📄 Toward Faithful Explanations in Acoustic Anomaly Detection
#音频事件检测 #自监督学习 #工业应用
✅ 7.5/10 | 前25% | #音频事件检测 | #自监督学习 | #工业应用
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Maab Elrashid(1 Mila-Quebec AI Institute, 2 Concordia University, 3 FORAC Research Consortium, 4 Université Laval)
- 通讯作者:未说明
- 作者列表:Maab Elrashid (Mila-Quebec AI Institute, Concordia University, FORAC Research Consortium, Université Laval), Anthony Deschênes (FORAC Research Consortium, Université Laval), Cem Subakan (Mila-Quebec AI Institute, Concordia University), Mirco Ravanelli (Mila-Quebec AI Institute, Concordia University), Rémi Georges (FORAC Research Consortium, Université Laval), Michael Morin (FORAC Research Consortium, Université Laval)
💡 毒舌点评
亮点: 论文聚焦于一个被忽视但至关重要的维度——异常检测模型的“可解释性”,并针对工业场景提出了严谨的评估协议(结合专家标注与忠实度指标),工作扎实且具实用导向。 短板: 所提核心改进(掩码自编码器MAE)对检测性能有轻微损害(AUC从0.916降至0.902),且在解释性提升方面的创新性更多是“应用适配”而非“方法论突破”,更像一项扎实的对比消融研究。
🔗 开源详情
- 代码:论文提供了代码仓库链接:
https://github.com/Maab-Nimir/Faithful-Explanations-in-Acoustic-Anomaly-Detection。 - 模型权重:论文未明确提及是否公开训练好的模型权重。
- 数据集:论文明确使用并提供了公开数据集的引用([1]),且论文提供的代码仓库中应包含处理后的数据或获取说明。人工标注的测试集(46条)也包含在上述GitHub仓库中。
- Demo:论文中未提及在线演示。
- 复现材料:论文给出了详细的训练设置(优化器、学习率、批大小、轮数、调度策略)、模型消融实验结果、评估指标计算方法。代码仓库的提供使得完全复现成为可能。
- 引用的开源项目:使用了Captum库进行模型解释。
📌 核心摘要
- 问题:基于深度学习的声学异常检测模型(如自编码器)性能虽强,但作为“黑箱”缺乏可解释性,可能依赖虚假特征,在工业安全关键场景中难以建立用户信任。
- 方法:在真实的工业木材刨床声学异常检测任务上,系统比较了标准自编码器(AE)与掩码自编码器(MAE)。应用了多种事后归因解释方法(误差图、显著图、SmoothGrad、集成梯度、GradSHAP、Grad-CAM)。
- 创新:1) 将MAE训练范式引入声学异常检测以提升特征学习与可解释性;2) 提出了一种基于扰动的“忠实度”评估指标,通过替换模型指出的异常区域为模型重建值来模拟正常输入,量化解释对模型决策的影响;3) 建立了结合专家时间标注的定量评估框架(F-score与忠实度)。
- 实验结果:MAE的异常检测性能(AUC=0.902)略低于标准AE(AUC=0.916),但在所有解释方法和评估指标(F-score, 忠实度)上均表现更优。其中,MAE的误差图在忠实度上表现最佳,其显著图在F-score上得分最高(0.63)。
- 实际意义:表明通过掩码训练,可以在几乎不牺牲检测性能的前提下,显著提升模型解释的忠实度与时间精度,为工业异常检测系统提供了更可靠、可信的解释方案。
- 主要局限性:研究基于单一工业数据集,结论的泛化性有待验证;模型架构的改进(MAE)带来的解释性提升是渐进式的,而非颠覆性的;评估依赖专家标注,标注过程存在主观性。
🏗️ 模型架构
论文未提供明确的模型架构图,主要基于文字描述。
- 完整输入输出流程:输入为10秒音频片段转换成的80×401梅尔频谱图。模型(AE或MAE)学习重建该频谱图。异常检测基于输入与重建之间的均方误差(MSE)。解释方法(归因图)也基于此误差进行反向传播计算。
- 主要组件:基于先前的Skip-CAE-Transformer架构,包含:
- 编码器:由卷积层(带批归一化和池化)和Transformer编码器组成,用于提取层级特征。
- 跳跃连接:将编码器中间层特征直接传递到解码器相应层,以保留细节信息。
- 解码器:镜像编码器结构,包含Transformer解码器,负责从潜在表示和跳跃连接特征中重建频谱图。
- 关键设计与数据流:
- 标准AE:编码器处理完整输入频谱图,解码器重建完整频谱图。
- 掩码自编码器(MAE):训练时,输入频谱图被随机遮蔽(如30%),模型仅学习重建被遮蔽区域(损失函数仅计算被遮蔽区域的MSE)。推理时,输入完整频谱图,模型输出完整重建。这种训练迫使模型学习上下文信息,以推断被遮蔽部分,从而获得更鲁棒的特征表示。
- 解释方法:使用Captum库应用多种事后归因方法,将重建误差作为标量输出进行反向传播,在输入频谱图上生成2D归因图,突出对误差贡献最大的区域。
💡 核心创新点
- 将掩码自编码器(MAE)应用于声学异常检测的可解释性提升:之前MAE主要用于自监督学习或计算机视觉异常检测。本文将其适配于工业声学异常检测,实验证明其能产生更精确、忠实的异常定位解释,且几乎不影响检测性能。
- 提出基于扰动的“忠实度”(Faithfulness)评估指标:为克服传统评估指标(如F-score仅衡量与人类标注的重叠)的局限,本文提出了一种量化解释“有效性”的方法。通过将模型指出的异常区域替换为模型自身的重建(模拟“正常化”),观察重建误差的变化,从而判断该解释区域是否真正影响了模型的决策。
- 建立面向解释性的系统评估协议:结合专家听觉与频谱图检查的标注,提出时间精度F-score和忠实度分数两个互补指标,为评估声学异常检测模型的解释质量提供了可量化的方法论。
- 对多种事后解释方法在声学异常检测任务上的系统比较:全面比较了误差图、显著图、SmoothGrad、集成梯度、GradSHAP、Grad-CAM在AE和MAE模型上的表现,揭示了MAE在提升所有解释方法质量方面的普遍优势。
🔬 细节详述
- 训练数据:使用公开的工业木材刨床声学数据集。训练集包含4327个正常样本,测试集包含3235个正常样本和105个异常样本(断板、卡板、厚板不均)。音频为单声道,20kHz采样,转换为80×401的梅尔频谱图。
- 损失函数:
- AE:标准均方误差损失(MSE),计算整个重建频谱图与原始输入的误差。
- MAE:掩码均方误差损失(LMAE),仅计算被随机掩蔽区域(二进制掩码M)的重建误差。公式:LMAE = (1/P) Σ M_ij (X_ij - \hat{X_ij})^2,其中P为被掩蔽的像素点数量。
- 训练策略:
- 优化器:AdamW
- 训练轮数:500 epochs
- 批大小:32
- 学习率:初始10^-3,采用带重启的余弦退火调度,最小10^-5,5次预热周期。
- 早停:耐心30个epoch,基于验证集损失进行模型检查点保存。
- 掩码比率消融:在4×4和16×16两种块大小下,测试了15%到90%的掩码比率。最终选择30%掩码比率和4×4块大小,取得最佳AUC(0.902)。
- 关键超参数:梅尔频谱图参数:帧长50ms,帧移25ms,80个梅尔频带。MAE掩码比率30%,块大小4×4。
- 训练硬件:单块32GB GPU。
- 推理细节:模型输入完整频谱图,输出重建频谱图。异常分数为输入与重建的逐像素MSE。归因方法(如误差图)直接基于此MSE进行反向传播生成。
- 归因图评估细节:2D归因图按频率维度求和并归一化为1D时间信号。使用高百分位阈值(如98th)识别峰值,与专家标注的1秒区间比较计算F-score。忠实度评估采用“基于段”的替换策略,即替换包含峰值且与标注重叠的完整1秒片段。
📊 实验结果
论文主要比较了AE与MAE在检测性能和解释质量上的表现。
主要检测性能对比:
| 模型 | 单次运行 AUC | 五次运行平均 AUC (均值±标准差) |
|---|---|---|
| 标准自编码器 (AE) | 0.916 | 0.885 ± 0.032 |
| 掩码自编码器 (MAE) | 0.902 | 0.864 ± 0.048 |
MAE的检测性能略有下降,但标准差更大,表明训练稳定性可能稍差。
解释性评估关键结果:
- F-score(图4):在所有方法和阈值上,MAE始终优于AE。MAE最佳为显著图在98th百分位阈值下的0.63,AE最佳为误差图在96th百分位阈值下的0.55。
 (图4显示MAE的F-score曲线(虚线)普遍高于AE(实线),且峰值更高。)
(图4显示MAE的F-score曲线(虚线)普遍高于AE(实线),且峰值更高。) - 忠实度分数(图5):同样,MAE在所有方法和阈值上均优于AE。MAE的误差图在95%-98%阈值范围内忠实度得分最高,表明其突出的区域对模型误差影响最大。
 (图5显示MAE的忠实度分数(虚线)普遍高于AE(实线),尤其是误差图。)
(图5显示MAE的忠实度分数(虚线)普遍高于AE(实线),尤其是误差图。) - 定性分析(图3):以断板异常为例,MAE的归因图(特别是误差图)产生的解释更集中、结构化,清晰勾勒出异常的非直线水平线,且与标注区域吻合度更高。AE的归因图则较为分散或聚焦于无关区域。
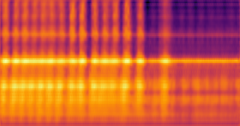 (图3展示了AE和MAE在同一异常样本上,六种解释方法生成的2D归因图及其二值化掩码和1D时间信号。MAE的结果明显更聚焦于标注的异常区域。)
(图3展示了AE和MAE在同一异常样本上,六种解释方法生成的2D归因图及其二值化掩码和1D时间信号。MAE的结果明显更聚焦于标注的异常区域。)
⚖️ 评分理由
- 学术质量:5.5/7。论文工作扎实,技术路线清晰,实验设计合理(包含消融、多方法比较、定量与定性分析)。创新点在于将MAE适配至声学异常检测并系统评估解释性,提出了有意义的忠实度评估指标。然而,核心方法(MAE)是现有技术的直接应用,创新性主要体现在应用和评估框架的构建上,未提出新的网络结构或理论。
- 选题价值:1.5/2。可解释AI是当前重要方向,尤其是在工业监测等高风险领域。论文直接针对这一痛点,研究结果具有明确的实用价值,能指导工业界构建更可信的异常检测系统。选题与音频/语音读者相关性高。
- 开源与复现加成:0.5/1。论文提供了代码仓库和标注数据集的GitHub链接,极大提升了可复现性。训练细节、超参数、评估协议描述详尽。扣0.5分是因为模型权重未明确提及是否公开,且评估依赖特定的人工标注数据。