📄 The Impact of Audio Watermarking on Audio Anti-Spoofing Countermeasures
#音频深度伪造检测 #领域适应 #知识蒸馏 #音频水印 #音频安全
🔥 8.5/10 | 前25% | #音频深度伪造检测 | #领域适应 | #知识蒸馏 #音频水印
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Zhenshan Zhang(杜克昆山大学多模态智能系统苏州重点实验室, 数字创新研究中心)
- 通讯作者:Ming Li(杜克昆山大学多模态智能系统苏州重点实验室, 数字创新研究中心, ming.li369@dukekunshan.edu.cn)
- 作者列表:Zhenshan Zhang(杜克昆山大学多模态智能系统苏州重点实验室, 数字创新研究中心)、Xueping Zhang(杜克昆山大学多模态智能系统苏州重点实验室, 数字创新研究中心)、Yechen Wang(OfSpectrum, Inc.)、Liwei Jin(OfSpectrum, Inc.)、Ming Li(杜克昆山大学多模态智能系统苏州重点实验室, 数字创新研究中心)
💡 毒舌点评
亮点:选题填补了一个重要的认知空白——系统量化了“水印”这种合法但普遍存在的人为扰动对反欺骗系统的“无差别攻击”效果,实验设计严谨(控制水印比例、类型分布),结论可靠。提出的KPWL框架在“已知水印”适应上取得了立竿见影的效果,思路清晰实用。 短板:在“未见水印”场景下的性能反而下降,暴露了当前方法对水印特异性的过拟合,极大限制了其在真实世界(水印类型未知且多样)中的应用价值,也说明“领域适应”的本质挑战并未被彻底解决。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:https://github.com/Alphawarheads/Watermark_Spoofing.git。
- 模型权重:论文未提及是否公开预训练的模型权重(如基线XLSR+SLS或KPWL适应后的模型)。
- 数据集:论文指出构建了“Watermark-Spoofing”数据集,并提供了获取方式(通过上述GitHub仓库),表明数据集是公开的。
- Demo:论文中未提及在线演示。
- 复现材料:论文详细说明了数据集构建协议(水印方法、比例)、训练配置(优化器、学习率、轮数、损失函数超参数)、评估设置,复现信息充分。
- 论文中引用的开源项目:引用了ASVspoof 2019/2021数据集[12,20]、In-the-Wild数据集[21]、多种水印方法(WavMark[4], Timbre[5], AudioSeal[13]等)、反欺骗模型(XLSR[6], SLS[9], Nes2Net[10])以及数据增强工具RawBoost[28]。
📌 核心摘要
- 问题:本文首次研究了广泛使用的音频水印技术(为版权保护设计)对语音反欺骗(深度伪造检测)系统性能的影响,发现这种影响之前被完全忽视。
- 方法核心:构建了包含多种手工和DNN水印的“Watermark-Spoofing”数据集,并系统评估了现有模型性能下降的程度。提出名为“知识保留水印学习”(KPWL)的适应框架,通过在冻结前端(XLSR)和分类器的情况下微调中间层,并结合对称知识蒸馏与参数锚定,使模型能适应水印引入的分布偏移。
- 创新:首次揭示了音频水印是反欺骗系统面临的一种新的、未被研究的领域偏移源;首次构建了用于评估和缓解此问题的专用数据集与基准;提出了首个旨在同时适应水印并保留原始域检测能力的专用框架。
- 实验结果:在ASVspoof 2021 LA数据集上,当75%的样本被水印时,基线模型(XLSR+SLS)的EER从3.02%上升至3.68%。KPWL模型在相同条件下将EER降至3.21%,同时在干净数据上保持3.06%(与基线3.02%接近)。然而,在“未见水印”评估中,基线模型在75%水印(LA21)下EER为9.94%,而KPWL模型恶化至11.22%。
- 实际意义:提醒反欺骗系统开发者需考虑水印带来的鲁棒性挑战;为构建抗水印污染的反欺骗系统提供了首个基准和初步解决方案;揭示了水印技术可能对语音安全生态产生的意外副作用。
- 主要局限性:KPWL框架在应对未见过的水印类型时效果不佳甚至有害,表明当前方法的适应能力局限于训练时接触过的特定水印,泛化能力有待突破。
🏗️ 模型架构
本文的核心模型架构并非提出一种全新的端到端神经网络,而是提出了一种训练策略与框架(KPWL),用于适应现有的反欺骗模型以应对水印干扰。以论文中作为骨干的 XLSR+SLS 模型为例,其整体流程与KPWL框架的适配如下:
整体流程:
- 阶段一(原始基线预训练):使用标准监督学习在原始(无水印)的ASVspoof 2019 LA训练集上训练XLSR+SLS模型。
- 阶段二(知识保留水印学习, KPWL):使用“Watermark-Spoofing训练集”(部分水印化的LA19)对阶段一的模型进行微调,目的是让模型适应水印偏移,同时保持其在原始干净数据上的能力。
KPWL框架详细结构与数据流(见图1):
- 输入:原始波形(16kHz, 标准化)。
- 前端(SSL Frontend):例如XLSR模型, 提取高层语音特征表示。在KPWL阶段,此部分权重被冻结(不更新)。
- 中间后端层(Intermediate Backend Layers):连接前端和分类器的若干全连接层。这是KPWL阶段唯一被训练/更新的部分。
- 分类器(Classifier):例如SLS中的fc3层, 输出真假语音的概率。在KPWL阶段,此部分权重被冻结。
- 教师-学生框架:在KPWL训练过程中,阶段一训练好的原始模型作为“教师”,当前正在适应水印的模型作为“学生”。对称知识蒸馏损失(L_KD) 用于约束学生的预测输出(logits)与教师的预测保持接近。
- 参数锚定(L2-SP):L2-SP正则化损失 用于惩罚KPWL阶段可训练参数(即中间层权重)与其在该阶段开始时的初始化值(即来自阶段一预训练模型的权重)的偏离。
- 损失函数:
L = L_task(加权交叉熵) + β L_KD(对称KL散度) + µ L2-SP(参数L2距离)。 - 输出:修改后的概率分布, 判断音频为真实(bonafide)或伪造(spoof)。
关键设计选择及动机:
- 冻结SSL前端:动机是保留模型在预训练阶段学到的、对水印扰动相对稳健的低层/通用语音特征表示,防止其被水印噪声“带偏”。
- 冻结分类器:动机是维持模型在原始干净数据上已建立的、精确的决策边界。
- 仅更新中间层:允许模型通过微调中间层的特征组合方式,来适应水印引入的特征分布变化,而不破坏已经学到的表示和决策逻辑。
- 结合知识蒸馏与参数锚定:双重约束(输出层面和参数层面)确保适应过程是渐进的、受控的,避免灾难性遗忘或对水印的过拟合。
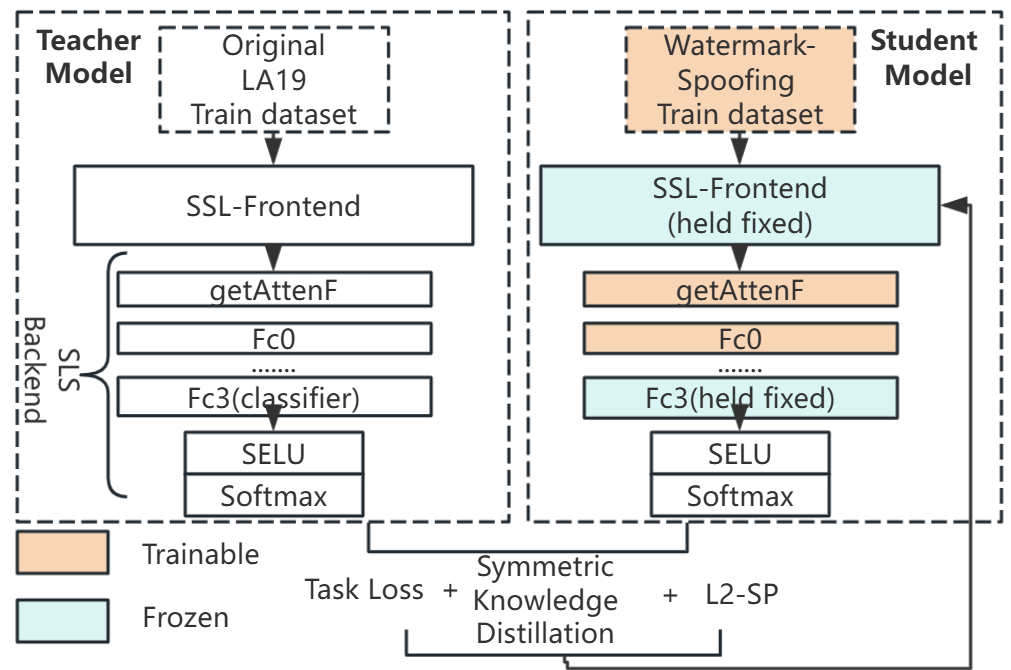 图1展示了KPWL框架。左侧是“Original Baseline Pretraining”阶段,模型在原始数据上训练。右侧是“Knowledge-Preserving Watermark Learning”阶段,虚线框表示被冻结的部分(SSL前端和分类器),仅中间层被更新。同时,通过教师-学生网络(由虚线箭头连接的“Teacher”和“Student”)实现对称知识蒸馏(L_KD),并通过参数锚定(L2-SP)约束中间层参数不偏离初始值(Wi)。最终损失L由任务损失、蒸馏损失和锚定损失组成。
图1展示了KPWL框架。左侧是“Original Baseline Pretraining”阶段,模型在原始数据上训练。右侧是“Knowledge-Preserving Watermark Learning”阶段,虚线框表示被冻结的部分(SSL前端和分类器),仅中间层被更新。同时,通过教师-学生网络(由虚线箭头连接的“Teacher”和“Student”)实现对称知识蒸馏(L_KD),并通过参数锚定(L2-SP)约束中间层参数不偏离初始值(Wi)。最终损失L由任务损失、蒸馏损失和锚定损失组成。
💡 核心创新点
- 问题揭示与量化:首次系统研究并证实了音频水印(一种合法且广泛存在的处理)是反欺骗检测性能下降的一个重要且未被重视的原因,将“水印”重新定义为一种领域偏移源。
- 专用基准构建:构建了首个包含多种手工和神经网络水印方法、覆盖不同水印比例、并区分“已见/未见水印”的Watermark-Spoofing数据集与评估协议,为后续研究提供了标准化的测试平台。
- 知识保留适应框架:提出了KPWL,通过“冻结两端、适配中间”结合知识蒸馏与参数正则化的策略,在有效适应水印偏移的同时,最大限度地保留模型在原始干净数据上的检测能力,实现了鲁棒性与原始性能的平衡。
🔬 细节详述
- 训练数据:
- 原始基线预训练:ASVspoof 2019 LA训练集。
- KPWL适应训练:基于LA19训练集构建的“Watermark-Spoofing Training dataset”,其中50%的样本被水印化。水印类型包括6种手工方法和3种DNN方法,按比例应用于真实(bonafide)和伪造(spoof)样本。
- 损失函数:见上文架构部分公式(1)。L_task为加权交叉熵,β=0.3, µ=1e-4。
- 训练策略:
- 基线预训练:优化器Adam,学习率1e-7,权重衰减1e-4,最多50轮,早停。
- KPWL适应:从预训练模型继续,优化器Adam,学习率5e-7(高于预训练),权重衰减1e-4,训练2轮。仅更新中间层参数。
- 关键超参数:XLSR前端模型规模未具体说明(通常为~300M参数)。SLS分类器为轻量级。关键超参数包括KPWL的学习率(5e-7)、训练轮数(2)、蒸馏损失权重(β=0.3)、参数锚定权重(µ=1e-4)。
- 训练硬件:论文未提供具体GPU型号、数量或训练时长信息。
- 推理细节:未说明具体解码策略。输入音频预处理为16kHz,通过平铺或截断统一为64600个采样点。使用RawBoost进行数据增强。
- 正则化/稳定训练技巧:KPWL中使用了对称知识蒸馏(双向KL散度)和L2-SP参数锚定来稳定适应过程。训练中使用了类权重来应对类别不平衡。
📊 实验结果
论文通过一系列表格系统展示了水印的影响和KPWL的有效性。
表1:单一水印方法对检测性能的影响(模型:XLSR+SLS, 测试集:In-the-Wild)
| 水印方法 | 75%水印 | 50%水印 | 25%水印 | 0%水印 | 75%相对提升(∆) |
|---|---|---|---|---|---|
| AudioSeal (2024) | 7.46% | 7.40% | 7.35% | 7.32% | +1.91% |
| Timbre (2023) | 8.18% | 7.93% | 7.53% | 7.32% | +11.75% |
| WavMark (2023) | 9.90% | 9.06% | 8.23% | 7.32% | +35.25% |
| DNN (2022) | 9.06% | 8.65% | 8.06% | 7.32% | +23.77% |
| 结论:所有水印方法都导致EER上升,且水印比例越高,EER越高。较新的水印方法(如AudioSeal)引入的性能下降更小。 |
表2:混合水印数据对不同基线模型的影响(训练集:LA19, 测试集:Watermark-Spoofing Seen Eval.)
| 模型 | 测试数据集 | 75% | 50% | 25% | 0% | 75% ∆ |
|---|---|---|---|---|---|---|
| XLSR+AASIST | LA21 | 0.88% | 0.83% | 0.79% | 0.73% | +20.55% |
| ITW | 11.28% | 10.65% | 10.00% | 9.42% | +19.75% | |
| DF21 | 6.16% | 6.08% | 5.99% | 5.86% | +5.12% | |
| XLSR+SLS | LA21 | 3.68% | 3.52% | 3.35% | 3.02% | +21.85% |
| ITW | 8.46% | 7.83% | 7.57% | 7.32% | +15.57% | |
| DF21 | 2.23% | 2.13% | 2.17% | 2.01% | +10.94% | |
| XLSR+Nes2Net-X | LA21 | 2.25% | 2.20% | 2.08% | 2.00% | +12.50% |
| ITW | 6.40% | 6.07% | 5.84% | 5.50% | +16.36% | |
| DF21 | 1.85% | 1.84% | 1.82% | 1.76% | +5.11% | |
| 结论:在所有模型和数据集上,水印比例与EER呈正相关,证实水印导致性能下降。 |
表5:KPWL框架在“已见水印”评估集上的效果(骨干:XLSR+SLS)
| 数据集 | 模型 | 75% | 50% | 25% | 0% |
|---|---|---|---|---|---|
| LA21 | Baseline | 3.68% | 3.52% | 3.35% | 3.02% |
| Watermarked | 3.28% | 3.25% | 3.23% | 3.17% | |
| KPWL | 3.21% | 3.18% | 3.12% | 3.06% | |
| ITW | Baseline | 8.46% | 7.83% | 7.57% | 7.32% |
| Watermarked | 9.03% | 8.75% | 8.57% | 8.21% | |
| KPWL | 7.92% | 7.74% | 7.60% | 7.37% | |
| DF21 | Baseline | 2.23% | 2.13% | 2.17% | 2.01% |
| Watermarked | 2.13% | 2.07% | 2.00% | 1.87% | |
| KPWL | 2.04% | 1.95% | 1.92% | 1.74% | |
| 结论:KPWL在75%水印条件下,在ITW上将EER从基线的8.46%降至7.92%,在LA21上从3.68%降至3.21%,且几乎不损失干净数据(0%)性能。 |
表6:KPWL框架在“未见水印”评估集上的效果(骨干:XLSR+SLS)
| 数据集 | 模型 | 75% | 50% | 25% | 0% |
|---|---|---|---|---|---|
| LA21 | Baseline | 9.94% | 8.01% | 5.72% | 3.07% |
| Watermarked | 10.21% | 8.00% | 5.64% | 3.17% | |
| KPWL | 11.22% | 8.47% | 5.66% | 3.04% | |
| ITW | Baseline | 13.41% | 11.43% | 9.36% | 7.32% |
| Watermarked | 15.66% | 13.15% | 10.68% | 8.62% | |
| KPWL | 14.78% | 12.27% | 9.71% | 7.37% | |
| DF21 | Baseline | 8.42% | 6.34% | 4.31% | 2.01% |
| Watermarked | 8.60% | 6.40% | 4.20% | 1.87% | |
| KPWL | 10.05% | 7.24% | 4.50% | 1.75% | |
| 结论:这是论文的关键局限性发现。面对未见过的水印方法,KPWL模型在高水印比例下性能反而比基线模型更差(如LA21上75%水印,KPWL为11.22% vs 基线9.94%),表明框架可能过拟合于训练时使用的特定水印。 |
⚖️ 评分理由
- 学术质量:6.5/7:创新性强,首次提出并验证了一个重要的交叉问题(水印 vs 反欺骗)。技术实现(KPWL)合理,实验设计严谨(多数据集、多模型、已见/未见评估)。扣分点在于核心方法(KPWL)在关键的“未见水印”测试中表现不佳,限制了其普适性和影响力,且论文未深入探讨此局限的根本原因或提供进一步的解决方案。
- 选题价值:1.5/2:选题新颖且具有前瞻性,直接关联音频内容安全两大技术(水印与反欺骗),对相关领域的研究者有明确价值。应用空间明确(指导抗水印污染的反欺骗系统设计)。扣分点在于问题本身相对垂直,受众可能不如通用反欺骗或生成模型广泛。
- 开源与复现加成:0.8/1:提供了完整的代码和数据集仓库,训练和评估细节描述详尽(超参数、损失函数权重等),极大便利了复现。未公开预训练模型权重可能略微影响复现便捷性,但整体开源程度很高。