📄 Temporal-Spatial Decouple Before Act: Disentangled Representation Learning for Multimodal Sentiment Analysis
#多模态模型 #情感分析 #解耦学习 #音视频
✅ 7.5/10 | 前25% | #情感分析 | #解耦学习 | #多模态模型 #音视频
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Chunlei Meng (Fudan University, 即复旦大学)
- 通讯作者:Chun Ouyang (Fudan University, 即复旦大学)
- 作者列表:Chunlei Meng(复旦大学)†、Ziyang Zhou(汕头大学)、Lucas He(伦敦大学学院)、Xiaojing Du(南澳大学)、Chun Ouyang(复旦大学)†、Zhongxue Gan(复旦大学) (†表示通讯作者)
💡 毒舌点评
亮点:论文的动机非常清晰,直指当前多模态融合中“时空信息混合建模”导致静态特征主导的痛点,并为此设计了一套从解耦、对齐到重耦合的完整技术流水线,逻辑自洽且实验验证充分。 短板:论文的可视化分析(图2)虽然展示了特征分布的改善,但缺乏对“解耦出的时空特征究竟学到了什么”更具体的语义或模态内解释,使得这个“黑箱”模型的可解释性打了折扣;此外,论文未开源代码,限制了其即时影响力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用公开基准CMU-MOSI和CMU-MOSEI。
- Demo:未提及。
- 复现材料:提供了一些训练细节(优化器Adam、权重衰减、批大小16、最多50 epoch、早停、五折交叉验证),但缺失关键信息(如各模态特征提取方式、模型具体维度、学习率、损失权重α/β/γ的具体值)。论文中未提及完整的复现计划或资源链接。
- 论文中引用的开源项目:未提及。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 要解决的问题:现有主流多模态情感分析方法在进行跨模态交互前,将时间动态信息(如语音韵律突变、视频微表情)和空间结构信息(如说话人身份、背景、句子整体极性)混合编码为单一嵌入,导致学习过程偏向于更稳定、方差大的静态成分,从而忽略了关键的时间轨迹信息,造成“时空信息不对称”,性能受限。
- 方法核心:提出TSDA(Temporal-Spatial Decouple before Act)框架。其核心是在任何跨模态交互之前,先为每个模态(语言、视觉、声学)学习解耦的“时间动态”和“空间结构”表征。具体包括:(1)独立的时间编码器和空间编码器;(2)因子一致性跨模态对齐(FCCA),使用块对角掩码注意力确保时间特征只与其它模态的时间特征对齐,空间特征同理;(3)门控重耦合(GR)模块,根据可靠度自适应融合对齐后的时间与空间表征。
- 与已有方法相比新在哪里:不同于大多数方法在融合前进行模态内或跨模态的不变/特定因子解耦(如MISA),TSDA更进一步,将时间与空间这两个正交的维度显式地解耦并独立进行跨模态对齐。这避免了传统混合编码中时空信息的相互干扰,是一种更细粒度的解耦学习范式。
- 主要实验结果:TSDA在CMU-MOSI和CMU-MOSEI两个标准基准测试的所有指标上均取得了最优(SOTA)结果。具体对比如下表所示,尤其在平均绝对误差(MAE)和7类准确率(ACC7)上优势明显。消融实验证明了解耦、FCCA和门控重耦合等各组件的必要性。
表1:在CMU-MOSI和CMU-MOSEI数据集上与现有方法的性能对比(对齐/未对齐设置)
| 方法 | CMU-MOSI MAE (↓) | CMU-MOSI ACC7 (%) | CMU-MOSI ACC2 (%) | CMU-MOSI F1 (%) | CMU-MOSEI MAE (↓) | CMU-MOSEI ACC7 (%) | CMU-MOSEI ACC2 (%) | CMU-MOSEI F1 (%) |
|---|---|---|---|---|---|---|---|---|
| LMF [20] | 0.931 / 0.963 | 36.9 / 31.1 | 78.7 / 79.1 | 78.7 / 79.1 | 0.564 / 0.565 | 52.3 / 51.9 | 84.7 / 83.8 | 84.5 / 83.9 |
| MuLT [21] | 0.936 / 0.933 | 35.1 / 33.2 | 80.0 / 80.3 | 80.1 / 80.3 | 0.572 / 0.556 | 52.3 / 53.2 | 82.7 / 84.0 | 82.8 / 84.0 |
| TFN [22] | 0.953 / 0.995 | 31.9 / 35.3 | 78.8 / 76.5 | 78.9 / 76.6 | 0.574 / 0.573 | 50.9 / 50.2 | 80.4 / 84.2 | 80.7 / 84.0 |
| MISA [12] | 0.754 / 0.742 | 41.8 / 43.6 | 84.2 / 83.8 | 84.2 / 83.9 | 0.543 / 0.557 | 52.3 / 51.0 | 85.3 / 84.8 | 85.1 / 84.8 |
| FDMER [13] | - / 0.725 | - / 44.2 | - / 84.6 | - / 84.7 | - / 0.536 | - / 53.8 | - / 84.1 | - / 84.0 |
| ConFEDE [11] | - / 0.742 | - / 46.3 | - / 84.2 | - / 84.2 | - / 0.523 | - / 54.9 | - / 81.8 | - / 82.3 |
| Self-MM [5] | 0.738 / 0.724 | 45.3 / 45.7 | 84.9 / 83.4 | 84.9 / 83.6 | 0.540 / 0.535 | 53.2 / 52.9 | 84.5 / 85.3 | 84.3 / 84.8 |
| MMIN [4] | - / 0.741 | - / - | 83.5 / 85.5 | 83.5 / 85.51 | - / 0.542 | - / - | 83.8 / 85.9 | 83.9 / 85.76 |
| DMD [9] | 0.721 / 0.721 | 46.2 / 46.7 | 83.2 / 84.0 | 83.2 / 84.0 | 0.546 / 0.536 | 52.4 / 53.1 | 84.8 / 84.7 | 84.7 / 84.7 |
| DEVA [6] | - / 0.730 | - / 46.3 | - / 84.4 | - / 84.5 | - / 0.541 | - / 52.3 | - / 83.3 | - / 82.9 |
| DLF [15] | - / 0.731 | - / 47.1 | - / 85.1 | - / 85.1 | - / 0.536 | - / 53.9 | - / 84.4 | - / 85.3 |
| EMOE [10] | 0.710 / 0.697 | 47.7 / 47.8 | 85.4 / 85.4 | 85.4 / 85.3 | 0.536 / 0.533 | 54.1 / 53.9 | 85.3 / 85.5 | 85.3 / 85.5 |
| TSDA (Ours) | 0.695 / 0.680 | 48.6 / 48.5 | 86.3 / 86.5 | 86.2 / 86.5 | 0.529 / 0.527 | 54.9 / 54.9 | 86.3 / 86.4 | 86.2 / 86.5 |
表2:TSDA在CMU-MOSI和CMU-MOSEI数据集上的消融实验结果
| 模型 | CMU-MOSI MAE (↓) | CMU-MOSI ACC7 (%) | CMU-MOSEI MAE (↓) | CMU-MOSEI ACC7 (%) |
|---|---|---|---|---|
| TSDA (Ours) | 0.680 | 48.5 | 0.527 | 54.9 |
| w/o Temporal | 0.726 | 46.0 | 0.552 | 52.5 |
| w/o Spatial | 0.716 | 46.8 | 0.546 | 53.0 |
| w/o ST Disen. | 0.731 | 45.7 | 0.555 | 52.2 |
| w/o FCCA | 0.728 | 45.5 | 0.552 | 51.9 |
| w/o Lpur | 0.722 | 46.5 | 0.548 | 52.9 |
| w/o Ldecorr | 0.713 | 46.9 | 0.541 | 53.3 |
| w/o Lorth | 0.714 | 47.1 | 0.542 | 53.4 |
- 实际意义:TSDA为多模态情感分析乃至其他音视频融合任务提供了一种新的、更精细的表征学习思路,强调在交互前处理好不同信号源内部的时空异质性,这对于提升模型在复杂真实场景下的鲁棒性和可解释性有积极意义。
- 主要局限性:论文未在更广泛的、更具挑战性的大规模“野外”数据集上进行验证;其计算开销(双编码器+两路注意力+门控)未与基线方法进行详细对比;对于解耦出的“时间”和“空间”表征的可解释性分析仅停留在t-SNE可视化,缺乏更深入的定量或定性分析。
🏗️ 模型架构
TSDA的整体架构(如图1所示)遵循“解耦-对齐-重耦合”的流程,处理语言(L)、视觉(V)、声学(A)三个模态的输入。
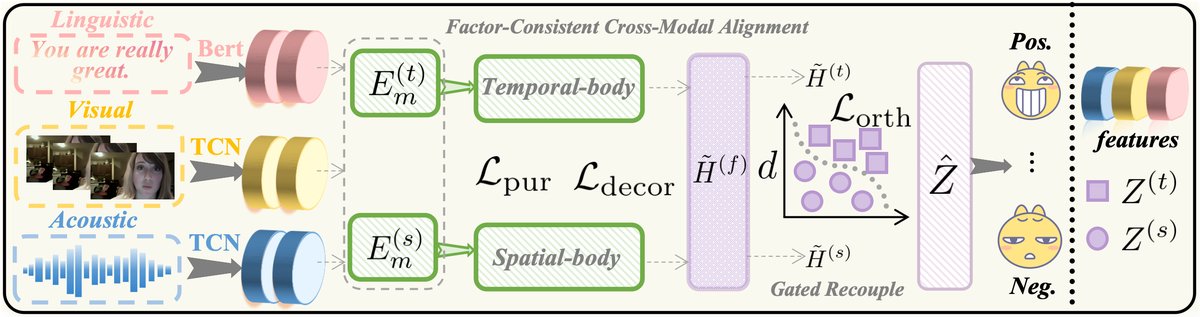 图1:TSDA架构示意图。对于每个模态,输入首先被分离到时间编码器和空间编码器中。随后,因子一致性跨模态对齐(FCCA)模块分别对时间特征和空间特征进行跨模态交互(使用块对角掩码确保因子内部交互)。最后,门控重耦合(GR)模块根据可靠度信号自适应地融合对齐后的时间与空间表征,用于最终的情感预测任务。
图1:TSDA架构示意图。对于每个模态,输入首先被分离到时间编码器和空间编码器中。随后,因子一致性跨模态对齐(FCCA)模块分别对时间特征和空间特征进行跨模态交互(使用块对角掩码确保因子内部交互)。最后,门控重耦合(GR)模块根据可靠度信号自适应地融合对齐后的时间与空间表征,用于最终的情感预测任务。
完整输入输出流程:
- 输入:对于每个模态m ∈ {L, V, A},输入为一个token序列 Xm = {xm,1, …, xm,Tm},其中Tm是序列长度。这些token可以是文本的词/子词、视频的图像帧/图像块、音频的声学特征帧。
- 时空解耦:每个模态的输入Xm分别送入两个编码器:
- 时间编码器 E^(t)_m:生成一个时间感知的序列表示 F^(t)_m ∈ R^(T_m × d_t),保留了序列的时序依赖关系。
- 空间编码器 E^(s)_m:生成一个时间无关的结构化表示 F^(s)_m ∈ R^(S_m × d_s),其中S_m是空间token数量(如视频图像块数、音频段数),该表示聚合了局部证据,形成稳定的结构化信息。
- 因子一致性跨模态对齐 (FCCA):
- 将所有模态的时间表征拼接为 H^(t) = concat({F^(t)_m}),空间表征拼接为 H^(s) = concat({F^(s)_m})。
- 对H^(t)和H^(s)分别进行线性投影得到查询(Q)、键(K)、值(V)。
- 关键设计:使用一个二进制掩码M^(f)(f为t或s),在计算注意力softmax(QK^T / sqrt(d) + log(M))V时,该掩码确保只有同一因子内的token可以互相注意(即时间-时间,空间-空间),形成块对角注意力,阻断跨因子(时间-空间)的信息交换。
- 对对齐后的表征进行池化,得到因子摘要 Z^(t) 和 Z^(s)。
- 正则化:
- 因子纯度监督 (L_pur):一个判别器D尝试从对齐后的token中分辨其来自时间流还是空间流,此损失迫使两个因子的表征分布更纯净、可分。
- 去相关性 (L_decorr):通过惩罚Z^(t)和Z^(s)之间的余弦相似性(二阶)和希尔伯特-施密特独立性准则HSIC(非线性依赖)来降低两个摘要之间的冗余。
- 门控重耦合 (GR):
- 计算可靠度信号:差异度 d = 1 - cos(Z^(t), Z^(s)),因子置信度 ct (时间流平均纯度) 和 cs (空间流平均纯度)。
- 将Z^(t), Z^(s), d, ct, cs 拼接为门控输入ϕ,通过一个线性层+sigmoid得到门控值g ∈ (0,1)。 计算最终融合表示:Ẑ = g U_t Z^(t) + (1-g) U_s * Z^(s),其中U_t和U_s是投影矩阵。
- 施加正交正则化 L_orth = ||U_t^T U_s||_F^2,以减少投影后的共线性。
- 输出与任务损失:融合表示Ẑ被用于情感分类(交叉熵)或回归(均方误差),总损失L = L_task + α L_pur + β L_decorr + γ L_orth。
组件间数据流与交互:数据流是清晰的三阶段串行结构,但FCCA阶段内部存在多模态、多因子的并行交互。门控重耦合模块利用了FCCA阶段产生的可靠度信号(ct, cs, d)来做出自适应决策。
关键设计选择及其动机:
- 显式时空解耦:动机是解决“时空信息不对称”问题,防止静态特征主导优化。
- 块对角注意力:动机是强制实现“因子一致性”,这是解决该问题的核心技术保障。
- 门控重耦合:动机是允许模型根据每个样本的具体情况(哪个因子更可靠)来动态平衡时间与空间信息的贡献,提高适应性。
💡 核心创新点
- 时空显式解耦框架 (TSDA):提出在跨模态交互之前,先为每个模态学习解耦的时间动态和空间结构表征。之前局限:大多数方法将每个模态编码为单个混合嵌入,时空信息纠缠,导致学习偏差。如何起作用:通过独立的时间编码器和空间编码器实现解耦,为后续独立的因子级对齐奠定基础。收益:从根源上分离了不同性质的信息,缓解了静态主导问题。
- 因子一致性跨模态对齐 (FCCA):设计了一种使用块对角掩码注意力的跨模态对齐机制。之前局限:传统跨模态注意力不加区分地混合所有特征,导致时间信息可能被空间信息“污染”。如何起作用:掩码结构化地约束了注意力流,确保时间特征只与其他模态的时间特征对齐,空间特征同理。收益:从交互机制上保证了因子对齐的一致性,是TSDA方法的核心技术贡献。
- 门控重耦合与可靠性校准:提出一种利用因子纯度、差异度等内部信号来校准融合门控的重耦合模块,并引入干预思想进行监督。之前局限:简单的拼接、求和或固定权重融合无法适应不同样本中时间/空间信号可靠性的变化。如何起作用:门控网络综合了特征本身(Z^(t), Z^(s))和反映其质量的元信号(d, ct, cs)来决定融合比例。收益:实现了样本自适应的融合策略,进一步提升了模型在复杂情况下的鲁棒性。
- 因子纯度与去相关性双重正则化:提出了在token级(L_pur)和摘要级(L_decorr)联合监督,以最小化跨因子信息泄漏。之前局限:解耦后可能仍存在残余的信息混合。如何起作用:纯度监督迫使每个因子的表征可被明确分类;去相关性惩罚则减少两个因子摘要之间的统计依赖。收益:在训练中强化了��耦的目标,提升了学到的时空表征的纯度和互补性。
🔬 细节详述
- 训练数据:
- 数据集:CMU-MOSI(2,199个片段,划分:1,284/229/686)和CMU-MOSEI(23,453个片段,划分:16,326/1,871/4,659)。
- 预处理:论文未详细说明数据预处理步骤(如视觉帧采样率、音频特征提取方式、文本分词等)。
- 数据增强:论文中未提及使用数据增强。
- 损失函数:
- L_task:分类任务使用交叉熵损失,回归任务使用均方误差损失。
- L_pur(公式4):因子纯度监督。训练一个判别器D,使其能以高概率区分来自时间流(˜h^(t))和空间流(˜h^(s))的对齐token。损失为负对数似然。 L_decorr(公式5):去相关性损失。由两部分组成:λ_c cos²(Z^(t), Z^(s))(惩罚线性相关)和 λ_h * HSIC(Z^(t), Z^(s))(惩罚非线性依赖,HSIC为希尔伯特-施密特独立性准则)。
- L_orth:正交损失,即投影矩阵U_t和U_s内积的Frobenius范数平方 ||U_t^T U_s||_F²,用于减少投影后的共线性。
- 总损失:L = L_task + α L_pur + β L_decorr + γ L_orth。
- 训练策略:
- 优化器:Adam,权重衰减 1×10⁻⁵。
- 批大小:16。
- 训练轮数:最多50个epoch,采用早停(early stopping)策略。
- 评估方式:五折交叉验证。
- 学习率:论文未明确给出初始学习率和调度策略。
- 关键超参数:
- 模型大小、层数、隐藏维度(d_t, d_s):论文中未提供具体数值。
- 损失权重α, β, γ:论文未给出默认值,但在敏感性分析(图4)中展示了模型对它们的鲁棒性。
- 训练硬件:
- GPU型号:NVIDIA A100。
- 数量:未说明。
- 训练时长:未说明。
- 推理细节:
- 解码策略:不适用于情感分析分类/回归任务。
- 温度、beam size:不适用。
- 正则化或稳定训练技巧:
- L_pur, L_decorr, L_orth 本身作为正则化项。
- 权重衰减 (1×10⁻⁵)。
- 早停。
- 五折交叉验证(也可视为一种确保稳定评估的方法)。
📊 实验结果
主要benchmark结果已在“核心摘要”部分用表1完整列出。TSDA在CMU-MOSI和CMU-MOSEI的所有指标上均优于表中列出的所有基线方法(包括解耦类、融合类等)。在未对齐设置下优势更为明显,例如在CMU-MOSI上将MAE从EMOE的0.697降至0.680,ACC7提升0.7个百分点;在CMU-MOSEI上将MAE从EMOE的0.533降至0.527,ACC7提升1.0个百分点。
关键消融实验及数字变化已在“核心摘要”部分用表2完整列出。关键结论:
- 移除时间流(w/o Temporal)比移除空间流(w/o Spatial)导致性能下降更显著,证实时间动态对情感判断更重要。
- 完全移除时空解耦(w/o ST Disen.)性能下降明显,验证了显式解耦的必要性。
- 移除FCCA模块(w/o FCCA)性能显著下降,表明因子一致性对齐是关键。
- 移除任何一项正则化(L_pur, L_decorr, Lorth)都会导致性能下降,其中L_pur影响最大,说明因子纯度监督至关重要。
可视化分析结果:
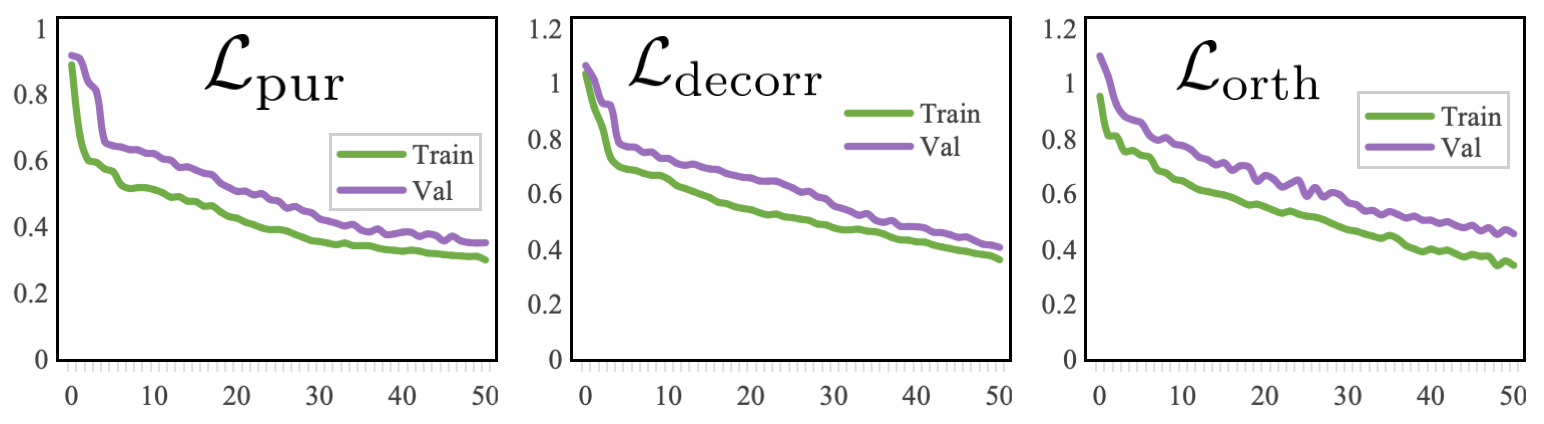 图2:不同模型设置在CMU-MOSI测试集上的t-SNE特征可视化(红色表示更强的正向情感)。从(a)无时空解耦,到(b)解耦但无FCCA,再到(c)解耦+FCCA但无GR,最后到(d)完整的TSDA,可以看到特征分布变得越来越紧凑、极性梯度越来越清晰有序,证明TSDA各组件逐步改善了表征质量。
图2:不同模型设置在CMU-MOSI测试集上的t-SNE特征可视化(红色表示更强的正向情感)。从(a)无时空解耦,到(b)解耦但无FCCA,再到(c)解耦+FCCA但无GR,最后到(d)完整的TSDA,可以看到特征分布变得越来越紧凑、极性梯度越来越清晰有序,证明TSDA各组件逐步改善了表征质量。
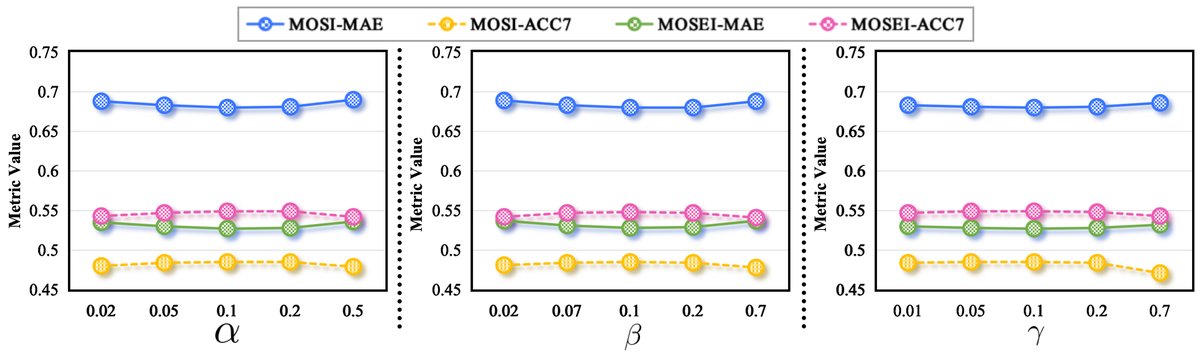 图3:在CMU-MOSI训练过程中,正则化损失L_pur, L_decorr, L_orth的变化曲线。三者均呈单调下降并收敛,表明因子分离过程稳定有效,模型持续学到了更纯净、更独立的时空表征。
图3:在CMU-MOSI训练过程中,正则化损失L_pur, L_decorr, L_orth的变化曲线。三者均呈单调下降并收敛,表明因子分离过程稳定有效,模型持续学到了更纯净、更独立的时空表征。
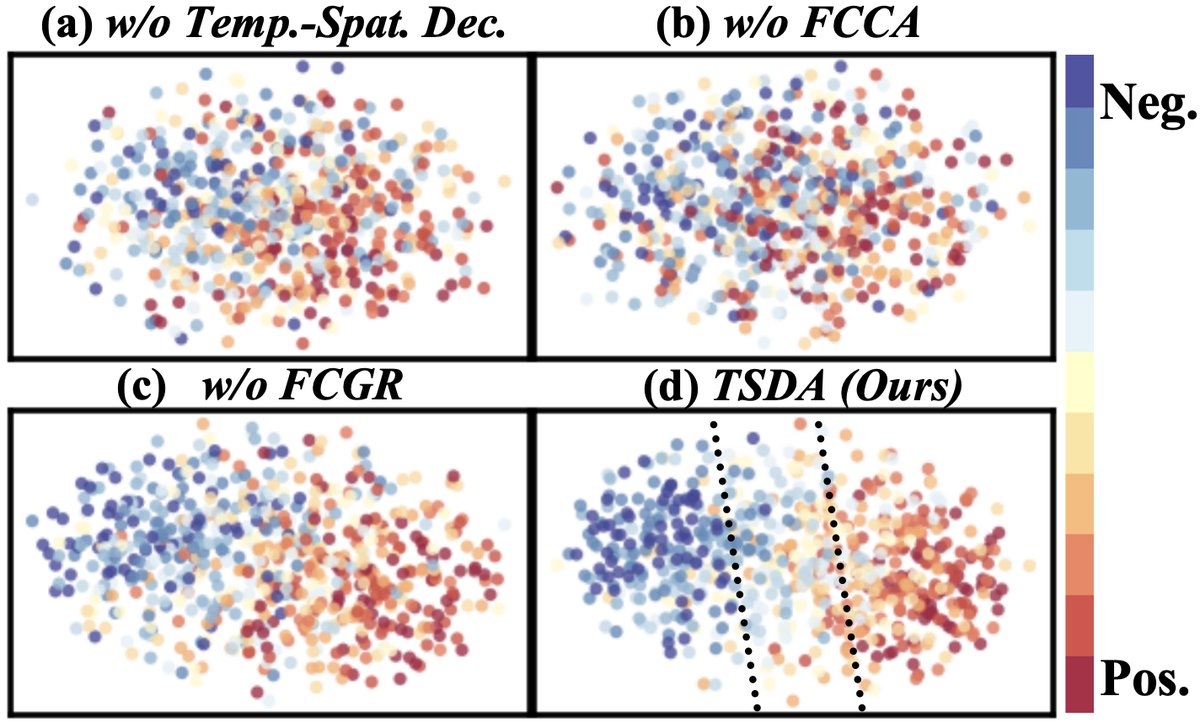 图4:在CMU-MOSI和CMU-MOSEI数据集上,固定其他两个超参数,分别扫描α、β、γ在不同取值时的模型性能(MAE和ACC7)。曲线波动很小,表明TSDA的性能对这些超参数的具体选择不敏感,验证了架构设计的鲁棒性。
图4:在CMU-MOSI和CMU-MOSEI数据集上,固定其他两个超参数,分别扫描α、β、γ在不同取值时的模型性能(MAE和ACC7)。曲线波动很小,表明TSDA的性能对这些超参数的具体选择不敏感,验证了架构设计的鲁棒性。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:提出了明确的“时空解耦先于交互”的新范式,并为其设计了针对性的技术组件(FCCA, GR)。创新点清晰、逻辑自洽,属于该领域内有价值的改进型工作。
- 技术正确性:方法设计合理,块对角注意力、正交正则化等技术应用得当,没有明显错误。
- 实验充分性:在两个主流基准数据集上进行了全面的对比实验和深入的消融研究(包括模态重要性、表示类型、融合机制、正则化项),证据充分。
- 证据可信度:实验设置规范(五折交叉验证,报告多种指标),结果对比清晰,消融实验有力地支持了各模块的必要性。t-SNE可视化和训练曲线提供了辅助证据。
- 选题价值:1.5/2
- 前沿性:多模态情感分析是持续研究的热点,本文聚焦于其核心挑战之一(时空异质性),具有理论前沿性。
- 潜在影响:提出的解耦-对齐-重耦合框架可能对其他需要精细处理时空信息的音视频任务(如动作识别、情感识别)有借鉴意义。
- 实际应用空间:情感分析在人机交互、社交媒体监控、心理健康评估等领域有直接应用。
- 读者相关性:方法涉及音频的声学动态与结构分析,与语音和音频处理领域高度相关。
- 开源与复现加成:0.0/1
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 复现材料:给出了部分训练设置(优化器、批大小),但缺少学习率、关键超参数(α,β,γ)的默认值、特征提取细节等,复现信息不充分。