📄 The Muse Benchmark: Probing Music Perception and Auditory Relational Reasoning in Audio LLMs
#音乐理解 #基准测试 #音频大模型 #模型评估
🔥 8.5/10 | 前25% | #音乐理解 | #基准测试 | #音频大模型 #模型评估
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.7 | 置信度 高
👥 作者与机构
- 第一作者:Brandon James Carone(纽约大学心理学系,音乐与音频研究实验室)
- 通讯作者:未说明
- 作者列表:Brandon James Carone(纽约大学心理学系,音乐与音频研究实验室)、Iran R. Roman(伦敦玛丽女王大学电子电气工程与计算机科学学院,多模态AI中心)、Pablo Ripollés(纽约大学心理学系,音乐与音频研究实验室)
💡 毒舌点评
亮点在于它像一把精准的手术刀,切开了当前音频大模型“音乐理解”的华丽外衣,暴露出它们在真正的音乐关系推理(如转调、节拍感知)面前脆弱不堪的内核。短板则是论文止步于“诊断”而未开出“药方”——它证明了现有范式和提示技巧的局限,但对于如何从根本上构建具备音乐不变性表示的模型,讨论略显不足。
🔗 开源详情
- 代码:提供了论文中提到的GitHub仓库链接(github.com/brandoncarone/MUSE_music_benchmark),用于评估脚本和任务描述。
- 模型权重:论文中未提及提供新模型权重,评估的是现有公开模型(Gemini, Qwen, Audio Flamingo 3)。
- 数据集:
- 200段音乐刺激已公开,提供了Airtable链接。
- 人类被试实验数据已公开,提供了OSF存储库链接,并设置了只读访问权限。
- Demo:论文中未提及在线演示。
- 复现材料:提供了刺激制作工具和参数(Logic Pro X,具体设备型号和插件)、完整的评估方法(提示策略、few-shot示例、系统指令的摘要在表A中)以及人类实验的详细流程。
- 论文中引用的开源项目:评估的模型均为外部开源或公开API项目(Gemini 2.5, Qwen2.5-Omni, Audio Flamingo 3)。使用了PsychoPy进行人类实验。
📌 核心摘要
- 解决的问题:现有针对音频大语言模型的评测多集中于表层分类任务,无法有效评估其对音乐深层结构(如音高不变性、调性层级、节奏分组)的感知和关系推理能力。
- 方法核心:构建了名为“MUSE”的音乐理解与结构评估基准,包含10项任务,分为“初级”(基础感知与不变性)和“高级”(需要音乐理论知识的推理)两个层级,并系统性地评估了四个SOTA模型(Gemini Pro/Flash, Qwen2.5-Omni, Audio Flamingo 3)在“独立”和“思维链(CoT)”提示下的表现,同时与200名人类被试进行对比。
- 新在哪里:与现有基准不同,MUSE的任务设计深深植根于音乐认知科学,旨在探测模型是否真正理解了音乐的“结构”而非仅仅“标签”。它首次对多个前沿模型在关系推理任务上进行了系统性的、与人类对标的横向比较。
- 主要实验结果:模型表现方差极大,且普遍存在严重缺陷。例如,在旋律形状识别任务中,Qwen2.5-Omni的准确率仅为23.33%,低于25%的随机水平(见表2)。最强模型Gemini Pro在初级任务上接近人类专家(如怪音检测100%),但在高级推理任务(如节拍识别46.67%)上远低于人类专家(73.30%)。CoT提示策略效果不稳定,常带来性能下降。
- 实际意义:MUSE为评估和推动具备真正音乐理解能力的AI系统提供了一个关键的诊断工具和基准。它明确指出,提升模型能力可能需要从架构和训练范式上突破,而不仅仅是缩放规模或优化提示。
- 主要局限性:基准测试本身无法指明解决路径。论文揭示了差距,但对于如何设计能学习音乐不变表示的模型,提出的建设性方案有限。此外,人类“专家”样本量较小(N=6),可能影响对比的统计效力。
🏗️ 模型架构
本文并非提出一个新的模型架构,而是对现有音频大语言模型进行系统性评测的框架论文。因此,其核心“架构”是评测系统本身。评测流程如下:
- 刺激生成与准备:使用专业音频设备和软件(Logic Pro X, Neural DSP插件等)创作并录制了200段音乐刺激(平均长度14.1秒),涵盖钢琴、吉他、贝斯、鼓等乐器。
- 模型推理设置:为每个模型编写定制化的推理脚本,以确保提示传递的标准化和响应记录。针对需要比较两个音频的任务,根据模型能力进行适配:Qwen和Gemini支持多文件输入;Audio Flamingo 3需将两个音频拼接并用语音提示分隔。
- 提示策略:设置两种条件:
- 独立(Standalone):模拟人类实验,提供系统指令和few-shot示例,利用模型的聊天模式维持对话历史。
- 思维链(Chain-of-Thought, CoT):在提示中引导模型进行多步骤分析推理,并要求其在给出答案前阐述推理过程。
- 评估执行与记录:每个任务运行三次(不同随机种子),取平均准确率以应对模型输出的随机性。所有推理日志被系统记录。
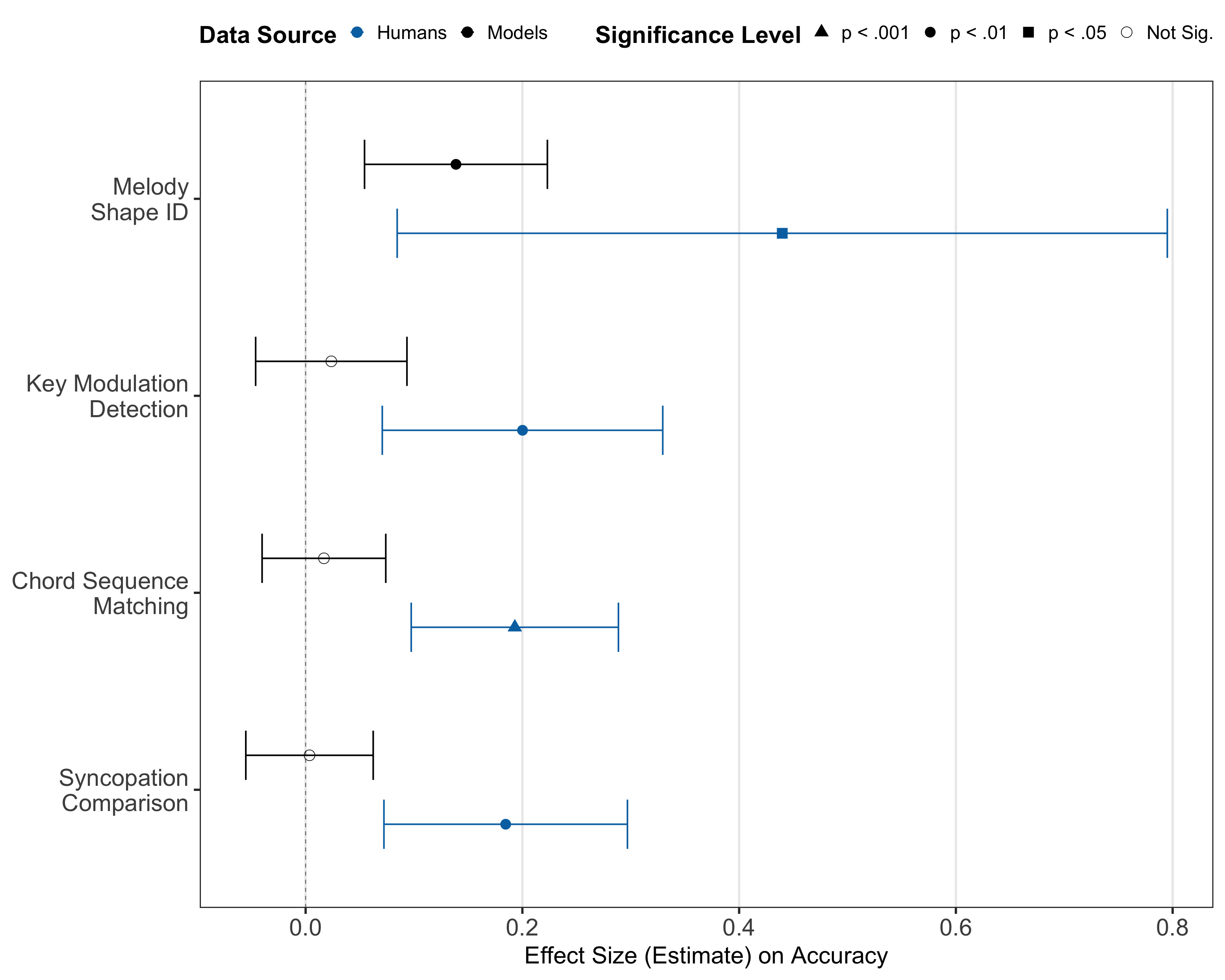 图1:MUSE基准上SOTA模型与人类被试的对比。图中显示了四个模型(AF3, Qwen, Flash, Pro)与人类非专家和专家在10项任务上的准确率。可以看出模型间差异巨大,且人类专家在多项高级任务上显著领先。
图1:MUSE基准上SOTA模型与人类被试的对比。图中显示了四个模型(AF3, Qwen, Flash, Pro)与人类非专家和专家在10项任务上的准确率。可以看出模型间差异巨大,且人类专家在多项高级任务上显著领先。
💡 核心创新点
- 基于音乐认知科学的基准设计:创新性地将音乐感知理论转化为可计算的评测任务,如“音高平移检测”(测试不变性)、“奇音检测”(测试调性层级感知),系统性地探测模型对音乐结构的理解深度。
- 揭示SOTA模型的根本性缺陷:通过严谨的对比,首次定量揭示了多个主流模型在核心音乐感知任务上存在严重失败,如Qwen在旋律形状识别上表现低于随机水平,暴露了其无法处理相对音高方向的根本问题。
- 对提示策略的批判性分析:系统性地评估了CoT提示在音乐推理任务上的效果,发现其并非常用的“万能药”,反而常常有害。并通过分析CoT输出日志,指出了模型“推理正确,结论错误”的不可靠性。
- 模型与人类学习模式的对比分析:创新性地使用“few-shot示例数量”作为模型“学习”的代理,与人类“音乐训练年限”进行对比,发现两者学习模式根本不同:人类训练带来稳定提升,而模型增加示例效果不稳定,暗示了当前范式的局限。
🔬 细节详述
- 训练数据:不适用。本文是评测论文,不涉及模型训练。测试使用的200段音乐刺激是为本研究专门创作的,已在GitHub和Airtable链接中公开。
- 损失函数:不适用。
- 训练策略:不适用。
- 关键超参数:不适用。
- 训练硬件:不适用。
- 推理细节:
- 所有模型均使用官方API或推荐接口进行推理。
- 针对Audio Flamingo 3,因其在保持聊天历史和few-shot条件下表现极差,故采用无历史、无示例、单次提示的特殊评估方案。
- 每个任务脚本运行3次,取平均准确率。
- 正则化或稳定训练技巧:不适用。
- 人类数据收集细节:
- 通过Prolific和纽约大学招募234名在线参与者,经耳机测试筛选后保留200人。
- 使用Gold-MSI量表评估音乐专业度,将得分在90百分位以上(N=6)定义为“专家音乐家”。
- 实验在PsychoPy上实现,任务和刺激顺序随机化,任务分半进行以减少疲劳。
📊 实验结果
主要结果总结如下表:
表2:MUSE基准十项任务准确率(%)
| 策略 | 模型 | 乐器ID | 旋律形状 | 怪音检测 | 节奏匹配 | 音高平移 | 和弦ID | 和弦序列匹配 | 调性转调 | 切分音比较* | 节拍识别 | 平均(初级) | 平均(高级) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 独立 | AF3 | 80.00 | 25.00 | 50.00 | 50.00 | 50.00 | 65.00 | 50.00 | 60.00 | 50.00 | 40.00 | 51.00 | 53.00 |
| Qwen | 98.33 | 23.33 | 73.33 | 56.67 | 51.67 | 51.67 | 60.00 | 61.67 | 50.00 | 33.33 | 60.67 | 51.33 | |
| Flash | 98.33 | 56.67 | 91.67 | 88.33 | 56.67 | 48.33 | 40.00 | 68.33 | 56.67 | 38.33 | 78.33 | 50.33 | |
| Pro | 98.33 | 96.67 | 100.00 | 96.67 | 81.36 | 58.33 | 66.67 | 88.33 | 69.49 | 46.67 | 94.61 | 66.09 | |
| CoT | AF3 | 70.00 | 25.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 40.00 | 49.00 | 48.00 |
| Qwen | 98.33 | 18.33 | 70.00 | 50.00 | 58.33 | 48.33 | 50.00 | 48.33 | 50.00 | 35.00 | 58.99 | 46.33 | |
| Flash | 91.67 | 46.67 | 85.00 | 63.33 | 86.67 | 43.33 | 48.33 | 58.33 | 43.33 | 35.00 | 74.67 | 46.38 | |
| Pro | 98.33 | 96.67 | 100.00 | 88.33 | 98.33 | 56.67 | 46.67 | 81.67 | 61.67 | 50.00 | 96.33 | 61.12 | |
| 人类 | 非专家 | 89.90 | 70.30 | 74.20 | 92.90 | 92.90 | 66.80 | 60.90 | 64.60 | 59.60 | 43.90 | 84.04 | 59.16 |
| 专家 | 98.30 | 95.00 | 90.00 | 100.00 | 100.00 | 83.30 | 85.00 | 91.70 | 92.30 | 73.30 | 96.72 | 85.12 |
注:带号任务需要处理两个音频。人类分数中,灰色背景表示优于最佳模型。随机水平见论文表2底部。*
(同图1,已使用)
图1结论:Gemini Pro在所有模型中表现最强,尤其在初级任务上表现突出。然而,在需要复杂推理的高级任务上,它与人类专家的差距显著。Qwen和Audio Flamingo 3在多项任务上表现接近或低于随机水平。
模型学习与人类学习对比分析(图2):
- 关键发现:对于Gemini模型,增加few-shot示例数量对“旋律形状识别”任务有显著正效应(p < .001),但对需要抽象推理的“调性转调检测”、“和弦序列匹配”和“切分音比较”任务无显著效应。
- 人类对照:相比之下,人类被试的“音乐训练”水平对所有四项任务的准确率均有显著的正向影响。
- 结论:这表明当前模型的“上下文学习”无法等同于人类通过训练内化抽象规则的过程,其性能更依赖于预训练获得的基础能力。
⚖️ 评分理由
- 学术质量:6.2/7:论文的实验设计严谨,评估全面,分析深入(包括对CoT输出的质性分析)。其主要贡献是提出了一个高质量的评测框架并提供了有力的实证证据,揭示了当前技术的真实水平与缺陷。由于是评测工作而非建模创新,因此在“创新性”维度上得分略低。
- 选题价值:1.5/2:选题精准切入当前音频AI评测的空白领域——深层音乐理解。其发现对于指导未来模型架构和训练范式的研究具有重要价值,对音频AI社区有广泛启发。
- 开源与复现加成:0.7/1:完全开源了评测所用的代码、刺激数据和人类实验数据,透明度高,极大地促进了该基准的复现和后续研究。缺乏模型训练细节是其性质决定的,不影响评测工作的复现。