📄 Task Vector in TTS: Toward Emotionally Expressive Dialectal Speech Synthesis
#语音合成 #流匹配 #零样本 #低资源 #情感方言
✅ 7.0/10 | 前50% | #语音合成 | #流匹配 | #零样本 #低资源
学术质量 5.8/7 | 选题价值 1.0/2 | 复现加成 0.2 | 置信度 高
👥 作者与机构
- 第一作者:未说明(作者列表标注“Pengchao Feng1,2∗, Yao Xiao1∗”为共同第一作者)
- 通讯作者:Xie Chen1,2†(上海交通大学X-LANCE实验室)
- 作者列表:Pengchao Feng(1上海交通大学X-LANCE实验室, 2上海创新研究院),Yao Xiao(1上海交通大学X-LANCE实验室),Ziyang Ma(1上海交通大学X-LANCE实验室),Zhikang Niu(1上海交通大学X-LANCE实验室, 2上海创新研究院),Shuai Fan(1上海交通大学X-LANCE实验室),Yao Li(3上海航空电器有限公司),Sheng Wang(1上海交通大学X-LANCE实验室, 3上海航空电器有限公司),Xie Chen(1上海交通大学X-LANCE实验室, 2上海创新研究院)
💡 毒舌点评
亮点在于其“分而治之”的策略,通过独立建模再分层整合,巧妙地绕过了缺乏方言情感联合标注数据的难题,并在实验上证明了其优于简单串联或直接合并的基线。短板则是该方法的泛化能力存疑,在对另一个主流TTS框架(CosyVoice)上尝试时效果不佳,暗示其可能过度依赖于特定的F5-TTS架构特性,通用性打了折扣。
🔗 开源详情
- 代码:论文中提供了代码仓库链接(https://the-bird-f.github.io/Expressive-Vectors)。
- 模型权重:未提及公开模型权重。
- 数据集:方言数据集为内部数据,未提及公开获取方式。情感数据集引用了公开的ESD。
- Demo:提供了在线演示页面(与代码链接相同)。
- 复现材料:给出了E-Vector和LoRA的关键超参数(α, r),但未提供完整的训练配置、检查点或附录。
- 论文中引用的开源项目:依赖于F5-TTS模型。此外,评估使用了Seed ASR和3D-Speaker模型。
📌 核心摘要
- 要解决什么问题:在语音合成领域,如何在缺乏大量方言与情感联合标注数据的情况下,生成同时具有特定方言口音和丰富情感表达的语音。
- 方法核心是什么:提出了一种两阶段方法“分层表达向量(HE-Vector)”。第一阶段,基于F5-TTS模型,通过微调并提取“任务向量”来独立构建表示方言和情感的“表达向量(E-Vector)”。第二阶段,设计了一个“分层合并策略”,将方言E-Vector应用于模型的文本嵌入层和早期DiT块(负责音素发音),将情感E-Vector应用于后期DiT块(负责韵律语调),从而在推理时融合两种风格。
- 与已有方法相比新在哪里:相比于直接合并不同风格的任务向量(会导致风格干扰)或采用双阶段流水线(易造成误差累积),该方法的核心创新在于提出了基于模型层功能分工的“分层整合”机制,使得方言和情感特征能更独立、更少干扰地被建模和融合,且无需联合标注数据。
- 主要实验结果如何:在方言合成任务上,E-Vector增强模型(α=3.0)在8个方言上的平均MOS达到3.18,显著优于CosyVoice2(2.62)和全量微调模型(1.85)。在情感方言合成任务上,HE-Vector框架取得最佳平均MOS(2.83),优于完全合并E-Vector(2.76)、双阶段流水线(2.56)和CosyVoice2(1.87)。具体MOS对比见下表:
| 方法 | 平均MOS (方言合成) | 平均MOS (情感方言合成) |
|---|---|---|
| CosyVoice2 | 2.62 | 1.87 |
| FT (微调) | 1.85 | 未提供 |
| FT-last (过度微调) | 2.85 | 未提供 |
| E-Vector (α=3.0) | 3.18 | 未提供 |
| LoRA E-Vector | 2.35 | 未提供 |
| Fully E-Vector | 未提供 | 2.76 |
| Dual-stage | 未提供 | 2.56 |
| HE-Vector (Ours) | 未提供 | 2.83 |
- 实际意义是什么:为低资源甚至零样本下的复杂表达性语音合成(如方言+情感)提供了一种数据高效的解决方案,有助于方言文化遗产保护和更自然的个性化语音交互。
- 主要局限性是什么:E-Vector的构建基于任务向量的线性缩放,而论文分析指出风格迁移的参数变化并非严格线性;该方法在其他TTS架构(如CosyVoice)上效果不佳,表明其通用性有限;实验中使用的方言和情感数据集部分为内部数据,未完全公开。
🏗️ 模型架构
本文提出的方法(HE-Vector)是一个两阶段的框架,旨在增强预训练TTS模型(F5-TTS)以实现可控的表达性语音合成。整体架构如图1所示。
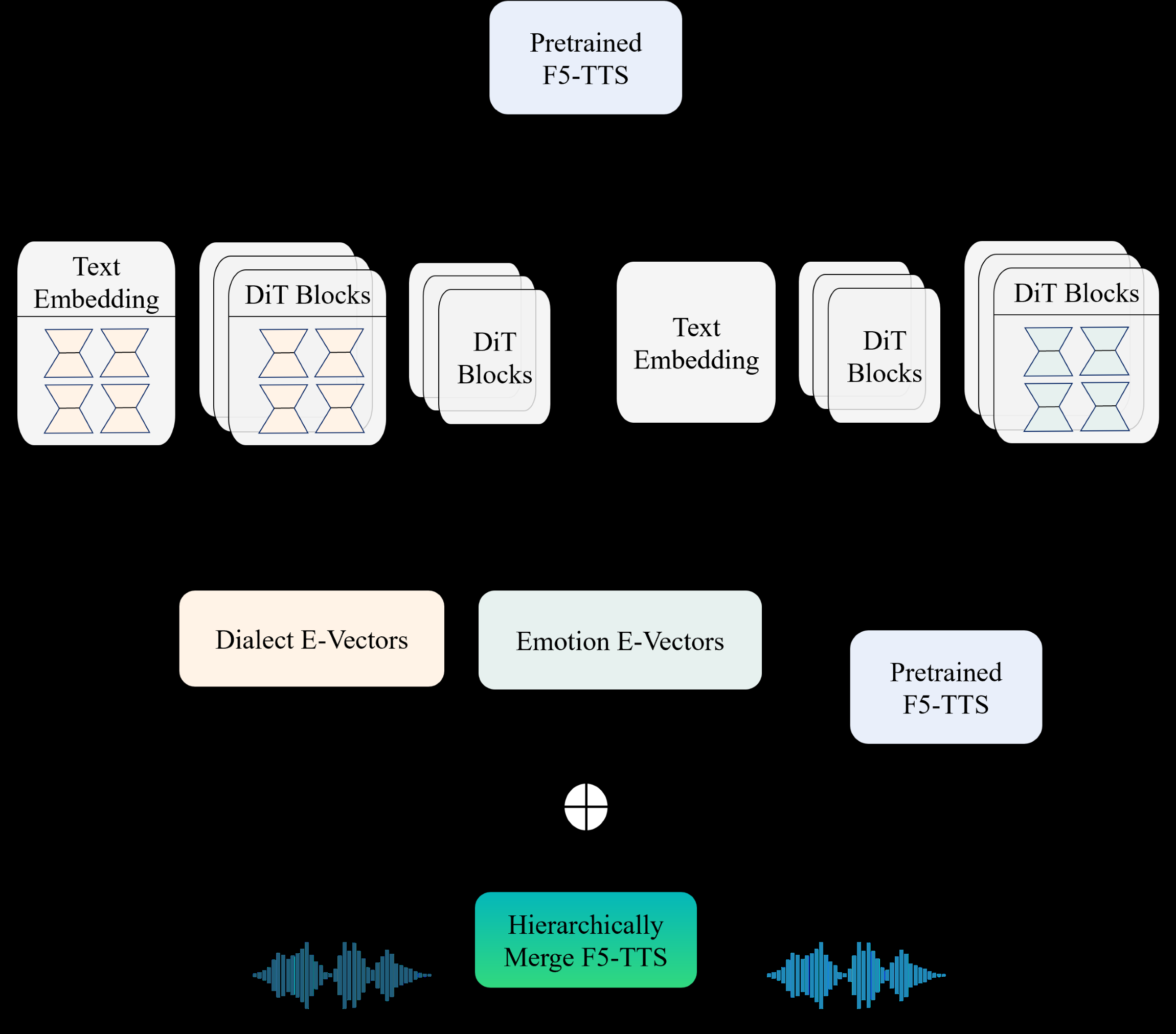
第一阶段:构建表达向量(E-Vector)
- 输入:预训练的F5-TTS模型参数θpre,以及针对单一风格(如某一种方言或某一种情感)的少量标注语音数据。
- 过程:在F5-TTS上进行适度微调,得到针对该风格的微调后模型参数θi。计算任务向量 τi = θi - θpre。然后,通过一个可调的增强系数α(对方言)或β(对情感)线性缩放该任务向量,得到表达向量 εi = α * τi。
- 输出:表示特定风格的表达向量εi。在推理时,将其加到预训练模型参数上(θ = θpre + εi),或更高效地,以LoRA形式插入模型,从而增强模型生成该特定风格语音的能力。这个过程类似于“无分类器引导(CFG)”的参数空间版本。
- 关键设计:利用了预训练模型参数空间的局部不敏感性和任务向量方向的一致性,使得对参数的微小扰动可以强化特定风格特征而不显著损害整体语音质量。对于连续变化的情感,β可在范围内调节以控制情感强度。
第二阶段:分层整合表达向量(HE-Vector)
- 输入:第一阶段分别构建的方言表达向量ε_dialect和情感表达向量ε_emotion。
- 过程:
- 完全合并策略(Baseline):直接将两个表达向量与预训练参数相加:θ = θpre + ε_dialect + ε_emotion。这种方法简单但易导致风格干扰和质量下降。
- 分层合并策略(Ours):根据模型不同层的功能进行分工整合。如图1(c)所示,将方言表达向量应用于模型的文本嵌入层和早期DiT块(负责建模音素、发音等与方言强相关的特征)。将情感表达向量应用于模型的后期DiT块(负责建模韵律、节奏、语调等与情感强相关的特征)。
- 输出:一个同时集成了方言和情感风格信息的增强模型,在推理时无需联合标注数据即可合成带有指定方言和情感的语音。分层设计旨在减少两种风格在表示和生成过程中的相互干扰。
总结:该架构的核心思想是解耦与重组。通过E-Vector将不同的表达风格解耦为独立的参数向量,再通过HE-Vector的分层策略将这些向量重组到模型的不同功能区域,从而实现灵活、可控且低干扰的多风格合成。
💡 核心创新点
- 提出表达向量(E-Vector):将任务向量的概念应用于语音合成中的主观风格建模(方言、情感)。通过对任务向量进行线性缩放,能有效增强和可控调整单一风格特征,且无需对整个模型进行全量微调,训练高效。
- 提出分层整合表达向量(HE-Vector)框架:为解决多风格(如方言+情感)合成中风格干扰和联合数据稀缺的问题,设计了基于模型层功能分工的分层合并策略。该策略是核心创新,它允许方言和情感特征在模型的不同区域独立生效,从而在不需联合标注数据的前提下实现高质量融合。
- 验证了任务向量在表达性TTS中的有效性与局限性:论文不仅展示了任务向量在低资源风格建模上的成功应用(相比全量微调更高效),还通过在其他TTS模型(CosyVoice)上的失败实验,指出了该方法对模型架构的依赖性,以及线性缩放假设的局限性,为后续研究提供了明确的改进方向。
🔬 细节详述
- 训练数据:
- 方言数据集:内部数据集,包含8种方言(天津、河南、广东、陕西、上海、湖南、四川、山东),每种方言约10小时语音及对应文本。训练/验证/测试集比例为8:1:1。
- 情感数据集:公开的Emotion Speech Dataset (ESD),包含四种情感(开心、悲伤、愤怒、惊讶),时长分别为5.38h, 6.83h, 5.33h, 5.88h。划分比例同为8:1:1。
- 评估数据:使用了CV3-Eval的子集。
- 损失函数:论文中未具体说明。
- 训练策略:
- 预训练模型:F5-TTS(基于流匹配和DiT架构的零样本TTS模型)。
- 微调步数:对于方言的E-Vector构建,全量微调进行了60k步(FT);对比组进行了约340k步直至验证损失平台期(FT-last)。
- LoRA配置:使用LoRA进行参数高效微调,秩(r)设置为8,插入模块为全量微调时参数变化最大的层。
- 增强系数:方言E-Vector的全量微调版本α=3.0,LoRA版本α=1.12(基于验证集主观结果选择)。情感E-Vector的强度系数β在[0, βmax]范围内可调。
- 关键超参数:未提供模型大小(参数量)、DiT层数、隐藏维度等具体架构参数。
- 训练硬件:未说明。
- 推理细节:基于流匹配的采样过程,具体采样步数、调度策略等未说明。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文主要评估了两个任务:1)纯方言合成;2)情感方言合成。
- 方言合成任务(使用普通话文本提示)
| 方法 | 平均MOS (↑) | 平均WER (%)* (↓) | 平均SIM-O (↑) |
|---|---|---|---|
| GT (Ground Truth) | 3.69 | 16.59 | - |
| CosyVoice2 | 2.62 | 14.49 | 0.63 |
| FT (微调60k步) | 1.85 | 9.04 | 0.72 |
| FT-last (微调340k步) | 2.85 | 7.43 | 0.65 |
| E-Vector (α=3.0) | 3.18 | 15.41 | 0.65 |
| LoRA E-Vector (r=8) | 2.35 | 18.58 | 0.70 |
| *注:WER评估仅涵盖部分方言,因ASR工具限制。 |
- 关键结论:E-Vector模型在平均MOS上(3.18)表现最佳,超越了在大规模数据上训练的CosyVoice2(2.62),甚至接近部分方言的原始录音质量(GT)。这证明了E-Vector在利用有限数据高效提升方言合成质量上的优势。LoRA版本性能较低,但在参数效率和多风格共存上有优势。WER和SIM-O指标表明E-Vector未损害语音可懂度和说话人相似性。
- 情感方言合成任务(使用普通话参考音频+目标方言和情感标签)
| 方法 | 平均MOS (↑) |
|---|---|
| CosyVoice2 | 1.87 |
| Dual-stage (流水线) | 2.56 |
| Fully E-Vector (完全合并) | 2.76 |
| HE-Vector (分层合并, Ours) | 2.83 |
- 关键结论:HE-Vector取得了最佳的平均MOS(2.83),显著优于CosyVoice2(1.87),也优于直接完全合并E-Vector的方法(2.76)。这验证了分层整合策略的有效性。值得注意的是,即使表现最好的方法,其MOS(2.83)也低于纯方言合成任务(3.18),表明同时控制多种风格仍然是一个极具挑战性的问题。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:良好。将任务向量应用于表达性TTS,并提出分层整合策略,思路清晰且有针对性。
- 技术正确性:较好。方法设计有理论依据(任务向量特性、模型层功能假设),实验对比合理。
- 实验充分性:中等偏上。对比了多种基线(CosyVoice2、不同微调策略、合并策略),并在主观(MOS)和客观(WER,SIM-O)指标上进行了评估。但部分关键训练细节缺失,且在情感方言任务上仅提供了MOS。
- 证据可信度:中等。实验基于内部方言数据集和公开情感数据集,结果具有一定的参考价值。但缺乏对更广泛方言和更复杂情感的验证。
- 选题价值:1.0/2
- 前沿性:在TTS的表达性控制领域,尤其是结合方言和情感的多风格合成,是一个值得探索的前沿问题。
- 潜在影响与应用空间:在方言保护、无障碍通信、个性化语音助手、影视游戏配音等领域有应用潜力,但市场相对垂直。
- 读者相关性:对专注于语音合成、风格迁移、低资源学习的研究人员有直接价值。
- 开源与复现加成:0.2/1
- 论文提供了代码仓库和Demo页面的链接(https://the-bird-f.github.io/Expressive-Vectors),这是一个重要的加分项。
- 然而,核心的训练数据集(内部方言数据集)未公开,预训练模型权重和训练细节(如完整超参数)也未完全披露,这给完全复现带来了障碍。