📄 Temporal Graph Modeling for Speech Emotion Recognition Using LSTM-Aggregated Multigraph Networks
#语音情感识别 #自监督学习 #图神经网络 #多图网络
✅ 7.5/10 | 前25% | #语音情感识别 | #图神经网络 | #自监督学习 #多图网络
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Patitapaban Palo(印度理工学院克勒格布尔分校电气工程系)
- 通讯作者:未说明
- 作者列表:Patitapaban Palo(印度理工学院克勒格布尔分校电气工程系)、Pooja Kumawat(印度理工学院克勒格布尔分校电气工程系)、Aurobinda Routray(印度理工学院克勒格布尔分校电气工程系)
💡 毒舌点评
亮点:论文巧妙地将“语音帧作为图节点”的思想与能够建模多关系的多图卷积网络(MGCN)结合,并创新性地用LSTM替代求和聚合来捕捉邻域内的时序依赖,这个设计直觉清晰且实验效果显著。短板:论文对“多图”(Multigraph)在语音任务中到底建模了哪几种“关系”的论述略显模糊(主要依赖初始图构建),且未提供代码和核心损失函数,对于一个声称“复现性强”的方法论工作来说有些扣分。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的IEMOCAP和BAUM-1数据库,但论文未说明如何获取其处理后的版本。
- Demo:未提及。
- 复现材料:论文给出了部分超参数(学习率、dropout、网络层大小等)和数据集划分方式,但缺失损失函数、优化器、具体网络配置等关键复现细节。
- 引用的开源项目:论文中引用了wav2vec 2.0模型、GCN、Graph U-Net等开源工作,但未说明是否依赖其官方代码。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 要解决的问题:语音情感识别(SER)需要有效捕捉语音信号中复杂、动态的时序依赖关系,传统RNN/CNN方法在建模长程依赖和复杂关系上存在局限。
- 方法核心:提出一种基于图神经网络(GNN)的SER框架。首先用预训练的wav2vec 2.0模型提取帧级特征作为图节点特征,并根据帧间相似性构建时序图。然后,采用一种改进的多图卷积网络(MGCN)进行分类,其关键创新在于使用LSTM进行邻域信息聚合,以更好地建模时序结构。
- 与已有方法相比新在哪里:a) 将自监督学习(SSL)特征以及时序图表示引入基于GNN的SER;b) 将最初用于分子建模的MGCN迁移到语音领域;c) 用LSTM聚合替代了GNN中传统的求和/均值聚合,以显式建模邻域节点(帧)的序列关系。
- 主要实验结果:在IEMOCAP数据集上,所提MGCN-LSTM方法达到78.22%的UWA,优于GCN、Graph U-Net以及使用求和聚合的MGCN(75.10%)。在BAUM-1数据集上,该方法达到69.89%的UWA,同样取得最佳性能。消融实验证明,基于时序相似度的图构建和LSTM聚合带来了显著性能提升。
方法 IEMOCAP UWA(%) BAUM-1 UWA(%) GCN 72.77 52.41 GUNET 36.98 42.38 MGCN (Sum) 75.10 65.84 MGCN (LSTM) 78.22 69.89 - 实际意义:为语音情感识别提供了一种新的、可解释性更强的图建模框架,展示了结合SSL和GNN在情感计算任务中的潜力。
- 主要局限性:a) “多图”中的多关系主要由初始图定义,对“多关系”学习的深度和必要性探讨不足;b) 实验分析较浅,缺乏错误分析、不同情绪类别性能、与更先进SSL模型(如HuBERT)的对比;c) 部分技术细节(如损失函数)未公开,影响复现性。
🏗️ 模型架构
整体架构是一个端到端的系统,包含三个主要阶段:特征提取、图构建与MGCN分类。
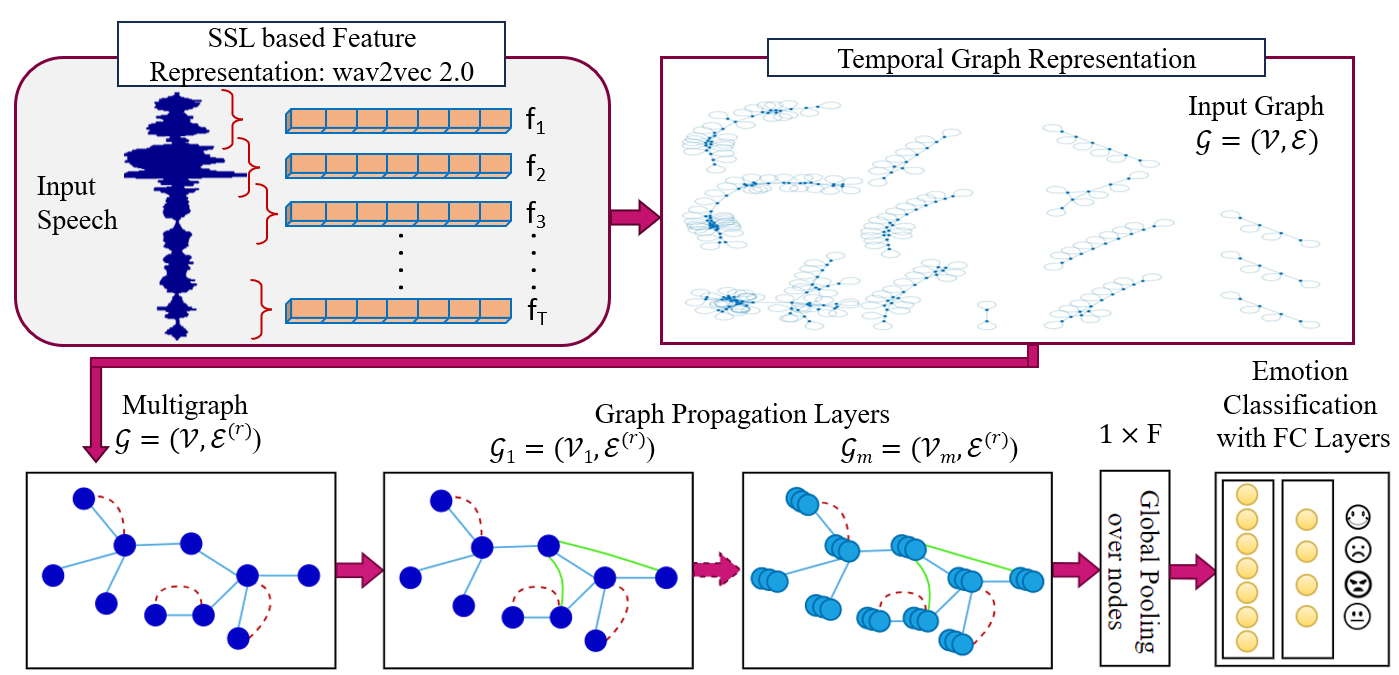
- 特征提取:输入原始语音波形,使用预训练的
wav2vec 2.0 (wav2vec2-large-960h)模型提取特征。该模型输出每个语音帧的1024维上下文表示,作为后续图节点的特征向量f_j。 - 时序图构建:以每个语音样本为一个独立的图。每个帧对应图中的一个节点。
- 节点特征:即该帧的wav2vec 2.0特征向量
f_j。 - 边权计算:计算任意两帧
j和k之间的欧氏距离d_j,k(公式1),然后通过高斯核函数转换为相似度权重 (公式2)。带宽参数σ通过所有帧间距离的中位数启发式确定 (公式3)。 - 图稀疏化:对相似度进行阈值筛选(论文中主要使用阈值0.5),并保证每个节点至少连接一个邻居(包含自身)。
- 节点特征:即该帧的wav2vec 2.0特征向量
- 多图卷积网络 (MGCN) 分类:将构建好的图输入修改后的MGCN模型。
- 谱图卷积:采用基于切比雪夫多项式逼近的谱图卷积操作 (公式4, 5)。
- 多关系融合:通过可学习的变换和乘性融合来处理“多图”中的多种关系 (公式6)。论文中,“多关系”主要来源于初始图构建(如不同的连接策略或权重计算方式),并引入了一个可学习的边预测模块 (公式7) 来进一步学习节点间的新关系。
- LSTM邻域聚合 (关键创新):在信息传递阶段,对于每个节点
v_i,将其所有邻居节点v_j的特征X_j按照它们的时间顺序(即帧索引)排序后,输入一个LSTM网络。LSTM的输出隐藏状态h_i作为该节点聚合了时序邻域信息后的新表示,替代了传统的求和/均值聚合 (公式8)。 - 图级分类:经过多层MGCN处理后,使用全局最大池化将节点表示汇总为整个图的表示,最后通过全连接层输出分类结果(情感类别)。
💡 核心创新点
- 将SSL特征与时序图表示结合用于SER:首次将wav2vec 2.0帧级特征直接作为图节点特征,并基于帧间相似度构建时序图,为情感识别提供了可解释的图域表示。
- 将MGCN迁移至语音领域:将最初用于发现分子多重关系的多图卷积网络(MGCN)应用于语音情感识别,利用其建模节点间多种关系的能力。
- LSTM聚合的引入:这是最核心的创新。在GNN的邻域聚合步骤中,用LSTM替代传统的求和/均值操作,显式地建模了邻域节点(语音帧)之间的时序依赖,更符合语音信号的动态特性。
- 结合自监督学习与图神经网络的框架:构建了一个完整的“SSL特征提取 -> 图表示学习 -> GNN分类”的管线,展示了两个前沿领域的协同潜力。
🔬 细节详述
- 训练数据:
- IEMOCAP:5531条英语语音,4类情感(愤怒、快乐、中性、悲伤),采用5折交叉验证(留一session-out)。
- BAUM-1:土耳其语,包含699条语音(6类情感),按80:10:10划分训练/验证/测试集。
- 损失函数:论文中未明确说明使用的损失函数。根据分类任务性质,推测为交叉熵损失。
- 训练策略:
- 学习率:0.005,在第25和35步进行衰减。
- 优化器:未说明。
- Batch size:32。
- 训练轮数:40 epochs。
- 权重衰减:1e-4。
- 关键超参数:
- MGCN:3个卷积层,每层64个滤波器,滤波器尺度为4。
- 边预测MLP:32个隐藏单元。
- 全连接层:在最后一个MGCN层之后有4个隐藏单元。
- Dropout率:0.1。
- 图构建:使用欧氏距离+高斯核,阈值0.5(默认),σ由中位数启发式计算。
- 训练硬件:论文中未提及。
- 推理细节:未提及,推测为标准的前向传播。
- 正则化技巧:使用了dropout。
📊 实验结果
主要对比结果:论文在表3中给出了最终对比,MGCN-LSTM在IEMOCAP和BAUM-1上均取得最优。
方法 IEMOCAP BAUM-1 WA(%) UWA(%) GCN 72.34 72.77 GUNET 36.07 36.98 MGCN (Sum) 74.82 75.10 MGCN (LSTM) 77.54 78.22 与SOTA对比:在表4中,与IEMOCAP上其他基于音频的SOTA方法相比,所提方法(78.22% UWA)优于GCN(72.77%)、Sajjad等(72.25%)、Kumawat等(72.82%)和Chen等(74.30%)。
消融实验 - 图构建方式 (表1):比较了循环图、KNN图和时序图。时序图(阈值0.5)在IEMOCAP(75.10%)和BAUM-1(65.84%)上大幅领先其他图构建方法。阈值调整(0.75)会导致性能下降。
消融实验 - 聚合方式 (表2):在MGCN上比较了不同聚合方式。LSTM聚合(IEMOCAP: 78.22%, BAUM-1: 69.89%)显著优于求和(75.10%, 65.84%)、均值(69.27%, 41.16%)和池化(39.40%, 38.58%),验证了核心创新点。
关键结论:1) 基于帧相似度的时序图构建优于传统KNN/循环图;2) LSTM聚合是性能提升的关键,证实了其在建模邻域时序依赖上的有效性;3) MGCN-LSTM框架在两个不同语言、不同情感类别数量的数据集上均表现优异。
⚖️ 评分理由
- 学术质量 (6.5/7):创新性明确(LSTM聚合、MGCN迁移到语音),技术路径正确,实验设计包含了必要的对比和消融,结果可信且有提升。主要扣分点在于“多图”关系的具体化讨论不足,实验分析深度有限(如缺乏错误分析、不同情绪类别性能分析),且部分技术细节(损失函数)缺失。
- 选题价值 (1.5/2):语音情感识别是人机交互和情感计算的核心问题,具有明确的应用前景和研究价值。将图神经网络与自监督学习结合是当前的研究热点之一,具有前瞻性。应用领域相对特定(情感识别),因此未给满分。
- 开源与复现加成 (-0.5/1):论文未提供代码、模型或训练脚本。虽然描述了主要超参数和数据集划分,但损失函数、网络层具体结构(如LSTM层数、隐藏状态维度)、训练硬件等信息缺失,使得完全复现其工作存在难度。