📄 The Role of Prosodic and Lexical Cues in Turn-Taking with Self-Supervised Speech Representations
#语音对话系统 #自监督学习 #语音活动检测 #语音表示学习
✅ 7.5/10 | 前25% | #语音对话系统 | #自监督学习 | #语音活动检测 #语音表示学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Sam O’Connor Russell(都柏林三一学院工程学院)
- 通讯作者:未说明
- 作者列表:Sam O’Connor Russell(都柏林三一学院工程学院)、Delphine Charuau(都柏林三一学院工程学院)、Naomi Harte(都柏林三一学院工程学院)
💡 毒舌点评
本文巧妙地将神经科学中的“声音相关噪声”范式移植到语音轮次预测的可解释性分析中,像做手术一样干净地分离了韵律和词汇线索,方法论上值得称赞。然而,结论“仅韵律就够了”可能过于乐观,毕竟实验中的“韵律匹配噪声”在真实世界的噪声环境下难以复现,且模型在复杂对话场景中是否仍能如此可靠地依赖单一线索存疑。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:
github.com/russelsa/noise_generation_ICASSP-。 - 模型权重:未提及是否公开预训练好的VAP模型或S3R权重。
- 数据集:使用CANDOR语料库,论文未提及是否提供处理后的数据版本或获取方式。
- Demo:未提及。
- 复现材料:论文详细说明了训练超参数(学习率、batch size、epoch数)、vocoder参数、评估指标和划分方法,提供了充分的复现细节。
- 引用的开源项目:主要依赖WORLD vocoder、Whisper(用于计算WER)、CPC和wav2vec 2.0预训练模型。
📌 核心摘要
- 要解决的问题:基于自监督语音表示(S3R)的轮次预测模型性能优异,但其决策依赖于语音中的哪些线索(韵律 vs. 词汇)尚不清楚,这限制了模型的可解释性、隐私保护和轻量化潜力。
- 方法核心:引入一种基于WORLD vocoder的控制方法,能够干净地生成仅保留韵律(去除词汇可懂度)或仅保留词汇(平滑韵律)的语音,用于系统性地探究S3R模型(主要是VAP模型)的线索依赖关系。
- 与已有方法相比新在哪里:不同于以往通过简单滤波或添加背景噪声(会同时破坏多种线索)的研究,该方法能独立、可控地操纵语音的韵律和词汇成分,提供了更干净的实验条件。研究范围从单一S3R(CPC)扩展到了wav2vec2.0,增强了结论的普适性。
- 主要实验结果:
- 在纯净语音上训练的VAP模型,在测试时面对仅保留韵律的噪声语音(WER>100%),仍能保持较高的轮次预测准确率(S/H-Pred平衡准确率≈70%,见表2),接近纯净语音性能的91%(图4)。
- 相反,去除韵律(平滑音高和强度)后,性能虽下降但仍显著高于随机水平(表2)。
- 当一种线索被破坏时,模型无需重新训练即可利用另一种线索,证明两种线索在S3R编码中相互独立(图2)。这一结论在wav2vec2.0前端上同样成立。
- 实际意义:该发现为设计轻量化、仅依赖韵律的轮次预测模型提供了理论支持,此类模型具有计算高效和保护语音隐私(去除可识别词汇内容)的双重优势。
- 主要局限性:研究仅在英语对话语料库(CANDOR)上进行,跨语言泛化性未验证。所使用的“韵律匹配噪声”是一种受控实验条件,与真实世界的噪声干扰存在差异。
🏗️ 模型架构
论文主要分析的对象是语音活动投影(Voice Activity Projection, VAP)模型,一个基于S3R的轮次预测模型。其架构如下:
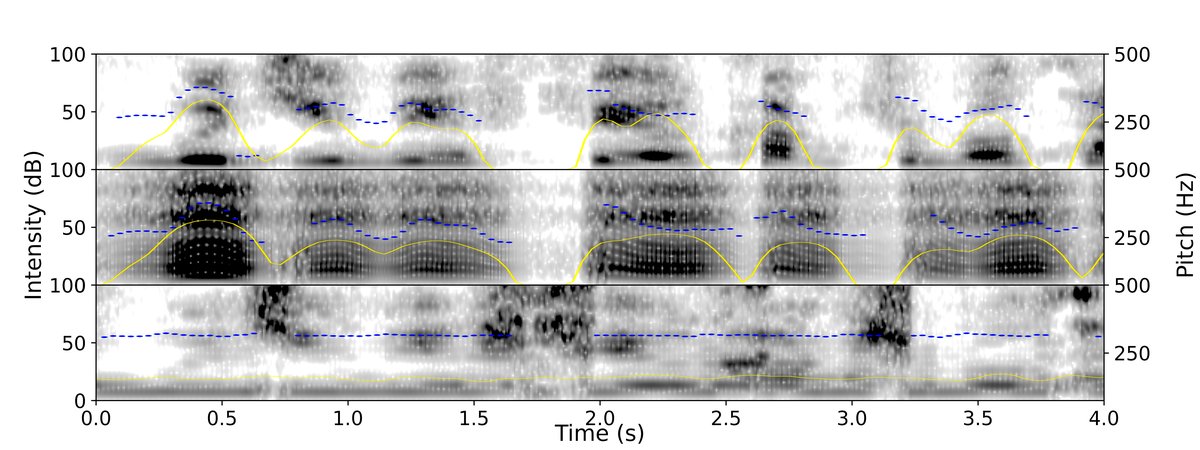 (注:此图(图1)主要展示语音信号处理示例,而非模型架构图。论文中未提供专门的VAP模型架构图。以下为文字描述。)
(注:此图(图1)主要展示语音信号处理示例,而非模型架构图。论文中未提供专门的VAP模型架构图。以下为文字描述。)
- 整体输入输出:输入为单个说话人的一段语音波形(通常为近期历史,如130个窗口)。输出为对未来2秒内(20Hz采样率)每个时间点上双方是否会说话的概率序列。
- 主要组件:
- 自监督语音表示(S3R)前端:论文测试了两种,一种是基于CPC的预训练编码器,另一种是wav2vec 2.0。它们将原始波形转换为高维的声学表示向量序列(如每秒100帧)。这部分是冻结的,不参与下游任务训练。
- 预测器:一个基于Transformer的网络。它接收S3R输出的向量序列,并通过3个自注意力层(用于建模当前说话人的语音上下文)和1个交叉注意力层(用于建模两个说话人之间的交互)来处理信息。最终通过一个投影层输出预测的概率。
- 数据流与设计选择:S3R负责提取丰富的声学特征,Transformer则负责建模这些特征在时间维度上的动态变化以及双人交互模式。使用冻结的预训练S3R是标准做法,旨在评估其本身所编码信息的效用。Transformer架构的选择是为了有效捕捉长距离依赖和交互关系。
💡 核心创新点
- 引入干净的声学线索控制方法:是什么:将WORLD vocoder与粉红噪声结合,生成保留原始音高和强度轮廓(韵律)但频谱包络为噪声(去除词汇可懂度)的语音。局限:以往研究(如平滑音高、添加背景噪声)会同时影响多种线索,难以归因。作用:能够近乎完美地隔离韵律线索,为后续实验提供了关键的“探针”。收益:首次在轮次预测领域实现了对语音线索的干净、可控分离,使结论更可靠。
- 证明韵律与词汇线索在S3R中独立支持轮次预测:是什么:发现模型在仅韵律(噪声)或仅词汇(平滑韵律)的测试条件下,性能均显著高于随机水平,且当一种线索缺失时能自动利用另一种。局限:先前研究未明确证明这种独立性,常认为线索是纠缠的。作用:通过系统的消融实验(表2、3, 图2、4)提供了直接证据。收益:深化了对S3R内部表示的理解,并指明了未来设计更高效、更注重隐私模型的方向。
- 揭示“仅韵律”的高效性:是什么:实验证明,用仅保留韵律的噪声语音训练的模型,其性能可达到用纯净语音训练的模型的87%-91%(图4)。局限:此结论在理想噪声条件下得出,实际环境噪声更复杂。作用:量化了韵律线索的独立贡献。收益:直接推动了开发轻量化、隐私保护型轮次预测模型的可能性。
🔬 细节详述
- 训练数据:使用CANDOR语料库。包含1657对美式英语双人对话,总计约850小时。音频为16kHz立体声(每人一轨)。转录时间戳由Amazon Transcribe提供。数据集划分:70个会话作为测试集,其余用于5折交叉验证。
- 损失函数:论文未明确提及VAP模型的损失函数名称。根据其任务性质(预测未来二值化的说话活动),通常采用二元交叉熵损失。
- 训练策略:
- 优化器/学习率:未明确说明优化器类型。学习率设为
1e-4。 - 批次大小:
32。 - 训练轮数:
10个epoch。 - 硬件:在NVIDIA RTX 6000 GPU上进行训练。
- 混合数据训练:为提升鲁棒性,部分实验使用了“混合”训练数据,其中75%为纯净语音,25%为某种特定干扰(如韵律匹配噪声、背景噪声等)。
- 优化器/学习率:未明确说明优化器类型。学习率设为
- 关键超参数:
- 模型维度:Transformer层隐藏维度为
256。 - S3R前端:CPC和wav2vec 2.0为预训练模型,其输出维度通过投影层统一到
256维。
- 模型维度:Transformer层隐藏维度为
- 推理细节:评估时,将模型输出的概率序列在200ms窗口内求和,并应用一个在验证集上调整的二值化阈值,以预测说话人切换点。评估指标包括S-Pred和S/H-Pred的F1分数及平衡准确率。
- 声学操控细节:使用WORLD vocoder(参数:
300ms窗,512点FFT,10ms帧移)。韵律匹配噪声:用粉红噪声替换原始语音的频谱包络,同时保留原始音高(F0)和强度轮廓。韵律平滑:将音高或强度轮廓替换为该话语的平均值。
📊 实验结果
论文的核心实验比较了不同训练和测试条件下VAP模型的性能。以下是关键结果表格的完整呈现:
表2:在纯净语音上训练的VAP模型,在各种操控语音上的测试性能(5折平均±标准差)
| 测试集内容 | 词汇 | 音高 | 强度 | S-Pred F1(w) | S-Pred 平衡准确率(%) | S/H-Pred F1(w) | S/H-Pred 平衡准确率(%) |
|---|---|---|---|---|---|---|---|
| 纯净语音 | ✓ | ✓ | ✓ | 0.86 | 85±0 | 0.83 | 80±1 |
| 韵律匹配噪声(无词汇) | ✗ | ✓ | ✓ | 0.60 | 60±2 | 0.69 | 61±1 |
| 平滑音高(保留词汇) | ✓ | ✗ | ✓ | 0.76 | 76±1 | 0.76 | 72±1 |
| 平滑强度(保留词汇) | ✓ | ✓ | ✗ | 0.71 | 71±1 | 0.72 | 66±1 |
| 同时平滑音高和强度 | ✓ | ✗ | ✗ | 0.68 | 68±1 | 0.70 | 63±1 |
结论:仅去除词汇信息(韵律匹配噪声)时,性能下降有限;仅去除韵律信息时,性能下降更明显,但均显著高于随机水平。说明模型对韵律和词汇线索均可利用。
表3:在特定操控语音上训练和测试的VAP模型性能(5折平均±标准差)
| 训练/测试集内容 | 词汇 | 音高 | 强度 | S-Pred 平衡准确率(%) | S/H-Pred 平衡准确率(%) |
|---|---|---|---|---|---|
| 韵律匹配噪声(仅韵律) | ✗ | ✓ | ✓ | 77±1.7 | 68±1.2 |
| 平滑音高(仅词汇) | ✓ | ✗ | ✓ | 82±1.8 | 76±1.4 |
| 同时平滑音高和强度(仅词汇) | ✓ | ✗ | ✗ | 74±3.4 | 70±3.0 |
| 纯净语音(基线) | ✓ | ✓ | ✓ | 85±0.4 | 80±1 |
结论:仅用韵律匹配噪声训练的模型,其性能(S-Pred: 77%, S/H-Pred: 68%)达到纯净语音模型(85%, 80%)的91%和85%。这证实了仅韵律线索就能支持有效的轮次预测。
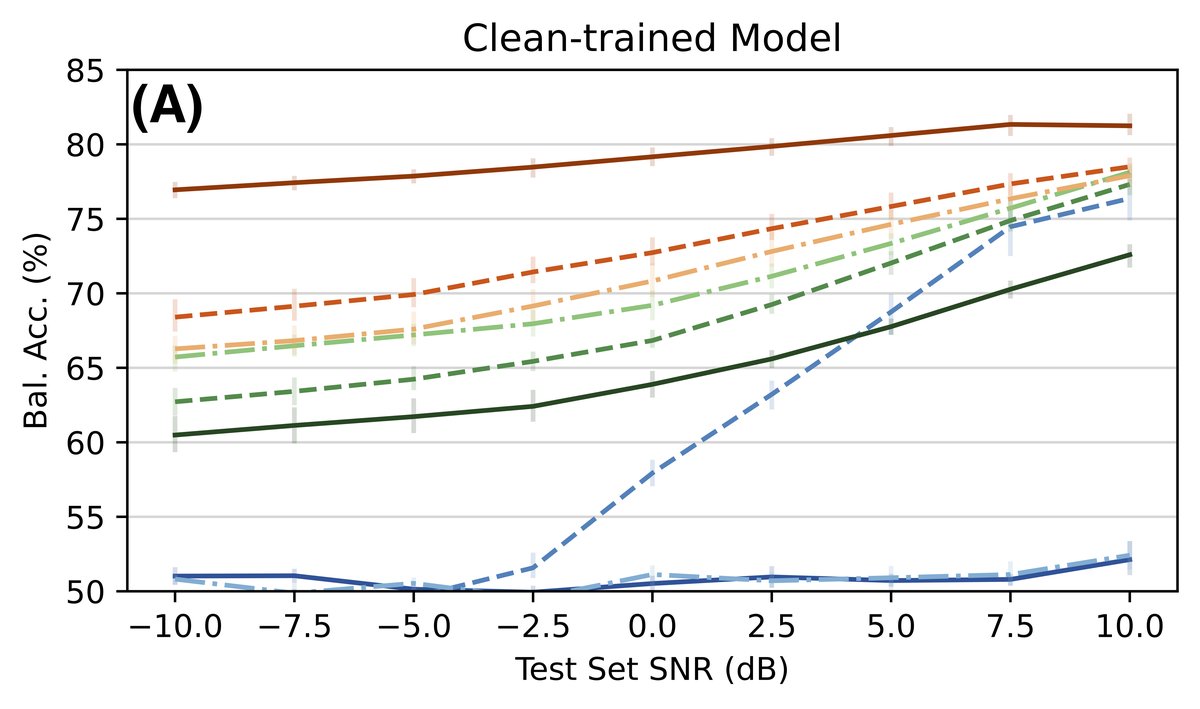
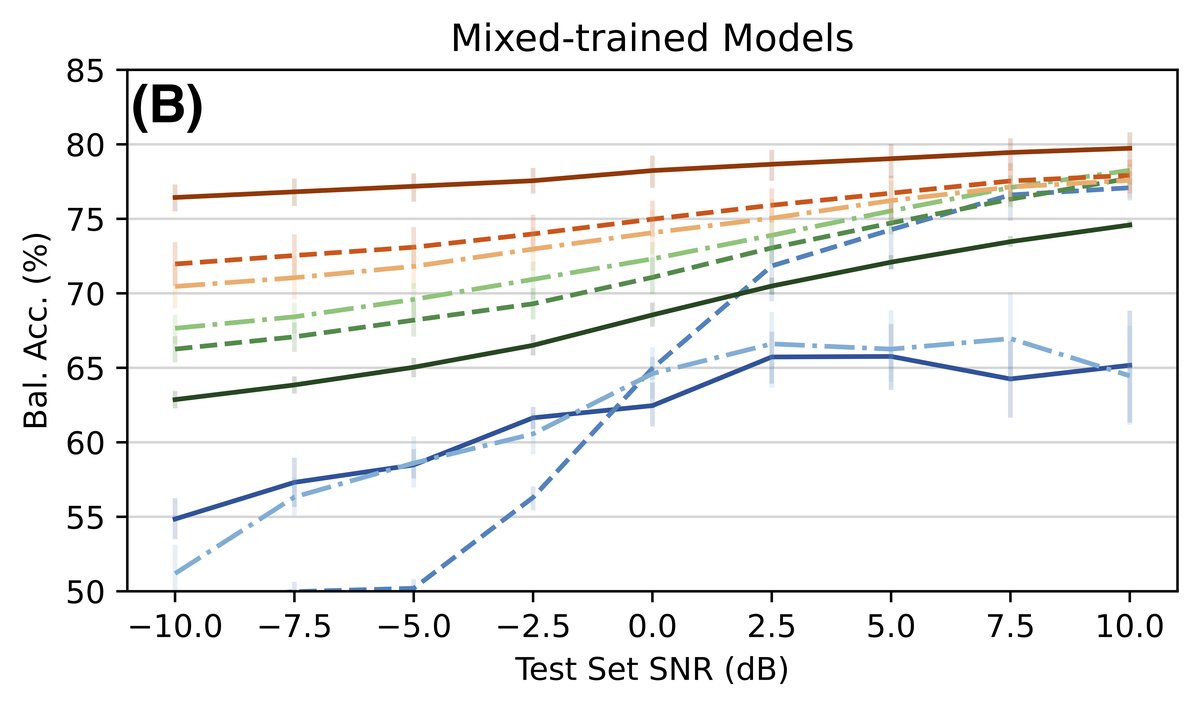 (图2)
说明:图2A显示在纯净语音模型上测试时,随着噪声增加,韵律匹配噪声(绿线)的性能下降比背景噪声(蓝线)缓慢,且在低信噪比下仍能保持一定准确率。图2B显示混合训练提升了模型在各自操控条件下的鲁棒性,但对低信噪比的背景噪声(蓝线)改善有限。
(图2)
说明:图2A显示在纯净语音模型上测试时,随着噪声增加,韵律匹配噪声(绿线)的性能下降比背景噪声(蓝线)缓慢,且在低信噪比下仍能保持一定准确率。图2B显示混合训练提升了模型在各自操控条件下的鲁棒性,但对低信噪比的背景噪声(蓝线)改善有限。
 (图3)
说明:图3量化了不同操控方式对语音可懂度的影响。韵律匹配噪声(绿色)的词错误率始终接近100%,证明词汇信息被完全去除。韵律平滑(橙色)对词错误率影响很小。背景噪声(蓝色)的词错误率随信噪比降低而升高。
(图3)
说明:图3量化了不同操控方式对语音可懂度的影响。韵律匹配噪声(绿色)的词错误率始终接近100%,证明词汇信息被完全去除。韵律平滑(橙色)对词错误率影响很小。背景噪声(蓝色)的词错误率随信噪比降低而升高。
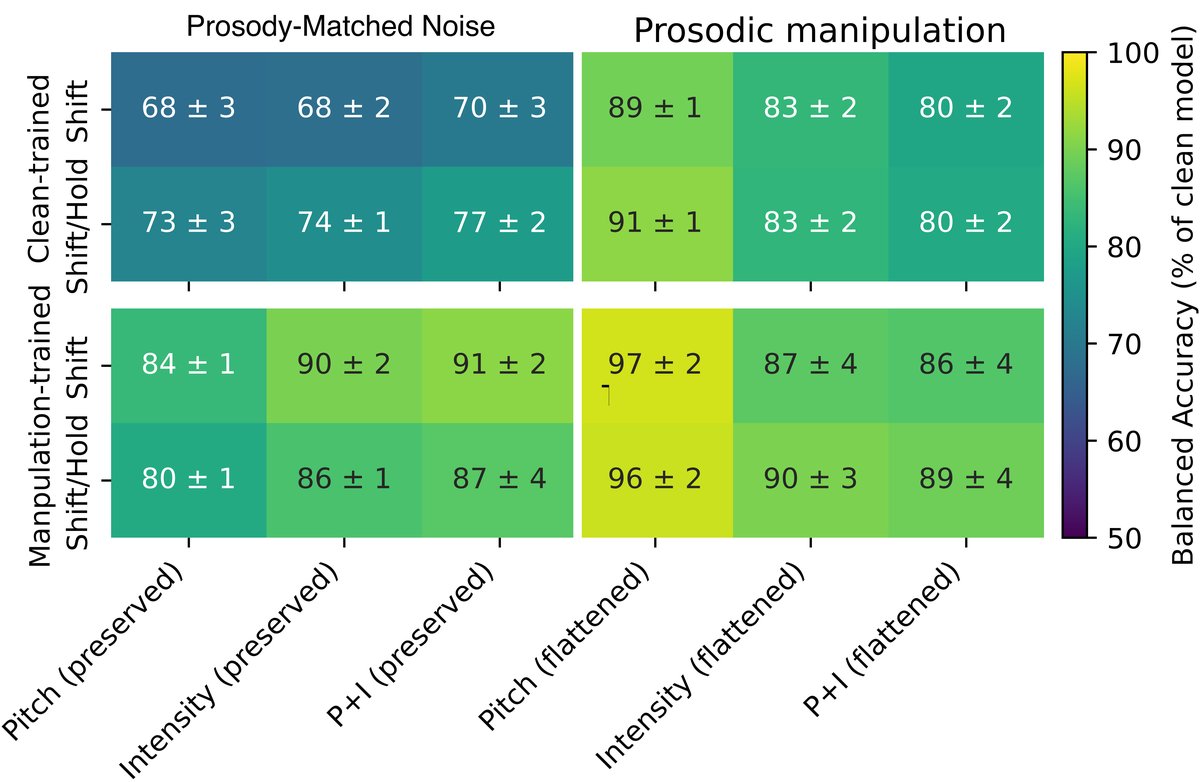 (图4)
说明:图4直观展示了,在仅韵律匹配噪声(绿色柱)或仅平滑韵律(橙色柱)的条件下训练或测试的模型,其性能可以达到纯净语音模型性能的87%-96%,有力地证明了韵律和词汇线索的独立有效性。
(图4)
说明:图4直观展示了,在仅韵律匹配噪声(绿色柱)或仅平滑韵律(橙色柱)的条件下训练或测试的模型,其性能可以达到纯净语音模型性能的87%-96%,有力地证明了韵律和词汇线索的独立有效性。
表4��使用wav2vec 2.0前端的VAP模型在纯净语音训练后的测试性能(5折平均±标准差)
| 测试集内容 | 词汇 | 音高 | 强度 | 平衡准确率(%) |
|---|---|---|---|---|
| 纯净语音 | ✓ | ✓ | ✓ | 93±0 |
| 韵律匹配噪声(无词汇) | ✗ | ✓ | ✓ | 92±1 |
| 同时平滑音高和强度(仅词汇) | ✓ | ✗ | ✗ | 92±1 |
结论:使用wav2vec 2.0时,去除韵律或词汇线索几乎不影响性能(均保持在92%),表明该发现不仅限于CPC,但wav2vec2.0的非因果特性可能导致了更高的基线性能。
⚖️ 评分理由
- 学术质量(5.5/7):创新性(2.0/3):方法论上的创新(干净控制声学线索)是明确的。研究问题(S3R轮次预测的线索依赖性)具有重要性。但结论(线索独立性)属于分析性发现,且已有前期工作铺垫,非从0到1的算法创新。技术正确性与实验充分性(2.5/2.5):实验设计非常系统,控制变量严谨,数据量充足,评估指标恰当,结论有充分的实验数据支撑。证据可信度(1.0/1.5):结果可复现(提供了代码),统计报告规范。主要局限是单一语料库,且“仅韵律”的实验条件与实际应用有差距。
- 选题价值(1.5/2):前沿性与潜在影响(1.0/1):轮次预测的可解释性研究是当前的热点。发现为“轻量化”和“隐私保护”的轮次预测模型提供了理论依据,具有明确的应用导向。应用空间与读者相关性(0.5/1):直接对话人机交互和语音助手开发。对于从事相关领域的研究者,本文提供的分析视角和实验方法具有参考价值。
- 开源与复现加成(+0.5/1):论文明确提供了代码仓库链接,且方法描述详细,极大提升了研究的可复现性和影响力,这是重要的加分项。