📄 Testing The Efficient Coding Hypothesis Beyond Humans: The Auditory Kernels of Bat Vocalizations
#生物声学 #稀疏编码 #信号处理 #音频分类
✅ 7.5/10 | 前25% | #生物声学 | #稀疏编码 | #信号处理 #音频分类
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明
- 通讯作者:未说明
- 作者列表:Aleksandra Savova(代尔夫特理工大学电气工程、数学与计算机科学学院)、Dimme de Groot(代尔夫特理工大学电气工程、数学与计算机学院)、Jorge Martinez(代尔夫特理工大学电气工程、数学与计算机学院)
💡 毒舌点评
亮点:方法新颖,首次将稀疏编码(Matching Pursuit)应用于蝙蝠回声定位信号的“听觉核”分析,成功提取出与叫声结构(CF-FM)高度对应的功能特化表示,为“高效编码假说”跨越物种边界提供了有力的计算证据。短板:结论的生物学说服力受限于缺乏真实的蝙蝠听觉神经生理数据(如revcor函数)作为验证基准,目前只能证明叫声结构本身“适合”被稀疏编码,而非“证实”蝙蝠大脑正是如此编码。
🔗 开源详情
- 代码:提供了GitHub仓库链接(https://github.com/D1mme/rp_auditory_kernels/tree/main),包含字典学习和匹配追踪的实现。
- 模型权重:论文中未提及公开训练好的“听觉核”字典权重。
- 数据集:使用公开的ChiroVox数据集(https://chirovox.org/)。
- Demo:论文中未提及在线演示。
- 复现材料:论文详细说明了数据预处理步骤、模型参数(字典大小、初始化长度、MP率)和评估指标。引用了具体的MP算法实现库[38]。
- 论文中引用的开源项目:引用了匹配追踪的具体实现[38]。
📌 核心摘要
- 问题:高效编码假说(生物感知系统最大化信息传输并最小化神经消耗)在人类语音中得到验证,但其在非人类(特别是依赖复杂回声定位的蝙蝠)听觉感知中的作用尚不明确。
- 方法:采用基于匹配追踪(Matching Pursuit)的稀疏编码方法,以大菊头蝠(Rhinolophus affinis)的回声定位叫声为数据,通过数据驱动学习得到一组“听觉核”字典,并分析其特性。
- 创新:与以往使用黑盒模型研究蝙蝠声音不同,本研究专注于从叫声结构本身出发,在早期听觉处理层面(独立于高级神经处理)检验其是否内禀地优化了稀疏表示。
- 结果:学习到的核具有紧凑、稀疏和功能专化的特点。它们能高效重建叫声(例如,图1显示200个激活即可达到SNR 20.62 dB),且核的激活模式能编码叫声特定形状。定量比较显示,对于R. affinis叫声,该方法的比特率-保真度(SNR)优于傅里叶和小波变换(图4)。聚类分析(27类)揭示了叫声多样性,包括主要谐波结构、伪影和窄CF成分(图6)。所有稀疏度指标(Gini指数≈0.99)均很高。
- 意义:为动物发声信号的计算建模提供了基础,支持未来在解码动物声音和跨物种通信领域的研究。证明了高效表示可以从非人类发声中涌现,且哺乳动物的听觉编码策略可能具有共享的进化基础。
- 局限:缺乏生物学验证数据(如蝙蝠听觉神经元的调谐特性)。聚类结果缺乏生物学标签进行验证。跨物种泛化性有限(对近缘种R. pearsonii效果较差)。
🏗️ 模型架构
论文未采用传统的深度神经网络,其“模型”是基于稀疏编码框架(图1)构建的。整体流程如下:
- 输入:预处理后的蝙蝠叫声时域信号
x(t)。 - 字典学习/表示:使用一个过完备字典
D = {ϕγ(t)}(包含32个“听觉核”原子),通过匹配追踪(MP)算法将输入信号近似表示为该字典中少量原子的线性组合:x(t) ≈ Σ a_k ϕγk(t)。每个原子由时间偏移、中心频率和尺度参数化。 - 核心组件 - 听觉核字典:这32个核是数据驱动学习得到的关键输出,其光谱特性(中心频率、带宽、偏度)被分析以回答研究问题。
- 输出/分析:对于每个叫声,输出其稀疏表示(一组稀疏的激活系数
a_k和对应的原子索引)。基于这些表示进行下游分析:- 核特性分析(RQ1):计算核的光谱属性。
- 重建效率分析(RQ2):与傅里叶/小波基进行比特率-保真度(SNR)比较。
- 特化性分析(RQ3):对叫声的稀疏表示向量(32维激活计数)进行K-means聚类,分析核的激活模式是否对应不同的叫声变体。
- 稀疏性分析(RQ4):计算激活向量的稀疏度度量(Gini指数等)。
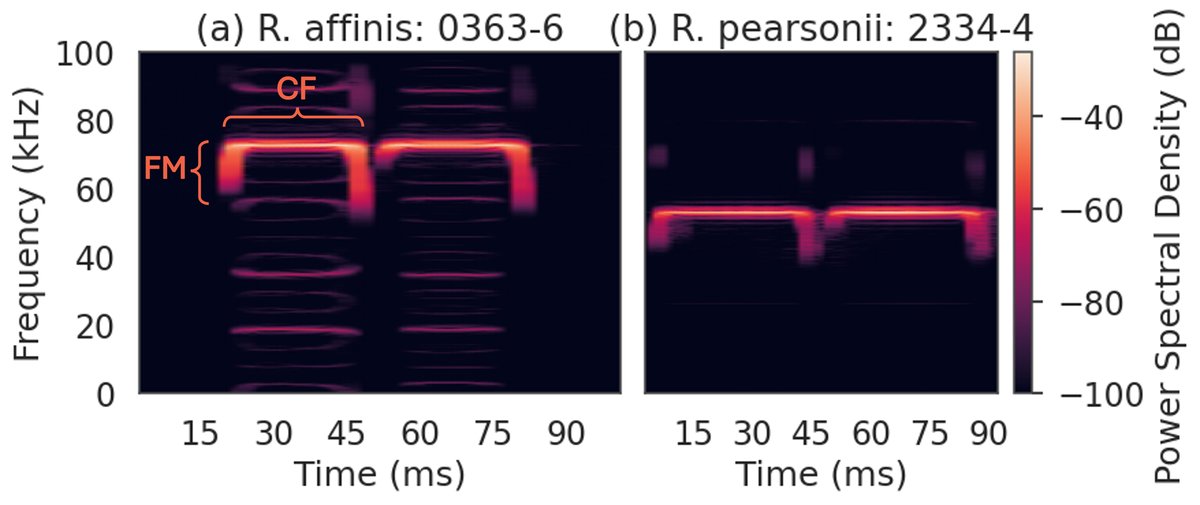 图1展示了稀疏编码分解过程:(a)原始波形,(b)由200个来自13个核的激活重建的波形,(c)残差能量。顶部显示了核激活在时间和质心频率上的分布,点的大小表示振幅,颜色表示核的ID。这直观展示了如何用少量特化核捕获复杂声学结构。
图1展示了稀疏编码分解过程:(a)原始波形,(b)由200个来自13个核的激活重建的波形,(c)残差能量。顶部显示了核激活在时间和质心频率上的分布,点的大小表示振幅,颜色表示核的ID。这直观展示了如何用少量特化核捕获复杂声学结构。
💡 核心创新点
- 跨物种验证高效编码假说:首次将从人类语音研究中成熟的稀疏编码方法应用于蝙蝠回声定位信号,检验了高效编码原则在非人类、高度特化的声学系统中的适用性。
- 数据驱动、机制无关的“听觉核”发现:不依赖预定义的生物启发滤波器(如Gammatone),而是直接从数据中学习能高效表示蝙蝠叫声的基函数(核)。这种方法能揭示叫声结构本身固有的、可能与感知系统协同进化的声学特征。
- 揭示功能特化的表示:通过聚类分析发现,学习到的核的激活模式能够编码不同的叫声变体,表明这些计算核可能对应着蝙蝠听觉系统中对特定声学特征敏感的功能单元。
- 验证稀疏编码在特定生物信号上的优势:实验量化证明,对于R. affinis的回声定位信号,基于学习核的稀疏编码在重建保真度(SNR)上优于传统的傅里叶和小波变换。
🔬 细节详述
- 训练数据:使用公开的ChiroVox数据集,选择大菊头蝠(Rhinolophus affinis)的录音,因其数量多、叫声(CF-FM结构)高度标准化。数据重采样至200 kHz,通过5阶巴特沃斯高通滤波器(截止频率0.7 × f_peak)去噪,并基于能量检测算法提取叫声段。
- 损失函数:未显式定义损失函数。字典学习目标是最小化重建误差,MP算法通过贪婪迭代选择能使残差能量下降最大的原子。
- 训练策略:
- 字典学习:使用MP和梯度上升进行字典学习(具体算法未详述,但引用了[38])。
- 稀疏编码(测试时):使用MP算法将测试叫声表示为字典中原子的稀疏线性组合。
- 关键超参数:
- 字典大小:32个核。
- 核初始化长度:400个样本(针对蝙蝠声音特性调整)。
- MP激活率:22,500 核/秒(用于高精度重建)。
- 聚类分析参数:重建深度n=200个激活,聚类数k=27。
- 训练硬件:未说明。
- 推理细节:MP算法是迭代贪婪的,当达到固定数量原子K或残差能量低于阈值时停止。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
- 主要结果对比:
- 重建效率(RQ2):在测试集上,对于R. affinis叫声,稀疏编码(MP)的比特率-SNR曲线显著优于傅里叶和Daubechies小波变换。在高比特率下,MP可达到约31 dB SNR(图4)。对于近缘种R. pearsonii,使用R. affinis训练的字典时,傅里叶变换的性能优于MP。
- 稀疏性(RQ4):所有稀疏度度量均显示极高的稀疏性。
表2:不同重建深度下的稀疏度指标(均值±标准差)
| 指标 | 200 个核激活 | 2400 个核激活 |
|---|---|---|
| Gini (R. affinis) | 0.984 ± 0.008 | 0.997 ± 0.001 |
| Gini (R. pearsonii) | 0.994 ± 0.004 | 0.998 ± 0.001 |
| Hoyer (R. affinis) | 0.959 ± 0.026 | 0.979 ± 0.011 |
| Hoyer (R. pearsonii) | 0.994 ± 0.014 | 0.990 ± 0.006 |
| PQ (R. affinis) | (3.59 ± 0.28) × 10⁻³ | (2.5 ± 1.5) × 10⁻⁴ |
| PQ (R. pearsonii) | (8.0 ± 1.6) × 10⁻⁴ | (1.2 ± 0.8) × 10⁻⁴ |
| R. pearsonii显示出比R. affinis更高的稀疏度,可能因为其叫声频率范围与学习核的中心频率匹配度较低。 |
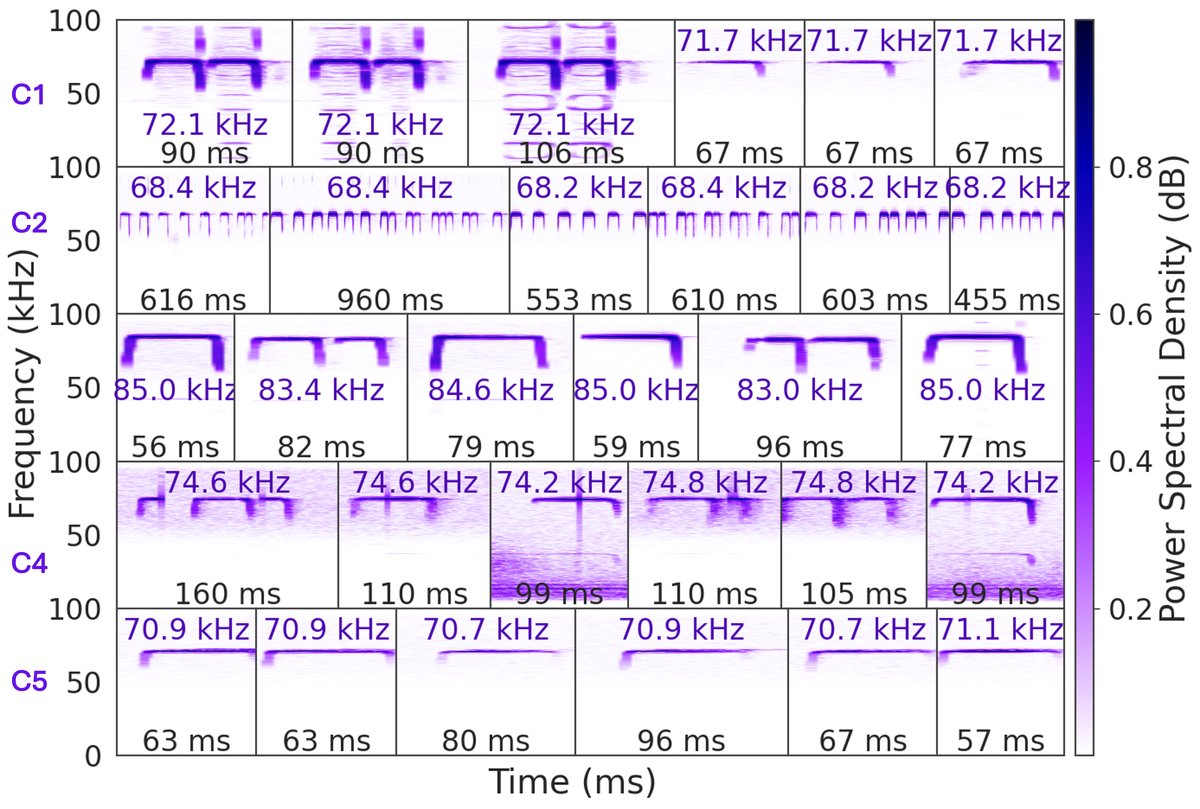 图4:不同编码方法的比特率-保真度曲线。实线为R. affinis,虚线为R. pearsonii。阴影区域为95%置信区间。结果显示MP在R. affinis上表现最佳,但跨物种泛化能力有限。
图4:不同编码方法的比特率-保真度曲线。实线为R. affinis,虚线为R. pearsonii。阴影区域为95%置信区间。结果显示MP在R. affinis上表现最佳,但跨物种泛化能力有限。
- 核特性(RQ1):学习到的核中心频率范围10-90 kHz,带宽1-40 kHz,偏度接近0(对称)。明显分为窄带高频核(>70kHz,对应CF成分)和宽带低频核(>30kHz,对应FM成分)两类(表1, 图3)。窄带核在早期高能量激活中占主导,宽带核在后期激活中增多,符合叫声CF-FM结构。
 图3:32个核在R. affinis叫声中的激活计数分布(前70个激活)。最频繁的核是窄带高频信号,很可能是CF特化的,因其高能量在早期被捕获。
图3:32个核在R. affinis叫声中的激活计数分布(前70个激活)。最频繁的核是窄带高频信号,很可能是CF特化的,因其高能量在早期被捕获。
- 特化性(RQ3):聚类分析(k=27,图5, 图6)产生了可分离的簇,每个簇包含声学轮廓相似的叫声。例如,C1簇包含突出次级谐波的叫声,C5簇包含非常窄的CF叫声。这表明核激活模式可以捕获叫声的功能性变化。
图6: Kernel-based clustering captures call diversity] 图6:五个代表性聚类(C1-C5),每个包含6个代表性叫声。每个叫声的持续时间按比例缩放。相似的谐波和频谱模式表明核的协同激活模式可能编码了叫声结构变化,可能传达更广泛的行为背景信息。
⚖️ 评分理由
- 学术质量:5.5/7。研究设计严谨,针对明确科学问题(四个RQ)进行系统性分析。技术实现(稀疏编码、聚类、统计度量)正确。实验证据(定量指标、可视化)支持主要结论。主要局限在于与更多相关基线的对比不足,以及实验结论(特化的核)与生物学真实处理机制之间存在论证跳跃。
- 选题价值:1.5/2。选题新颖且有深度,跨越了工程与生物学,为动物声音感知和信号处理研究提供了有价值的计算视角。虽然直接应用前景不如主流语音任务明确,但对基础科学和仿生工程有启发。
- 开源与复现加成:+0.5/1。论文提供了明确的代码链接、使用的数据集信息、算法引用和详细的方法参数,可复现性好。