📄 TAU: A Benchmark for Cultural Sound Understanding Beyond Semantics
#音频问答 #基准测试 #数据集 #模型评估
✅ 7.5/10 | 前25% | #音频问答 | #基准测试 | #数据集 #模型评估
学术质量 0.85/7 | 选题价值 0.75/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yi-Cheng Lin (National Taiwan University)
- 通讯作者:论文中未明确指定通讯作者
- 作者列表:Yi-Cheng Lin¹, Yu-Hua Chen², Jia-Kai Dong¹, Yueh-Hsuan Huang¹, Szu-Chi Chen¹, Yu-Chen Chen¹, Chih-Yao Chen¹, Yu-Jung Lin¹, Yu-Ling Chen¹, Zih-Yu Chen¹, I-Ning Tsai¹, Hsiu-Hsuan Wang¹, Ho-Lam Chung¹, Ke-Han Lu¹, Hung-yi Lee¹ (¹National Taiwan University, ²University of Toronto)
💡 毒舌点评
该论文的亮点在于它敏锐地指出了当前音频-语言模型评估体系中一个被忽视的“文化盲区”,并为此提供了一个设计精巧、收集过程透明的高质量本地化基准,为推动更公平的多模态评估铺了路。短板则在于,它本质上是一个评估工具(Benchmark),而非解决该问题的算法或模型,因此其影响力高度依赖于后续研究社区的采纳程度,且论文本身未对“如何提升模型的文化理解能力”给出更深入的方案探索。
🔗 开源详情
- 代码:论文中未提及明确的代码仓库链接。仅提供了项目主页链接
https://dlion168.github.io/TAU_demo/,该页面可能包含演示或信息,但未说明是否包含数据处理、问题生成和过滤的源代码。 - 模型权重:未提及。本文评估现有模型,未贡献新模型。
- 数据集:项目主页链接暗示数据集可能与之相关,但论文中未明确说明数据集是否公开、如何获取(例如,是否需要签署协议、通过何种平台分发)。
- Demo:项目主页链接(
https://dlion168.github.io/TAU_demo/)可能是一个演示页面,但论文未具体描述。 - 复现材料:论文详细描述了基准构建的五阶段流程,但未提供构建过程中使用的具体工具版本、LLM提示词模板、过滤的精确统计检验参数(如t值)等完整复现细节。
- 论文中引用的开源项目:明确提到了在数据集构建和评估中使用的开源模型,包括Whisper (large-v3) 用于转录,LLaMA-3.1 (8B) 用于文本泄漏检测,Gemini 2.5 Flash 用于辅助问题生成。
- 总体开源计划:论文中未提及明确的开源计划(如后续将在GitHub开源代码和数据)。
📌 核心摘要
- 问题:现有的大型音频-语言模型评估基准主要关注语音或全球通用的声音环境音,忽略了对社区独特文化声音(如特定地区的地铁提示音、便利店音乐)的理解能力评估,导致无法真实衡量模型在真实本地化场景中的表现,并可能加剧技术对弱势社区的排斥。
- 方法核心:提出了TAU(台湾音频理解)基准,通过一个结合人工编辑和LLM辅助的多阶段流程,构建了702个台湾日常“声音地标”音频片段和1,794个无法仅通过文本转录解答的文化相关多选题。
- 新意:不同于以往评估语音语义或全球通用声音的基准,TAU首次将评估重点转向“非词汇的、文化特异性的声景理解”,强调通过音色、节奏等声学特征而非语义进行识别。
- 主要实验结果:实验表明,最先进的模型(如Gemini 2.5 Pro)在TAU上的表现(单跳72.4%,多跳73.9%)远低于本地人类表现(单跳84.0%,多跳83.3%)。即使在提供“文化身份”提示后,模型性能也无普适性提升,甚至对部分顶级模型有轻微下降。具体关键数据如下表所示:
| 模型 | 参数量 | 单跳准确率 (默认提示) | 多跳准确率 (默认提示) | 单跳准确率 (文化提示) | 多跳准确率 (文化提示) |
|---|---|---|---|---|---|
| 人类(顶线) | - | 84.0% | 83.3% | - | - |
| Gemini 2.5 Pro | - | 72.4% | 73.9% | 70.6% | 71.8% |
| Gemini 2.5 Flash | - | 61.3% | 63.2% | 62.8% | 62.2% |
| Qwen2.5-Omni-7B | 7.6B | 46.4% | 46.1% | 43.6% | 42.3% |
| DeSTA2.5-Audio | 8.8B | 43.3% | 41.7% | 38.2% | 38.9% |
| Qwen2-Audio-Instruct | 8.2B | 30.3% | 27.8% | 29.0% | 27.1% |
| Gemma-3n-E4B-it | 6.8B | 29.0% | 25.9% | 34.0% | 33.4% |
| 随机基线 | - | 25.0% | 25.0% | 25.0% | 25.0% |
- 实际意义:揭示了当前模型在文化本地化音频理解上的严重不足,强调了构建本地化评估基准对于实现公平、稳健的多模态AI的必要性。
- 主要局限性:基准仅专注于台湾文化,性能在其他地区不具普适性;声音库可能存在城市场景过采样问题;声景随时间变化可能导致数据分布偏移。
🏗️ 模型架构
本文是一篇基准测试论文,并未提出新的模型架构。其核心工作是构建了一个用于评估现有大型音频-语言模型的数据集和评估流程。因此,没有模型架构图。论文中提及的架构图(如图1)是数据集构建工作流的示意图,而非模型架构。
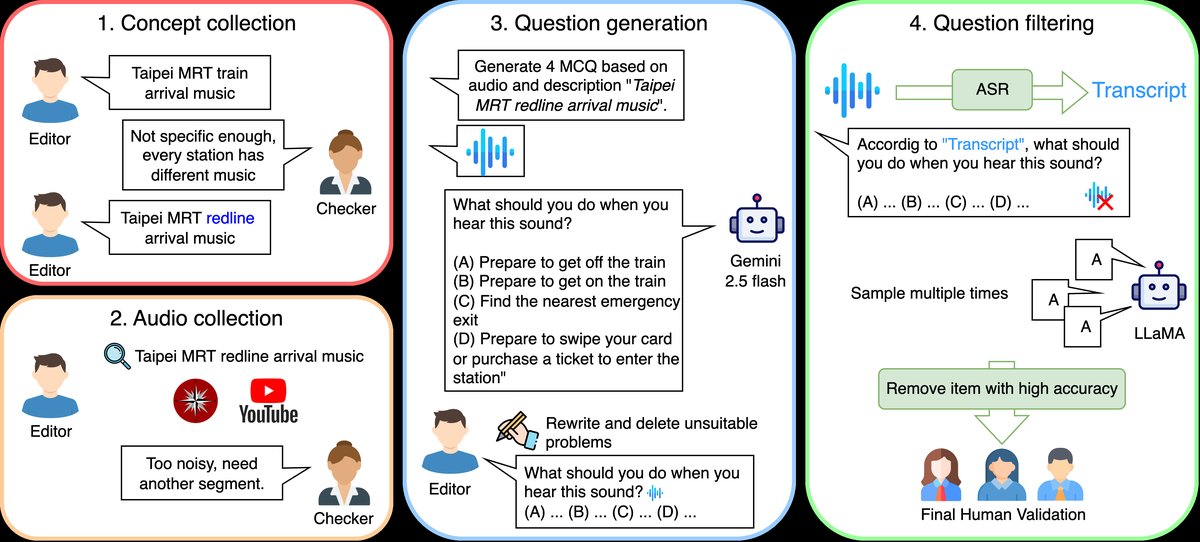 图1说明:该图展示了TAU基准的构建流程,包含概念收集、音频收集、问题生成和问题过滤四个主要阶段。这个流程确保了数据的文化相关性、音频质量和问题的非语义依赖性。
图1说明:该图展示了TAU基准的构建流程,包含概念收集、音频收集、问题生成和问题过滤四个主要阶段。这个流程确保了数据的文化相关性、音频质量和问题的非语义依赖性。
💡 核心创新点
- 定义并聚焦于“文化本地化音频理解”评估任务:创新性地提出了评估模型对“声音地标”的识别能力,这类声音基于文化暴露而非语言理解来识别。这填补了现有基准忽略文化特异性的空白。
- 构建无法通过文本语义解决的高质量评估集:通过严格的收集、编辑和过滤流程(使用ASR+LLM排除可文本解决的题目),确保评估项真正依赖于听觉感知和文化知识。
- 提出一套可复现的本地化基准构建流程:从概念收集到质量控制,论文详细描述了一个五阶段流水线,为其他社区构建类似的本地化评估基准提供了模板。
- 通过实验证明文化身份提示的局限性:实验结果表明,简单的提示工程不足以弥合模型与人类在文化理解上的巨大差距,为未来研究指明了方向(如需要文化信息注入训练)。
🔬 细节详述
- 训练数据:未说明。本文为评估基准,未涉及模型训练。
- 损失函数:未说明。本文为评估基准,未涉及模型训练。
- 训练策略:未说明。本文为评估基准,未涉及模型训练。
- 关键超参数:未说明。本文评估的是现有模型。
- 训练硬件:未说明。本文评估的是现有模型。
- 推理细节:对于被评估的LALM,使用其默认系统提示或指定的“文化身份”提示。模型输出通过Gemini-2.0-flash解析为四个选项之一。具体解码策略、温度等参数未说明。
- 数据集构建细节:
- 概念收集:由10名台湾本土标注员收集了550个“声音地标”候选。
- 音频收集:来源包括Creative Commons仓库和自录,每个目标声音包含最多3个不同背景的变体。初始收集943段音频。
- 问题生成:使用Gemini 2.5 Flash辅助生成初始选项,再由编辑人工精炼。问题分为“单跳”(单一声学线索可解)和“多跳”(需结合文化知识)。
- 问题过滤:使用Whisper-large-v3进行转录,然后使用LLaMA-3.1 8B在仅文本输入下尝试回答。通过t检验(p<0.05)剔除可通过文本显著超越随机水平的题目,最终保留702段音频和1,794个评估项。
- 评估细节:包含人类标注员评估(9人,双人评估,Fleiss’s κ = 0.72)作为性能上限。
📊 实验结果
实验设置:评估了多个LALM(Gemini 2.5 Pro/Flash, Qwen2-Audio, Qwen2.5-Omni, DeSTA2.5-Audio, Gemma-3n)、ASR+LLM基线(Whisper+LLaMA)和纯LLM基线(Qwen2.5-7B, LLaMA-3.1)。指标为多选题准确率(%)。
主要结果:实验在两个表格中给出了详细对比。
| 模型 | 参数量 | 单跳准确率 | 多跳准确率 |
|---|---|---|---|
| 表1:使用默认系统提示时的性能 | |||
| 随机 | - | 25.0 | 25.0 |
| Qwen2-Audio-Instruct | 8.2B | 30.3 | 27.8 |
| Gemma-3n-E4B-it | 6.8B | 29.0 | 25.9 |
| DeSTA2.5-Audio | 8.8B | 43.3 | 41.7 |
| Qwen2.5-Omni-7B | 7.6B | 46.4 | 46.1 |
| Gemini 2.5 Flash | - | 61.3 | 63.2 |
| Gemini 2.5 Pro | - | 72.4 | 73.9 |
| LLaMA-3.1 (ASR+LLM) | 9.6B | 34.9 | 34.1 |
| Qwen2.5-7B-Instruct (LLM) | 7.0B | 38.5 | 35.5 |
| 人类(顶线) | - | 84.0 | 83.3 |
| 表2:使用文化身份提示时的性能 | |||
|---|---|---|---|
| 随机 | - | 25.0 | 25.0 |
| Qwen2-Audio-Instruct | 8.2B | 29.0 | 27.1 |
| Gemma-3n-E2B-it | 4.4B | 29.7 | 29.4 |
| DeSTA2.5-Audio | 8.8B | 38.2 | 38.9 |
| Qwen2.5-Omni-7B | 7.6B | 43.6 | 42.3 |
| Gemini 2.5 Flash | - | 62.8 | 62.2 |
| Gemini 2.5 Pro | - | 70.6 | 71.8 |
| Gemma-3n-E4B-it | 6.8B | 34.0 | 33.4 |
| LLaMA-3.1 (ASR+LLM) | 9.6B | 34.7 | 31.8 |
| LLaMA-3.1 (LLM only) | 8.0B | 37.7 | 35.8 |
关键结论:
- 所有模型均显著低于人类表现,最强模型(Gemini 2.5 Pro)与人类仍有约10-12个百分点的差距。
- 文本基线(ASR+LLM, LLM only)的性能虽高于随机,但远低于最佳LALM,验证了大部分题目无法仅凭文本解答。
- 文化身份提示对不同模型影响不一:对顶级模型(Gemini)有轻微负面影响,对轻量级模型(Gemma-3n)有一定提升,说明提示工程效果有限且不稳定。
- “多跳”问题通常比“单跳”问题更具挑战性,尤其在较弱模型上差距明显。
数据集分布:
 图2说明:展示了来自媒体、交通和零售类别的三道多选题示例,直观体现了问题的文化特异性(如“台湾高铁”、“7-11门铃声”)和干扰项的设计逻辑。
图2说明:展示了来自媒体、交通和零售类别的三道多选题示例,直观体现了问题的文化特异性(如“台湾高铁”、“7-11门铃声”)和干扰项的设计逻辑。
图3说明:这是一个柱状图,显示了TAU基准中10个类别的题目数量分布,其中“交通”、“媒体”和“零售”类别数量最多,反映了数据集的构成。
⚖️ 评分理由
- 学术质量:6.0/7:作为一篇基准测试论文,其创新点明确(定义文化本地化音频评估任务),技术路径严谨(详细、可复现的构建流程),实验证据充分(对比了广泛的模型与人类,设计了合理的消融)。但创新类型属于“评估框架”而非“模型算法”,理论深度和技术挑战性相对有限。
- 选题价值:1.5/2:选题具有高度的前沿性和社会责任感,指向了AI公平性的一个关键盲点。对多模态和音频社区的研究方向有明确的引导意义。但应用场景相对集中于学术研究和模型评测。
- 开源与复现加成:0/1:论文提供了项目主页链接(
https://dlion168.github.io/TAU_demo/),但未明确说明代码开源、数据集访问方式(是直接下载还是需申请)、以及构建过程中使用的具体LLM提示词等细节。因此,完全复现其基准构建过程存在信息缺口。