📄 Teacher-Guided Pseudo Supervision and Cross-Modal Alignment for Audio-Visual Video Parsing
#音视频 #视频理解 #知识蒸馏 #弱监督学习
✅ 7.0/10 | 前25% | #音视频 | #知识蒸馏 | #视频理解 #弱监督学习
学术质量 6.5/7 | 选题价值 7.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yaru Chen (Centre for Vision Speech and Signal Processing, University of Surrey, United Kingdom)
- 通讯作者:未说明
- 作者列表:
- Yaru Chen (Centre for Vision Speech and Signal Processing, University of Surrey, United Kingdom)
- Ruohao Guo (School of Intelligence Science and Technology, Peking University, China)
- Liting Gao (Centre for Vision Speech and Signal Processing, University of Surrey, United Kingdom)
- Yang Xiang (Centre for Vision Speech and Signal Processing, University of Surrey, United Kingdom)
- Qingyu Luo (Centre for Vision Speech and Signal Processing, University of Surrey, United Kingdom)
- Zhenbo Li (College of Information and Electrical Engineering, China Agricultural University, China)
- Wenwu Wang (Centre for Vision Speech and Signal Processing, University of Surrey, United Kingdom)
💡 毒舌点评
这篇论文的亮点在于其系统性和针对性:它精准地指出了现有弱监督AVVP方法的两个痛点(缺乏稳定段监督、粗糙的跨模态对齐),并用EMA和CMA这两个成熟但组合起来很有效的方案“对症下药”,在LLP数据集上的视觉和音视频联合指标上取得了实实在在的提升。但短板也十分明显:创新程度更像是一个“集大成”的工程优化方案,而非提出一个全新的学习范式;而且,论文在追求性能报告上非常详细,却在开源复现信息上极为吝啬,这对于一个旨在推动领域前进的会议论文来说,是减分项。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开权重。
- 数据集:LLP和UnAV-100均为公开数据集,论文中给出了引用和基本描述。
- Demo:未提供在线演示。
- 复现材料:论文详细描述了模型架构、损失函数和主要思路,并报告了在标准数据集上的结果。然而,关键的训练超参数(如学习率、EMA动量α、阈值γ、Top-k的k值等)未在正文中明确给出,这使得精确复现存在困难。
- 论文中引用的开源项目:论文明确指出其基线是CoLeaF [8],并使用了预训练模型CLIP [12] 和 CLAP [13]。在UnAV-100实验中使用了I3D [19] 和VGGish [20] 模型提取特征。这些都是可公开获取的开源项目/预训练模型。
📌 核心摘要
- 解决的问题:本文针对弱监督音视频视频解析(AVVP)任务,旨在仅使用视频级标签训练模型,以定位视频中仅音频、仅视频以及音视频事件的时间范围与类别。核心挑战在于缺乏精确的段级监督信号,以及现有跨模态对齐方法过于全局化,忽略了不同类别事件在不同模态、不同时间出现的特性。
- 方法核心:提出E-CMA框架,包含两大核心策略:(1) 指数移动平均(EMA)引导的伪监督:构建教师-学生模型,教师模型参数由学生模型参数的EMA更新,能更稳定地生成段级二值伪掩码(通过自适应阈值或Top-k选择),为学生提供比视频级标签更精细、动态更新的监督信号。(2) 类感知跨模态一致性(CMA)损失:仅对那些音频和视觉预测置信度均高且与视频级标签一致的“可靠”片段-类别对,强制其音频和视觉特征向量的余弦相似度接近1,实现选择性的细粒度跨模态对齐。
- 与已有方法的创新:相比之前仅使用静态伪标签或全局跨模态相似度方法,本工作创新在于:a) 引入动态的、由教师模型生成的伪监督,提升了段级监督的稳定性;b) 提出类感知的选择性对齐策略,避免了强制对齐不相关事件带来的噪声。
- 主要实验结果:在LLP基准数据集上,E-CMA在段级解析上达到SOTA,音频F1为66.1%(+0.2%),视觉F1为69.9%(+2.8%),音视频联合F1为61.7%(+1.1%)。在事件级解析上,视觉F1达到66.6%。在UnAV-100数据集上,音视频段级F1为41.8%(+0.3%)。消融实验表明,同时去除CMA和EMA会导致所有指标下降,证实了二者的互补有效性。
| 模型 (数据集) | 音频F1 (段级) | 视觉F1 (段级) | 音视频F1 (段级) | 类别平均F1 (段级) | 事件平均F1 (段级) |
|---|---|---|---|---|---|
| CoLeaF (LLP) | 64.2 | 67.1 | 59.8 | 63.8 | 61.9 |
| E-CMA (LLP) | 66.1 | 69.9 | 61.7 | 65.9 | 65.4 |
表1:在LLP数据集上的关键段级性能对比(论文表1节选)。
| 模型 | 音视频段级F1 | 音视频事件级F1 |
|---|---|---|
| CoLeaF (UnAV-100) | 41.5 | 47.8 |
| E-CMA (UnAV-100) | 41.8 | 47.4 |
表2:在UnAV-100数据集上的性能对比(论文表2)。
| 消融设置 | 段级AV F1 | 事件级AV F1 |
|---|---|---|
| CoLeaF† (基线) | 59.9 | 52.4 |
| w/o CMA | 60.4 | 52.3 |
| w/o EMA | 61.0 | 52.9 |
| E-CMA (完整) | 61.7 | 53.5 |
表3:消融实验结果,展示EMA和CMA模块的贡献(论文表3节选)。
- 实际意义:该工作提升了弱监督条件下音视频事件解析的精度,为减少视频分析中的密集人工标注成本提供了更优的算法方案,对智能安防、视频内容理解与检索等领域有应用价值。
- 主要局限性:论文承认其伪标签生成策略(自适应阈值/Top-k)是固定的,可能无法充分适应视频中复杂的事件分布变化。此外,论文未提供代码和完整的复现实例,限制了其可重复性和社区快速跟进。
🏗️ 模型架构
本文提出的E-CMA框架建立在CoLeaF基线之上,整体架构如图2所示。
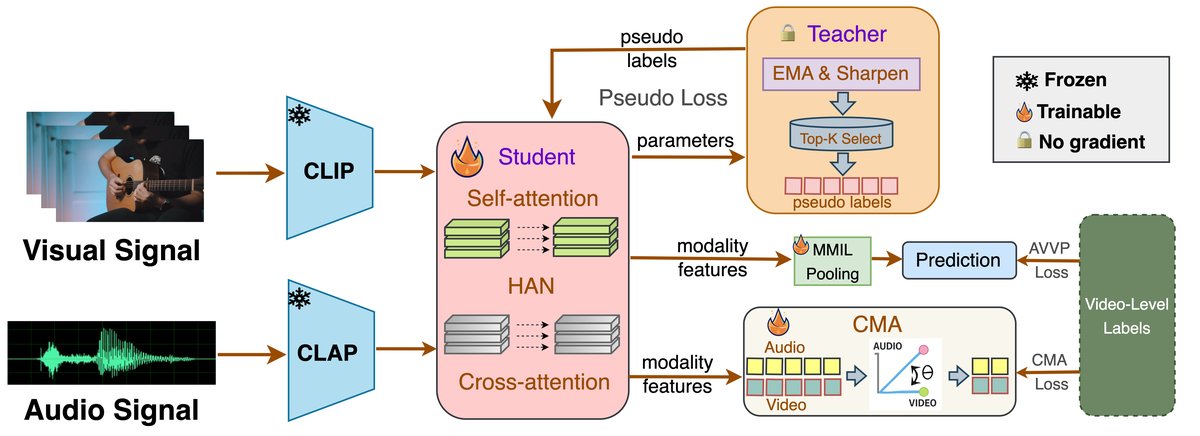
整体输入输出流程:
- 输入:一段T秒的视频,被划分为T个不重叠的1秒片段。每个片段提取出音频特征
xa_t和视觉特征xv_t。 - 特征编码与融合:使用预训练的CLAP和CLIP模型分别编码音频和视觉特征。这些特征随后输入到层次注意力网络(HAN)中,HAN通过自注意力和跨注意力机制,捕捉片段内的时序依赖和片段间的跨模态交互,输出精炼后的段表示。
- 多实例学习池化(MMIL):精炼后的段表示被聚合成视频级预测,对应弱监督标签
y。 - 教师-学生伪监督生成:
- 学生网络:与上述流程一致,产生片段级的音视频概率
Pt帽。 - 教师网络:架构与学生相同,但参数通过EMA(公式2)从学生网络更新。教师网络产生更稳定的片段级预测
Pt波浪,并通过自适应阈值(公式4、5)或Top-k选择生成二值伪掩码矩阵M。这个M指示了哪些片段-类别对是可靠的。
- 学生网络:与上述流程一致,产生片段级的音视频概率
- 跨模态对齐(CMA):在可靠的片段-类别对
(t,c)(满足置信度阈值且与视频标签一致)上,计算音频特征xa_t和视觉特征xv_t的余弦相似度s_{t,c}。 - 输出与损失:最终的损失函数(公式9)包含三部分:标准AVVP损失(
LAVVP)、伪监督损失(Lpseudo,基于M的掩码交叉熵损失)和CMA损失(LCMA)。训练目标是同时优化这三个损失。
关键组件解释:
- EMA教师:核心作用是作为学生网络的“稳定版”参考,生成更可靠的伪标签,缓解因学生网络训练早期波动或噪声标签导致的错误传播。
- CMA模块:核心作用是“选择性”对齐。它不强求所有时段音频和视觉特征相似,而是只在模型已经“确信”是某个事件发生的时段,鼓励模态特征一致,从而避免将无关内容错误对齐。
- HAN与MMIL:是继承自基线的特征聚合模块,负责从编码后的特征中提取时空和跨模态信息,并映射到任务标签。
💡 核心创新点
EMA引导的动态伪监督框架:
- 是什么:采用教师-学生架构,教师模型参数是学生模型参数的指数移动平均。教师模型用于生成段级伪标签(二值掩码),并通过损失函数监督学生。
- 之前局限:以往方法要么将视频级标签简单传播给所有片段(引入噪声),要么使用静态的伪标签(如从预训练CLIP/CLAP生成),无法在训练过程中自适应优化。
- 如何起作用:EMA使教师模型的预测比当前学生更稳定、更平滑。自适应阈值或Top-k选择从教师预测中挑选高置信度位置生成伪掩码,作为额外的段级监督信号。
- 收益:提供了超越视频级标签的稳定时序指导,减少了静态伪标签的噪声和领域不匹配问题。
类感知跨模态一致性(CMA)损失:
- 是什么:一种选择性的特征对齐损失,仅作用于那些音频和视觉预测均置信且与视频级标签一致的片段-类别对。
- 之前局限:大多数跨模态方法最大化全局音视频相似度,这可能迫使模型在不同事件发生的时段也去对齐特征,导致错误关联。
- 如何起作用:通过置信度阈值和标签一致性双重过滤,定义了可靠的对齐集合
Ω。在该集合上最小化(1 - 余弦相似度),即鼓励特征向量对齐。 - 收益:实现了更精细、事件一致的跨模态监督,防止了异步内容的强制匹配,提升了定位的准确性。
模块的互补性:
- 消融实验(表3)表明,EMA主要提升事件级一致性(Event@AV),而CMA主要提升跨模态指标(视觉和音视频F1)。两者结合带来全面提升,证明了其互补性。
🔬 细节详述
- 训练数据:
- 数据集:LLP数据集(11,849个10秒视频,25类事件);UnAV-100数据集(10,790个长视频,100类事件)。
- 来源:论文中未详细说明。
- 预处理:视频被划分为1秒不重叠的片段。特征提取:在LLP上使用预训练CLAP和CLIP提取768维特征;在UnAV-100上使用双流I3D(RGB+RAFT)提取2048维视觉特征,VGGish提取128维音频特征。
- 数据增强:论文中未提及。
- 损失函数:
LAVVP:标准二元交叉熵损失,用于视频级预测。Lpseudo:掩码二元交叉熵损失(公式6),仅在伪掩码M为1的位置计算,监督学生网络的融合预测Pt帽。LCMA:平均余弦距离损失(公式8),仅在可靠对(t,c) ∈ Ω上计算。- 总损失
L = LAVVP + Lpseudo + LCMA。论文未说明三个损失的权重,默认是相加。
- 训练策略:
- 学习率:未说明。
- Warmup:未说明。
- Batch size:未说明。
- 优化器:未说明。
- 训练步数/轮数:未说明。
- 调度策略:未说明。
- 关键超参数:
- EMA动量
α:公式2中定义,但具体值未在正文中说明。 - 自适应阈值缩放因子
γ:公式4中定义,具体值未在正文中说明。 - Top-k选择的
k:未在正文中说明具体值。 - CMA���失中使用的置信度阈值
τa,τv:未说明。
- EMA动量
- 训练硬件:未说明。
- 推理细节:未明确说明,推测与训练时学生网络的前向传播相同。
- 正则化或稳定训练技巧:核心的稳定训练技巧就是EMA教师网络和基于置信度的伪标签选择。
📊 实验结果
主要Benchmark与结果:
- 数据集:LLP, UnAV-100。
- 指标:段级和事件级的音频(A)、视觉(V)、音视频(AV) F1分数,以及类别平均F1(Type@AV)和事件平均F1(Event@AV)。IoU阈值为0.5。
- 核心对比:与近期SOTA方法对比,如CoLeaF (ECCV’24), PPL (CVPR’24), VALOR (NeurIPS’23)等。
关键结果表格(完整引用自论文表1):
| Model | Venue | Segment-level (%) | Event-level (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| A | V | AV | Type@AV | Event@AV | A | V | AV | ||
| HAN [1] | ECCV’20 | 60.1 | 52.9 | 48.9 | 54.0 | 55.4 | 51.3 | 48.9 | 43.0 |
| MGN [16] | NeurIPS’22 | 60.8 | 55.4 | 50.0 | 55.1 | 57.6 | 52.7 | 51.8 | 44.4 |
| MA [5] | CVPR’21 | 60.3 | 60.0 | 55.1 | 58.9 | 57.9 | 53.6 | 56.4 | 49.0 |
| CMPAE [11] | CVPR’23 | 64.2 | 66.2 | 59.2 | 63.3 | 62.8 | 56.6 | 63.7 | 51.8 |
| VALOR [14] | NeurIPS’23 | 61.8 | 65.9 | 58.4 | 62.0 | 61.5 | 55.4 | 62.6 | 52.2 |
| CoLeaF [8] | ECCV’24 | 64.2 | 67.1 | 59.8 | 63.8 | 61.9 | 57.1 | 64.8 | 52.8 |
| PPL [15] | CVPR’24 | 65.9 | 66.7 | 61.9 | 64.8 | 63.7 | 57.3 | 64.3 | 54.3 |
| RLLD [21] | CVM’25 | 62.2 | 66.7 | 59.3 | 62.7 | 62.4 | 55.7 | 63.1 | 53.7 |
| PPAE [9] | TPAMI’25 | 64.3 | 66.6 | 59.6 | 63.5 | 63.0 | 57.0 | 64.1 | 52.5 |
| E-CMA | - | 66.1 | 69.9 | 61.7 | 65.9 | 65.4 | 54.5 | 66.6 | 53.5 |
| (+0.2) | (+2.8) | (+1.1) | (+1.7) | (+1.8) |
与最强基线差距:在段级指标上,E-CMA相对于第二名(PPL)在视觉F1上领先3.2个百分点(69.9% vs 66.7%),在音视频F1上领先0.2个百分点(61.7% vs 61.5%)。在事件级指标上,E-CMA在视觉F1上领先2.3个百分点(66.6% vs 64.3%),但在音频A和音视频AV F1上略低于PPL。
关键消融实验(表3):
- 移除CMA:段级视觉F1从69.9%降至68.2%,音视频F1从61.7%降至60.4%,表明CMA对提升跨模态性能至关重要。
- 移除EMA:事件级Event@AV从54.3%降至54.0%,表明EMA对提升事件级一致性有贡献。
- 完整模型:在所有指标上均优于基线CoLeaF†和任何单模块移除的变体。
不同条件/场景下的结果:论文未提供跨语言或不同场景的细分结果,实验仅在两个英文视频数据集上进行。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出的E-CMA框架技术路线正确,实验设计完整,包含多个基线的对比和充分的消融研究,结果可信。两个创新点(EMA伪监督、CMA损失)各自有效且互补,共同推动了性能提升。创新性属于将已有技术(EMA、选择性损失)在特定问题上进行有效组合与适配,而非提出全新的模型或理论,因此未给予更高分数。
- 选题价值:1.5/2:弱监督音视频理解是一个活跃且有实际意义的研究方向,本文针对该任务中的具体挑战提出了解决方案,具有一定的前沿性和应用潜力。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重或足够详细的训练配置(如具体超参数值、优化器设置),这严重影响了其可复现性,因此不加分。