📄 Temporal Distillation for Music Representation Learning
#音乐信息检索 #自监督学习 #知识蒸馏 #音频大模型
✅ 7.5/10 | 前25% | #音乐信息检索 | #知识蒸馏 | #自监督学习 #音频大模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:未说明
- 通讯作者:未说明
- 作者列表:Shiqi Wei(ByteDance)、Bilei Zhu(ByteDance)
💡 毒舌点评
亮点:论文精准地指出了传统蒸馏在序列任务上的“逐帧匹配”缺陷,并提出了“时间分布对齐”这一优雅且有效的替代方案,其在多个任务上超越了教师模型的表现,证明了“时间先验”传递的有效性。短板:实验结论中“Harmonia作为正则化器能稳定深层模型训练”的宣称,其实验支撑相对单薄,仅有“Deeper Arch.”一组结果,且未对比无正则化时的训练曲线或失败案例,说服力不足。同时,完全缺乏代码和模型开源,对于一个声称“加速和稳定大规模训练”的框架,其实用价值在社区中将大打折扣。
🔗 开源详情
论文中未提及代码仓库、模型权重、数据集的任何开源计划或链接。训练细节(如优化器、学习率、batch size)在论文中有说明,但完整的训练脚本、配置文件和预训练检查点均未提供。因此,论文中未提及开源计划。
📌 核心摘要
- 问题:训练音乐基础模型面临数据需求大、方法效率低、难以捕捉长程时间依赖的挑战。传统自监督学习和知识蒸馏方法(如逐帧匹配)缺乏有效的“时间归纳偏置”,导致模型无法学习音乐的动态演进过程,尤其在数据有限时易过拟合或训练不稳定。
- 核心方法:提出Harmonia,一种时间蒸馏框架。其核心是设计了“时间KL损失”(LTemporal-KL),该损失要求学生模型对齐教师模型输出表征序列在时间维度上的概率分布(即学习每个特征维度上的时间激活模式),而非传统逐帧匹配。这显式地注入了时间一致性的先验知识。
- 创新点:a) 明确识别并解决了音乐表示学习中时间偏置缺失的问题;b) 提出基于完整输出序列分布对齐的蒸馏目标(时间KL损失),以传递时间动态知识;c) 验证了该框架在知识迁移(模型压缩/自蒸馏)和训练正则化(长上下文编码器)两种场景下的双重优势。
- 主要实验结果:
- 在音乐信息检索(MIR)的9项任务上,Harmonia在多数指标上超越了教师模型(如MusicFM)和帧式蒸馏基线。例如,在330M模型上,GTZAN分类准确率比教师高4.1%,和弦识别准确率高2.6%。
- 消融实验表明,即使仅使用30%训练数据,Harmonia(81.8%)也优于同数据量下不蒸馏的基线(80.1%)。
- 模型压缩实验:用Harmonia蒸馏出的190M学生模型,在多项任务上性能接近或达到330M教师模型的水平。
- 可扩展性:成功应用于训练更深的650M模型,性能良好。
- 关键实验结果表格如下:
| 配置 | 数据 | 架构 | α/β | GTZAN ACC | MTT ROC | MTT AP | Beat F1 | Downbeat F1 | Chord ACC | Structure HR.5 | Key ACC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 参考 & 基线 | |||||||||||
| Teacher Model (fT) | In-house | 330M | – | 82.7 | 90.1 | 40.39 | 86.4 | 80.4 | 72.6 | 69.9 | 69.4 |
| Frame-wise Distill. | In-house | 330M | – | 58.6 | 78.4 | 32.4 | 34.5 | 66.4 | 67.4 | 64.2 | 54.2 |
| Data Compression (30%) | 0.3 In-house | 330M | – | 80.1 | 88.1 | 38.5 | 84.6 | 78.7 | 71.4 | 66.9 | 62.3 |
| Harmonia (本文) | |||||||||||
| Harmonia | In-house | 330M | 0.2 | 86.8 | 91.4 | 40.8 | 86.7 | 80.9 | 75.2 | 73.1 | 70.4 |
| Finetuned Teacher | In-house | 330M | – | – | – | – | 86.5 | 80.1 | 80.5 | 74.2 | 71.1 |
| Harmonia (Fine-tuned) | In-house | 330M | 0.2 | – | – | – | 87.1 | 81.5 | 83.1 | 74.9 | 73.1 |
| 消融研究 | |||||||||||
| Data Ablation (30%) | 0.3 In-house | 330M | 0.2 | 81.8 | 89.7 | 39.2 | 86.1 | 79.4 | 71.7 | 71.3 | 69.2 |
| Experiment α1 | In-house | 330M | 0.5 | 85.1 | 92.0 | 40.2 | 87.6 | 80.3 | 74.3 | 73.1 | 70.6 |
| Experiment α2 | In-house | 330M | 0.7 | 86.0 | 91.9 | 41.4 | 86.1 | 80.5 | 75.9 | 73.2 | 71.3 |
| Compression | In-house | 190M | 0.2 | 83.2 | 90.0 | 37.2 | 86.8 | 79.1 | 71.4 | 71.1 | 64.2 |
| 可扩展性研究 | |||||||||||
| Deeper Arch. | In-house | 650M | 0.2 | 85.4 | 92.4 | 41.6 | 86.7 | 80.6 | 75.2 | 73.2 | 68.2 |
| Long Context | In-house | 330M | 0.2 | 86.8 | 91.2 | 40.4 | 84.9 | 80.2 | 74.7 | 74.4 | 69.6 |
| SOTA [21-26] | – | – | – | 85.6 | 92.0 | 41.4 | 88.7 | 81.0 | 80.7 | 74.2 | 74.4 |
- 实际意义:为高效训练音乐基础模型提供了一种新思路。通过时间蒸馏,可以提升小模型性能、实现模型压缩、并稳定训练更大更深的模型,有助于降低音乐AI的研发门槛。
- 主要局限性:a) 理论分析不足,缺乏对时间KL损失优化几何的深入探讨;b) 实验主要基于单一的MusicFM架构和一家公司的内部数据(“In-house”),结论的普适性有待验证;c) 完全未开源,严重影响可复现性和社区影响力;d) 对长上下文正则化的具体实现和优势阐述不够细致。
🏗️ 模型架构
Harmonia本身并非一个独立的模型架构,而是一个应用于已有编码器(如MusicFM)的知识蒸馏框架。
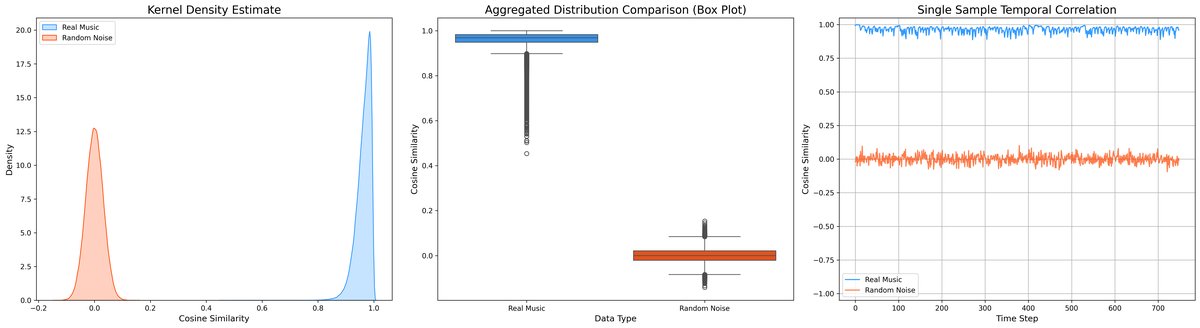 图1:Harmonia框架示意图。左侧为传统的逐帧蒸馏,教师和学生对齐每个时间步的输出分布。右侧为Harmonia的核心,教师和学生模型分别处理输入,输出隐藏序列表征 \(z \in R^{L \times D}\)。对于每个特征维度 \(d\),在时间轴上应用softmax得到时间分布向量 \(q_d\)。框架的目标是计算所有维度上教师与学生时间分布的KL散度(Temporal KL Loss),并以此来训练学生模型。
图1:Harmonia框架示意图。左侧为传统的逐帧蒸馏,教师和学生对齐每个时间步的输出分布。右侧为Harmonia的核心,教师和学生模型分别处理输入,输出隐藏序列表征 \(z \in R^{L \times D}\)。对于每个特征维度 \(d\),在时间轴上应用softmax得到时间分布向量 \(q_d\)。框架的目标是计算所有维度上教师与学生时间分布的KL散度(Temporal KL Loss),并以此来训练学生模型。
整体流程:
- 输入:音乐波形被转换为梅尔频谱图 \(x\)。
- 编码:教师模型 \(f_T\) 和学生模型 \(f_S\)(架构可相同或不同)分别将 \(x\) 编码为隐藏序列表征 \(z_T, z_S \in R^{L \times D}\),其中 \(L\) 是时间步数,\(D\) 是隐藏维度。
- 损失计算:
- 主任务损失(L_SSL):通常为掩码预测(如MusicFM),用于学习基本表示。
- 时间蒸馏损失(L_Temporal-KL):对于每个特征维度 \(d \in \{1, ..., D\}\):
- 计算教师的时间分布:\(q^T_d = \text{Softmax}(z^T_{:,d})\),其中 \(z^T_{:,d}\) 是教师输出中第 \(d\) 个维度随时间变化的序列。
- 计算学生的时间分布:\(q^S_d = \text{Softmax}(z^S_{:,d})\)。
- 计算该维度的KL散度:\(D_{KL}(q^T_d \| q^S_d)\)。
- 对所有 \(D\) 个维度取平均,得到最终的时间蒸馏损失 \(L_{Temporal-KL}\)。
- 训练目标:学生模型的总损失为 \(L_{Student} = (1 - \alpha) L_{SSL} + \alpha L_{Temporal-KL}\)。
应用变体:
- 通用知识迁移/自蒸馏:如上所述,学生和教师可以处理相同长度的输入。
- 长上下文编码器正则化:教师处理长音频切分出的多个短片段,学生处理完整的长音频。损失计算时,教师在每个短片段上计算时间分布,学生在其对应的时间切片上计算时间分布,然后对各片段的KL损失取平均。这为训练长上下文模型提供了局部的时间一致性监督。
关键设计选择:
- 对齐时间分布而非逐帧值:动机是捕获音乐的“动态演进”这一全局结构,而非孤立的时间点信息。实验(图2)证明预训练教师模型确实具有很强的时间连贯性(相邻帧余弦相似度高)。
- 使用KL散度:衡量两个概率分布之间的差异,适用于分布对齐任务。
💡 核心创新点
- 识别并针对“时间归纳偏置”缺失问题:明确指出传统逐帧蒸馏在序列任务(如音乐)上的根本缺陷——无法传递时间动态知识,这是对现有方法局限性的深刻洞察。
- 提出时间分布对齐(Temporal KL Loss):创新性地设计了对齐输出表征序列在时间维度上概率分布的损失函数。这是一种全新的蒸馏目标,直接作用于模型学到的时间先验。
- 框架的双重应用验证:不仅证明了Harmonia能有效进行知识迁移(用于模型压缩和小数据学习),还证明了它能作为一种正则化器,稳定和改善大规模、深层编码器的训练过程,拓展了蒸馏框架的应用场景。
🔬 细节详述
- 训练数据:
- 数据集:论文中未提供具体名称,仅标注为“In-house”(公司内部数据)。
- 规模:论文未明确说明总数据量。但在消融实验中提到了“Data Compression”使用30%数据。
- 预处理:输入波形转换为梅尔频谱图(Mel-spectrogram)。
- 数据增强:论文未明确提及特定的音频数据增强策略。
- 损失函数:
- 主任务损失 \(L_{SSL}\):采用MusicFM的掩码预测损失。
- 时间蒸馏损失 \(L_{Temporal-KL}\):如上文公式(1)所示,是跨所有隐藏维度的平均KL散度。
- 组合损失:公式(2) \(L_{Student} = (1 - \alpha)L_{SSL} + \alpha L_{Temporal-KL}\),其中 \(\alpha\) 是平衡超参数。
- 训练策略:
- 优化器:Adam。
- 学习率:1e-4。
- Batch Size:64。
- 训练硬件:8张NVIDIA A100 GPU。
- 掩码比例:0.6(与MusicFM一致)。
- 训练步数/轮数:论文未明确说明。
- 调度策略:论文未明确说明。
- Warmup:论文未明确说明。
- 关键超参数:
- 模型大小:主要实验为12层,330M参数(MusicFM架构)。压缩实验为190M参数,可扩展性实验为650M参数。
- 平衡权重 \(\alpha\):消融实验测试了0.2, 0.5, 0.7,主要结果使用0.2。
- 长上下文权重 \(\beta\):论文未给出具体数值。
- 推理细节:论文未提及推理时的特殊设置(如解码策略),通常此类表示模型用于特征提取,不涉及生成解码。
- 正则化技巧:Harmonia框架本身被提出是一种有效的正则化器。此外,论文提到了“时间一致性”能平滑优化空间,有助于逃离局部最小值,但这更多是方法论层面的解释,而非额外的正则化技巧。
📊 实验结果
主要对比与基准: 论文在9项MIR任务上进行了评估,包括分类(GTZAN)、标签(MagnaTagATune)和更复杂的结构理解任务(节拍、和弦、结构、调性)。主要对比了以下方法:
- 教师模型 (330M):预训练的MusicFM基线。
- 帧式蒸馏:传统逐帧匹配的蒸馏方法。
- 数据压缩基线:仅使用30%数据训练的教师模型。
- Harmonia(本文):不同配置下的时间蒸馏。
- SOTA:引用的其他先进方法(Mulan, Luyu等)。
关键结果(见上文核心摘要中的表格):
- 时间蒸馏的优越性:Harmonia(330M, α=0.2)在绝大多数任务上大幅超越帧式蒸馏,并显著超越教师模型。例如,在GTZAN上达到86.8%(教师82.7%),在和弦识别上达到75.2%(教师72.6%)。
- 数据效率:在仅使用30%数据时,Harmonia(81.8%)优于同数据量的基线(80.1%)。
- 模型压缩:190M的学生模型在多项任务上(如Beat F1 86.8%)接近330M教师模型(86.4%)。
- 可扩展性:650M的模型训练成功,并在MTT(ROC 92.4%)和和弦识别(75.2%)上达到最佳。长上下文模型在GTZAN上取得最高分(86.8%)。
- 与SOTA对比:在部分任务(如Beat F1, Chord ACC)上,Harmonia微调后的结果或最深模型结果与SOTA非常接近,甚至在个别指标上超越。
消融实验:
- 权重α:α=0.5和0.7也能取得较好结果,表明框架对超参数不敏感。
- 数据消融:如上所述,验证了数据效率。
- 图3(训练对比):显示Harmonia的训练曲线(绿色)比教师模型(蓝色)收敛更快,且最终损失更低,这提供了训练效率提升的直观证据。
图表引用与说明:
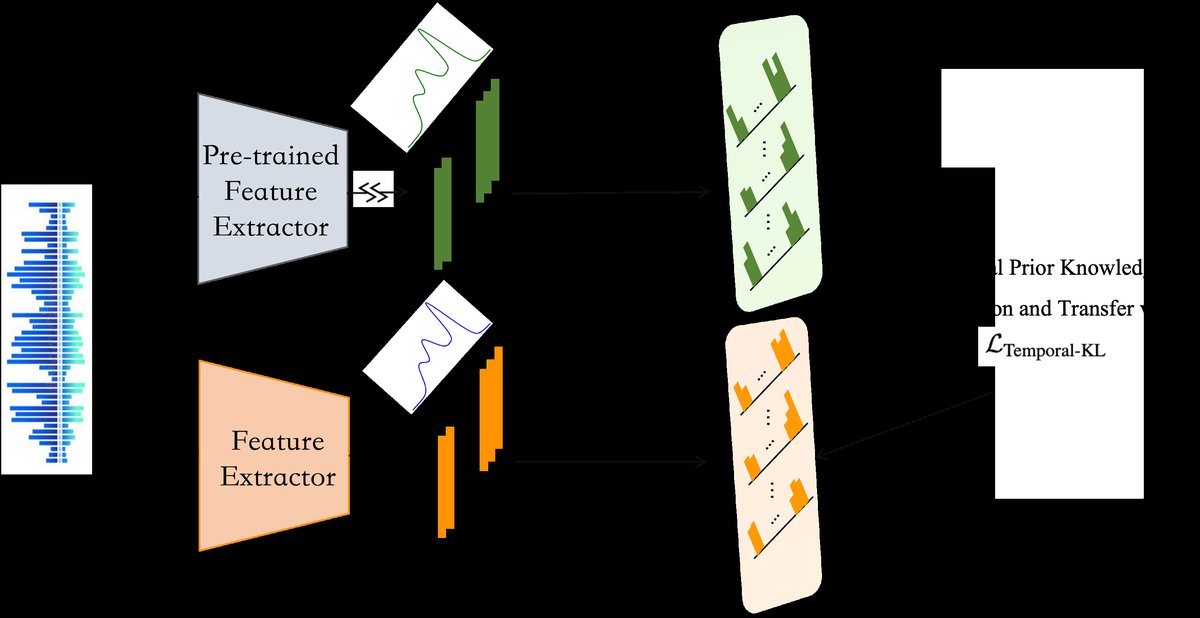 图2:预训练模型的时间连贯性验证。左图为预训练教师模型输出的相邻帧余弦相似度分布(红色),峰值接近0.85,表明高度连贯;右图为随机张量的分布(蓝色),接近0。此图证实了教师模型隐含了强大的时间先验,这是Harmonia方法成立的前提。
图2:预训练模型的时间连贯性验证。左图为预训练教师模型输出的相邻帧余弦相似度分布(红色),峰值接近0.85,表明高度连贯;右图为随机张量的分布(蓝色),接近0。此图证实了教师模型隐含了强大的时间先验,这是Harmonia方法成立的前提。
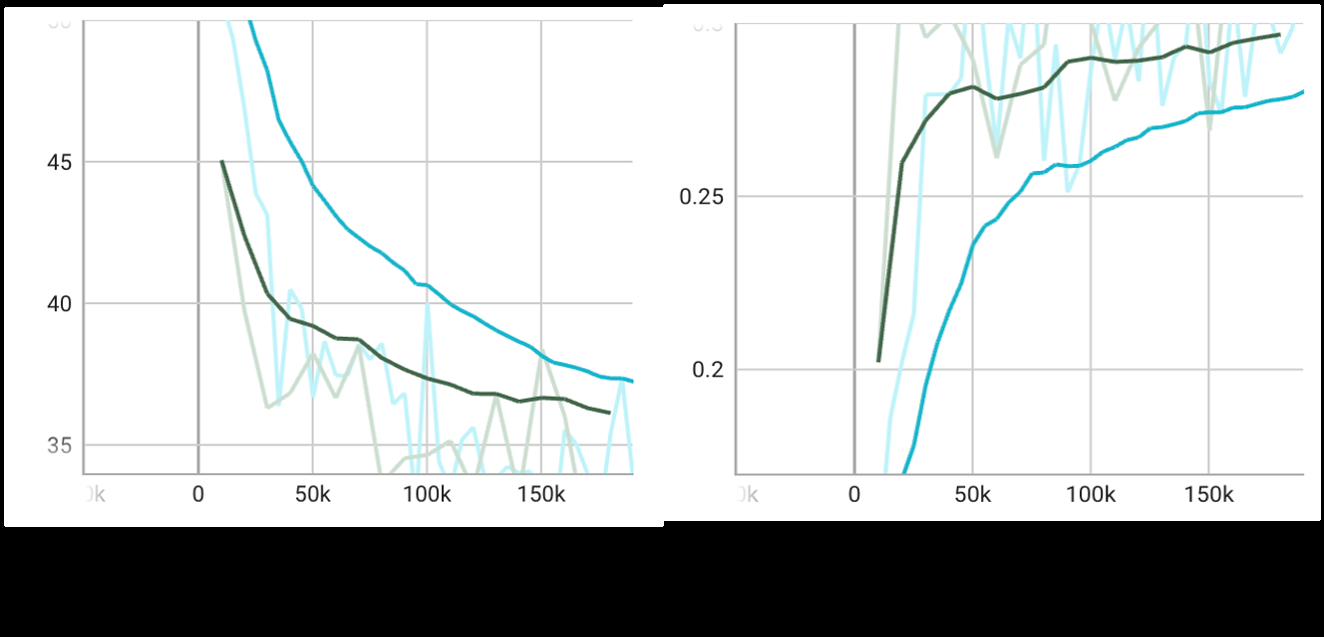 图3:训练过程对比。横轴为训练步数,纵轴为损失。绿色曲线(Harmonia)下降更快且最终低于蓝色曲线(教师模型),直观证明了Harmonia能提升训练效率,达到更低的损失值。
图3:训练过程对比。横轴为训练步数,纵轴为损失。绿色曲线(Harmonia)下降更快且最终低于蓝色曲线(教师模型),直观证明了Harmonia能提升训练效率,达到更低的损失值。
⚖️ 评分理由
- 学术质量:5.5/7。创新性明确(时间分布对齐),实验设计系统(覆盖多任务、多维度),证据较为充分(多组对比和消融),部分实验达到了SOTA水平。扣分在于:理论深度一般,对长上下文正则化的实验支撑不够全面,且部分实验设置细节(如长上下文的切分方式)描述不足。
- 选题价值:1.5/2。针对音乐表示学习中的关键瓶颈问题,提出了有前景的解决方案,对构建更强大、更高效的音乐基础模型有直接贡献。方法具有序列建模的通用性,但具体应用场景与“语音”读者的相关性中等。
- 开源与复现加成:0.5/1。论文详细列出了训练超参数和硬件,为复现提供了理论可能。但完全未提供代码、模型和数据,使得实际复现几乎无法进行,严重减分。