📄 TAGARELA - A Portuguese Speech Dataset from Podcasts
#语音识别 #语音合成 #数据集 #预训练 #低资源
✅ 7.0/10 | 前25% | #语音识别 #语音合成 | #预训练 | #语音识别 #语音合成
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Frederico Santos de Oliveira(Federal University of Mato Grosso (UFMT))
- 通讯作者:未说明
- 作者列表:Frederico Santos de Oliveira (UFMT), Lucas Rafael Stefanel Gris (UFG), Alef Iury Siqueira Ferreira (UFG), Augusto Seben da Rosa (UNESP), Alexandre Costa Ferro Filho (UFG), Edresson Casanova (NVIDIA), Christopher Dane Shulby (Elsa Speak), Rafael Teixeira Sousa (UFMT), Diogo Fernandes Costa Silva (UFG), Anderson da Silva Soares (UFG), Arlindo Rodrigues Galvão Filho (UFG)
💡 毒舌点评
这篇论文在解决“数据饥饿”问题上做得非常扎实,为葡萄牙语社区贡献了一个规模空前(近9000小时)且处理精细的语音数据集,其多阶段处理流水线的工程设计体现了对实际数据挑战的深刻理解。然而,其核心创新更偏向于工程集成与数据处理,而非算法突破;此外,部分关键转录步骤依赖商业闭源服务,这为追求完全开源复现的研究者设置了一定的门槛。
🔗 开源详情
- 代码:论文中未提及完整的处理流水线代码仓库链接。
- 模型权重:提及提供了训练好的重叠检测模型和��噪模型(基于Vocos)的检查点用于下载。还提及了ASR/TTS实验中使用的模型,如Parakeet v2 FT, Orpheus-TTS, Chatterbox等,部分模型本身为开源项目。
- 数据集:公开。论文明确声明TAGARELA数据集已公开发布,并提供了访问地址:https://freds0.github.io/TAGARELA/。
- Demo:论文中未提及在线演示。
- 复现材料:提供了处理流水线的高层次描述、数据集统计信息和模型评估结果。提供了用于特定步骤(重叠检测、降噪)的模型检查点。但缺少详细的超参数配置、训练日志等深度复现材料。
- 论文中引用的开源项目:pyannote.audio(说话人分离)、Wav2vec2-XLS-R(重叠检测、转录一致性检查)、Whisper large-v3(转录)、Vocos(降噪)、RedimNet B6(说话人嵌入)、HDBSCAN(聚类)、wav2vec-base(方言分类)。
📌 核心摘要
- 要解决的问题:葡萄牙语作为全球广泛使用的语言,缺乏像英语那样大规模、高质量的公开语音数据集,这严重制约了葡萄牙语自动语音识别和文本转语音技术的发展。
- 方法核心:作者从“Cem Mil Podcasts”原始语料出发,设计并实施了一个多阶段数据处理流水线。该流水线包括音频标准化、说话人分离、基于模型的重叠语音检测与过滤、基于商业ASR种子语料的自举式转录(微调Whisper生成伪标签),以及最后的音频增强(降噪)。
- 与已有方法相比新在哪里:相比于已有的小规模葡萄牙语语料(如CORAA,290小时),TAGARELA在规模上实现了量级飞跃(8972小时),并且通过精细的流水线显著提升了音频和转录质量,使其同时适用于ASR和通常需要更干净音频的TTS任务。
- 主要实验结果:
- ASR:在TAGARELA测试集上,微调后的Parakeet v2模型取得最佳性能,WER为15.18%,CER为7.09%。
- TTS:使用2800小时干净子集训练的Orpheus-TTS和Chatterbox模型,在生成语音的可懂度和自然度上与真实语音差距较小。
- 数据质量客观评估:使用无参考指标(STOI, PESQ, SI-SDR)评估了降噪后的音频质量。
- 实验结果表格见下文详细分析。
- 实际意义:TAGARELA数据集的发布,为葡萄牙语语音技术研究提供了一个可与顶级英语数据集媲美的基准资源,有望大幅推动该语言领域ASR和TTS模型性能的提升。
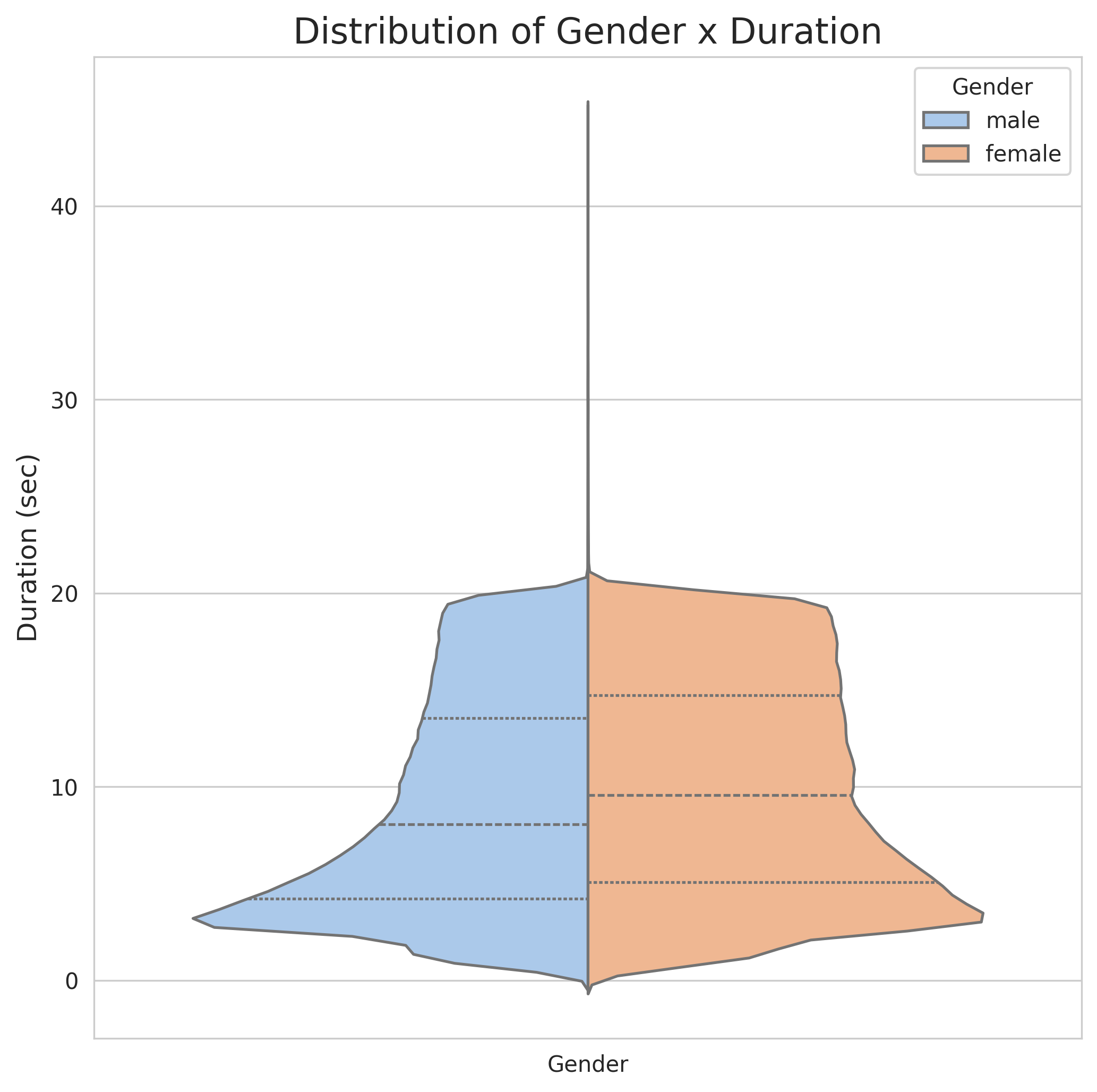
- 主要局限性:论文承认数据集在文本-音频对齐方面仍有改进空间;部分转录步骤依赖商业API;性别分布上男性语音占比较大(70%)。
🏗️ 模型架构
本文的核心“模型”是TAGARELA数据构建流水线(见图1),而非一个用于端到端推理的神经网络模型。该流水线是一个多阶段的串联系统,旨在将原始的播客音频转化为高质量的语音-文本对数据集。
- 输入与初始化:原始的“Cem Mil Podcasts”音频(~76,000小时,未经处理)。
- 音频标准化与分割:将所有音频统一格式为FLAC, 16kHz, 16-bit, 单声道。随后将长录音分割成5-20秒的片段,并尽量在自然停顿处分割。
- 说话人分离:使用
pyannote.audio框架进行说话人日志,识别并标记每个说话人的语音段,确保每个最终片段主要包含一个说话人。 - 重叠语音检测:训练一个基于
Wav2vec2-XLS-R的二分类模型,专门检测片段中是否存在多人同时说话的重叠情况。所有被标记为重叠的片段被丢弃。 - 降噪/语音增强:使用一个经过微调的Vocos声码器作为去噪器,去除背景噪声、嘶嘶声和轻微混响,提升音频清晰度。
- 转录:采用两阶段自举策略。首先,用商业ASR(ElevenLabs Scribe v12)转录约1000小时数据作为“种子语料”。然后,用该种子语料微调
Whisper large-v3模型,并用其为剩余所有数据生成伪标签。同时,训练一个Wav2vec2-XLS-R模型在相同种子数据上,通过计算两个模型输出之间的WER/CER来筛选出高一致性的转录结果,以保证质量。 - 说话人与方言标注:通过提取音频嵌入(使用RedimNet B6)并聚类(HDBSCAN)为每个片段分配说话人ID。另外,训练一个方言分类器(基于wav2vec-base)来标注片段是巴西葡萄牙语还是欧洲葡萄牙语。
- 输出:最终得到两个子集:包含不流畅语音的完整8972小时集(适用于鲁棒ASR),以及精选的2800小时干净语音子集(适用于TTS)。
💡 核心创新点
- 大规模、高质量葡萄牙语音频数据集的构建:这是最核心的贡献。在葡萄牙语领域首次提供了近万小时、经过专业处理的播客语音数据,填补了资源空白。
- 多阶段自动化处理流水线:设计了一个从原始音频到最终数据集的完整、自动化的工程流水线,综合运用了说话人分离、重叠检测、降噪等多种技术,系统地解决了播客音频的噪声、多说话人等挑战。
- 自举式混合转录策略:结合了商业高质量ASR(种子生成)和开源模型(大规模伪标签生成)的优势,并通过双模型一致性检验来过滤转录错误,在保证质量的同时实现了大规模转录的可行性。
- 双子集设计:有意识地将数据集划分为“完整版”(用于鲁棒ASR)和“干净版”(用于TTS),更精细地适配不同下游任务的需求,体现了对实际应用场景的考量。
🔬 细节详述
- 训练数据:
- 源数据:“Cem Mil Podcasts”集合,包含约16,806集、2,094个节目,原始音频超过76,000小时。
- 最终规模:8,972小时(巴西葡萄牙语8,130小时,欧洲葡萄牙语842小时)。
- 预处理:如流水线所述,经历了格式转换、分割、分离、重叠过滤、降噪、转录等。
- 数据增强:未明确提及传统数据增强(如速度扰动),但降噪本身可视为一种增强。
- 损失函数:论文中未说明。文中涉及的训练模型(如重叠检测器、方言分类器、Whisper微调)的损失函数未在本文详细描述。
- 训练策略:
- ASR模型训练:在TAGARELA全集上微调Distil-Whisper, Parakeet TDT v2, Wav2Vec Large。未提及具体超参数。
- TTS模型训练:在TAGARELA 2800小时干净子集上训练Orpheus-TTS和Chatterbox。未提及具体超参数。
- 关键超参数:论文中未提供。
- 训练硬件:ASR实验使用了NVIDIA A100或B200 GPU,具体配置未说明。
- 推理细节:ASR和TTS推理的具体解码策略(如beam search大小)未说明。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文通过ASR和TTS两项任务验证数据集有效性。
表1:TAGARELA测试集上的WER结果(ASR任务)
| 模型 | WER (%) ↓ | CER (%) ↓ |
|---|---|---|
| Whisper Large V3 | 20.91 | 12.42 |
| Wav2Vec Large FT | 21.85 | 8.55 |
| Distil-Whisper FT | 20.02 | 11.18 |
| Parakeet v3 | 23.30 | 14.86 |
| Parakeet v2 FT | 15.18 | 7.09 |
- 关键结论:在TAGARELA自身测试集上,微调后的Parakeet v2性能最佳,显著优于作为基线的Whisper Large V3等预训练模型,证明了数据集能够有效训练出高性能ASR模型。
表2:TTS模型性能
| 模型 | WER (%) ↓ | CER (%) ↓ | MOS ↑ |
|---|---|---|---|
| Chatterbox | 0.3111 ± 0.442 | 0.268 ± 0.423 | 4.176 ± 0.983 |
| Orpheus-TTS | 0.095 ± 0.100 | 0.046 ± 0.051 | 4.155 ± 1.001 |
| Ground Truth | 0.010 ± 0.033 | 0.006 ± 0.018 | 4.231 ± 1.001 |
- 关键结论:Orpheus-TTS生成的语音可懂度更高(WER更低),而Chatterbox在自然度(MOS)上略胜一筹。两者与真实语音的MOS差距都很小,表明用TAGARELA可以训练出高质量的TTS模型。可懂度上的差距可能与文本-音频对齐有关。
数据质量客观评估图(图3)
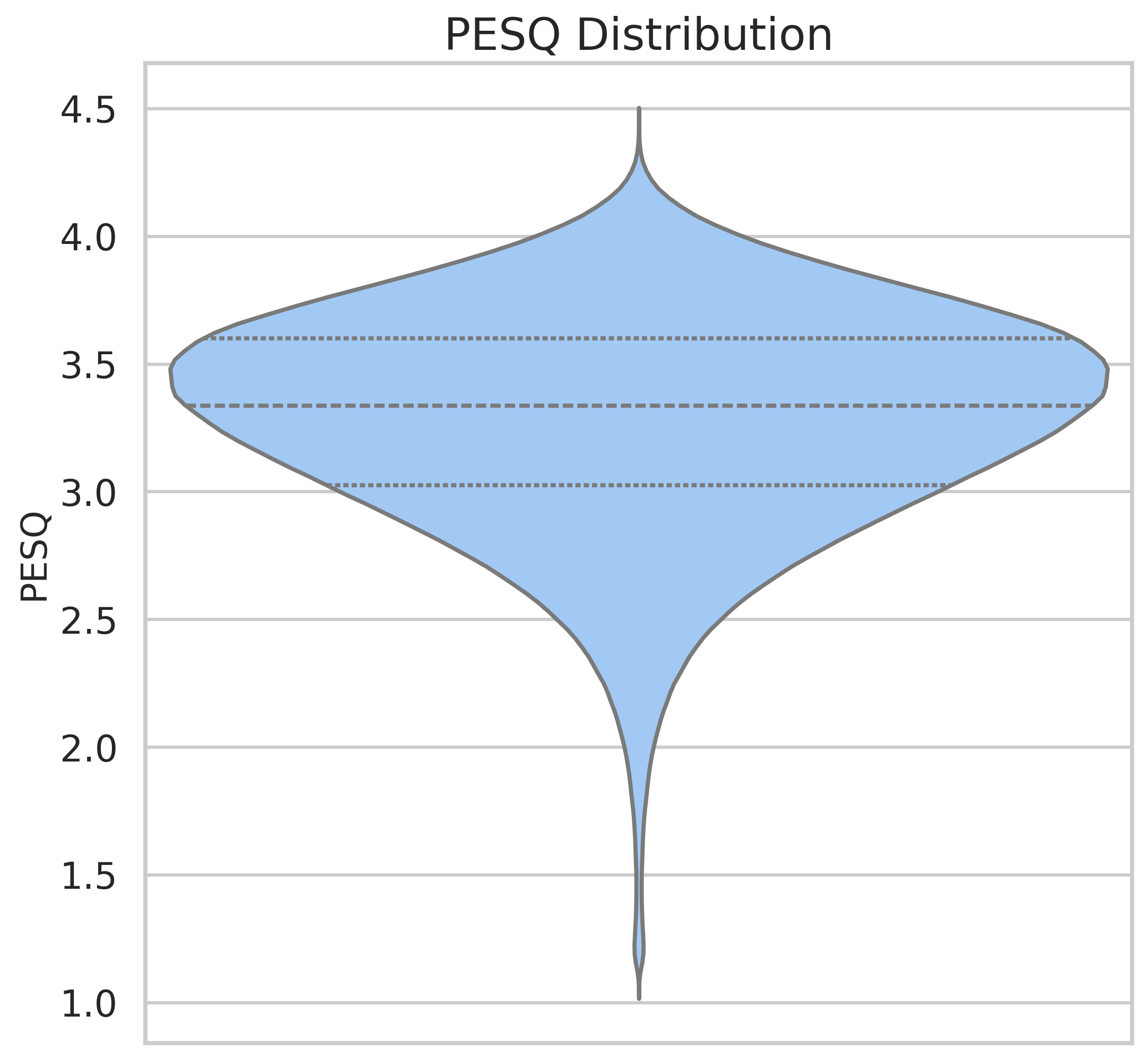
- 说明:该图展示了经流水线处理后,TAGARELA数据集中音频片段的客观质量指标(STOI, PESQ, SI-SDR)分布。这些指标通常需要干净参考信号,此处使用了无参考估计。结果表明,经过降噪等处理后,数据集整体音频质量处于较高水平。
音频片段时长分布图(图2)
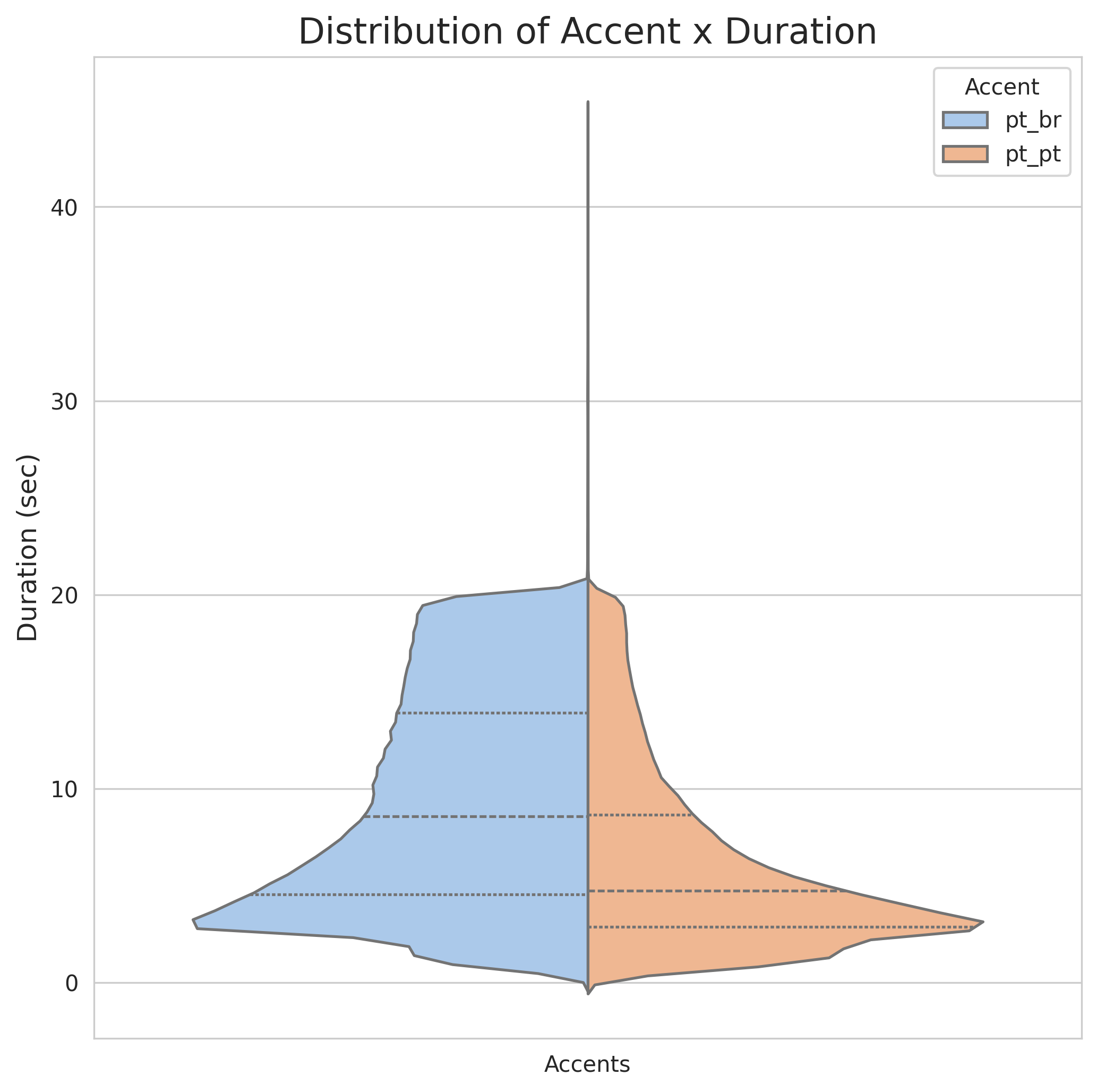
- 说明:左图比较了巴西葡萄牙语(pt-br)和欧洲葡萄牙语(pt-pt)片段的时长分布,右图比较了男性和女性说话人的片段时长分布。可以观察到分布的大致形态和可能存在的差异。
⚖️ 评分理由
- 学术质量:6.0/7:论文在数据工程方面工作扎实,流水线设计合理且完整,实验评估了数据集在主要下游任务(ASR, TTS)上的有效性,结果具有说服力。主要扣分点在于创新性更多体现在系统集成而非算法突破,且部分实验细节(如训练超参数)和更深入的分析(如与其它葡萄牙语数据集在相同模型上的对比)有所欠缺。
- 选题价值:1.5/2:对于葡萄牙语语音社区而言,这是一个需求迫切、价值极高的资源型工作。其规模和质量直接关系到该语言领域研究水平的提升。对于更广泛的语音研究社区,它也提供了一个在非英语低/中资源语言上构建大规模数据集的方法论案例。
- 开源与复现加成:0.5/1:积极开源了最终的数据集和部分处理模型,这是巨大的贡献。但缺少完整处理代码的仓库链接,且转录过程依赖商业API,使得他人难以完全复现其数据构建流程,因此加成有限。