📄 Time-Shifted Token Scheduling for Symbolic Music Generation
#音乐生成 #自回归模型 #多轨音乐
🔥 8.5/10 | 前25% | #音乐生成 | #自回归模型 | #多轨音乐
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Ting-Kang Wang(台湾大学通讯工程研究所)
- 通讯作者:未说明
- 作者列表:Ting-Kang Wang(台湾大学通讯工程研究所)、Chih-Pin Tan(台湾大学通讯工程研究所)、Yi-Hsuan Yang(台湾大学通讯工程研究所)
💡 毒舌点评
这篇论文巧妙地将音频领域已有的“延迟模式”思想移植到符号音乐生成,用近乎零成本的方式显著改善了复合token建模的短板,体现了“好移植胜过坏发明”的实用主义智慧。不过,其核心创新更多是工程技巧的适配与验证,缺乏更深层的理论分析或架构上的原创性,并且实验局限于管弦乐MIDI生成,对于更复杂或更抽象的音乐结构建模能力有待观察。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/tklovln/dp-scheduling
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用公开数据集SymphonyNet,论文中描述了获取和划分方式。
- Demo:提供在线演示页面:https://tklovln.github.io/dp-demo/
- 复现材料:提供了完整的训练细节(模型架构、数据集处理、超参数、优化器配置)、代码和演示。
- 引用的开源项目/工具:论文引用了并可能依赖以下开源工具:muspy [23], pypianoroll [24], fluidsynth(用于MIDI渲染)。基线模型MMT [15]和NMT [6]也是开源的。
📌 核心摘要
- 问题:符号音乐生成中,紧凑的复合token表示(将音符多个属性打包)虽提高了效率,但导致模型在并行预测这些属性时忽略了它们内部的依赖关系(如音高与时长的相关性),影响生成质量。
- 方法核心:提出一种轻量级的延迟调度机制(DP),将复合token的各个子字段(如类型、节拍、音高等)在解码时按固定顺序延迟一步预测,从而将并行预测转化为自回归预测,以建模属性间的依赖关系。
- 创新:该方法并非新的表示方案,而是一种可即插即用到现有复合token表示上的调度策略,不引入任何额外参数,仅需微小的数据加载器改动。它借鉴了音频领域的延迟模式(如MusicGen),但创新性地应用于符号音乐的异质属性依赖建模。
- 实验结果:在SymphonyNet管弦乐数据集上的实验表明,将DP应用于基线模型(MMT-DP)后,所有评估指标均优于标准复合token模型。主观听觉测试(26名参与者)显示,MMT-DP在连贯性、丰富性、一致性和总体评分上均有提升,达到了与更复杂的嵌套Transformer(NMT)和细粒度表示(REMI+)相当的水平。客观评估表格如下:
模型 音高类熵(越接近真值越好) 音阶一致性(越接近真值越好) 律动一致性(越接近真值越好) Ground truth 2.70 (±0.39) 0.92 (±0.08) 0.90 (±0.07) MMT 2.42 (±0.46) 0.96 (±0.05) 0.90 (±0.07) NMT 2.74 (±0.43) 0.92 (±0.07) 0.99 (±0.00) REMI+ 2.64 (±0.46) 0.92 (±0.07) 0.88 (±0.08) MMT-DP (Ours) 2.53 (±0.46) 0.95 (±0.06) 0.93 (±0.05) - 实际意义:为复合token表示在效率与质量之间的权衡提供了一个极低成本的优化方案,能无缝集成到现有系统中,提升生成音乐的连贯性和准确性。
- 主要局限性:方法有效性在多大程度上依赖于特定的子字段顺序和延迟步长未充分探讨;实验仅在管弦乐生成任务上验证,对其他音乐类型或更复杂的长篇结构生成能力未加检验。
🏗️ 模型架构
论文提出的延迟调度(DP)机制本身不是一个独立模型,而是一个可插入现有Transformer解码框架的调度策略。以论文使用的基线模型MMT(多轨Transformer)为例,其整体架构如下:
- 输入表示:每个音乐事件被表示为一个复合token,由6个子字段(类型、节拍、位置、音高、时值、乐器)的嵌入向量求和而成,并加入绝对位置编码。
- 核心Transformer解码器:采用标准的decoder-only Transformer(8层,8头,维度512)。在标准MMT中,解码器在每个时间步输出一个隐藏状态,然后通过K个并行的线性输出头(K=6)同时预测所有子字段。
- 引入DP调度:DP机制改变了预测的时间顺序。它不再在时间步t同时输出所有子字段,而是将事件$e_i$的6个子字段分散到从$t = i + \Delta_d$开始的连续6个时间步进行预测。具体而言:
- 在时间步$ t=i $,只预测
type字段($\Delta_{type}=0$)。 - 在时间步$ t=i+1 $,预测
beat字段($\Delta_{beat}=1$),此时该预测的输入上下文已包含当前事件已预测的type以及所有历史事件。 - 以此类推,直到在时间步$ t=i+5 $预测完
instrument字段。 - 公式(2)和(3)形式化描述了这一条件概率分解过程。
- 在时间步$ t=i $,只预测
- 输出:预测序列的总长度从$ N \times K $(N为事件数,K为子字段数)变为$ N + K - 1 $,仅增加常数项。
- 数据流:DP调度仅改变了训练时的目标序列构造和推理时的逐步采样顺序,Transformer解码器本身架构不变。
架构图说明:论文提供了两幅架构图。
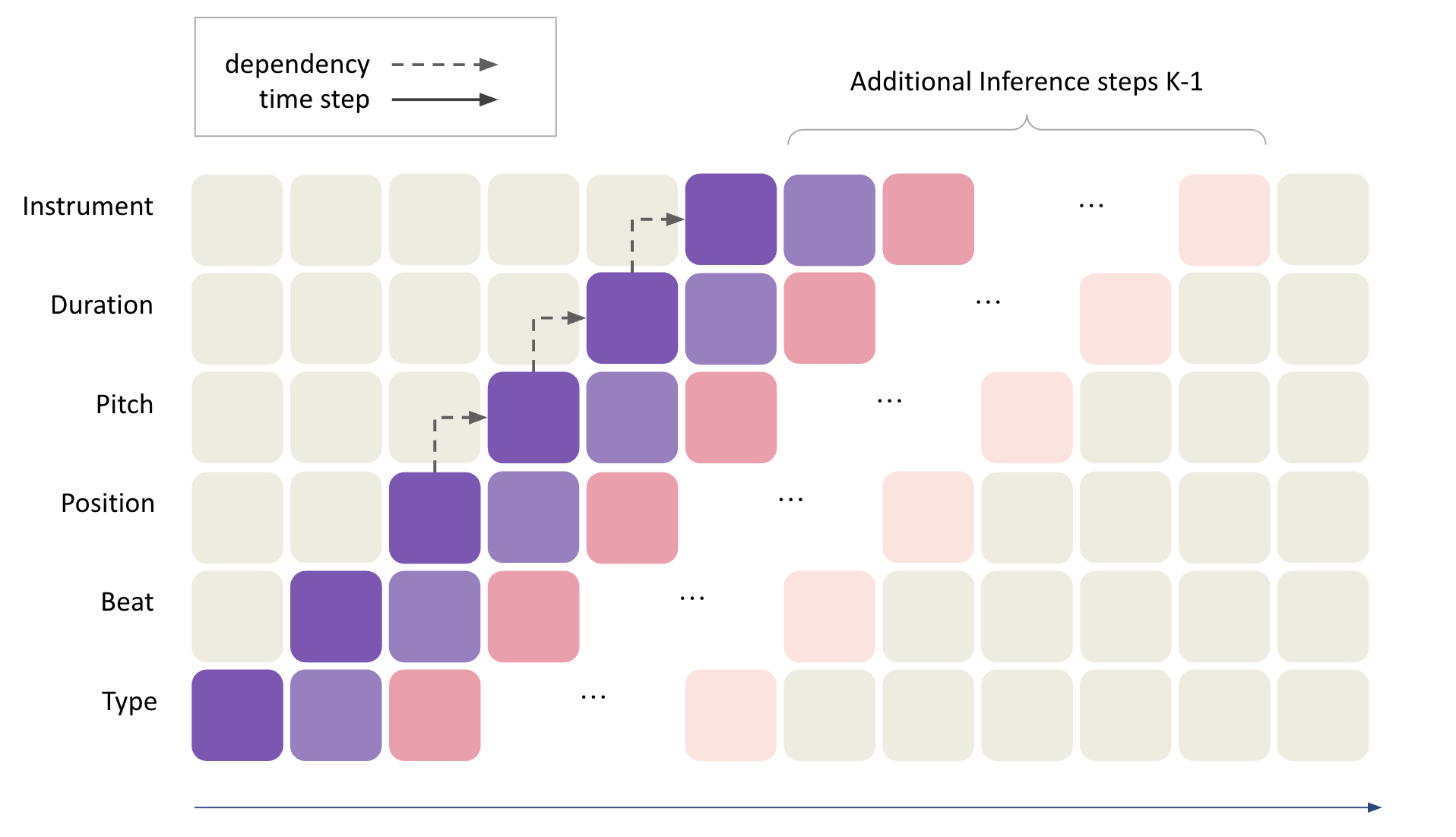 图1清晰展示了DP机制的工作原理。水平轴是自回归时间步,垂直轴是子字段。可以看到,一个事件(例如事件$e_2$)的多个属性(type, beat, …)被分散到相邻的时间步进行预测,箭头表示子字段之间潜在的依赖关系被显式建模。
图1清晰展示了DP机制的工作原理。水平轴是自回归时间步,垂直轴是子字段。可以看到,一个事件(例如事件$e_2$)的多个属性(type, beat, …)被分散到相邻的时间步进行预测,箭头表示子字段之间潜在的依赖关系被显式建模。
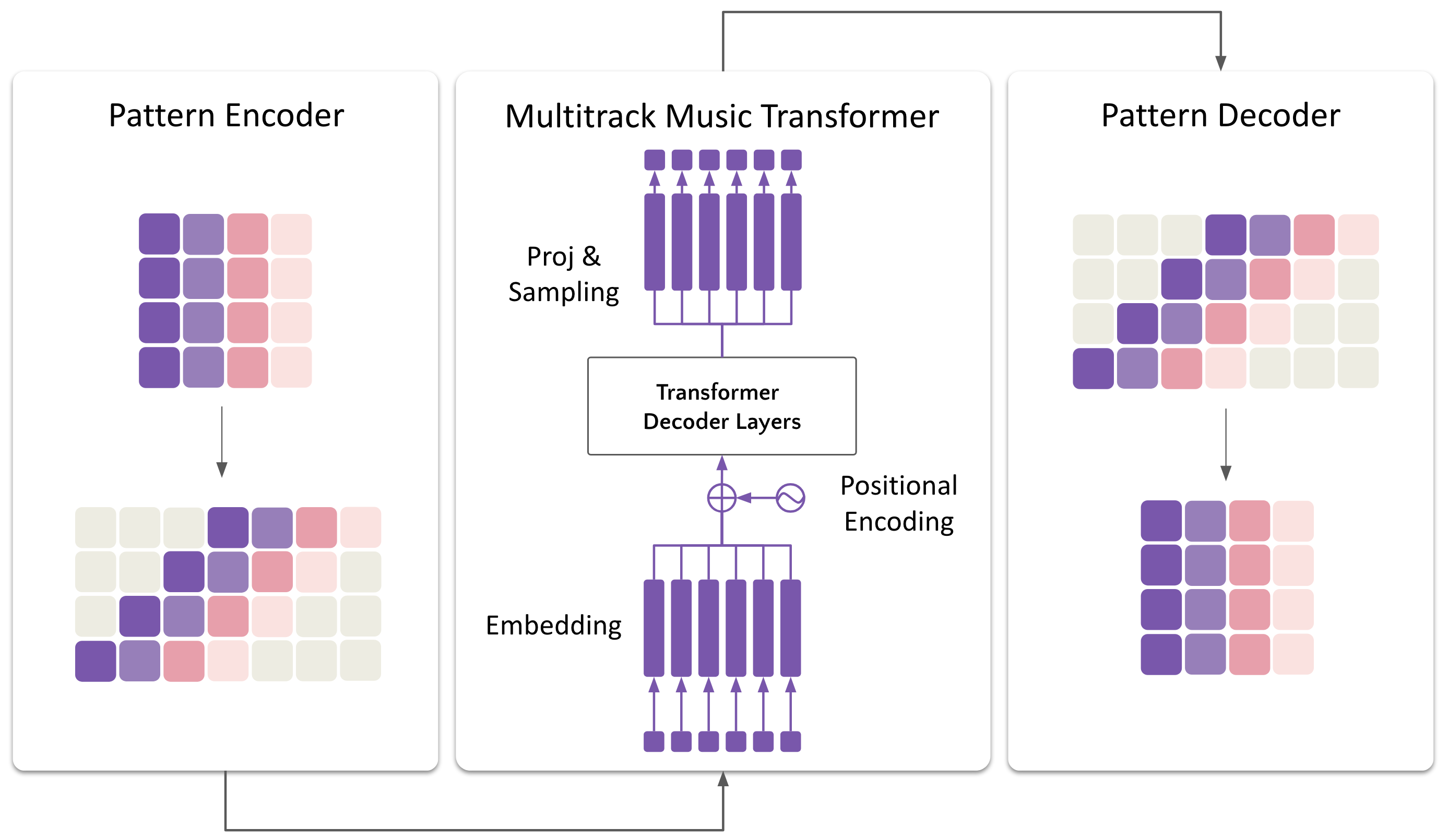 图2展示了将DP调度集成到多轨音乐Transformer中的整体框架。图中强调了DP调度器与编码器-解码器框架的结合。
图2展示了将DP调度集成到多轨音乐Transformer中的整体框架。图中强调了DP调度器与编码器-解码器框架的结合。
💡 核心创新点
- 轻量级、即插即用的依赖建模:核心创新是将源自音频领域的延迟模式(DP)迁移至符号音乐生成。其关键优势在于“轻量”——不增加任何模型参数,仅通过改变数据处理(调度)逻辑,就在紧凑的复合token表示上实现了对子字段间依赖关系的自回归建模。
- 弥合效率与质量的差距:针对复合token(高效但牺牲内部依赖)与细粒度token(高质但序列长)之间的根本权衡,DP提供了一条中间路径。它保留了复合token的高效性(序列长度几乎不变),同时通过调度策略恢复了类似细粒度token的依赖建模能力,实验结果显示其显著缩小了两者之间的质量差距。
- 对现有框架的零成本增强:该方法被设计为一个“调度策略”,可以无缝“插入”到任何已使用复合token的自回归模型(如MMT)中。这极大降低了应用门槛,使其能快速赋能现有系统。
🔬 细节详述
- 训练数据:使用SymphonyNet数据集,包含46,359首管弦乐MIDI总谱,平均时长256秒,总计约3,284小时。数据集划分:训练/验证/测试 = 80%/10%/10%。数据增强:随机音高转调$s \sim U(-5, 6)$半音。
- 损失函数:论文中未明确说明损失函数名称。根据任务(多分类预测)和模型结构(Transformer解码器+并行输出头),可推断为标准的交叉熵损失,针对每个子字段分别计算后求和。
- 训练策略:优化器:Adam。学习率:初始$3 \times 10^{-4}$,使用线性预热后接逆平方根衰减。最大序列长度:1024。批大小(batch size):16。训练步数:200,000步。所有模型(包括基线)在相同配置下训练。
- 关键超参数:Transformer层数:8。注意力头数:8。模型维度:512。前馈网络维度:2048。Dropout率:0.1。子字段数K:6。
- 训练硬件:论文中未说明。
- 推理细节:采用自回归解码。推理速度评估在单张RTX 3090 GPU上进行,生成序列最长1024步或直到EOS。解码策略、温度、beam size等具体参数论文中未说明。
- 正则化/稳定训练技巧:使用了Dropout(0.1)进行正则化。
📊 实验结果
主观听觉测试:26名参与者对2小节续写任务进行盲听评分(1-5分)。MMT-DP在所有维度上相比MMT基线均有提升,达到与NMT和REMI+可比的水平。MOS评分图表如下:
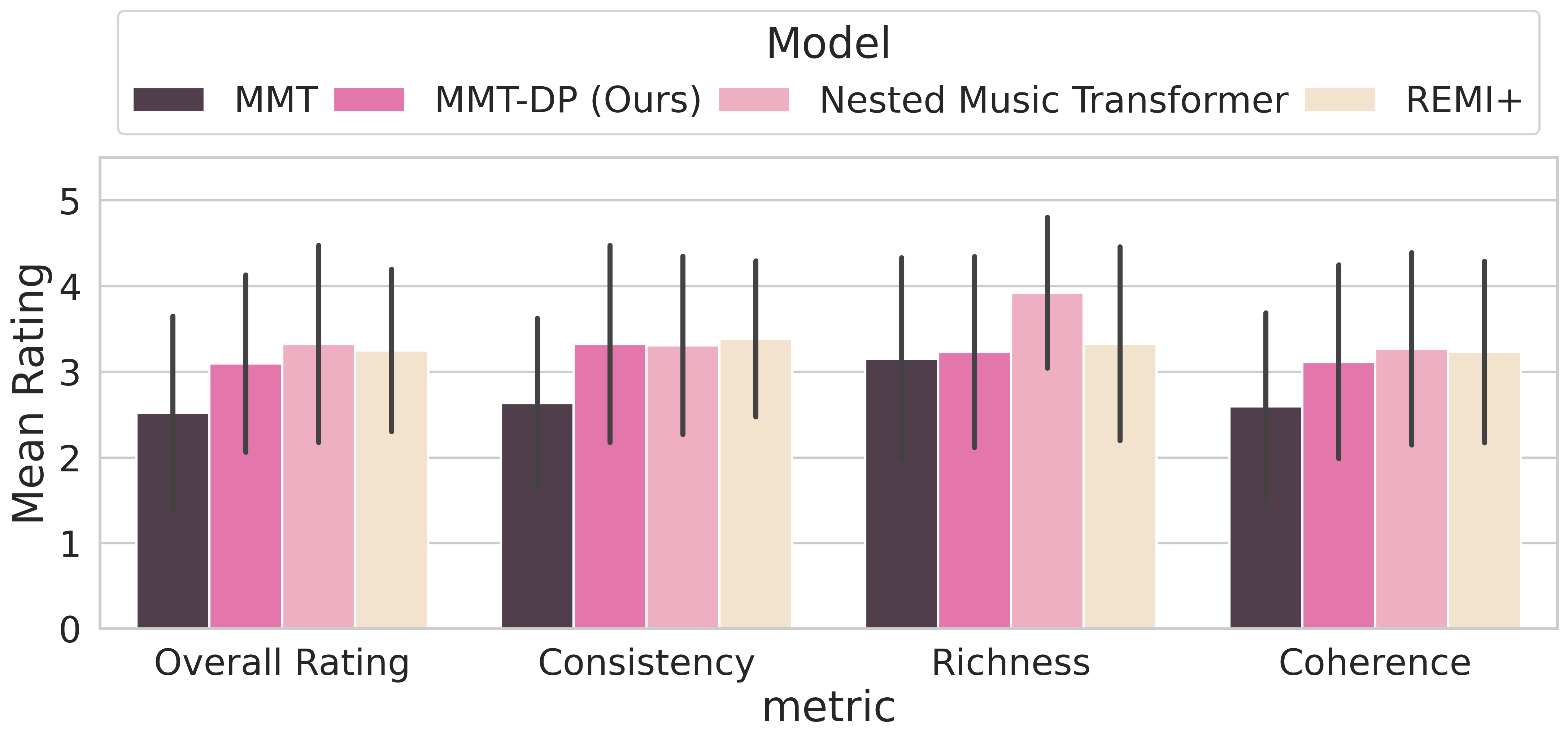 图3显示,MMT-DP在“一致性”、“连贯性”和“总体评分”上提升明显,其分数条和置信区间与NMT、REMI+高度重叠,表明感知质量接近。
图3显示,MMT-DP在“一致性”、“连贯性”和“总体评分”上提升明显,其分数条和置信区间与NMT、REMI+高度重叠,表明感知质量接近。
客观评估:在SymphonyNet测试集上测量三个指标(越接近Ground Truth越好)。结果如上文核心摘要中的表格所示。MMT-DP在所有指标上均优于MMT基线。
案例研究:图4展示了三个测试提示的续写对比。
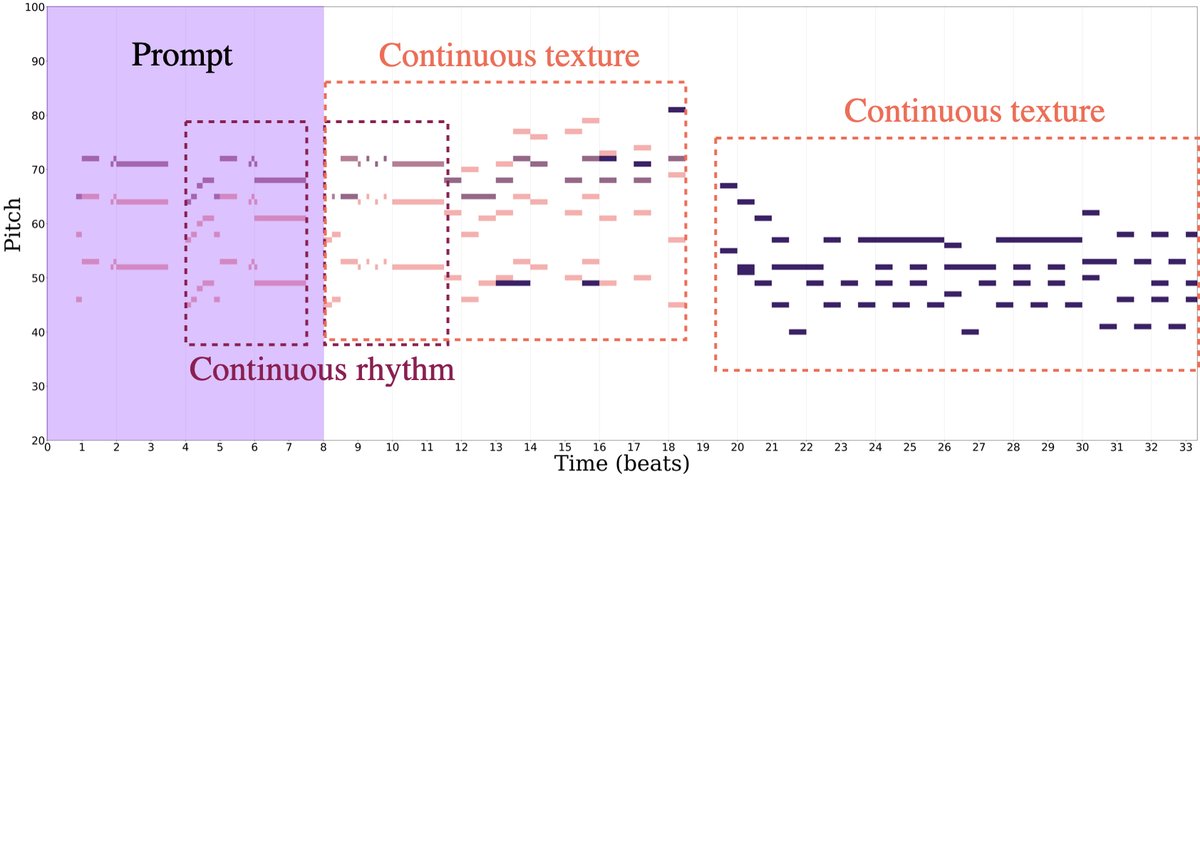
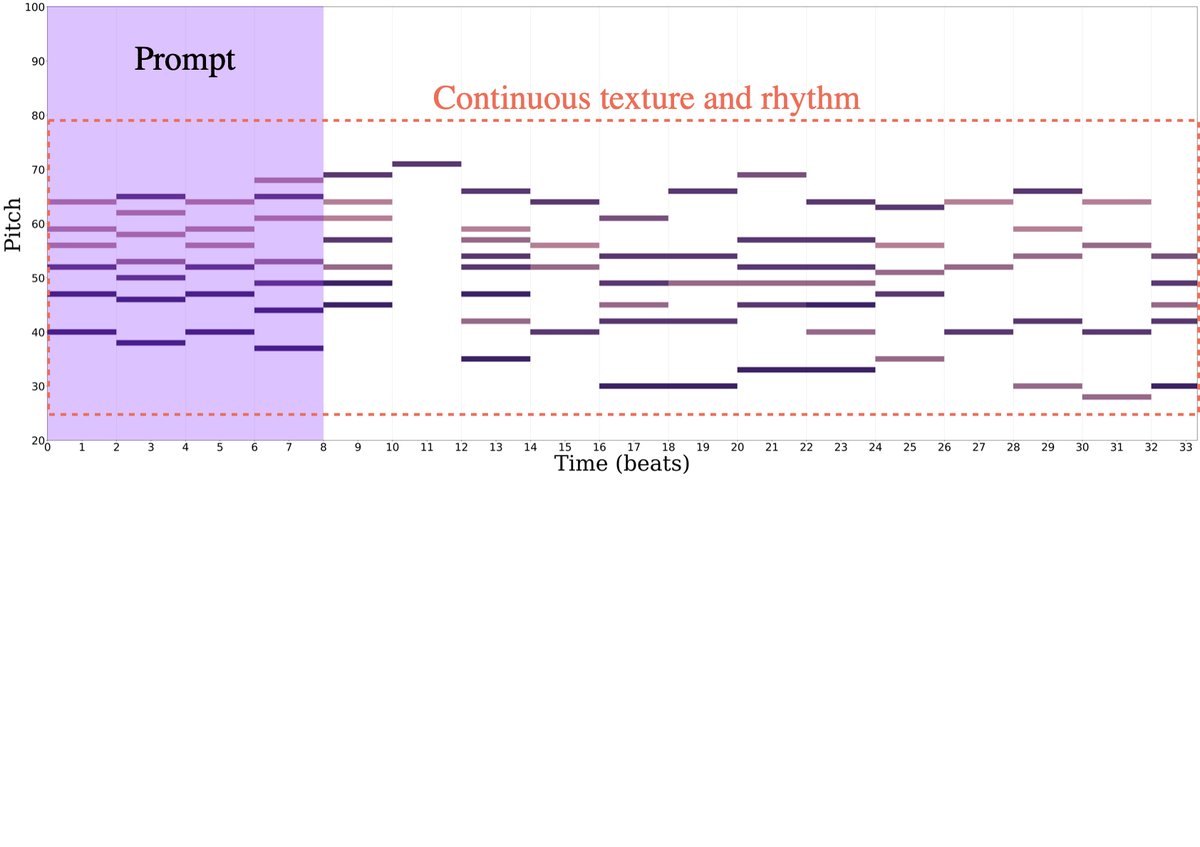
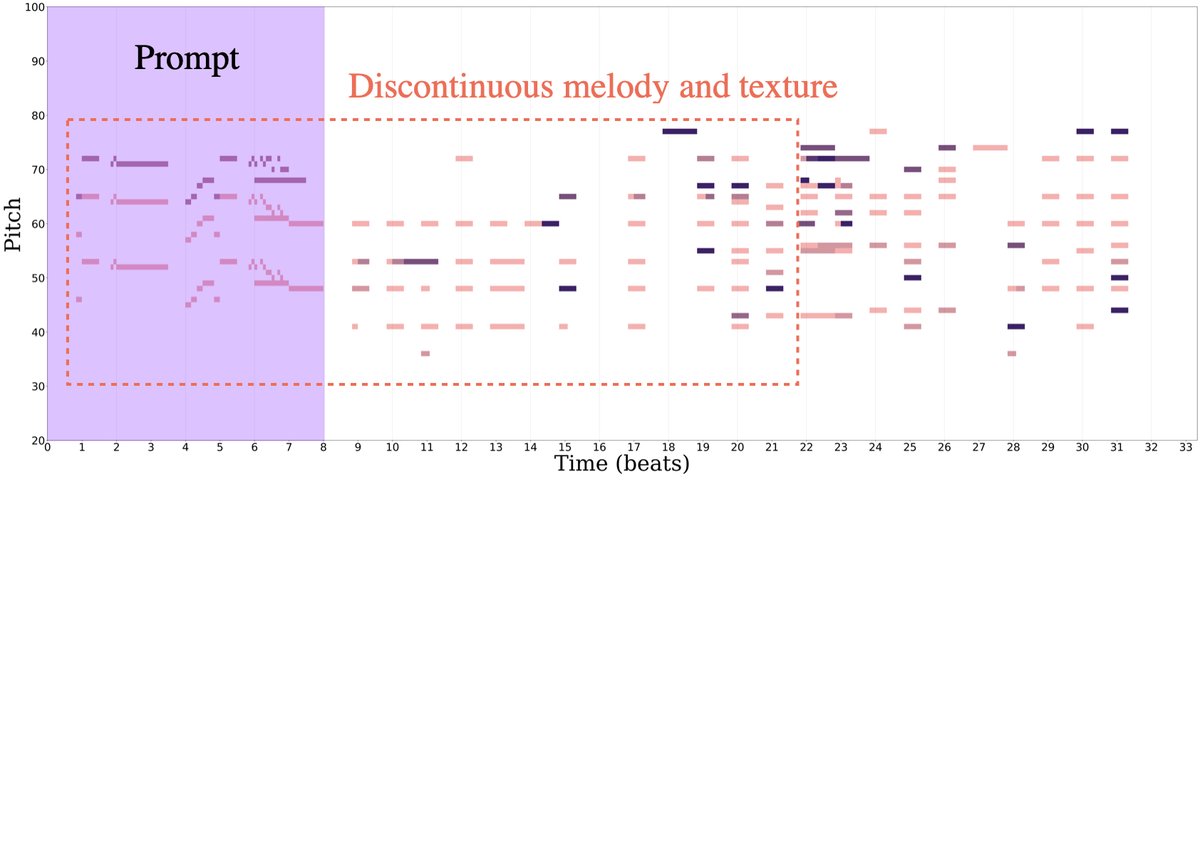 案例(a)-(c)均显示,无DP的MMT生成容易出现节奏断裂、纹理不连贯、旋律散乱等问题;而使用DP的MMT-DP生成的续写在节奏稳定性、纹理一致性和整体连贯性上明显更优。
案例(a)-(c)均显示,无DP的MMT生成容易出现节奏断裂、纹理不连贯、旋律散乱等问题;而使用DP的MMT-DP生成的续写在节奏稳定性、纹理一致性和整体连贯性上明显更优。
推理效率:比较推理速度(音符/秒)和复杂度。结果表格如下:
| 模型 | 推理速度(音符/秒) | 复杂度(Big-O) |
|---|---|---|
| MMT | 63.53 | O(N²) |
| MMT-DP (Ours) | 62.47 | O((N + (K-1))²) |
| NMT | 41.99 | O(E²) + O(NK) |
| REMI+ | 20.42 | O((NK)²) |
| MMT-DP比MMT仅慢1.7%,但比NMT快约49%,比REMI+快约206%,验证了其轻量性。 |
⚖️ 评分理由
- 学术质量:6.0/7。创新在于将已知技巧创造性地应用于新问题域,解决了实际痛点,方法正确且有效。实验设计全面,包含主观评估、客观指标、案例研究和效率对比,证据链完整。扣分主要因为创新幅度有限(非原始创新),且验证范围较窄(单一数据集和任务)。
- 选题价值:1.5/2。选题精准针对符号音乐生成中的核心工程矛盾,提出的解决方案具有立即可用性和推广潜力,对相关领域的研究者和开发者有直接价值。应用空间明确,但受限于垂直领域。
- 开源与复现加成:0.8/1。论文提供了清晰的代码库链接、演示页面、详尽的数据集信息(名称、划分、增强)、完整的训练配置(超参数、优化器、学习率策略)。复现友好度极高。0.8分是因为未明确承诺或已提供预训练模型权重下载。