📄 TMD-TTS: A Unified Tibetan Multi-Dialect Text-to-Speech Framework for Ü-Tsang, Amdo and Kham Speech Dataset Generation
#语音合成 #流匹配 #方言建模 #低资源 #数据集
✅ 7.5/10 | 前25% | #语音合成 | #流匹配 | #方言建模 #低资源
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yutong Liu(电子科技大学信息与软件工程学院)、Ziyue Zhang(电子科技大学信息与软件工程学院)(论文显示两人贡献相等,标注为†)
- 通讯作者:Yongbin Yu(电子科技大学信息与软件工程学院)、Xiangxiang Wang(电子科技大学信息与软件工程学院)、Nyima Tashi(电子科技大学信息与软件工程学院 & 西藏大学信息科学技术学院)
- 作者列表:Yutong Liu(电子科技大学信息与软件工程学院),Ziyue Zhang(电子科技大学信息与软件工程学院),Ban Ma-bao(电子科技大学信息与软件工程学院),Renzeng Duojie(西藏大学信息科学技术学院),Yuqing Cai(电子科技大学信息与软件工程学院),Yongbin Yu(电子科技大学信息与软件工程学院),Xiangxiang Wang(电子科技大学信息与软件工程学院),Fan Gao(电子科技大学信息与软件工程学院),Cheng Huang(美国德克萨斯大学西南医学中心眼科),Nyima Tashi(电子科技大学信息与软件工程学院 & 西藏大学信息科学技术学院)
💡 毒舌点评
亮点在于其问题定义精准——直接针对藏语三大方言互不相通的现实痛点,并设计了端到端的解决方案与数据生成管线,形成了从模型到数据集的完整闭环。短板在于其核心方法DSDR-Net的本质是在Transformer的FFN中引入了基于方言ID的条件计算,这属于对标准架构的合理扩展,理论创新深度有限,且论文对训练损失等细节描述不足。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开TMD-TTS的预训练模型权重。
- 数据集:论文明确表示将构建并发布TMDD数据集,但未说明具体的发布平台与获取方式。
- Demo:未提及在线演示。
- 复现材料:论文给出了一些关键训练设置(优化器、步数、硬件、主要超参数),但未提供完整的配置文件、损失函数细节或预训练检查点,复现材料不够充分。
- 论文中引用的开源项目:引用了Matcha-TTS [15], BigVGAN [12], VITS2 [3], MetricGAN+ [18] 等作为基线或组件。
- 总结:论文在数据集开源方面有明确承诺,但模型和代码的开源计划未提及。
📌 核心摘要
- 解决的问题:针对藏语(卫藏、安多、康巴三方言)作为低资源语言,缺乏大规模平行语音语料库,限制了跨方言交流与语音技术发展的问题。
- 方法核心:提出TMD-TTS框架,基于Matcha-TTS(流匹配模型)构建。核心创新是引入了方言融合模块,将方言ID的嵌入与文本隐层表示融合;以及设计了方言专属动态路由网络(DSDR-Net),用以替代Transformer中的标准前馈网络(FFN)。DSDR-Net根据输入的方言ID,将信息动态路由到对应的方言专属子网络中,从而更精细地建模各方言独特的声学与韵律特征。
- 与已有方法相比新在哪里:相比先前方法(如使用独立 vocoder 或共享参数),本框架在统一的模型中通过明确的方言嵌入和条件计算机制,实现了对多方言特征更早、更深层次的建模,无需为每个方言单独训练 vocoder。
- 主要实验结果:在构建的179小时多方言数据集上,TMD-TTS在三方言上的所有主要客观指标(STOI, PESQ, SI-SDR, DNSMOS)和方言一致性指标(DCA, DECS)上均显著优于SC-CNN、VITS2和Matcha-TTS基线。例如,在卫藏方言上,TMD-TTS的DECS为88.09%(Matcha-TTS为65.20%),DCA为67.41%(Matcha-TTS为65.80%)。消融实验表明,DSDR-Net和方言融合模块共同贡献了模型性能,移除任一模块都会导致方言一致性大幅下降。基于该模型生成的TMDD数据集(约102小时)在下游的语音到语音方言转换(S2SDC)任务中,也表现优于基线数据集。
- 实际意义:为藏语这一低资源语言提供了一个高效、可控的多方言语音合成工具,并发布了大规模、高质量的合成语音数据集(TMDD),极大地降低了相关研究的数据门槛,有望推动藏语语音技术(如语音识别、方言转换)的整体进步。
- 主要局限性:论文主要聚焦于生成能力的提升和验证,未深入探讨生成语音可能存在的“方言刻板印象”或真实细微差异的保真度上限。此外,虽然实验充分,但所有评估均基于合成数据,尚缺乏在真实、自然对话场景中的大规模效用验证。
🏗️ 模型架构
TMD-TTS是一个基于流匹配(Matcha-TTS)的端到端文本到语音(TTS)合成模型,其整体架构如图1所示。
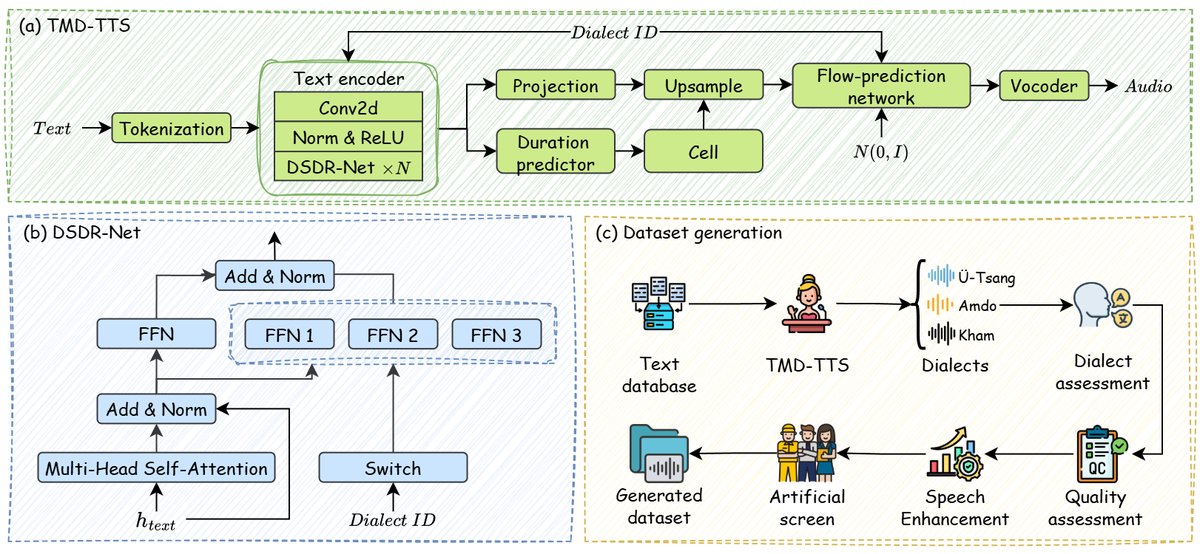
模型接收的输入是藏语文本,输出是波形语音。主要处理流程如下:
- 文本编码:藏文字符首先通过一个嵌入层和编码器,生成文本隐层表示
h_text。 - 方言融合:方言ID(0, 1, 2分别对应卫藏、安多、康巴)被映射为归一化的方言嵌入
h_did。该嵌入通过一个线性层与h_text融合,得到方言条件化的文本表示ĥ_text。公式为:ĥ_text = h_text + Linear(h_did)。 - 时长预测:一个时长预测器根据
ĥ_text估计每个音素的持续时间,用于后续的上采样。 - 声学建模(核心创新部分):上采样后的特征序列被送入一个基于Transformer的流预测网络。该网络中的每一层包含一个多头自注意力层和一个方言专属动态路由网络(DSDR-Net),后者取代了标准FFN。
- DSDR-Net内部结构(如图1(b)所示):它由一个公共FFN(
FFN_public)和一个私有FFN池(FFN_private,包含三个独立的FFN,分别对应三个方言)组成。输入特征首先经过自注意力层得到ĥ_attn。然后,系统根据当前的方言IDdid,从私有FFN池中选择对应的FFN_private,did。最终的输出是公共FFN的输出与被选中的私有FFN的输出之和。这种设计允许模型学习方言无关的通用表示(通过公共FFN),同时又能捕捉每个方言独特的声学模式(通过私有FFN)。
- DSDR-Net内部结构(如图1(b)所示):它由一个公共FFN(
- 波形生成:DSDR-Net处理后的特征经过流预测网络生成梅尔频谱图,最后由一个预训练的声码器(BigVGAN)转换为时域波形。
💡 核心创新点
- 提出TMD-TTS统一框架:首次为藏语三大方言构建了一个统一的、基于流匹配的TTS模型,克服了以往方法需要多模型或多 vocoder 的局限,实现了用一个模型生成所有方言语音。
- 设计DSDR-Net:这是核心的建模创新。它通过条件计算机制,为不同方言动态分配专用的网络路径(私有FFN),使得模型能够学习并保持各方言细微的韵律、音色等声学差异,显著提升了方言一致性和表现力。
- 构建大规模合成数据集TMDD:基于提出的TMD-TTS和一套完整的数据筛选与增强管线(包括客观质量阈值筛选和人工审核),生成了包含约102小时、近10万条语音的平行多方言数据集,极大地扩展了该领域的数据资源。
- 提出方言评估指标与工具:论文引入或使用了DECS(方言嵌入余弦相似度)等指标来定量评估生成语音的方言保真度,并承诺发布相关的评估工具包,为后续研究提供了标准化评估手段。
🔬 细节详述
- 训练数据:论文构建了一个179小时的多方言藏语语音语料库,包含44小时卫藏、45小时康巴、90小时安多方言,来自1500+说话人。训练集每方言4万样本,验证集和测试集各300样本。未说明具体的数据预处理步骤(如归一化、切分)。
- 损失函数:论文未明确说明TMD-TTS训练时所使用的具体损失函数。根据其基础模型Matcha-TTS推断,可能包含流匹配损失和时长预测损失,但论文中未给出公式或权重。
- 训练策略:TMD-TTS使用Adam优化器训练50万步。声码器(BigVGAN)使用AdamW优化器,并采用指数衰减的学习率调度。训练在两块RTX 4090 GPU上进行。未说明学习率具体数值、批大小、warmup策略。
- 关键超参数:文本词汇表大小为216个字符。方言嵌入维度为128,DSDR-Net(私有FFN)的隐藏维度为192。
- 训练硬件:两块NVIDIA RTX 4090 GPU。未说明总训练时长。
- 推理细节:使用预训练的BigVGAN声码器将梅尔频谱图转换为波形。论文未提及推理时是否使用温度调节、beam search等策略,因其为非自回归模型。
- 正则化技巧:论文未提及具体的正则化方法(如Dropout、权重衰减)。
📊 实验结果
论文进行了多维度的实验评估,主要结果如表1所示。
表1:藏语多方言TTS的客观与主观评估结果
| 方言 | 模型 | 客观指标 | 主观指标 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| STOI(%)↑ | PESQ↑ | SI-SDR(dB)↑ | DCA(%)↑ | DECS(%)↑ | DNSMOS↑ | RTF↓ | nMOS↑ | ||
| 卫藏 | SC-CNN | 80.40 | 1.62 | 7.24 | 40.37 | 65.04 | 2.16±0.38 | 0.036 | 2.83 |
| VITS2 | 85.72 | 2.00 | 9.88 | 39.26 | 41.91 | 2.53±0.35 | 0.020 | 3.18 | |
| Matcha-TTS | 93.84 | 2.43 | 12.32 | 65.80 | 65.20 | 2.77±0.15 | 0.023 | 3.73 | |
| TMD-TTS | 94.52 | 3.03 | 17.91 | 67.41 | 88.09 | 2.78±0.29 | 0.032 | 3.83 | |
| 安多 | SC-CNN | 79.90 | 1.65 | 8.25 | 59.63 | 65.04 | 2.16±0.38 | 0.036 | 2.82 |
| VITS2 | 89.13 | 1.98 | 11.28 | 39.26 | 41.91 | 2.54±0.36 | 0.021 | 3.20 | |
| Matcha-TTS | 94.54 | 2.34 | 19.17 | 75.42 | 65.32 | 2.79±0.13 | 0.023 | 3.75 | |
| TMD-TTS | 94.92 | 3.13 | 21.32 | 87.78 | 79.17 | 2.79±0.18 | 0.032 | 3.84 | |
| 康巴 | SC-CNN | 76.09 | 1.47 | 5.69 | 38.52 | 19.16 | 2.01±0.30 | 0.034 | 2.67 |
| VITS2 | 82.25 | 1.87 | 9.06 | 44.81 | 46.01 | 2.43±0.34 | 0.021 | 3.18 | |
| Matcha-TTS | 91.47 | 2.32 | 17.90 | 60.80 | 63.48 | 2.74±0.20 | 0.022 | 3.73 | |
| TMD-TTS | 93.17 | 3.05 | 21.43 | 61.11 | 67.65 | 2.77±0.17 | 0.031 | 3.86 |
关键结论:TMD-TTS在语音质量(STOI, PESQ, SI-SDR, DNSMOS)和方言一致性(DCA, DECS)上全面超越基线。特别是在DECS指标上优势明显,表明其生成的语音在方言特征嵌入空间更接近目标方言。
消融实验结果(表2): 表2:消融研究结果
| 模型变体 | DCA(%) | DECS(%) |
|---|---|---|
| TMD-TTS (完整) | 80.25 | 78.3 |
| w/o DSDR-Net | 60.12 | 58.6 |
| w/o Dialect Fusion | 74.15 | 72.8 |
| w/o Dialect Fusion & DSDR-Net | 33.42 | 32.2 |
关键结论:移除DSDR-Net或方言融合模块都会导致方言一致性指标显著下降,证明了两个模块的互补性和重要性。
数据集生成与下游任务验证:基于TMD-TTS生成的TMDD数据集(表3)规模是基线数据集的20倍以上。使用TMDD训练的S2SDC模型(DurFlex-EVC)在主观MOS上优于使用基线数据集训练的模型(表4),验证了生成数据的实用性。
图表分析:
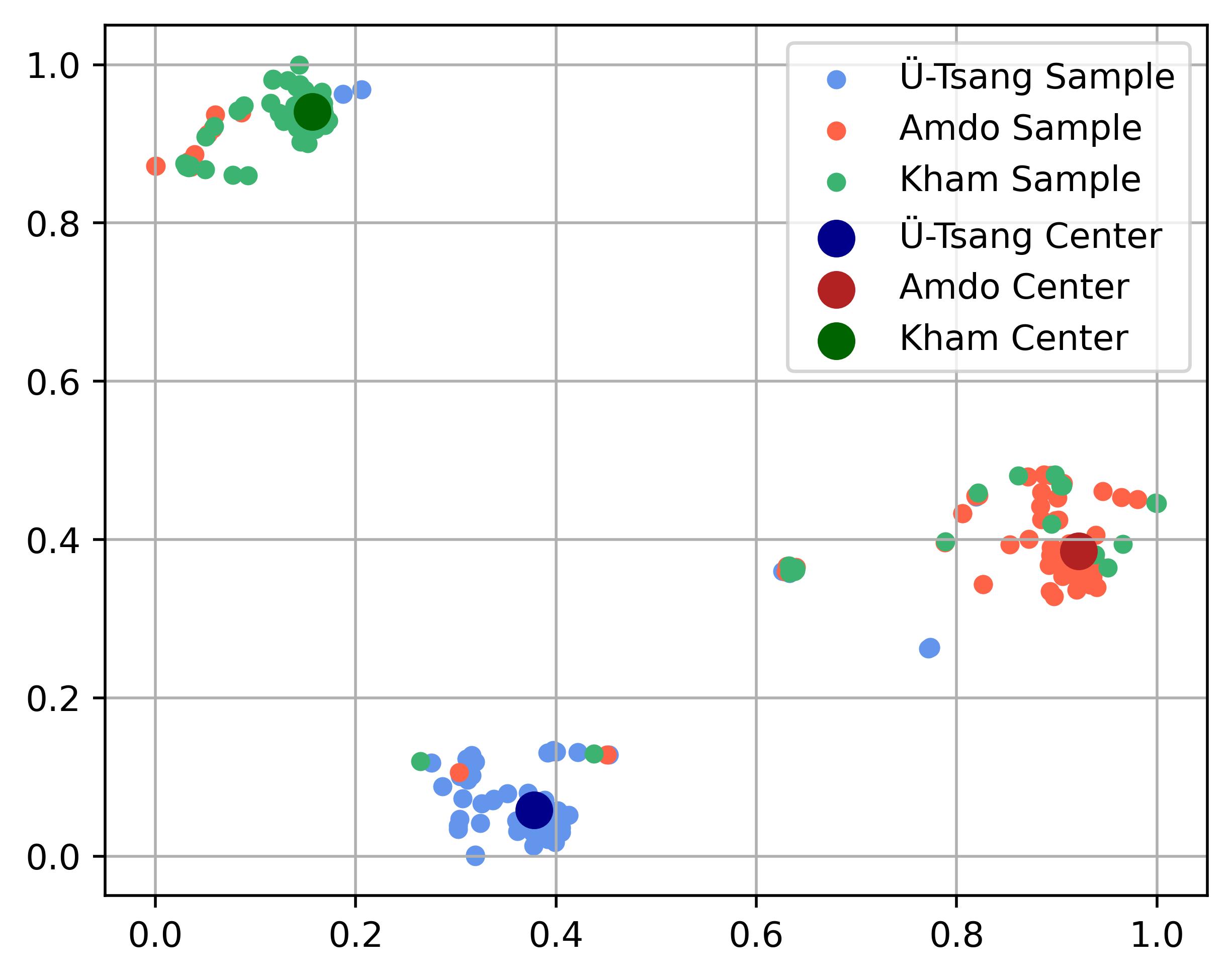 图2(左VITS2,右TMD-TTS)展示了在三个方言测试样本上,由预训练分类器输出的平均方言分类概率。TMD-TTS的输出在目标方言上的概率柱状图更高、更集中,表明其生成的语音具有更鲜明、更准确的方言特征。
图2(左VITS2,右TMD-TTS)展示了在三个方言测试样本上,由预训练分类器输出的平均方言分类概率。TMD-TTS的输出在目标方言上的概率柱状图更高、更集中,表明其生成的语音具有更鲜明、更准确的方言特征。
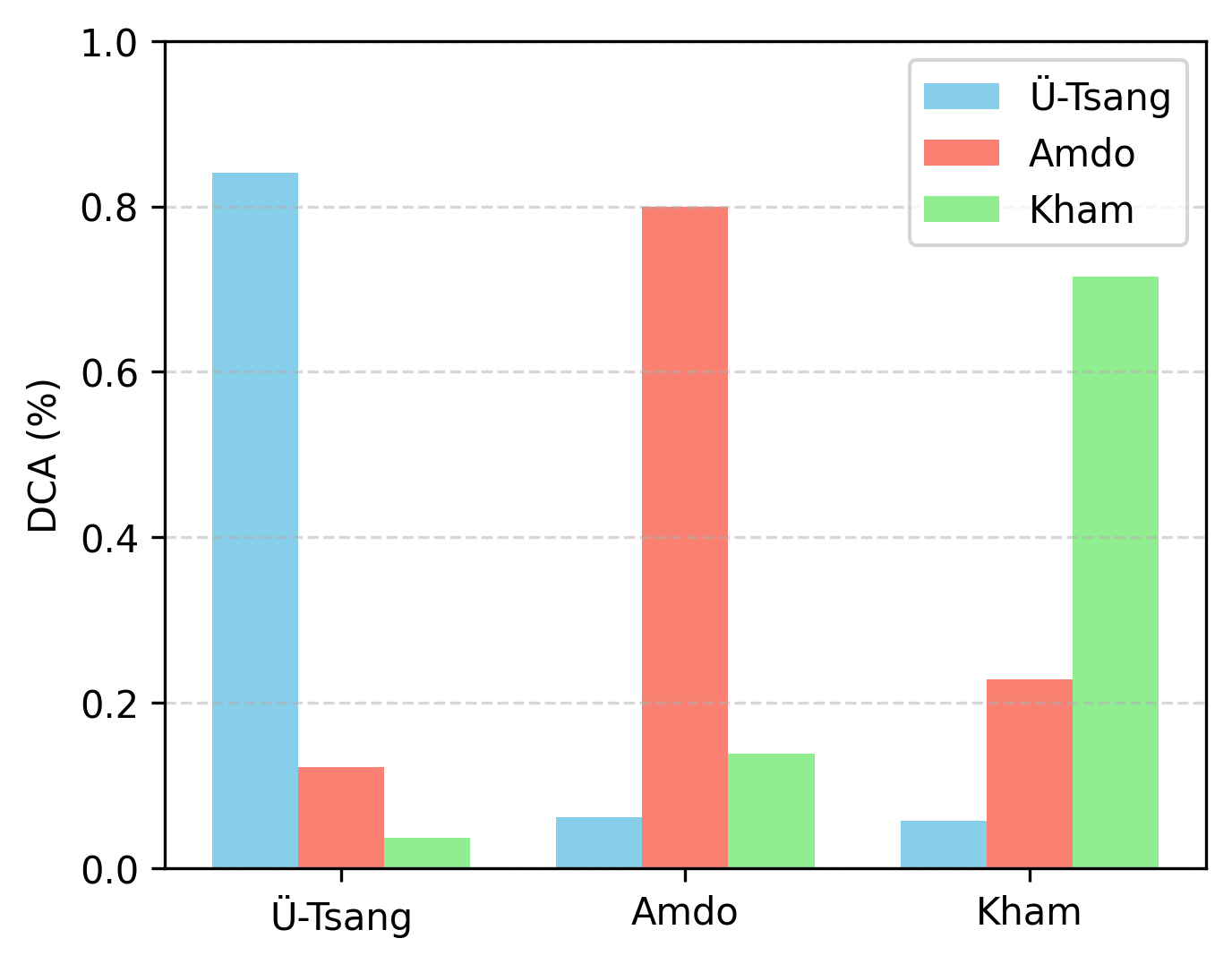 图3(左VITS2,右TMD-TTS)是方言嵌入的t-SNE可视化。TMD-TTS的嵌入点聚类更紧密,且三个簇(代表三个方言)分离度更好,证明其学习到的方言表示更具区分性。
图3(左VITS2,右TMD-TTS)是方言嵌入的t-SNE可视化。TMD-TTS的嵌入点聚类更紧密,且三个簇(代表三个方言)分离度更好,证明其学习到的方言表示更具区分性。
⚖️ 评分理由
- 学术质量:5.5/7:论文解决了明确的低资源多方言语音合成问题,提出了有效的技术方案(方言融合、DSDR-Net),并进行了全面、严谨的实验验证,包括多基线对比、充分的消融研究和下游任务验证,实验数据翔实。其创新属于在现有优秀架构(Matcha-TTS)上进行的、针对特定问题的有效扩展,而非基础理论的突破。
- 选题价值:1.5/2:藏语多方言合成是重要且前沿的低资源语音技术课题,对语言文化保护与技术发展有直接价值。论文产出的TMDD数据集预计将对该领域研究产生长期积极影响。
- 开源与复现加成:0.5/1:论文明确承诺发布TMDD数据集和评估工具包,这是重要贡献。但论文中未提及是否开源TMD-TTS的代码、模型权重,也未提供足够详细的训练配置(如超参数文件)以供完全复现。