📄 Teaching the Teachers: Boosting Unsupervised Domain Adaptation In Speech Recognition By Ensemble Update
#语音识别 #领域适应 #知识蒸馏 #半监督学习 #教师-学生模型
✅ 7.0/10 | 前25% | #语音识别 | #领域适应 | #知识蒸馏 #半监督学习
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Rehan Ahmad(谢菲尔德大学)
- 通讯作者:未说明
- 作者列表:
- Rehan Ahmad¹² (¹University of Sheffield, UK; ²Emotech Ltd.)
- Muhammad Umar Farooq² (²Emotech Ltd.)
- Qihang Feng¹ (¹University of Sheffield, UK)
- Thomas Hain¹ (¹University of Sheffield, UK)
💡 毒舌点评
亮点:该工作直击多教师-学生训练范式中“教师模型更新滞后”这一痛点,提出了一个轻量(EMA更新)、高效(同时训练)且有效的同步更新机制,在多个基准上取得了显著WER提升,证明了其方法的实用性。 短板:创新本质是对现有“教师-学生”和“集成学习”方法的精巧组合与工程优化,缺乏理论上的深度突破。此外,所有实验均围绕英语语音识别展开,方法在其他语言或更复杂的声学环境下的有效性尚未可知,存在一定的泛化性质疑。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开预训练或微调后的模型权重。
- 数据集:实验中使用的AMI, WSJ, LS360, SwitchBoard均为公开语音数据集(论文中给出了引用),可依法获取。
- Demo:未提及在线演示。
- 复现材料:论文提供了算法伪代码(Algorithm 1)、关键超参数(α, Δ, τ)的最优值及其影响分析,以及模型架构的简要描述(基于wav2vec 2.0)。但缺乏训练日志、优化器设置、学习率策略等细节。
- 引用的开源项目:主要依赖预训练模型
wav2vec 2.0(开源),以及标准的CTC损失实现。 - 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:语音识别系统在训练数据未覆盖的新领域(Out-of-Domain, OOD)上性能会显著下降。无监督领域适应(UDA)方法,特别是基于教师-学生(T/S)的框架,可以缓解这一问题,但其性能与有监督的领域内训练相比仍有较大差距。
- 方法核心:本文提出“同时更新教师模型”(Simultaneous Teachers Update, STU)的策略。在传统的集成教师-学生框架中,多个教师模型在源数据上预训练后,生成伪标签来训练学生模型。现有方法(如METS)要么教师模型固定,要么顺序更新学生模型作为新教师。本文则在训练学生模型的同时,通过指数移动平均(EMA)的方式,用当前学生模型的权重来同步更新所有教师模型的参数。
- 创新点:与多阶段顺序更新(METS)相比,该方法避免了多轮完整训练,降低了计算复杂度;与迭代伪标签或单教师更新(KAIZEN)相比,它保持了集成教师的优势并提升了所有教师的质量,从而为学生模型提供更高质量的伪标签。
- 主要实验结果:在三个有标签源数据集(AMI, WSJ, LS360)上训练教师模型,在无标签的SwitchBoard(电话对话语音)上适应学生模型。与多个基线方法(STS, KAIZEN, ETS, METS)相比,所提出的STU方法在SwitchBoard eval00测试集上实现了最低的词错率(WER)。具体而言,在使用外部语言模型时,STU的WER为18.7%,相比最强基线METS的19.6%降低了0.9%;相比其他基线,优势更大(如比ETS的26.2%低7.5%)。
关键数据表格(WER% on eval00 w/ LM):
方法 eval00 CallHome SwitchBoard STU (本文) 18.7 22.3 15.0 METS 19.6 23.1 16.0 ETS 26.2 30.2 22.0 KAIZEN 29.3 33.3 25.1 STS 31.5 35.8 27.0 有监督上限 (SWBD) 10.1 12.8 7.3 - 实际意义:该方法提供了一种更高效、计算成本更低的无监督领域适应方案,能够利用多个源域的有标签数据,快速适配到新的无标签目标域,对于需要快速部署语音识别系统的场景(如特定行业、新语种)具有实用价值。
- 主要局限性:
- 论文指出,方法可能导致模型崩溃(model collapse),尤其是在域外数据上,现有的控制技术效果不佳,这是一个需要解决的稳定性问题。
- 所有实验均在英语语音数据集上进行,方法在多语言或方言场景下的有效性有待验证。
- 依赖特定的超参数(α, Δ, τ)组合,且这些参数相互影响,调优过程复杂。
🏗️ 模型架构
该论文的系统架构围绕集成教师-学生(Ensemble Teacher-Student) 框架构建,核心是同时更新教师模型。
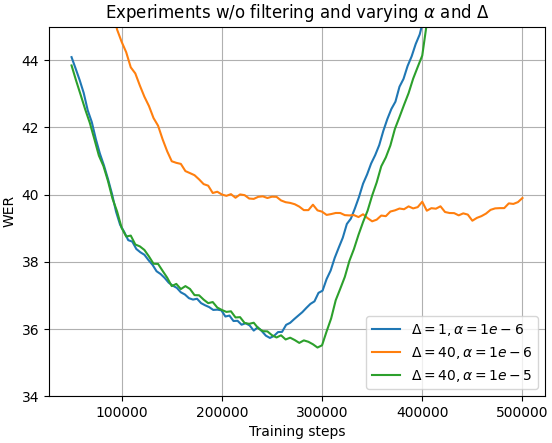 图1:同时更新教师模型的系统框图。无标签音频输入所有教师模型,每个模型输出后验概率。通过选择与过滤机制,选出一个最优后验概率分布,解码成伪标签,用于训练学生模型。学生模型通过EMA方式更新所有教师模型。
图1:同时更新教师模型的系统框图。无标签音频输入所有教师模型,每个模型输出后验概率。通过选择与过滤机制,选出一个最优后验概率分布,解码成伪标签,用于训练学生模型。学生模型通过EMA方式更新所有教师模型。
主要组件与数据流:
教师模型集合 (T₁, T₂, … Tₙ):
- 数量:N=3个。
- 基础架构:基于
wav2vec 2.0预训练模型,后接两个全连接层,输出为31个英文字符(含空格、字母、撇号)的后验概率分布。 - 初始训练:每个教师模型独立在各自对应的有标签源数据集上进行微调(使用CTC损失)。
- 输入:原始音频波形。
- 输出:帧级别的token后验分布
P_i。
学生模型 (M):
- 架构:与教师模型完全相同。
- 初始化:随机初始化。
- 训练目标:在无标签目标域数据集 (U) 上,使用从教师模型生成的伪标签
L̂进行微调(CTC损失)。
选择与过滤模块:
- 功能:为每个无标签语音片段,从多个教师模型的输出中选出最可靠的一个作为伪标签来源。
- 流程:
- 计算置信度:对每个教师模型k,计算其在该片段上每个时间帧最大后验概率的平均值
q_k。 - 精英选择:选择置信度最高的教师模型
b = argmax_k q_k。 - 置信度过滤:设定阈值
τ,只有当被选教师的置信度q_b ≥ τ时,才使用该片段的后验概率分布P̂;否则丢弃该片段。 - 解码:对保留的后验分布
P̂进行贪心解码,得到伪标签L̂。
- 计算置信度:对每个教师模型k,计算其在该片段上每个时间帧最大后验概率的平均值
联合更新机制:
- 学生模型更新:标准反向传播,使用伪标签计算CTC损失。
- 教师模型更新:采用指数移动平均(EMA) 方式。每隔
Δ次学生模型更新,所有教师模型参数Θ_i被更新为当前学生模型参数Φ与自身参数的加权平均:Θ_i = αΦ + (1 − α)Θ_i。其中α是一个非常小的值(如1e-5),保证教师模型缓慢、稳定地向学生模型靠近。
💡 核心创新点
同时更新集成教师模型:
- 局限:以往多阶段方法(如METS)需要顺序训练多个学生模型,前一阶段的学生作为下一阶段的教师,导致计算成本高昂且可能丢失集成的多样性。
- 如何起作用:在训练当前学生模型的同时,使用EMA直接更新所有现有的教师模型,使教师群体能同步获得学生模型学到的、更适应目标域的知识。
- 收益:避免了多阶段训练,降低了复杂度;教师模型质量的同步提升,使得为学生模型生成的伪标签质量逐轮提高。
轻量且有效的教师模型更新方式:
- 局限:对学生模型进行反向传播是标准做法,但对教师模型进行类似更新会非常昂贵。
- 如何起作用:采用EMA,这是一种无需梯度计算的参数平滑更新方法,仅涉及简单的加权平均操作。
- 收益:更新成本极低,几乎不增加额外计算开销,却能使教师模型持续进化。
将迭代更新融入集成教师-学生框架:
- 局限:传统的集成教师-学生方法(如ETS)中,教师是固定的;迭代更新方法(如KAIZEN)通常只针对单一教师。
- 如何起作用:将迭代自训练的思想与集成教师相结合,形成一个统一的、同时优化的训练循环。
- 收益:结合了集成学习(提供互补信息)和自训练(利用无标签数据)的优势,并在统一框架内进行优化。
🔬 细节详述
- 训练数据:
- 源域(有标签):AMI (100h,会议语音), WSJ (272h,朗读语音), LS360 (360h,朗读语音)。
- 目标域(无标签):SwitchBoard (300h,电话对话语音)。音频上采样至16KHz。
- 评估集:SwitchBoard eval00,包含SwitchBoard (SB) 和 CallHome (CH) 两个子集。
- 损失函数:CTC损失(公式1),用于教师模型在源数据上的初始微调和学生模型在无标签数据上的训练。
- 训练策略:
- 优化器/学习率:论文未明确说明优化器类型和学习率。从超参数讨论看,重点在于
α,Δ,τ的协调。 - 关键超参数:最优值为
α = 1e-5,Δ = 40,τ = 0.90。论文详细分析了这三个参数对收敛稳定性和性能的影响(见图2)。 - 训练步数:未明确说明。图2显示了约300k步的训练过程。
- 优化器/学习率:论文未明确说明优化器类型和学习率。从超参数讨论看,重点在于
- 训练硬件:论文中未提及。
- 推理细节:
- 教师生成伪标签时:使用贪心解码,以降低训练阶段计算量。
- 评估学生模型时:使用一个外接的3-gram语言模型(OOD LM),该LM在AMI, LS360, WSJ数据上训练。评估时进行有/无LM的对比。
- 正则化或稳定训练技巧:
- 置信度过滤:通过阈值
τ过滤低置信度的语音片段,减少错误标签的干扰。 - EMA更新:通过小的
α值,使教师模型缓慢更新,有助于稳定训练过程。
- 置信度过滤:通过阈值
📊 实验结果
主要实验在SwitchBoard eval00测试集上进行,比较了所提出STU方法与多种基线方法。
表1:eval00测试集上的WER(%)对比
| 模型/方法 | 评估集 | 无LM (w/o LM) | 有LM (w/ LM) |
|---|---|---|---|
| 教师模型 | eval00 | 47.4 / 41.8 / 64.2 | 44.3 / 38.2 / 61.8 |
| (T1:AMI, T2:LS360, T3:WSJ) | CH | 52.0 / 46.8 / 71.6 | 49.0 / 43.2 / 69.7 |
| SB | 42.5 / 36.7 / 56.5 | 39.3 / 33.0 / 53.5 | |
| 有监督基线 (SWBD) | eval00 | 11.9 | 10.1 |
| 学生模型 | eval00 | ||
| STS (单教师) | 36.3 | 31.5 | |
| KAIZEN (单教师迭代) | 33.5 | 29.3 | |
| ETS (集成教师) | 32.0 | 26.2 | |
| METS (多阶段集成) | 21.0 | 19.6 | |
| STU (本文方法) | 23.4 | 18.7 | |
| CH | 27.3 | 22.3 | |
| SB | 19.3 | 15.0 |
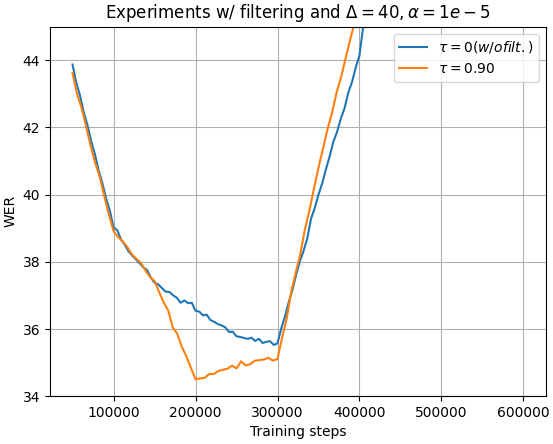 图2:不同超参数下学生模型验证集WER的收敛曲线。 (a) 不同α值的影响(Δ固定为1)。 (b) 不同Δ值的影响(α相应调整)。 (c) 不同τ值的影响(α和Δ固定)。
图2:不同超参数下学生模型验证集WER的收敛曲线。 (a) 不同α值的影响(Δ固定为1)。 (b) 不同Δ值的影响(α相应调整)。 (c) 不同τ值的影响(α和Δ固定)。
关键结论:
- 集成优于单教师:ETS方法(32.0% w/o LM)显著优于STS(36.3%)和KAIZEN(33.5%),证明了教师集成的有效性。
- 多阶段训练强大但昂贵:METS方法在无LM时达到了21.0%的最佳WER,但其训练过程涉及多个学生模型的完整训练,计算成本很高。
- 本文方法(STU)高效且有效:在仅使用贪心解码和单个学生模型训练的前提下,STU在有LM评估时达到了最低的18.7% WER,超过了使用了beam search和语言模型的METS(19.6%)。在无LM评估下,STU(23.4%)略逊于METS(21.0%),但仍远优于其他基线。
- 参数敏感性:图2揭示了
α(教师更新步长)、Δ(更新频率)和τ(过滤阈值)三者之间需要仔细权衡,以平衡训练稳定性和性能。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性(2/3):创新点明确,即提出“同时更新教师模型”的机制,并有效结合了EMA和集成学习。但属于现有技术框架的改进与整合,非基础理论或架构突破。
- 技术正确性(2/2):方法描述清晰,算法完整,公式(EMA更新)正确。实验设计合理,对比充分。
- 实验充分性(2/2):在标准数据集上进行了全面的对比实验,包括多种强基线,并提供了详细的收敛分析和参数敏感性分析。结果数字明确。
- 选题价值:1.5/2
- 前沿性(1/1):无监督领域适应是当前语音识别研究的热点和难点,具有明确的前沿性。
- 潜在影响(0.5/1):方法有效降低了WER,且计算上比METS更高效,对实际应用(如快速适配新领域)有积极意义。但应用场景集中在英语对话语音,普遍性有待观察。
- 开源与复现加成:-0.5/1
- 论文未提供代码、模型或详细训练脚本。虽然公开了关键超参数,但复现需要大量工程实现和调参工作,信息不够充分,不利于快速验证和推广。