📄 Text2Move: Text-To-Moving Sound Generation via Trajectory Prediction and Temporal Alignment
#空间音频 #音频生成 #预训练 #多任务学习 #数据集
🔥 8.0/10 | 前25% | #空间音频 | #多任务学习 | #音频生成 #预训练
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yunyi Liu(悉尼大学 University of Sydney)
- 通讯作者:未说明
- 作者列表:Yunyi Liu(悉尼大学)、Shaofan Yang(杜比实验室 Dolby Laboratories)、Kai Li(杜比实验室)、Xu Li(杜比实验室)
💡 毒舌点评
论文的亮点在于其巧妙的“分解”思想,将复杂的移动声音生成问题拆解为可控的轨迹预测、单声道音频生成与基于对象的音频空间化,框架清晰且具有很好的模块化扩展性。但短板在于,为了评估轨迹预测模块,构建了一个基于线性匀速运动的简化合成数据集,这可能无法充分代表真实世界中声音轨迹的复杂性和音频的多样性,使得方法在泛化到真实场景时的有效性存疑。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:论文中明确说明构建了合成数据集(76,850个样本),但未提供公开下载或获取方式。
- Demo:提供了在线演示网站链接:https://reinliu.github.io/text2move/。
- 复现材料:论文给出了部分训练细节(优化器、学习率、轮数、批次大小等),但未提供完整的配置、检查点或附录说明。
- 论文中引用的开源项目:使用了DistilBERT文本编码器[14]、Make-An-Audio 2扩散模型[16]、AudioTime数据集[17]和HRTF库[18]。
📌 核心摘要
- 问题:现有文本驱动的空间音频生成主要聚焦于静态声源,无法有效生成具有动态空间运动的声音,限制了沉浸式体验。
- 方法核心:提出一种混合框架,将生成过程分解为:a) 从文本预测声源的三维时空轨迹;b) 微调一个预训练的文本到音频模型以生成与该轨迹时间对齐的单声道音频;c) 基于预测的轨迹对单声道音频进行基于对象的空间化模拟。
- 新意:首次在统一框架中显式地连接了文本、轨迹和音频,利用了“轨迹”作为中间表示来提供精确的空间和时间控制,区别于端到端生成FOA或双耳音频的方法。
- 主要结果:
- 文本到轨迹模型在合成测试集上表现出合理的预测能力(例如,方位角MAE为18.53°,范围感知MAE为15.52°)。
- 轨迹预测器和时间调整器均能实现高精度的时间对齐(起止点MAE均低于0.01秒,重叠率OLR分别为0.86和0.94)。
- 与仅预测端点的基线模型相比,全轨迹预测模型的绝对精度较低,但预测结果仍落在预定义的空间范围内。
- 实际意义:为可控的移动声音生成提供了新思路,可集成到现有的文本到音频工作流中,应用于VR/AR、游戏、电影音效等需要动态空间音频的领域。
- 主要局限性:完全依赖于构建的合成数据集进行训练和评估,数据集中的运动轨迹为简单的线性匀速运动,音频与空间属性是解耦合成的,可能无法完全反映真实世界数据的复杂性;未与现有的端到端空间音频生成方法在生成质量(如听感自然度、空间准确性)上进行直接对比。
🏗️ 模型架构
本文提出的Text2Move框架由两个主要部分构成,其整体架构如图1所示。
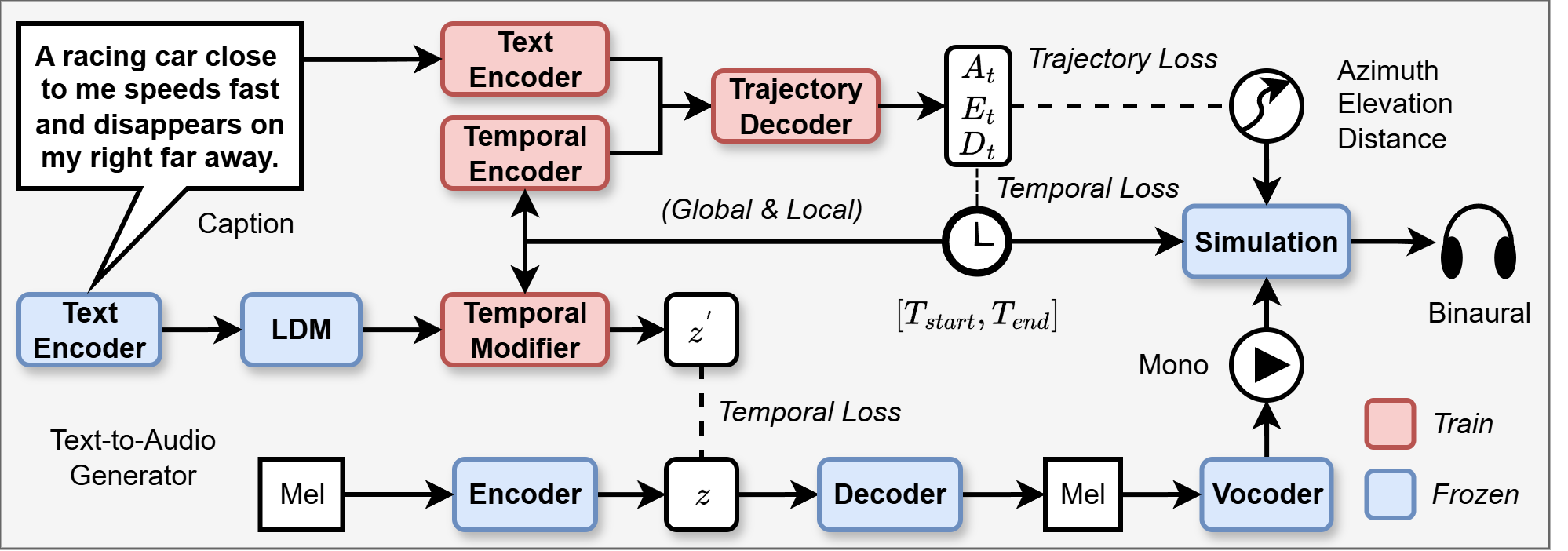
- 文本到轨迹预测模型 (Text-to-Trajectory Prediction) 该模型旨在从文本描述中预测一个移动声源的三维时空轨迹(方位角、仰角、距离随时间的变化)。
- 输入:描述声音事件和空间运动的文本字符串。
- 组件与数据流:
- 文本语义编码器 (Text Encoder):采用预训练的DistilBERT(隐藏维度768),通过可学习的注意力池化将token嵌入聚合成一个512维的语义向量,作为共享潜在空间。
- 时间编码器 (Temporal Encoder):在全局和局部两个层面注入时间信息。
- 全局层面:输入事件的起止时间戳(t0, t1),通过傅里叶特征映射和两层MLP编码成一个512维的全局时间嵌入。
- 局部层面:为轨迹上的每个时间步分配一个归一化索引τ∈[0,1],同样通过傅里叶特征和投影得到64维的每步嵌入。
- 轨迹解码器 (Trajectory Decoder):一个4层、8头、隐藏维度512的Transformer编码器。在每个时间步,将512维文本嵌入、512维全局时间嵌入和64维每步嵌入拼接后投影,输入Transformer进行自注意力计算。最后通过一个轻量级回归头(两层线性层)输出每步的方位角、仰角和距离。输出通过tanh(乘以±180°和±90°)和softplus激活函数进行约束,以确保物理意义。
- 输出:一个时间对齐的轨迹序列,包含每个时间步的(azimuth, elevation, distance)。
- 设计动机:这种设计显式地建模了轨迹的每一个点,相比于仅预测起止点的基线,提供了更细粒度的时空控制。
- 时序对齐的文本到音频生成与空间化
- 文本到单声道音频生成:使用一个预训练的潜在扩散模型(Make-An-Audio 2)作为骨干。为了使其生成的音频能与预测轨迹在时间上对齐,引入了时序调整器 (Temporal Modifier)。这是一个可训练的轻量模块,结合卷积层(局部平滑)和MLP(编码t0, t1),通过二值掩码调整扩散模型的潜在表示z_ldm,仅修改目标时间窗口外的区域,保留窗口内的原始生成,从而确保生成的声音事件发生在正确的时间段内。
- 基于对象的空间化:利用上一步生成的与轨迹时间对齐的单声道音频,结合预测的轨迹,通过与HRTF进行逐帧卷积来模拟生成双耳空间音频。
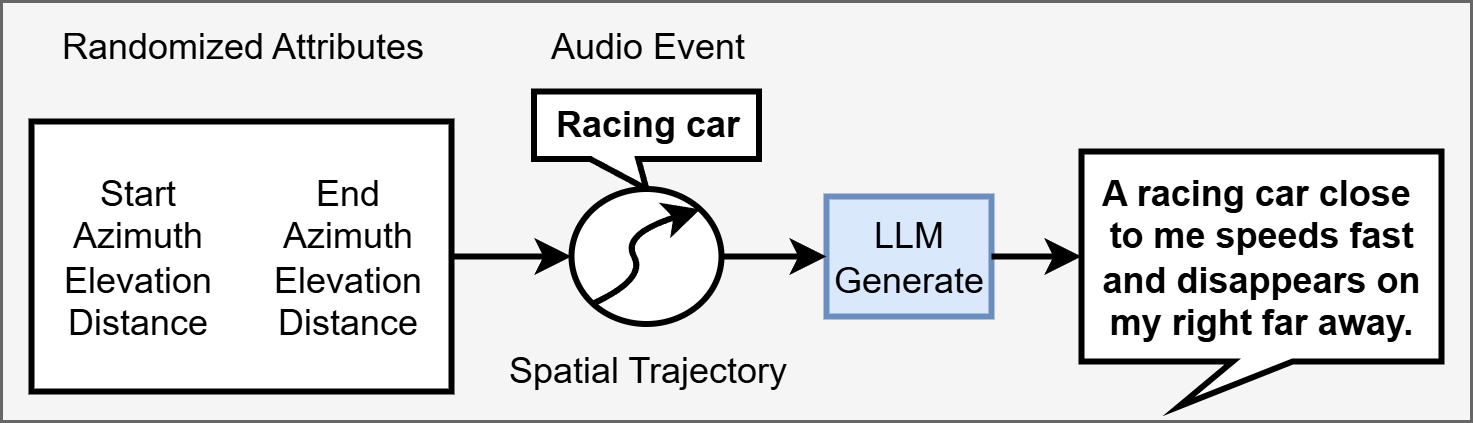
图2展示了数据集构建过程,该过程对于训练上述模型至关重要。
💡 核心创新点
- 问题分解与模块化框架:首次将“文本到移动声音生成”问题显式分解为“文本->轨迹”、“文本->时间对齐音频”和“轨迹+音频->空间化”三个子问题。这比端到端生成FOA或双耳音频的方法更具可解释性、可控性,并允许灵活替换各模块(如使用更好的T2A模型或空间化引擎)。
- 轨迹作为中间表示:将“轨迹”引入文本到空间音频的生成流程,作为连接语义(文本)和信号(音频)的桥梁。轨迹提供了明确、显式的运动控制信号,这是现有工作(主要生成静态空间音频)所缺乏的。
- 轻量级时序对齐机制:针对T2A模型缺乏精确时间控制的问题,设计了一个时序调整器,通过掩码重建损失微调潜在表示,使生成的音频能与预测轨迹在时间上精确同步,且不破坏预训练模型原有的生成能力。
🔬 细节详述
- 训练数据:
- 来源与预处理:基于AudioTime数据集(5000个带时间戳的单声道音频),筛选出单源事件,得到7685个干净片段。
- 数据增强与合成:为每个片段随机分配10次起止空间位置(基于图1/Table 1定义的方位角、仰角、距离类别范围),生成76,850个样本(213小时)。假设声源从起点到终点做匀速直线运动,采样率20Hz。通过与HRTF库中的HRIR逐帧卷积,模拟生成双耳音频。
- 文本标注:使用GPT-4根据音频事件和分配的空间属性生成自然语言描述,并进行50%的随机省略(OM)以增加多样性。
- 损失函数:
- 轨迹预测损失:包含两部分。
L_traj:带掩码的轨迹损失。对有效时间步(由mt控制)的方位角和仰角使用圆形L1误差(∆◦(x, y) = min(|x-y|, 360-|x-y|)),对距离使用标准L1误差。各维度通过权重waz, wel, wds平衡。L_time:端点对齐损失。额外惩罚预测轨迹的首尾位置与真实起止点的偏差,同样使用圆形L1误差。 总损失:L_total = L_traj + λ_time * L_time。
- 时序调整器损失:使用掩码MSE损失(
L_temp),仅对目标时间窗口外的潜在表示进行优化,迫使调整器在窗口外生成“静音”特征,而保持窗口内特征不变。
- 轨迹预测损失:包含两部分。
- 训练策略:
- 轨迹预测模型:优化器AdamW(lr=1e-5, weight_decay=1e-4),训练10,000 epochs,batch size 256,使用混合精度训练和梯度裁剪(1.0)。
λ_time的值论文未明确说明。 - 时序调整器:冻结扩散模型骨干,仅优化调整器模块。优化器AdamW(lr=1e-4),训练10 epochs。
- 轨迹预测模型:优化器AdamW(lr=1e-5, weight_decay=1e-4),训练10,000 epochs,batch size 256,使用混合精度训练和梯度裁剪(1.0)。
- 关键超参数:
- 文本编码器:DistilBERT,隐藏维度768。
- 轨迹解码器Transformer:4层,8头,隐藏维度512,FFN扩展因子4,dropout 0.1。
- 傅里叶特征频率数F=8。
- 轨迹采样率20Hz。
- 训练硬件:论文中未说明。
- 推理细节:论文中未说明具体的解码策略(如扩散步数、采样器)或流式设置。
📊 实验结果
论文主要评估了轨迹预测模块的准确性和时序对齐模块的有效性。
表2. 轨迹预测结果对比
| 属性 | 模型 | 准确率(Accuracy) | 宏平均F1(Macro-F1) | 平均绝对误差(MAE) | 范围感知MAE(RA-MAE) |
|---|---|---|---|---|---|
| 方位角 | 朴素基线 (端点预测) | 98.2% | 98.5% | 5.789° | 2.339° |
| 全轨迹预测 | 75.9% | 75.1% | 18.53° | 15.52° | |
| 仰角 | 朴素基线 (端点预测) | 98.0% | 98.1% | 6.431° | 1.352° |
| 全轨迹预测 | 61.2% | 65.9% | 28.75° | 21.44° | |
| 距离 | 朴素基线 (端点预测) | 87.5% | 87.1% | 0.166 | 0.013 |
| 全轨迹预测 | 66.7% | 52.1% | 1.601 | 0.365 |
关键结论:
- 仅预测起止点的朴素模型表现极佳,证明文本编码器能很好地理解空间语义。
- 全轨迹预测模型的绝对精度较低,但RA-MAE指标显示其预测值大多落在预定义的合理空间范围内(如方位角RA-MAE为15.52°,远小于类别宽度)。这表明模型学到了正确的空间概念,但在轨迹细节的精确回归上仍有挑战。
- 与预测端点相比,预测完整轨迹是一个难度显著增加的任务。
表3. 时序对齐性能
| 方法 | 起点MAE (秒) | 终点MAE (秒) | 重叠率(OLR) |
|---|---|---|---|
| 轨迹预测器 | 0.0086 | 0.0012 | 0.8596 |
| 时序调整器 | 0.0018 | 0.0024 | 0.9370 |
关键结论:
- 两种方法都能实现毫秒级的时间对齐精度(MAE < 0.01秒)。
- 时序调整器获得了更高的重叠率(0.94),表明其通过直接操作潜在表示能更精确地控制音频事件的起止边界。
注意:论文未提供最终生成的空间音频在听感自然度、空间定位准确性等主观或客观质量指标上的评估结果,也未与其他文本到空间音频生成方法(如[2, 3, 5])进行对比。
⚖️ 评分理由
- 学术质量:6.5/7。创新性体现在将问题分解并引入轨迹中间表示,设计合理;技术细节描述清晰;实验设计合理,在合成数据集上验证了各模块的有效性。但缺乏与更强大端到端生成模型的对比,且最终生成音频的质量未被量化评估,降低了结论的完整性。
- 选题价值:1.5/2。选题瞄准了空间音频生成中的一个明确空白(动态声源),前沿性强;提出的方法为可控的沉浸式音频内容创作提供了新工具,应用前景明确。
- 开源与复现加成:0.0/1。论文仅提供了演示网站链接,未公开代码、模型权重或完整的训练数据,严重限制了社区复现和在此基础上进一步研究的可能性。