最有效的顺序。先呈现模糊样本(A)比先呈现困难样本(H)更有利于后续学习。遗忘实验证明持续学习所有阶段数据是必要的。 |
固定数据量消融实验(使用70%训练数据,iSDR,单位dB):
| 设置 | 2spk | 3spk | 4spk |
|---|---|---|---|
| 全量70%(均匀采样) | 11.37 | 8.19 | 7.17 |
| 易样本70% | 9.71 | 6.50 | 6.40 |
| 模糊样本70% | 11.67 | 8.67 | 8.61 |
| 难样本70% | 10.10 | 6.75 | 6.99 |
| 结论:在相同数据量下,优先使用“模糊”样本训练效果最好,因其持续提供有信息量的梯度,帮助模型建立更鲁棒的决策边界。 |
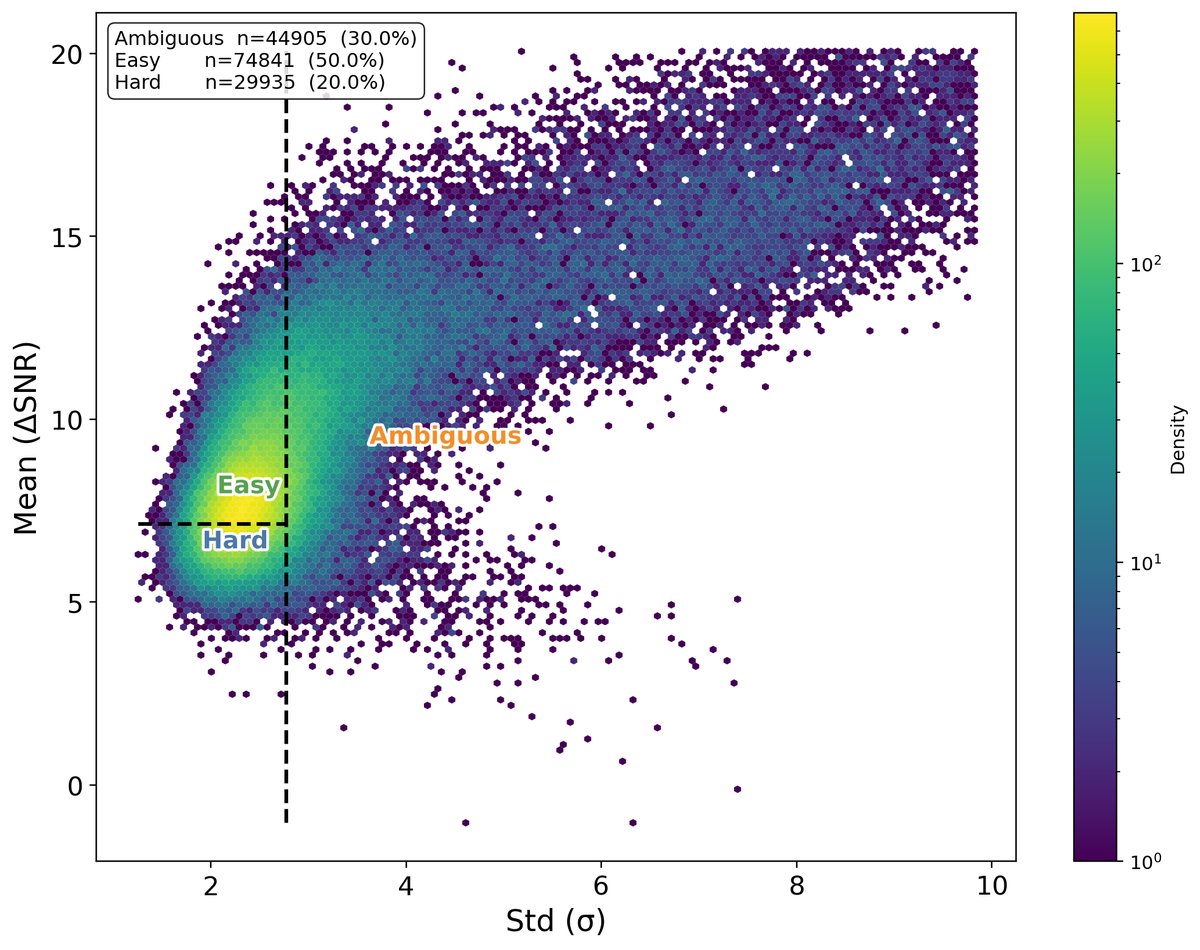 图1:TSE-Datamap可视化。每个点代表一个训练样本,X轴为损失变异性,Y轴为损失置信度(均值)。图表显示了三个典型区域:高置信度/低变异性(易学习)、高变异性(模糊)、低置信度/低变异性(难学习)。这为课程学习的数据选择提供了可视化依据。
图1:TSE-Datamap可视化。每个点代表一个训练样本,X轴为损失变异性,Y轴为损失置信度(均值)。图表显示了三个典型区域:高置信度/低变异性(易学习)、高变异性(模糊)、低置信度/低变异性(难学习)。这为课程学习的数据选择提供了可视化依据。
⚖️ 评分理由
- 学术质量:5.5/7。本文在训练策略(课程学习)上具有明确的创新(多因子、数据驱动),解决了该领域的一个实际痛点。实验设计周密,包括多组基线对比、不同课程顺序测试、固定数据量消融等,结果一致且显著。扣分点在于:1) 核心模型架构是成熟的BLSTM,未提出新的网络结构;2) TSE-Datamap的区域划分比例是启发式规则,缺乏更深入的自适应方法讨论;3) 实验未在更先进的模型和更广泛的数据集上验证泛化性。
- 选题价值:1.5/2。目标说话人提取是语音分离和听觉场景分析的核心任务��有明确的学术和应用价值(如会议转录、助听器)。课程学习作为提升模型训练效率和性能的重要范式,本文将其与该具体任务深度结合,对相关领域的研究者有参考价值。
- 开源与复现加成:0.0/1。论文详细描述了数据集、模型配置、训练策略,为复现提供了较好基础。然而,未提供源代码、预训练模型权重、TSE-Datamap的具体实现工具。对于希望直接复现或基于此工作的研究者,仍需自行编写关键部分代码,因此不给加分。