📄 Task-Oriented Sound Privacy Preservation for Sound Event Detection Via End-to-End Adversarial Multi-Task Learning
#音频事件检测 #对抗学习 #多任务学习 #隐私保护 #端到端
✅ 7.5/10 | 前25% | #音频事件检测 | #对抗学习 | #多任务学习 #隐私保护
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Nao Sato (NTT, Inc., Japan)
- 通讯作者:未说明(论文中未明确指定通讯作者)
- 作者列表:Nao Sato (NTT, Inc., Japan), Masahiro Yasuda (NTT, Inc., Japan), Shoichiro Saito (NTT, Inc., Japan)
💡 毒舌点评
亮点是提出了一个灵活且可扩展的“任务导向”框架,将隐私保护从固定的信号处理流程转变为可通过改变训练任务(隐私目标)来定制的学习过程,思路巧妙。短板在于所有实验均基于自建的、场景相对可控的合成数据集,这虽然能验证方法原理,但离真实世界中复杂、非结构化的声学环境和攻击场景还有距离,说服力略打折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:未提及公开其构建的合成数据集。论文中引用了VoxCeleb1, FSD50K, DCASE2025 Task 4等公开数据集作为其合成数据的来源。
- Demo:未提供在线演示。
- 复现材料:论文正文和附录(未提供,但正文中描述详细)给出了非常详尽的训练细节、超参数设置和模型规格,具备良好的可复现文本指南。
- 论文中引用的开源项目:
- 演唱声分离U-Net [23]:Jansson et al., 2017.
- 说话人识别CNN [24]:Nagrani et al., 2017.
- 梯度反转层(GRL)[22]:Ganin & Lempitsky, 2015.
- CRNN用于SED [25]:Cakir et al., 2017.
- SI-SDR度量 [26]:Erdogan et al., 2019.
- 整体开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:声音事件检测(SED)在智能家居等场景的应用需要持续录音,这会导致说话人身份、键盘敲击声等隐私信息泄露。现有方法多集中于分离并处理语音,不够灵活,无法保护非语音的隐私信息,且混淆机制依赖手动设计。
- 方法核心:提出端到端对抗多任务学习(EAML)。其核心是一个混淆网络(OBFNet),通过对抗训练(梯度反转层GRL)学习一个时频掩膜,在混淆指定隐私信息(如说话人ID、键盘声)的同时,保留完成目标任务(如SED)所需的声音信息。
- 与已有方法相比新在哪里:与传统两阶段(先分离再信号处理)方法相比,EAML是端到端可学习的。最关键的是,它实现了“任务导向”的混淆:隐私保护的目标不再是固定的(仅限语音),而是可以作为训练任务之一,通过改变训练配置(如表1的T1-T3)灵活定义需要混淆的信息类型和需要保留的目标信息。
- 主要实验结果:实验在包含7类声音事件的合成数据集上进行。如表2所示,在T1配置下,EAML在混淆说话人身份(ASI)上达到了最接近随机猜测的性能(Top-1准确率0.11%),同时SED性能(F-score)仅比未混淆的基线(87.40%)下降约4.5个百分点(82.88%),显著优于传统方法(D和E)。如表3所示,EAML在T2配置中通过引入SI-SDR损失,将音频质量(SI-SDR)从-20.35 dB提升至-16.78 dB,同时不影响其他任务。在T3配置中,成功将键盘打字检测(TAD)的AUC从0.99降至0.72。
- 实际意义:为隐私敏感的音频应用(如家庭监控、办公环境感知)提供了一种新的、灵活的技术范式。用户可根据具体场景定义“何为隐私”和“何为有用信息”,系统通过学习来平衡二者。
- 主要局限性:研究基于精心构建的合成数据,可能无法完全代表真实场景的复杂性;对“隐私”的定义和攻击模型相对简单,仅评估了预定义分类器的识别性能,未考虑更强大的攻击者或更广泛的隐私属性;混淆导致目标任务性能有一定程度的下降。
🏗️ 模型架构
EAML的整体架构围绕一个核心的混淆网络(OBFNet)和多个任务网络展开,通过对抗学习和多任务损失联合训练。
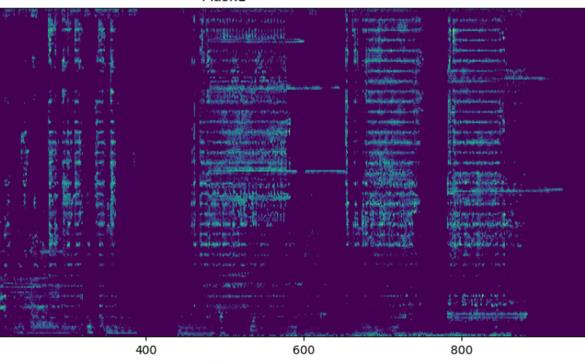 图1. EAML架构示意图(对应表1中T3配置:TAD和ASI为混淆任务,SED为目标任务)。图中展示了数据流与训练梯度路径。
图1. EAML架构示意图(对应表1中T3配置:TAD和ASI为混淆任务,SED为目标任务)。图中展示了数据流与训练梯度路径。
完整输入输出流程:
- 输入:原始音频信号
s,经过STFT转换为幅度谱图S ∈ R^{F×T}。 - 混淆路径:幅度谱
S输入OBFNet,生成一个时频掩膜M。通过M与S的逐元素相乘(⊙),得到混淆后的谱图S_obf = S ⊙ M。这等价于在频域对信号进行滤波或掩蔽。 - 任务路径:混淆后的谱图
S_obf(或其逆变换后的波形)被分别送入:- 混淆任务网络(攻击者):如自动说话人识别(ASI)网络、键盘打字活动检测(TAD)网络。其目标是识别应被保护的信息(
y^o_i)。 - 目标任务网络(用户):如声音事件检测(SED)网络、音频质量评估(计算SI-SDR)。其目标是完成用户指定的任务(
y^t_i)。
- 混淆任务网络(攻击者):如自动说话人识别(ASI)网络、键盘打字活动检测(TAD)网络。其目标是识别应被保护的信息(
- 输出:混淆后的音频信号,以及各任务网络的预测结果。
主要组件与交互:
- OBFNet (混淆网络):采用为歌声分离设计的U-Net架构。它是整个系统的“混淆器”,其参数
θ_O的优化方向由对抗损失和目标任务损失共同决定。其设计动机是U-Net在音频分离任务上的有效性。 - 梯度反转层 (GRL):插入在OBFNet与混淆任务网络之间。这是实现对抗学习的关键。在反向传播时,GRL会将来自混淆任务损失
L^i_A的梯度乘以一个负系数(如-λ),再传递给OBFNet。这迫使OBFNet生成的混淆信号,能使混淆任务网络的性能变差(即混淆隐私信息)。 - 任务网络:
- ASI网络:采用预训练的CNN(参考[24]),用于说话人识别。
- SED网络与TAD网络:均采用卷积循环神经网络(CRNN),由CNN块、双向GRU和全连接层构成。SED是多标签分类(7类),TAD是单标签二分类(检测打字声)。
- 损失函数与优化目标:
- 对抗目标(Eq. 6):通过GRL实现。优化目标是
min_{θ_O} max_{θ^i_A} ΣL^i_A。在实现中,OBFNet试图最大化混淆任务损失(因为梯度被反转),而混淆任务网络则试图最小化该损失(常规梯度)。 - 保留目标(Eq. 7):优化目标是
min_{θ_O, θ^i_T} ΣL^i_T。OBFNet与目标任务网络协同优化,以最小化目标任务损失。 - 总损失(Eq. 9):
L_total = Σ_{i=1}^M L^i_T + Σ_{i=1}^N λ^i_w L^i_A。通过加权和将两个冲突目标统一在一个端到端训练框架中。λ^i_w是关键超参数,用于平衡隐私混淆强度和目标任务性能保留。
- 对抗目标(Eq. 6):通过GRL实现。优化目标是
关键设计选择:
- 在频域掩蔽而非波形域处理:直接操作谱图在计算上更高效,且更容易通过掩膜影响特定频段(如语音的谐波结构),从而针对性地破坏身份信息。
- 任务导向的灵活配置:通过简单地更改参与训练的任务网络(增加/删除TAD或ASI网络),系统即可针对不同的应用需求(保护说话人ID、保护键盘声、保留音频质量)进行训练,无需重新设计核心架构。
💡 核心创新点
- 提出“任务导向”的声音隐私保护范式:突破了以往方法固定混淆语音的局限。将“什么需要被混淆”和“什么需要被保留”明确定义为学习任务,使隐私保护策略变得可配置、可学习,适应不同应用场景。
- 端到端对抗多任务学习(EAML)框架:将混淆网络(OBFNet)、混淆任务(攻击者)和目标任务(用户)集成到一个统一的端到端训练流程中。利用对抗学习(GRL)天然适合解决“混淆-反识别”的对抗关系,并与目标任务学习协同优化,避免了多阶段方法(如先分离再处理)的信息损失和误差累积。
- 处理非语音隐私信息的能力:首次在ASA领域的隐私保护中,将非语音声音(如键盘敲击声)也视为需要保护的隐私信息,并通过增加相应的混淆任务(TAD)成功地实现了对这类信息的混淆,展示了框架的扩展性。
- 多任务损失平衡与控制:通过精心设计的总损失函数(Eq. 9)和损失权重(
λ^i_w),使用户可以在隐私保护强度和任务效用之间进行定量权衡。实验结果(如表3)证明,通过调整训练目标(增加SI-SDR任务或TAD混淆任务),可以按预期控制各任务的性能表现。
🔬 细节详述
- 训练数据:论文构建了一个合成数据集。包含7类声音事件(语音、键盘、拍手、电话、脚步、水龙头、乐器),每段10秒,最多3个事件重叠。语音来自VoxCeleb1(1251位说话人),键盘声来自DCASE2025 Task 4,其余来自FSD50K。训练/验证/测试集划分:7506/2502/1251条。数据增强未提及。
- 损失函数:
L^1_A(ASI损失):交叉熵损失(CE Loss)。L^1_T(SED损失):二元交叉熵损失(BCE Loss)。L^2_A(TAD损失):二元交叉熵损失(BCE Loss)。L^2_T(音频质量损失,T2配置):缩放不变信号失真比(SI-SDR Loss),计算原始信号S与混淆信号S_obf之间的失真,值越大表示质量越好。λ^i_w:损失权重。T1/T2中λ^1_w=0.1;T3中λ^1_w=0.1,λ^2_w=0.3。
- 训练策略:
- 优化器:OBFNet和SED网络使用Adam优化器,学习率0.001。ASI网络使用带动量的SGD优化器,学习率5e-4,动量0.90,权重衰减1e-5。
- 训练步数/轮数:T1和T2训练150个epoch,T3训练200个epoch。
- 调度策略:GRL层的缩放因子α从0线性增加到1,以稳定对抗训练初期。在T2中,SI-SDR损失的权重从epoch 20的0线性增加到epoch 25的5e-4,之后保持不变。
- Batch size:ASI预训练/微调64,SED预训练/微调及T1/T2为32,T3为24。
- 关键超参数:
- 模型参数量:SED ~0.50M,ASI ~17.91M,OBFNet ~9.82M。
- 输入特征:16kHz采样率,STFT窗长25ms,步长10ms,汉宁窗。频谱图归一化处理。
- GRL调度参数α:设置为25。
- 训练硬件:未说明。
- 推理细节:未提及特殊解码策略,直接使用训练好的OBFNet生成掩膜对输入谱图进行掩蔽,然后送入各任务网络进行评估。
- 正则化或稳定训练技巧:除了使用GRL和线性调度外,未明确提及 dropout、权重衰减等额外正则化技巧(ASI网络训练中使用了权重衰减)。
📊 实验结果
实验在自建合成数据集上,评估了三个任务配置(T1-T3)。
表2. T1配置下的性能对比(仅混淆ASI)
| 条件 | 目标任务 | 混淆任务 | ASI Top1 Acc.[%] | ASI Top5 Acc.[%] | ASI Top20 Acc.[%] | SED F(All)[%] | SED F(Speech)[%] |
|---|---|---|---|---|---|---|---|
| (A) Only SED | SED (7cls) | - | - | - | - | 87.40±0.11 | 96.28±0.05 |
| (B) Only ASI | - | - | 29.44±0.73 | 53.64±0.94 | 73.83±0.49 | - | - |
| (C) Random ASI | - | - | 0.08 | 0.40 | 1.60 | - | - |
| (D) Oracle sep.+Lowpass [8] | SED (7cls) | ASI | 0.19±0.21 | 0.56±0.23 | 2.11±0.20 | 87.80±0.01 | 87.86±0.12 |
| (E) Oracle sep.+MFCC inv.[8] | SED (7cls) | ASI | 0.37±0.010 | 1.89±0.16 | 6.53±0.48 | 88.03±0.06 | 96.00±0.04 |
| (F-T1) EAML | SED (7cls) | ASI | 0.11±0.05 | 0.40±0.08 | 1.68±0.32 | 82.88±0.37 | 94.88±0.19 |
结论:EAML (F-T1) 在混淆说话人身份(ASI准确率)上达到了最接近随机猜测(C)的水平,显著优于传统信号处理方法(D, E)。同时,其SED性能(F-score)虽然略低于直接处理原始数据的基线(A),但优于将语音严重扭曲的Lowpass方法(D),与MFCC逆变换方法(E)在保留语音事件检测上竞争力相当。
表3. 不同任务配置下EAML的性能(任务导向灵活性验证)
| 条件 | 目标任务 | 混淆任务 | ASI Top1 Acc.[%] | ASI Top5 Acc.[%] | ASI Top20 Acc.[%] | SED F(All)[%] | SED F(Speech)[%] | TAD AUC | SI-SDR [dB] |
|---|---|---|---|---|---|---|---|---|---|
| (F-T1) EAML | SED (7cls) | ASI | 0.11±0.05 | 0.40±0.08 | 1.68±0.32 | 82.88±0.37 | 94.88±0.19 | 0.99±0.00 | -20.35±3.32 |
| (F-T2) EAML | SED (7cls), Quality | ASI | 0.11±0.12 | 0.56±0.14 | 2.26±0.09 | 83.33±0.19 | 94.67±0.10 | - | -16.78±2.25 |
| (F-T3) EAML | SED (6cls) | ASI, TAD | 0.11±0.05 | 0.43±0.12 | 1.57±0.09 | 72.13±1.83 | 91.97±0.68 | 0.72±0.07 | - |
结论:
- 在所有配置中,说话人混淆(ASI)均成功(准确率接近随机水平)。
- T2配置引入SI-SDR损失后,音频质量(SI-SDR)显著提升(+3.57 dB),而SED和ASI性能基本保持不变,证明了多任务平衡的有效性。
- T3配置引入TAD作为混淆任务后,键盘打字检测的AUC从T1的0.99大幅下降至0.72(随机基线为0.5),表明系统成功学习了混淆打字声。但代价是SED总体F-score下降较多(从82.88%降至72.13%),论文指出这是因为“电话”和“拍手”声与打字声在频谱和瞬态特性上相似,导致混淆。
图2(对应pdf-image-page4-idx2): 混淆效果频谱图对比
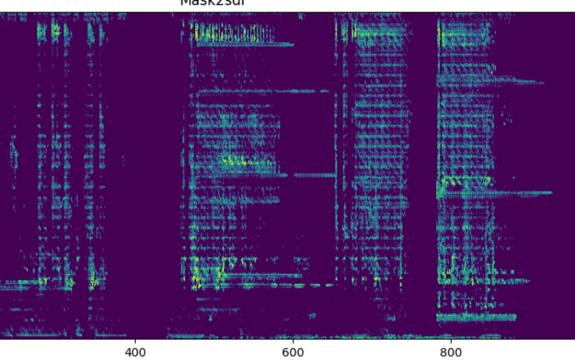 左:原始信号频谱,包含清晰的语音谐波结构。中:F-T1配置(无SI-SDR损失)的混淆后频谱,区域(a)显示语音的谐波结构被有效抹平,旨在破坏说话人身份信息。右:F-T2配置(有SI-SDR损失)的混淆后频谱,区域(b)显示非目标事件(如电话声)的细节保留得比F-T1更好,表明音频质量损失有助于维持信号的整体结构。
左:原始信号频谱,包含清晰的语音谐波结构。中:F-T1配置(无SI-SDR损失)的混淆后频谱,区域(a)显示语音的谐波结构被有效抹平,旨在破坏说话人身份信息。右:F-T2配置(有SI-SDR损失)的混淆后频谱,区域(b)显示非目标事件(如电话声)的细节保留得比F-T1更好,表明音频质量损失有助于维持信号的整体结构。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:提出了任务导向的声音隐私保护新范式,并实现了灵活的端到端对抗多任务学习框架,思想新颖且有扩展性。
- 技术正确性:方法描述清晰,模型架构和损失函数设计合理,对抗训练的实现方式(GRL)是标准做法。
- 实验充分性:通过精心设计的三个任务配置(T1-T3)验证了框架的灵活性和有效性;与基线方法(A)和传统方法(D, E)进行了定量对比;提供了消融性质的配置对比(如T1 vs T2, T1 vs T3)。
- 证据可信度:实验结果(表2、3)数据详实,并与频谱图(图2)的定性分析相互印证。但所有实验均在自建合成数据集上进行,可能限制结论的泛化性,这是主要扣分点。
- 选题价值:1.5/2
- 前沿性:声音隐私保护是当前音频和AI伦理研究的热点之一,任务导向的思路具有前瞻性。
- 潜在影响:为各类需要处理声音的智能设备(智能家居、办公室监控)提供了新的隐私保护技术选项。
- 实际应用空间:直接针对现实中的隐私合规需求,应用前景明确。
- 读者相关性:对从事音频安全、人机交互、智能感知的研究者和工程师有较高参考价值。
- 开源与复现加成:0.3/1
- 优点:论文提供了详细的实现细节(网络结构、损失、超参数、训练流程),可复现性较高。
- 缺点:未提供代码、模型权重或合成数据集的下载链接。对于依赖复杂数据集和特定模型架构的研究,这增加了社区独立复现的难度。