📄 Tldiffgan: A Latent Diffusion-Gan Framework with Temporal Information Fusion for Anomalous Sound Detection
#音频事件检测 #生成模型 #扩散模型 #预训练 #数据增强
✅ 7.5/10 | 前25% | #音频事件检测 | #扩散模型 | #生成模型 #预训练
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Chengyuan Ma (清华大学深圳国际研究生院)
- 通讯作者:Wenming Yang (清华大学深圳国际研究生院)
- 作者列表:Chengyuan Ma (清华大学深圳国际研究生院), Peng Jia (大连海事大学交通运输协同创新中心), Hongyue Guo (大连海事大学交通运输协同创新中心), Wenming Yang (清华大学深圳国际研究生院)
💡 毒舌点评
论文在框架设计上确实展现了巧妙的组合能力,通过双分支结构(LDGAN重建+预训练编码器嵌入)有效融合了频谱图和波形两种互补信息源,并通过精心的消融实验证实了各模块的有效性。然而,其创新更多是将已有的强大组件(潜在扩散模型、GAN、预训练音频模型)进行整合与适配,而非提出全新的核心算法;此外,所有实验仅在单一基准数据集(DCASE 2020 Task 2)上进行,虽然性能优越,但缺乏在更多样化场景或最新数据集上的验证,限制了结论的泛化说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用的是公开数据集DCASE 2020 Challenge Task 2,但论文未提供特定处理后的数据或预训练模型。
- Demo:未提及。
- 复现材料:提供了部分关键超参数和训练设置(学习率、批量大小、epoch数、损失权重、TMixup的阈值范围),但网络架构的详细参数(如层数、注意力头数、隐藏维度等)以及预训练编码器的具体版本和使用方式未完全说明。
- 论文中引用的开源项目:
- 潜在扩散模型(LDM):[11] Ho et al., “Denoising diffusion probabilistic models”
- GAN对抗损失与梯度惩罚:[13] Gulrajani et al., “Improved training of Wasserstein GANs”
- 预训练音频模型:AST[16], ATST[17], BEATs[18], EAT[19]
- 异常检测算法:KNN[20], LOF[21], GMM[22], SOS[23]
- TMixup的灵感来源:[14] Choi & Choi, “Noisy-ARCMix”
- 总体开源状态:论文中未提及开源计划。
📌 核心摘要
本文针对无监督异常声音检测(ASD)中生成模型难以完全捕捉正常声音复杂分布的问题,提出了一个名为TLDiffGAN的新框架。该框架包含两个互补分支:一个分支将潜在扩散模型(LDM)整合到GAN的生成器中(称为LDGAN),通过对抗训练提高生成质量和训练稳定性;另一个分支利用预训练的音频模型编码器直接从原始波形提取特征,以弥补Mel频谱图可能丢失的信息。此外,论文引入了一种自适应时间混合(TMixup)增强技术,通过注意力机制增强模型对局部时间模式的敏感性。在DCASE 2020 Challenge Task 2数据集上的大量实验表明,TLDiffGAN在平均AUC(88.60%)和pAUC(74.35%)上均优于其他主流生成模型(如AEGAN-AD、ASD-Diffusion),并具备优秀的异常时频定位能力。该工作的实际意义在于提升了工业设备声音监控中异常检测的性能和可解释性。其主要局限性在于评估完全基于单个数据集,且依赖多个经典的异常检测算法进行最终决策。
🏗️ 模型架构
TLDiffGAN是一个双分支的无监督异常声音检测框架,其整体流程如图1所示。输入为原始音频波形,经过两条并行路径处理:一条路径将其转换为log-Mel频谱图(128×313),并输入TMixup模块进行时间特征增强,随后送入LDGAN骨干网络进行重建;另一条路径将原始波形直接输入预训练的音频编码器(如EAT)以提取高级特征嵌入。
LDGAN骨干网络(图2) 是框架的核心,它创新性地将潜在扩散模型(LDM)与GAN结合。生成器G的任务是从噪声z'通过逐步去噪过程重建出log-Mel频谱图。判别器D则更为复杂:它不仅要区分真实的频谱图和最终生成的频谱图,还要对扩散模型的中间去噪步骤进行评估,从而为生成器提供每一步的优化信号。生成器的训练目标包括噪声预测损失(Lnoise,标准的LDM目标)和统计匹配损失(Lstat,对齐生成样本与真实样本在判别器深度特征上的分布)。判别器的损失则包括对抗损失(Ladv)和梯度惩罚(LGP)以稳定训练。

TMixup模块(公式3,4) 对输入的log-Mel频谱图进行操作。它首先通过可学习的权重对最大池化、平均池化和幂平均池化的结果进行加权求和,然后通过Sigmoid函数生成一个软时间注意力图。接着,该注意力图被阈值(τ,随机采样自[0.2, 0.5])二值化为硬掩码,用于定位“可疑”的时间区域。最后,通过Mixup操作将原始频谱图与这些被掩码增强的区域进行混合,从而强化模型对边界模式的敏感性。
预训练音频编码器 使用如EAT、BEATs等Transformer架构,直接处理原始音频波形,输出一个固定维度的嵌入向量Zwave,旨在保留被频谱图转换可能忽略的原始声学细节。
检测器(图1,公式6) 由两个并行部分组成:
- 重建检测器:计算真实频谱图的潜在表示
zreal与LDGAN重建的频谱图的潜在表示zrec之间的L2距离,作为异常分数sr。 - 嵌入检测器:将LDGAN提取的频谱图嵌入
Zmel与预训练编码器提取的波形嵌入Zwave拼接成联合特征空间。在此空间上运行多种经典异常检测算法(KNN、LOF、GMM、SOS)。系统通过验证集性能为每种机器类型自动选择表现最佳的检测器(基于AUC和pAUC的均值),并输出对应的异常分数se。 最终的异常分数sf由重建分数sr和最优嵌入检测器分数se竞争决定(取性能最佳检测器对应的分数)。
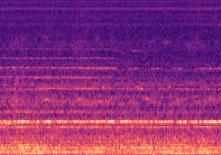 图3 展示���模型在测试集上的异常定位能力。对于正常样本(a),重建频谱图与训练集平均频谱图高度一致,差值频谱图(第三行)响应弱且随机。对于异常样本(b),差值频谱图则显示出明显的结构化异常响应(高亮区域),表明模型成功分离了稳态成分和瞬态异常成分。
图3 展示���模型在测试集上的异常定位能力。对于正常样本(a),重建频谱图与训练集平均频谱图高度一致,差值频谱图(第三行)响应弱且随机。对于异常样本(b),差值频谱图则显示出明显的结构化异常响应(高亮区域),表明模型成功分离了稳态成分和瞬态异常成分。
💡 核心创新点
- LDGAN骨架(创新整合):将潜在扩散模型(LDM)的渐进式去噪过程深度整合到GAN的生成器中。之前的方法要么使用自编码器(重建模糊),要么使用纯GAN(训练不稳定),要么使用纯扩散模型(可能将异常视为噪声去噪,导致检测困难)。LDGAN结合了LDM的高质量生成能力和GAN的训练稳定性,同时让判别器监督去噪过程,提高了重建保真度和对抗训练的有效性。
- 双分支多模态特征融合:传统生成模型仅依赖Mel频谱图输入,但频谱图转换会丢失部分原始波形中的关键信息。本文设计了一个并行分支,利用预训练的音频SSL模型(如EAT)直接从原始波形中提取丰富的特征嵌入,与LDGAN重建路径的特征在嵌入空间融合,从而捕获更全面、互补的声学表征。
- 自适应时间混合(TMixup)增强:现有生成模型倾向于学习全局宏观特征,对局部的、微弱的瞬时异常模式不敏感。TMixup模块通过一个可学习的注意力机制,自动识别并增强频谱图中位于正常数据分布边界的可疑时间区域。这种针对性的数据增强迫使模型在训练时更关注决策边界,从而提升了推理时对真实异常的敏感性。
🔬 细节详述
- 训练数据:DCASE 2020 Challenge Task 2数据集,包含MIMII和ToyADMOS两个子集,涵盖6种机器类型(Fan, Pump, Slider, Valve, ToyCar, ToyConveyor)。单声道,采样率16kHz,每段约10秒。未使用其他数据集。
- 数据增强:主要依靠框架内部的TMixup模块进行训练时的动态数据增强。
- 损失函数:
- 生成器损失:
LG = Lnoise + λstat · Lstat,其中Lnoise是标准的LDM噪声预测损失(L2),Lstat是对抗统计匹配损失(L2距离)。λstat设为1.0。 - 判别器损失:
LD = Ladv + λGP · LGP,其中Ladv是标准对抗损失(WGAN-GP风格),LGP是梯度惩罚项。λGP设为10。
- 生成器损失:
- 训练策略:使用Adam优化器,学习率0.0001,批量大小512,训练150个epoch。应用了梯度惩罚以稳定判别器训练。
- 关键超参数:输入log-Mel频谱图维度为128×313。TMixup模块的阈值τ在每个训练步从均匀分布
U(0.2, 0.5)中随机采样。判别器结构与编码器类似,但最后一层使用了分组卷积。 - 训练硬件:论文中未说明具体的GPU型号、数量或训练时长。
- 推理细节:最终异常分数通过选择在验证集上表现最佳的检测器(重建或嵌入检测器之一)来确定。
- 正则化/稳定技巧:对判别器D应用了谱归一化和梯度惩罚(LGP)。
📊 实验结果
论文在DCASE 2020 Task 2数据集上进行了全面的实验,主要与主流生成模型进行对比。
主要性能对比(表1)
| 方法 | Fan (AUC/pAUC) | Pump (AUC/pAUC) | Slider (AUC/pAUC) | ToyCar (AUC/pAUC) | ToyConveyor (AUC/pAUC) | Valve (AUC/pAUC) | Average (AUC/pAUC) |
|---|---|---|---|---|---|---|---|
| 官方基线 | 65.91/52.74 | 71.36/60.02 | 83.86/66.42 | 78.23/67.38 | 71.01/59.78 | 65.28/49.98 | 72.61/59.39 |
| ANP | 69.20/54.40 | 72.80/61.80 | 90.70/74.20 | 86.90/70.70 | 72.50/67.30 | 67.00/54.50 | 76.52/63.82 |
| GANomaly | 79.37/63.48 | 72.65/61.48 | 84.21/72.84 | 85.12/72.23 | 74.59/61.24 | 79.30/57.74 | 79.21/64.84 |
| ASD-Diffusion | 83.64/71.92 | 82.78/74.92 | 88.51/75.24 | 92.30/81.48 | 78.65/63.12 | 87.78/61.55 | 85.61/71.37 |
| AEGAN-AD | 83.12/71.86 | 84.37/75.42 | 91.84/78.18 | 91.70/80.40 | 79.00/65.86 | 84.37/60.75 | 86.08/72.08 |
| Ours (TLDiffGAN) | 85.88/73.15 | 87.60/76.55 | 94.78/83.94 | 93.35/82.97 | 80.29/65.21 | 89.67/64.26 | 88.60/74.35 |
TLDiffGAN在平均AUC和pAUC上分别达到了88.60% 和 74.35%,显著优于所有对比的生成模型,相比次优的AEGAN-AD分别提升了2.52% 和 2.27%。
预训练音频编码器消融实验(表2)
| 模型 | 参数量 | 平均AUC (%) | 平均pAUC (%) |
|---|---|---|---|
| AST | 86M | 85.47 | 71.40 |
| ATST | 85M | 85.85 | 71.24 |
| BEATs | 90M | 86.92 | 73.98 |
| EAT | 88M | 88.60 | 74.35 |
使用EAT编码器取得了最佳性能。
核心组件消融实验(表3)
| 模型 | Fan | Pump | Slider | ToyCar | ToyConveyor | Valve | Average |
|---|---|---|---|---|---|---|---|
| TLDiffGAN | 85.88 | 87.60 | 94.78 | 93.35 | 80.29 | 89.67 | 88.60 |
| w/o Latent Diffusion | 83.27 | 85.95 | 92.52 | 92.14 | 79.85 | 84.68 | 86.40 |
| w/o EAT | 86.35 | 87.28 | 90.94 | 88.51 | 78.32 | 86.73 | 86.36 |
| w/o Logmel-Enhance | 85.14 | 86.55 | 91.69 | 93.10 | 80.86 | 88.50 | 87.64 |
消融实验(以AUC为准)表明,移除任何一个核心组件(潜在扩散、EAT编码器、频谱图增强TMixup)都会导致整体平均性能下降(-2.20%到-0.96%),验证了各模块的有效性。特别是移除TMixup模块对ToyConveyor这种具有复杂时间模式的声音源影响最小,甚至略有提升,但整体上完整模型最优。
异常定位可视化(图3)
如上文“模型架构”部分所述,图3直观展示了TLDiffGAN对正常和异常样本的重建误差差异,证明了其良好的时间-频率异常定位能力。
⚖️ 评分理由
学术质量:6.2/7
- 创新性 (中等偏上):创新是组合式创新。将潜在扩散模型与GAN骨架结合、引入预训练音频编码器进行多模态特征融合、以及设计TMixup增强模块,这几个点单独看都不是首创,但整合到一个统一的ASD框架中,并针对该任务的特点进行适配,体现了良好的系统设计和工程创新能力。
- 技术正确性 (高):方法描述清晰,损失函数设计合理,实验设置(包括消融实验)规范,技术实现逻辑自洽。
- 实验充分性 (高):在单一但经典的基准数据集(DCASE 2020 Task 2)上进行了非常全面的实验,包括与多个基线方法的对比、不同预训练编码器的对比、以及针对三个核心组件的消融实验,提供了丰富的性能数据(AUC, pAUC)。
- 证据可信度 (中高):实验基于公开数据集和标准评估指标,结果具有可比性。消融实验有力支持了各组件贡献的论点。主要证据局限在于缺乏跨数据集验证。
选题价值:1.5/2
- 前沿性 (中):异常声音检测是工业物联网和智能维护中的重要课题,属于持续受到关注的领域。将生成模型(特别是扩散模型)应用于此是当前的研究热点之一。
- 潜在影响/应用空间 (中):该工作直接提升了无监督ASD的性能,并提供了异常定位能力,对工业设备的预测性维护等实际应用有直接价值。然而,该任务本身相对垂直。
- 与音频/语音读者相关性 (中):对于从事音频信号处理、故障诊断、或异常检测研究的读者,本文有较高的参考价值。对于更广泛的语音AI读者,相关性一般。
开源与复现加成:0/1
- 论文未提及任何代码仓库、模型权重、训练脚本或详细配置文件的公开计划。实验细节(如具体网络层数、隐藏维度、编码器详细配置)未完全披露,这会显著增加独立复现的难度。