📄 Thinking While Listening: Simple Test Time Scaling for Audio Classification
#音频分类 #预训练 #测试时缩放 #大语言模型 #零样本
✅ 6.5/10 | 前50% | #音频分类 | #测试时缩放 | #预训练 #大语言模型
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Prateek Verma(斯坦福大学电气工程系)
- 通讯作者:未说明
- 作者列表:Prateek Verma(斯坦福大学电气工程系)、Mert Pilanci(斯坦福大学电气工程系)
💡 毒舌点评
本文将LLM领域的“测试时缩放”概念移植到音频分类,思路清晰,用轻量级的GPT-2微调击败百亿参数大模型的结果也颇具启发性。但遗憾的是,论文在方法细节的深度打磨和与最新技术的全面比较上显得有些“想得不够深”,比如缺乏不同音频编码器、不同聚合策略的系统消融,更像是一个概念验证报告而非坚实的技术突破。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及是否公开了微调后的嵌入矩阵或任何其他模型权重。
- 数据集:使用了公开数据集ESC-50和FSD-50K,但未提供预处理脚本或划分细节。
- Demo:未提及。
- 复现材料:提供了一些关键超参数(如补丁长度、采样次数范围、训练轮数、学习率),但缺少优化器、批量大小、随机种子、完整配置文件等核心复现信息。
- 论文中引用的开源项目:引用了AST[17], YAMNet[18], GPT-2[20], AudioSet[21], ESC-50[26], FSD-50K[27]。
📌 核心摘要
- 问题:论文旨在探索如何将大型语言模型中的“推理”和“测试时缩放”能力引入音频分类任务,在模型权重固定的情况下,仅通过增加推理时的计算来提升性能。
- 方法核心:提出“边听边想”框架。首先,利用预训练的音频模型(如AST, YAMNet)对输入音频进行补丁级(如500ms)的因果预测,通过多次采样为每个补丁生成一个包含类别和置信度的“推理轨迹”。然后,将这个轨迹输入一个冻结的大语言模型(如GPT-2, GPT-OSS-20B),利用其推理能力聚合轨迹信息,做出最终分类。
- 与已有方法相比新在哪里:传统音频分类管道(如AST)直接输出单个概率向量。本文方法在推理时构建了动态的、基于证据累积的“推理链”,并将分类任务转化为LLM可以处理的序列推理问题。其创新在于将音频模型的输出(而非原始音频)作为LLM的推理输入,并利用测试时缩放来提升性能。
- 主要实验结果:在ESC-50数据集(单标签)上,冻结的AST模型通过增加采样轨迹长度(从1到32)并用GPT-2聚合,准确率从79.3%提升至88.3%,接近全量微调的88.8%。在FSD-50K数据集(多标签)上,增加采样轨迹长度同样能持续提升AUC。论文中关键实验结果表格如下:
表1: ESC-50数据集上,基于YAMNet骨干网络,不同采样长度下零样本文本推理模型的准确率对比
| 模型 | 采样长度/输出预测 | 1 | 2 | 4 | 16 |
|---|---|---|---|---|---|
| GPT-OSS 20B | 53.5 | 58.75 | 57.6 | 61.25 | |
| Qwen-3 14B | 52.3 | 55.5 | 57.2 | 54.25 |
表2: ESC-50数据集上,使用不同温度/采样轨迹长度,冻结AST骨干网络与GPT-2的准确率对比
| 温度 | 模型 | 采样长度 / op prediction | 1 | 2 | 4 | 16 | 32 |
|---|---|---|---|---|---|---|---|
| 1.0 | YAMNet | 72.0 | 77.4 | 80.8 | 83.8 | 84.5 | |
| 1.0 | AST | 79.3 | 83.5 | 86.3 | 87.3 | 88.3 | |
| 1.2 | AST | 76.8 | 84.8 | 85.3 | 87.0 | 87.0 | |
| 1.5 | AST | 72.5 | 80.5 | 82.8 | 86.5 | 88.5 | |
| 2.0 | AST | 53.5 | 65.3 | 77.3 | 84.8 | 83.8 | |
| 1.0 | AST | Full Model Finetune [17] | 88.8 |
- 实际意义:为在部署后持续提升固定音频模型性能提供了一种新范式,即通过增加推理时的计算(多次采样和LLM推理)而非重新训练模型。轻量级方案(微调GPT-2嵌入层)的发现对资源受限场景有参考价值。
- 主要局限性:1) 方法引入了额外的LLM推理步骤,增加了延迟和计算成本;2) 对LLM的依赖性强,其推理能力直接决定最终性能;3) 实验部分缺乏对关键组件(如不同聚合策略、轨迹长度增长上限)的深入消融;4) 论文未提供代码和模型,可复现性差。
🏗️ 模型架构
整体架构分为两个阶段:音频感知阶段和推理聚合阶段。
音频感知阶段:
- 输入:原始音频波形。
- 核心组件:预训练的音频分类模型(如AST, YAMNet)。这些模型被修改为以因果(自回归)方式处理音频。 流程:音频被切分为固定长度的补丁(如500ms)。模型逐补丁处理,对于每个新补丁,基于已听到的所有历史补丁预测当前可能的声音类别。为了生成“推理轨迹”,在每个补丁位置,从模型输出的后验概率分布中多次(T次)采样,得到一个类别标签和对应的置信度。因此,对于P个补丁,采样长度为T,会生成长度为2P*T的推理轨迹(类别和置信度交替)。
- 输出:一个文本序列形式的“推理轨迹”,编码了模型对音频随时间演变的假设。
推理聚合阶段:
- 输入:上一步生成的推理轨迹文本序列。
- 核心组件:大语言模型(LLM)。
- 流程(零样本路径):将推理轨迹和结构化的提示词(Prompt, 详见论文脚注1)输入冻结的、参数量较大的开源推理模型(如GPT-OSS-20B, Qwen3-14B)。LLM根据轨迹进行“链式思考”,输出最终的音频类别。
- 流程(微调路径):使用一个冻结的、较小的LLM骨干(如GPT-2 base)。仅重新训练其嵌入矩阵,使其词汇表能映射到目标数据集的类别标签和置信度区间。推理轨迹被编码为该新词汇表下的token序列。LLM的主干权重和位置编码保持固定。最终,取最后一个token的预测通过一个MLP分类头(对于多标签任务使用sigmoid)得到分类结果。
- 设计选择:动机是利用LLM在大规模文本数据上学到的推理能力。零样本路径探索LLM的即用推理能力;微调嵌入层路径则尝试以极小代价(仅更新一个矩阵)激活LLM中与分类任务相关的连接,结果显示后者在ESC-50上更优。
论文图1描述了整个流程:
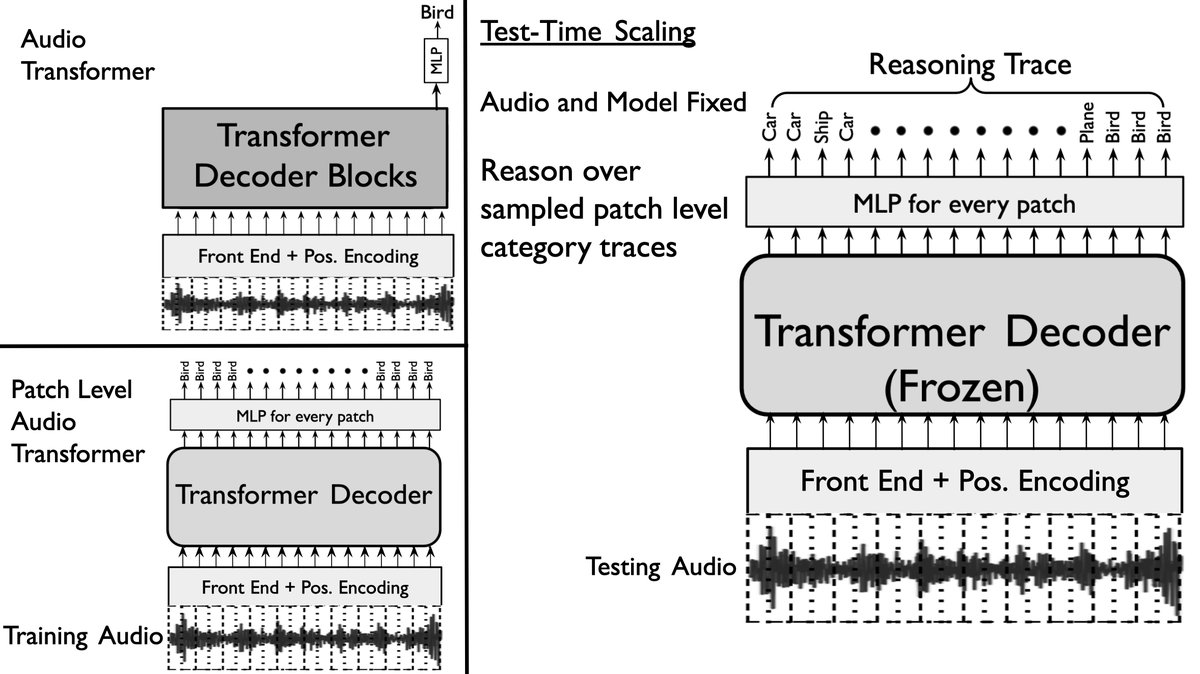 (图1:方法描述。训练阶段,模型被允许因果地预测每个补丁的类别以获得补丁级类别输出。推理阶段,模型和音频固定。我们从每个补丁的后验概率类别分布中多次采样(定义为每个补丁的采样轨迹长度)以得到一个推理轨迹。该轨迹随后被用于理解类别,通过一个冻结的LLM推理模型如GPT-OSS 20B或一个冻结的GPT-2模型(使用新的嵌入矩阵)进行聚合,并给出音频的准确预测。)
(图1:方法描述。训练阶段,模型被允许因果地预测每个补丁的类别以获得补丁级类别输出。推理阶段,模型和音频固定。我们从每个补丁的后验概率类别分布中多次采样(定义为每个补丁的采样轨迹长度)以得到一个推理轨迹。该轨迹随后被用于理解类别,通过一个冻结的LLM推理模型如GPT-OSS 20B或一个冻结的GPT-2模型(使用新的嵌入矩阵)进行聚合,并给出音频的准确预测。)
💡 核心创新点
- 将“测试时缩放”引入音频分类:核心创新是提出一种在推理时通过增加计算(多次采样构建更长的轨迹)来提升固定音频模型性能的范式。这与传统的通过扩大模型或数据进行训练时缩放形成对比。
- 构建“推理轨迹”作为LLM输入:创新性地将音频分类模型(感知模型)的补丁级、逐步预测结果,转化为一种可供文本LLM理解和推理的结构化“证据序列”。这桥接了音频感知与语言推理两个领域。
- 探索轻量级激活LLM推理能力:通过仅重训练冻结GPT-2的嵌入矩阵,在特定音频分类任务上超越了参数量大得多的零样本推理模型(GPT-OSS-20B, Qwen3-14B)。这表明针对性地调整输入/输出接口比完全依赖LLM原生能力更高效。
- 统一框架处理现有与新型音频模型:框架既适用于将现有的、输出单一向量的模型(如YAMNet)改造为生成推理轨迹,也为设计原生支持该流程的新模型(如修改后的AST)提供了思路。
🔬 细节详述
- 训练数据:
- 音频感知模型在预训练阶段使用AudioSet数据集(未在本文中训练)。
- 微调嵌入矩阵阶段:对于ESC-50(单标签),使用其训练集;对于FSD-50K(多标签),使用其训练集。论文中未详细说明训练集划分和数据增强。
- 损失函数:对于FSD-50K的多标签任务,训练时对每个补丁的类别预测使用均方误差(MSE)损失进行最小化。
- 训练策略:
- 训练轮数:300个epochs。
- 学习率:初始为1e-3,衰减至1e-6。
- 优化器:未说明。
- Batch size:未说明。
- 关键超参数:
- 补丁长度:500ms(ESC-50), 25ms(FSD-50K, 因为每秒分40个补丁)。
- 每个补丁的采样次数(T):关键超参数,从1变化到32。
- 推理模型:GPT-2(基础, 嵌入维度768), GPT-OSS-20B, Qwen3-14B。
- 音频模型:AST(前端64个滤波器,6层,嵌入维度64), YAMNet。
- 训练硬件:未说明。
- 推理细节:
- 对于零样本LLM:使用论文脚注1中给出的详细结构化提示词。
- 对于微调GPT-2:输入序列由类别token和置信度token(10个桶)交错组成,长度为2PT。最终通过MLP头输出分类。
- 温度调整:论文中尝试了温度1.0, 1.2, 1.5, 2.0,发现对性能有轻微影响(如表2所示)。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文在两个标准数据集上进行了评估:
- ESC-50(单标签分类):指标为Top-1准确率。
- 主要结果:如表1和表2所示。关键发现包括:1) 随着采样轨迹长度增加,准确率持续提升。例如,冻结AST模型在采样长度为32时(88.3%)接近全量微调的88.8%。2) 微调GPT-2嵌入层的方法优于强大的零样本推理模型(GPT-OSS-20B, Qwen3-14B)。3) AST优于YAMNet。
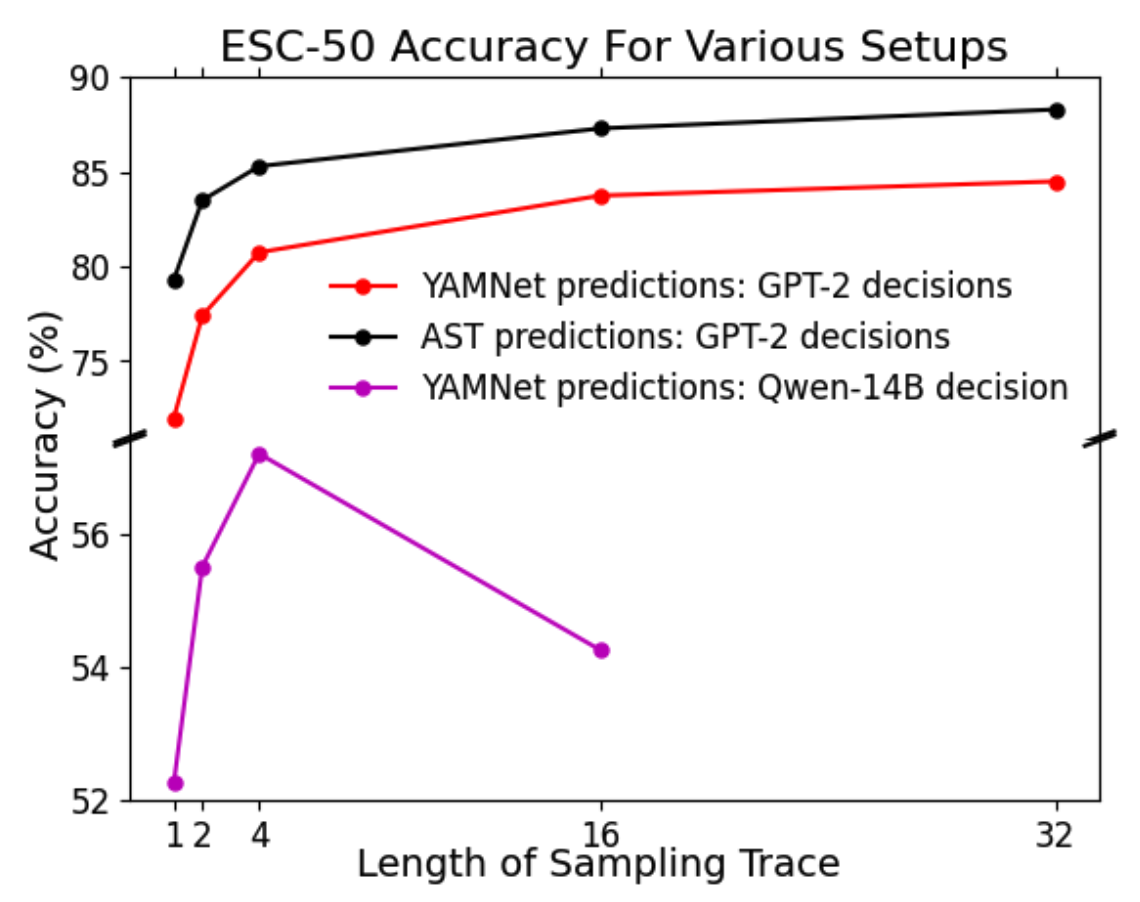 (图2:ESC-50数据集上,冻结YAMNet和AST的测试时缩放结果,使用GPT-2和Qwen-14B进行类别预测,随采样轨迹长度变化的准确率。图表显示了准确率随采样长度增加而上升的趋势,以及不同模型间的对比。)
(图2:ESC-50数据集上,冻结YAMNet和AST的测试时缩放结果,使用GPT-2和Qwen-14B进行类别预测,随采样轨迹长度变化的准确率。图表显示了准确率随采样长度增加而上升的趋势,以及不同模型间的对比。)
- FSD-50K(多标签分类):指标为AUC。
- 主要结果:如图3所示。对于修改后支持补丁级预测的Audio Transformer基线,在1秒输入下,较短的采样轨迹可能因信息损失而性能不增反降。但当每个补丁的采样次数增加到8次时,性能超过基线。趋势同样是性能随轨迹长度增加而提升。
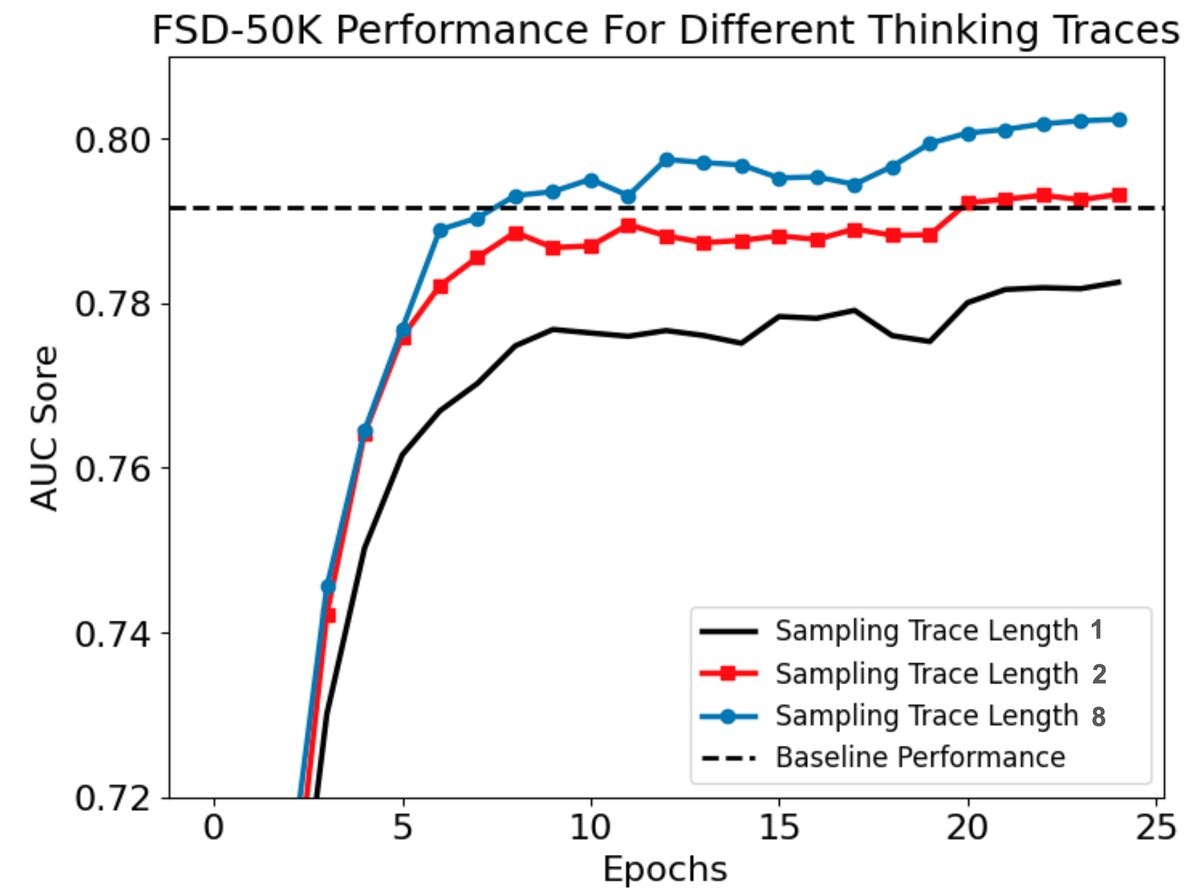 (图3:FSD-50K数据集上1秒音频片段的结果,针对不同采样轨迹长度。我们使用一个冻结的GPT-2骨干网络(具有训练过的嵌入矩阵)对基线Audio Transformer和骨干网络进行推理。图表显示了AUC随采样次数的变化,表明在达到一定采样次数(如8次)后,方法开始优于基线。)
(图3:FSD-50K数据集上1秒音频片段的结果,针对不同采样轨迹长度。我们使用一个冻结的GPT-2骨干网络(具有训练过的嵌入矩阵)对基线Audio Transformer和骨干网络进行推理。图表显示了AUC随采样次数的变化,表明在达到一定采样次数(如8次)后,方法开始优于基线。)
- 与最强基线/ SOTA的差距:在ESC-50上,本方法的最优结果(冻结AST + 32次采样 + GPT-2)为88.3%,与全量微调的AST(88.8%)差距很小(0.5%),但与该数据集上更新的SOTA(论文未引用对比)的差距未知。
- 关键消融实验:论文的核心消融即为改变采样轨迹长度(T),并观察性能变化(如图2,图3所示)。另外,对比了不同推理模型(GPT-2微调 vs. GPT-OSS-20B vs. Qwen3-14B)在相同音频轨迹下的性能(表1)。但缺乏对聚合方法(目前仅用简单投票或LLM推理)的消融。
⚖️ 评分理由
- 学术质量:5.5/7。论文提出了一个完整且逻辑自洽的框架,并通过实验证明了“测试时缩放”在音频分类中的有效性。技术路线清晰,实验结果可观察到提升趋势。主要扣分点在于:1) 创新性属于概念迁移和框架整合,未提出根本性的新算法;2) 实验对比不够深入,例如未与更多类型的音频模型(如卷积网络)或更新的聚合方法对比;3) 部分关键实现细节(如具体采样策略、优化器)缺失。
- 选题价值:1.0/2。选题方向(测试时缩放应用于音频)具有前沿性和启发性。但该方法强依赖外部LLM进行推理,可能在实时性、部署成本上存在挑战。应用场景目前局限于标准分类,向更复杂的音频理解任务(如声源定位、字幕生成)的推广未被探讨,因此潜在影响和应用空间有限。
- 开源与复现加成:0.0/1。论文完全��有提供代码、模型或详细训练脚本的获取方式。所有模型(AST, YAMNet, GPT-2)均为公开模型,但论文中对它们进行的具体修改(如AST的补丁级预测头、嵌入矩阵训练细节)未充分公开,这严重阻碍了研究的可复现性。