📄 Tpeformer: Temporal Patch Embedding Transformer
#多模态模型 #语音情感识别 #端到端 #预训练
✅ 7.5/10 | 前25% | #语音情感识别 | #多模态模型 | #端到端 #预训练
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 中
👥 作者与机构
- 第一作者:Ziqing Yang(Department of Computer Science, New York Institute of Technology, New York, United States)
- 通讯作者:未说明(论文未明确标注)
- 作者列表:Ziqing Yang(纽约理工学院计算机系)、Houwei Cao(纽约理工学院计算机系)
💡 毒舌点评
亮点:论文巧妙地将Mamba2模型引入作为ViT的位置编码,这不仅是一个新颖的技术融合,更在实验上证明了其在数据稀缺场景下相比传统位置编码的优越性,提升了模型的数据效率。短板:号称是端到端多模态系统,但实验仅在CREMA-D这一个规模不大的数据集上完成,泛化能力未经考验;且全篇未提供任何代码或模型链接,所谓的“从零训练”和“效率提升”在缺乏复现支持的情况下,说服力打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及是��公开预训练或训练完成的模型权重。
- 数据集:使用公开数据集CREMA-D,可通过相关论文或数据集主页获取。
- Demo:未提及在线演示。
- 复现材料:论文提供了一些训练细节(如数据采样方式、梅尔频谱图参数、训练轮次、学习率策略),但不足以完全复现。未提供模型具体配置、检查点或详细附录。
- 论文中引用的开源项目:引用并依赖了以下开源工作的实现:ResNet-18 [11]、Mamba/Mamba2 [12, 13]、标准Transformer [16]。但未说明具体使用了哪个官方代码库。
- 论文中未提及任何开源计划。
📌 核心摘要
- 问题:多模态情感识别在现实场景中常面临数据有限的问题,而主流的大规模预训练模型(如ViT、AST)在此条件下效率低下、收敛慢,且模型参数量大。
- 方法核心:提出TPEformer,一个端到端的多模态情感识别模型。其核心是使用ResNet-18作为特征提取器并进行“特征级”patch化,然后用双向Mamba2模块替代传统的位置编码,以更高效地捕捉时序依赖关系,最后采用标准Transformer编码器和瓶颈融合策略进行多模态决策。
- 创新点:1) 将Mamba2模型适配为Transformer的位置编码,利用其选择性状态空间特性增强时序建模和数据效率;2) 采用从ResNet中间层提取特征再进行patch化的方法,而非直接对像素或原始频谱图进行patch,平衡了全局与局部特征;3) 整个架构可灵活嵌入现有Transformer骨干网络。
- 主要实验结果:在CREMA-D数据集上,多模态TPEformer(使用预训练ResNet权重)达到85.2% 的准确率,超越了预训练的ViT & AST融合基线(81.4%)、MultiMAE-DER-FSLF(79.4%)等现有方法。即使从零训练,其性能(81.4%)也与预训练基线持平,同时参数量从1.72亿减少至1.08亿。消融实验表明,移除Patchify ResNet会导致性能骤降至0.450,而Mamba2在配合它时能将准确率从0.791提升至0.852。
- 实际意义:为资源受限(数据量小、算力有限)的多模态情感识别任务提供了一个轻量、高效且性能优异的解决方案,降低了对该类技术应用的门槛。
- 主要局限性:实验验证仅在一个公开数据集(CREMA-D)上进行,缺乏在更多元、更大规模数据集上的泛化性验证;未探讨模型在包含更多模态(如文本)或更复杂情感场景下的表现。
🏗️ 模型架构
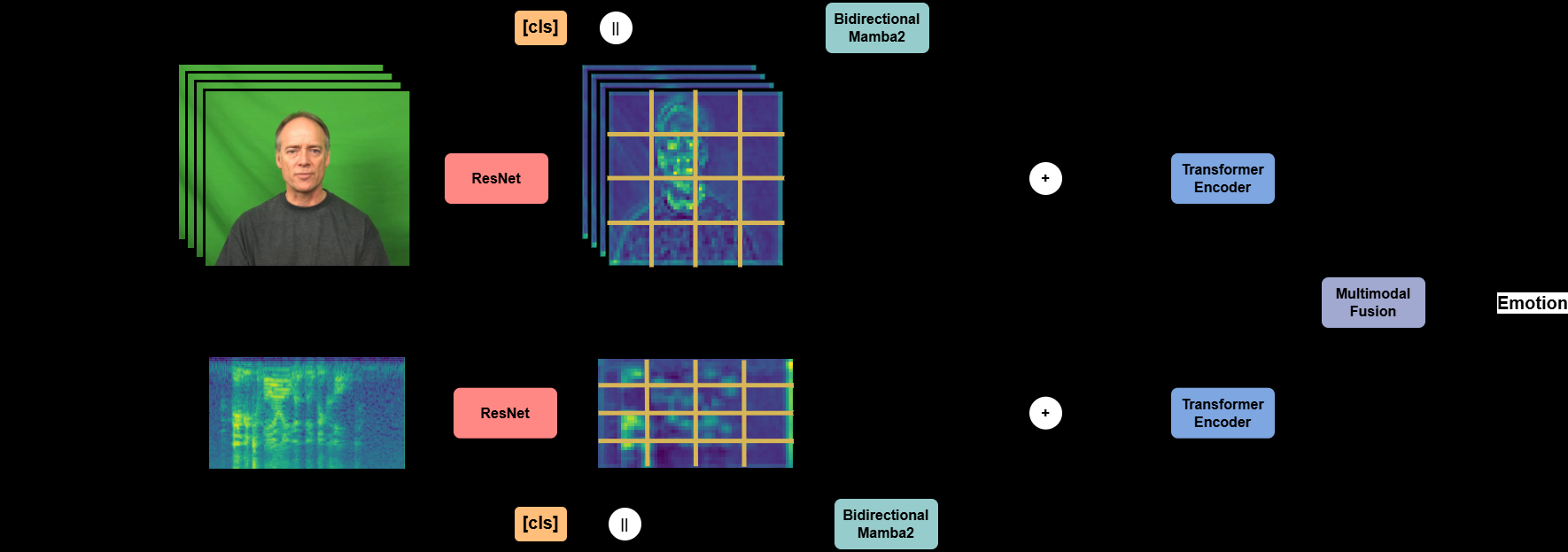
如图1所示,TPEformer的架构包含两个对称的流(音频流和视频流)以及一个融合模块。
- 输入处理:
- 视频流:输入视频随机采样16帧RGB图像。
- 音频流:输入音频波形转换为梅尔频谱图(128 Mel bins)。
- 特征提取与Patch化(Patchify ResNet):
- 两个流分别使用一个ResNet-18作为骨干网络,提取特征。关键在于,模型不使用ResNet最初的浅层特征图,而是使用Stage 4的输出作为特征图。
- 提取出的特征图(例如,对于视频是
H' x W' x C的特征图)被划分为不重叠的patch序列,形成N个P维的token序列(N = (H'/p) * (W'/p),p为patch大小)。这个过程称为“特征级patch化”,它显著缩短了序列长度(相比对原始输入进行patch),同时保留了丰富的特征信息。这种设计兼容任何以patch序列作为输入的Transformer变体(如ViT, AST)。
- 位置编码(Mamba2):
- 在将patch化后的token序列送入Transformer编码器之前,先经过一个双向Mamba2模块。Mamba2的输出被加回到原始输入token上,作为位置编码。这替代了ViT中传统的可学习1D绝对位置编码。Mamba2利用其状态空间模型的特性,对序列进行内容感知的推理,动态地为每个token融入时序上下文信息。
- Transformer编码器:
- 经过Mamba2处理后的序列(每个模态的序列开头会拼接一个分类
[CLS]token),被送入标准的Transformer编码器。该编码器结构与ViT/AST一致,由多头自注意力(MSA)和前馈网络(MLP)构成,并使用残差连接和层归一化。
- 经过Mamba2处理后的序列(每个模态的序列开头会拼接一个分类
- 多模态融合(瓶颈融合):
- 两个模态的Transformer编码器输出序列被序列拼接(
z^rgb || z^spec)。 - 引入一个瓶颈融合token
z_fsb,通过多头交叉注意力(MCA) 与拼接后的多模态表征进行交互(公式5),使瓶颈token吸收全局多模态信息。 - 更新后的瓶颈token
z'_fsb再分别通过MCA与原始的各模态表征进行交互(公式6,7),将融合后的全局上下文信息反馈回每个模态的流中,实现双向信息交换,最后取各模态的[CLS]token表示进行分类预测。
- 两个模态的Transformer编码器输出序列被序列拼接(
关键设计选择及动机:
- 特征级Patch化:动机是借鉴“卷积stem”能提升ViT在小数据集上的训练稳定性和收敛速度。与直接对像素patch化相比,使用ResNet中间层特征能提供更鲁棒的表征,减少序列长度,同时保持架构的通用性。
- Mamba2作为位置编码:动机是解决传统可学习位置编码在数据有限时学习不充分的问题。Mamba2的线性递归模式天然适合建模时序依赖,其二次模式可引入数据依赖的软性位置偏置,两者结合在低资源场景下表现出更高的数据效率。
- 瓶颈融合:动机是采用一种轻量且有效的多模态融合策略,通过引入一个共享的瓶颈token来建模跨模态依赖,避免直接拼接所有特征带来的高计算成本。
💡 核心创新点
- 将Mamba2创新性地适配为Transformer位置编码:这是论文最核心的创新。之前方法使用可学习绝对编码(如ViT)或固定编码(如正弦编码、RoPE)。本方法利用双向Mamba2模块,在Transformer骨干网络之前对patch序列进行处理,动态地、内容感知地融入时序上下文,从而同时提供软性位置偏置和深层时序建模能力。实验证明,其性能显著优于其他位置编码方案(如RoPE、可学习相对PE等)。
- 采用“特征级Patch化”作为通用嵌入机制:创新性地使用ResNet-18的Stage 4特征图进行patch化,而非原始输入。这既引入了有益的归纳偏置(卷积先验),又大幅减少了序列长度,使模型在保持性能的同时更轻量、训练更快。该设计被强调为可无缝集成到任何基于patch的Transformer架构中。
- 构建从零训练且高性能的端到端多模态系统:针对依赖预训练大模型的主流方法,论文提出了一个完全可从零开始训练的架构。通过结合上述两个创新点(更好的特征提取+更高效的位置编码),该模型在CREMA-D数据集上,仅用1.08亿参数就达到了与1.72亿参数的预训练ViT+AST基线相当甚至更优的性能,展现了在数据有限场景下的高数据效率和实用性。
🔬 细节详述
- 训练数据:CREMA-D数据集,包含7,442个视频片段,91名演员,6种基本情感(愤怒、厌恶、恐惧、快乐、中性、悲伤)。划分:5,733训练,1,638测试。预处理:视频每批次随机采样16帧;音频使用汉宁窗、128个Mel频率带、25ms帧长计算梅尔频谱图,最大帧数截断为512。论文中未提及使用了额外数据增强。
- 损失函数:论文中未明确提及损失函数名称。根据任务(6类分类),通常使用交叉熵损失。
- 训练策略:训练30个epoch,批次大小16。学习率初始为0.001,采用步进衰减策略,每两个周期衰减一次,学习率依次变为0.0005,0.0003,0.0001并循环。优化器未说明。Warmup策略未说明。
- 关键超参数:模型参数量:108M。Transformer骨干网络结构与ViT/AST保持一致,具体层数、隐藏维度、注意力头数等未在文中说明。
- 训练硬件:在RTX A6000 GPU上评估了训练速度(表2),但未说明训练所用的具体GPU型号、数量和总训练时长。
- 推理细节:论文未说明推理时的解码策略、温度、beam size等具体设置。任务为分类,通常直接取最终分类token的预测。
- 正则化或稳定训练技巧:论文提到了使用残差连接和层归一化来稳定训练。未明确提及其他如Dropout、权重衰减等技术细节。
📊 实验结果
实验在CREMA-D数据集上进行,主要评估情绪分类准确率。
表1:不同模态下的情绪分类准确率
| 模态 | 模型 | 准确率 |
|---|---|---|
| 仅音频 | Pretrained ViT & AST | 0.551 |
| TPEformer (Ours, w/o Pretrain) | 0.595 | |
| 仅视频 | Pretrained ViT & AST | 0.699 |
| TPEformer (Ours, w/o Pretrain) | 0.718 | |
| TPEformer (Ours, Pretrained) | 0.798 | |
| 多模态 | MultiMAE-DER-FSLF | 0.794 |
| VQ-MAE-AV | 0.804 | |
| Pretrained ViT & AST | 0.8136 | |
| TPEformer (Ours, w/o Pretrain) | 0.8143 | |
| TPEformer (Ours, Pretrained) | 0.852 |
关键结论:在单模态(尤其音频)和多模态设置下,TPEformer均超越了预训练的ViT&AST基线和其他SOTA方法。其多模态性能提升显著,从零训练版本即达到与预训练基线相当的水平。
表2:模型参数与训练效率对比 (RTX A6000)
| 模型 | 模型参数量 | RTX A6000上的训练速度 |
|---|---|---|
| Pretrained ViT & AST | 172M | 0.2500 |
| TPEformer (Ours, w/o Pretrain) | 108M | 0.0625 |
| TPEformer (Ours, Pretrained) | 108M | 0.0625 |
关键结论:TPEformer的参数量比预训练基线减少约37.2%,训练速度(推测为每个迭代所需时间)快4倍,体现了模型的轻量和高效。
表3:TPEformer组件消融实验
| Patchify ResNet | Mamba2 位置编码 | 准确率 |
|---|---|---|
| ✓ | ✓ | 0.852 |
| ✓ | ✗ | 0.791 |
| ✗ | ✓ | 0.450 |
| ✗ | ✗ | 0.449 |
关键结论:Patchify ResNet是性能的关键基础,移除它会导致准确率从0.852暴跌至0.450左右。Mamba2位置编码在有Patchify ResNet的基础上能带来+6.1% 的显著提升(0.791 -> 0.852),两者协同工作效果最佳。
表4:位置编码方式消融实验(以1D可学习绝对PE为基线)
| 配置 | 准确率 | 与基线相比的差值 |
|---|---|---|
| TPEformer (1D learnable Absolute PE) | 0.791 | - |
| + Learnable Relative PE | 0.770 | -2.1% |
| + Convolutional Relative PE | 0.812 | +2.1% |
| + Rotary PE (2D RoPE) | 0.820 | +2.9% |
| TPEformer (Mamba2) | 0.852 | +6.1% |
关键结论:Mamba2作为位置编码的性能(+6.1%)显著优于包括RoPE在内的其他先进位置编码方案。论文指出,Mamba2的优势超越了单纯的位置偏置,它提供了序列级的上下文建模能力。
⚖️ 评分理由
- 学术质量:6.0/7:论文技术路线清晰,创新点(Mamba2用于位置编码、特征级Patch化)有实际价值和实验证明。架构描述和消融实验比较完整,说服力较强。扣分点主要在于实验部分:仅在单个数据集(CREMA-D)上验证,缺乏跨数据集泛化性分析;与基线的对比虽然取得了优势,但SOTA的定义域较窄;部分技术细节(如Transformer具体配置、损失函数)缺失。
- 选题价值:1.5/2:情感计算是重要应用领域,多模态是趋势。论文关注数据有限这一实际痛点,并提出了轻量化的解决方案,具有应用价值。但该任务本身并非当前AI最前沿的突破点,影响力和关注度相对有限。
- 开源与复现加成:0/1:论文完全未提及代码、模型权重的开源计划。虽然给出了一些训练超参数,但缺少完整的复现指南(如环境配置、完整代码、预处理脚本),使得“从零训练”的承诺难以被读者独立验证,严重影响了其可复现性和影响力。