📄 Text2midi-InferAlign: Improving Symbolic Music Generation with Inference-Time Alignment
#音乐生成 #强化学习 #文本到音乐 #自回归模型 #大语言模型
✅ 7.5/10 | 前25% | #音乐生成 | #强化学习 | #文本到音乐 #自回归模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Abhinaba Roy (新加坡科技设计大学)
- 通讯作者:未明确说明,从致谢和贡献看,Dorien Herremans或Geeta Puri可能为通讯作者,但论文中未明确标注。
- 作者列表:Abhinaba Roy (新加坡科技设计大学)、Geeta Puri (新加坡科技设计大学)、Dorien Herremans (新加坡科技设计大学)
💡 毒舌点评
本文巧妙地将大语言模型领域成熟的“推理时对齐”范式跨界应用到符号音乐生成,通过精心设计的奖励函数(文本-音频一致性+调性一致性)引导搜索,无需重训模型即可显著提升生成质量,尤其是对自由文本描述的适应性(2.6:1偏好),思路清晰且实用。不过,其核心贡献更像是一次“优秀的系统集成与工程优化”,在音乐生成的深层理论或全新架构上并未突破;奖励函数的设计(如固定权重)以及对“音乐性”的衡量仍依赖于CLAP等外部模型和调性规则,可能限制了其捕捉更复杂、更人性化音乐美学的能力。
🔗 开源详情
- 代码:提供代码仓库链接
https://github.com/AMAAILab/t2m-inferalign。 - 模型权重:未提及是否公开预训练的模型权重。
- 数据集:未提及新数据集。基线模型使用公开的MidiCaps数据集。
- Demo:未提及在线演示。
- 复现材料:论文给出了关键超参数(m, T, α, β)和生成设置(2000 tokens),但未提供详细的训练日志、配置文件或预训练检查点。
- 论文中引用的开源项目:Text2midi模型、MidiCaps数据集、CLAP模型、Claude-3-Haiku LLM、COSIATEC工具、MIDI Miner库、PsyToolkit。
📌 核心摘要
- 解决的问题:现有端到端文本到MIDI生成模型(如Text2midi)在推理时,生成的符号音乐在语义上与输入文本对齐不足,且常出现破坏音乐结构性(如调性不协和)的问题。
- 方法核心:提出Text2midi-InferAlign,一种无需重训练的推理时对齐框架。将生成过程建模为奖励引导的树搜索,交替进行“探索”(使用LLM对原始标题进行变异以扩展搜索空间)和“利用”(基于两个奖励函数:CLAP衡量文本-音频一致性,调性检查衡量和声一致性,对候选序列进行排序和替换)。
- 创新之处:首次将基于奖励的推理时对齐技术应用于符号音乐生成;设计并验证了针对语义和结构完整性的互补奖励函数;引入标题变异机制以促进生成多样性。
- 主要实验结果:在MidiCaps测试集上,相比基线Text2midi模型,所有客观指标均有提升,其中CLAP分数提升31.8%,速度(TB)提升32.5%。主观听音测试中,68.75%的听众认为其音乐质量更优。消融实验显示,变异数T=5、替换周期m=100时效果较优。
- 实际意义:提供了一种即插即用的增强模块,可提升任意自回归音乐生成模型的输出质量与可控性,推动更实用的AI音乐创作工具发展。
- 主要局限性:性能提升高度依赖奖励函数的设计和外部模型(如CLAP)的质量;对于包含丰富音乐细节的标题(如MidiCaps),探索空间受限,提升幅度有限;推理时间略有增加(约7%)。
🏗️ 模型架构
本论文未提出新的生成模型架构,而是提出了一个推理时优化框架,应用于现有的自回归MIDI生成模型(以Text2midi为例)。整体流程如图1所示。
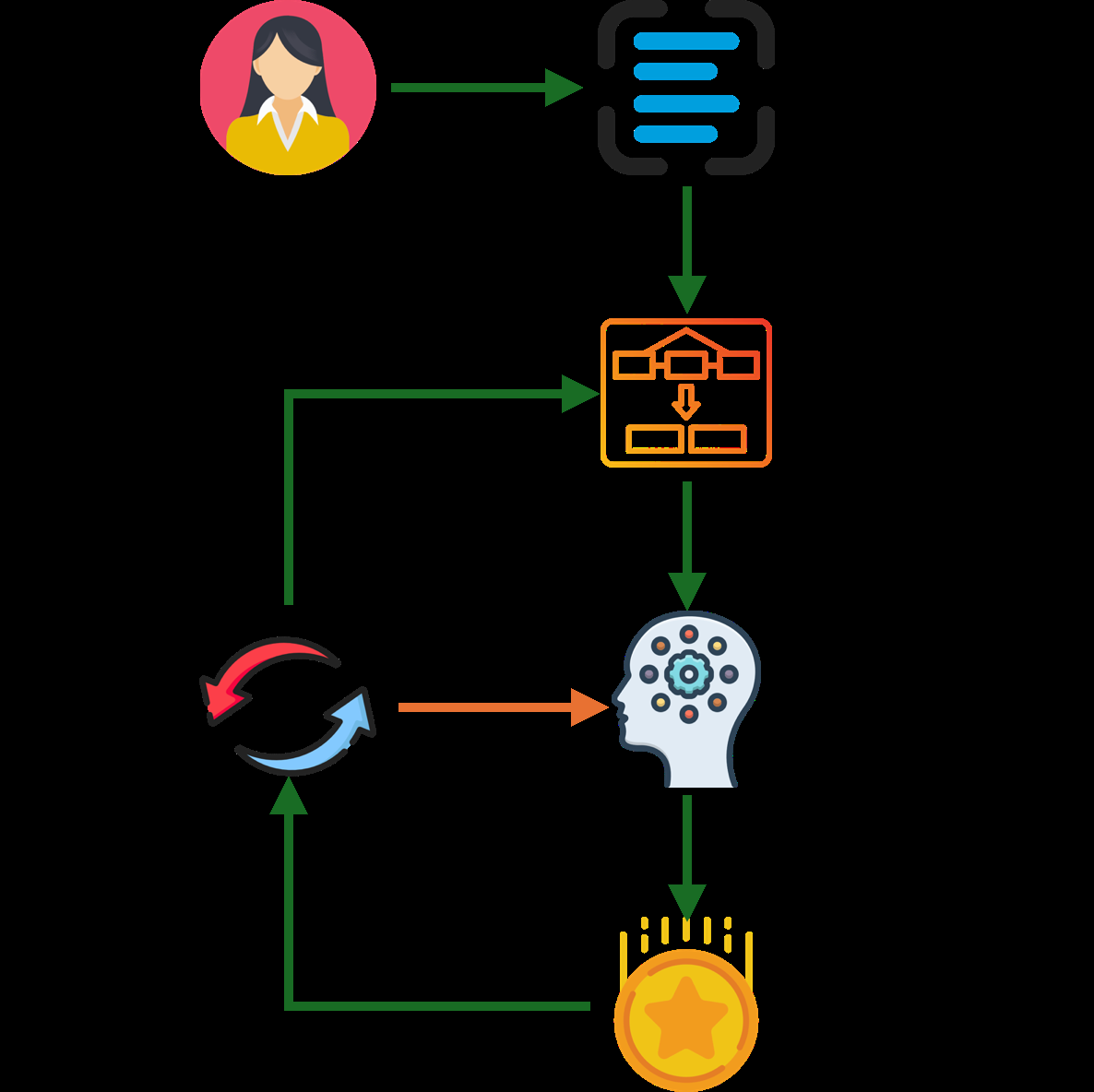
核心流程与组件:
- 输入:一个文本标题
x。 - 初始化:使用该标题初始化
q个并行的搜索状态(beams),每个状态代表一个部分生成的MIDI序列。 - 生成循环(迭代 N 次):
- 探索阶段(每
m步触发):对于当前每个搜索状态si,利用外部LLM(Claude-3-Haiku)将其对应标题xi进行变异,生成T个文本变体。这些变体将用于扩展新的搜索分支,探索不同的生成可能性。 利用阶段(每m步触发):对所有活跃的搜索状态si,计算其复合奖励分数R(si, x) = αRa(s, x) + β*Rh(s, x)。根据分数对状态进行排序,保留分数最高的k个状态(即“精英”状态),将其余低分状态替换为随机从这k个精英状态复制而来的副本。这个过程聚焦搜索于高奖励路径。 - 扩展:使用预训练的自回归模型(Text2midi)为每个状态
si生成下一个音乐符号(token),扩展序列。
- 探索阶段(每
- 输出:生成循环结束后,返回获得最高复合奖励分数的完整MIDI序列。
关键设计选择:
- 奖励函数:作为优化的“指南针”,直接决定了生成音乐的目标。组合奖励旨在平衡语义贴合度与音乐结构性。
- 树搜索:将生成过程显式地建模为在巨大输出空间中的搜索,利用“探索-利用”平衡来寻找更优解。
- 标题变异:鼓励模型从略微不同的文本描述角度去生成,增加多样性并可能发现更优的生成路径,尤其对开放式自由文本有效。
💡 核心创新点
- 推理时对齐框架的迁移:首次将大语言模型领域已验证有效的“基于奖励引导树搜索的推理时对齐”范式,成功应用于符号音乐生成任务。此前方法主要依赖训练时优化(如RLHF),成本高且不灵活。本文方法在推理时通过搜索实现优化,无需修改或重训原模型,通用性强。
- 领域特定的复合奖励函数:此前方法在音乐生成评估中常仅依赖单一指标或通用感知分数。本文明确设计了两个互补奖励:
Ra(文本-音频一致性)通过跨模态CLAP模型捕捉语义对齐;Rh(和声一致性)通过调性检查确保基本的音乐规则符合性。实验证明两者结合有协同效应(5.3节)。 - 用于探索的标题变异策略:此前方法的生成空间由固定输入决定。本文引入LLM作为“变异器”,生成标题的语义扩展、结构精炼和流派上下文化变体,有效扩展了搜索空间。这对弥合用户简略描述与模型丰富训练数据之间的差距尤为重要(见5.4节)。
🔬 细节详述
- 训练数据:论文未提供新训练数据。其方法应用于在MidiCaps数据集上预训练的Text2midi基线模型。
- 损失函数:未提供本文方法自身的损失函数。其核心优化目标是最大化设计的复合奖励函数
R(s, x),这是一个推理时目标,而非训练损失。 - 训练策略:不适用。本文方法无需训练,仅在推理时进行优化。
- 关键超参数:
- 搜索束大小
q,替换周期m,变异数T,保留精英数k。 - 奖励权重
α=1,β=5。权重选择理由未充分说明。 - 消融实验表明
m=100和T=5效果较优。
- 搜索束大小
- 训练硬件:未提及训练硬件,因其方法不涉及训练。推理在单张Nvidia L40S GPU上进行。
- 推理细节:
- 生成序列长度:2000个token。
- 解码策略:在奖励引导的树搜索框架下,使用beam search的变体。
- 推理时间:相比基线,仅增加约7%(9.3秒 vs. 8.7秒)。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
论文在MidiCaps测试集上进行了评估,基线模型为Text2midi。
客观指标对比(表3)
指标 Text2midi (基线) Text2midi-InferAlign (本文方法) 提升幅度 结构与语义 压缩比 (CR) ↑ 2.31 2.47 +6.9% CLAP分数 ↑ 0.22 0.28 +31.8% 音乐特征 速度匹配 (TB) (%) ↑ 39.73 52.64 +32.5% 允许容差的速度匹配 (TBT) (%) ↑ 66.80 69.18 +4.2% 正确调性 (CK) (%) ↑ 33.60 40.08 +19.3% 含重复音的正确调性 (CKD) (%) ↑ 35.60 47.18 +15.3% 结论:本文方法在所有六项客观指标上均优于基线。 消融研究(表1,表2)
替换周期
m的影响(T=3):指标 m=100 m=500 m=1000 m=2000 (Best-of-N) TB (%) ↑ 37.50 37.50 31.25 37.50 TBT (%) ↑ 62.50 62.50 56.25 62.50 CK (%) ↑ 37.50 31.25 43.75 37.50 CKD (%) ↑ 43.75 31.25 43.75 37.50 结论:m=100在整体性能上最优,尤其是CKD。更频繁的优化(更小的m)通常更好。 变异数
T的影响(m=100):指标 T=1 (无变异) T=3 T=5 TB (%) ↑ 37.50 37.50 37.50 TBT (%) ↑ 62.50 62.50 62.50 CK (%) ↑ 37.50 37.50 50.00 CKD (%) ↑ 37.50 43.75 50.00 结论:增加变异数T能显著提升调性正确率(CK, CKD),T=5达到当前测试最佳。
- 主观听音测试(表4,表5)
总体偏好:
评估标准 Text2midi Text2midi-InferAlign 音乐质量 31.25% 68.75% (2.2:1) 文本-音频匹配度 41.67% 58.33% (1.4:1) 结论:听众显著偏好本文方法生成的音乐质量和文本匹配度。 按标题类型分解:
标题类型 Text2midi Text2midi-InferAlign MidiCaps(详细) 48.33% 51.67% (1.1:1) 自由文本(开放) 27.78% 72.22% (2.6:1) 结论:方法对自由文本的提升极为显著(2.6:1),因为变异探索能更好地丰富简略描述。
- 补充分析
- 奖励函数贡献(5.3节):单独使用Ra对CLAP提升大(+24.1%)但对CK提升小(+8.3%);单独使用Rh对CK提升大(+9.2%)但对CLAP提升小(+6.7%)。组合使用效果超越简单相加,存在协同效应。
- 变异类型分析(5.4节):变异主要分三类:语义扩展(47%)、结构精炼(31%)、流派上下文化(22%)。语义扩展对自由文本最有效。
- 计算效率(5.6节):推理时间仅增加7%。
⚖️ 评分理由
- 学术质量:5.5/7。创新在于将成熟范式成功迁移至新领域并系统验证,技术实现正确,实验设计周密(消融、主客观评估)。扣分点在于核心模型无创新,部分设置缺乏理论依据,且对“音乐性”的评估仍依赖于现有指标和外部模型。
- 选题价值:1.5/2。符号音乐生成是活跃且实用的研究方向,解决“文本-音乐对齐”这一核心痛点具有明确的应用价值和前沿性。
- 开源与复现加成:0.5/1。提供了代码仓库链接,具备开源基础。但缺失模型权重、详细数据配置和完整复现脚本,加成有限。