📄 TAG: Structured Temporal Audio Generation via LLM-Guided Manual Scription and Control
#音频生成 #大语言模型 #扩散模型 #免训练方法 #注意力机制
✅ 7.5/10 | 前25% | #音频生成 | #扩散模型 | #大语言模型 #免训练方法
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Hanwen Zhang(USC,美国)
- 通讯作者:Shuhui Wang(ICT, CAS,中国);Wei Yang(HUST,中国)
- 作者列表:
- Hanwen Zhang(USC,美国)
- Jinshen Zhang(HUST,中国)
- Cong Zhang(UCAS,中国)
- Shuhui Wang(ICT, CAS,中国)
- Wei Yang(HUST,中国)
💡 毒舌点评
亮点:该工作最大的价值在于提出了一个“即插即用”的免训练框架,通过操纵已有音频生成模型的注意力图来实现精确的时间控制,巧妙地将语言理解的复杂性与生成模型的控制分离。短板:其性能高度依赖于作为“大脑”的LLM的指令遵循能力和基础生成模型的预训练质量,论文未能充分分析这种依赖性带来的边界情况或失效模式。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开的TAG框架自身或微调后的基础模型权重。
- 数据集:实验使用公开的Audiocaps和AudioCondition数据集,但论文未提供数据处理脚本或增强细节。
- Demo:未提及在线演示。
- 复现材料:未提供详细的训练细节(针对基础模型)、配置文件、检查点或附录说明。
- 论文中引用的开源项目:引用了TANGO2, Stable Audio Open等基础模型,但未说明TAG框架如何具体集成这些模型的代码。
📌 核心摘要
本文针对现有文本到音频生成方法在生成具有复杂时间结构的音频时面临的挑战,提出了一种名为TAG的两阶段框架。问题:现有方法独立构建结构化信息,缺乏灵活性,且现有时间控制方法计算成本高或适应性有限。方法核心:第一阶段利用大语言模型作为推理器和规划器,将复杂文本提示解析为结构化的“音频生成手册”;第二阶段是一个免训练的生成框架,通过对扩散模型的交叉注意力图进行动态、自适应的调制,实现精确的时间控制。新意:相比独立于模型构建结构或需要重新训练的方法,TAG将LLM的语义规划能力与对现有模型注意力的无损操作相结合,且可轻松集成到各种基于注意力的扩散模型中(如UNet和DiT架构)。实验结果:在Audiocaps数据集上,TAG在保持或提升音频质量(FAD, CLAP)的同时,显著提升了文本-音频对齐度。在AudioCondition数据集上的时间控制评估表明,TAG在事件基指标(Eb)和宏观F1(At)上大幅超越了基线模型和先前的SOTA方法,例如,Stable Audio Open + TAG在Eb上达到47.21(基线8.13),At达到74.77(基线56.96)。实际意义:为可定制、时间结构精确的音频生成提供了一个高效、通用且易于部署的解决方案。局限性:方法的上限受限于基础生成模型的能力和LLM对复杂指令的解析精度;免训练的控制方式可能在某些极端场景下对原始生成分布造成干扰。
🏗️ 模型架构
本文提出的TAG(Structured Temporal Audio Generation)框架是一个两阶段的系统。
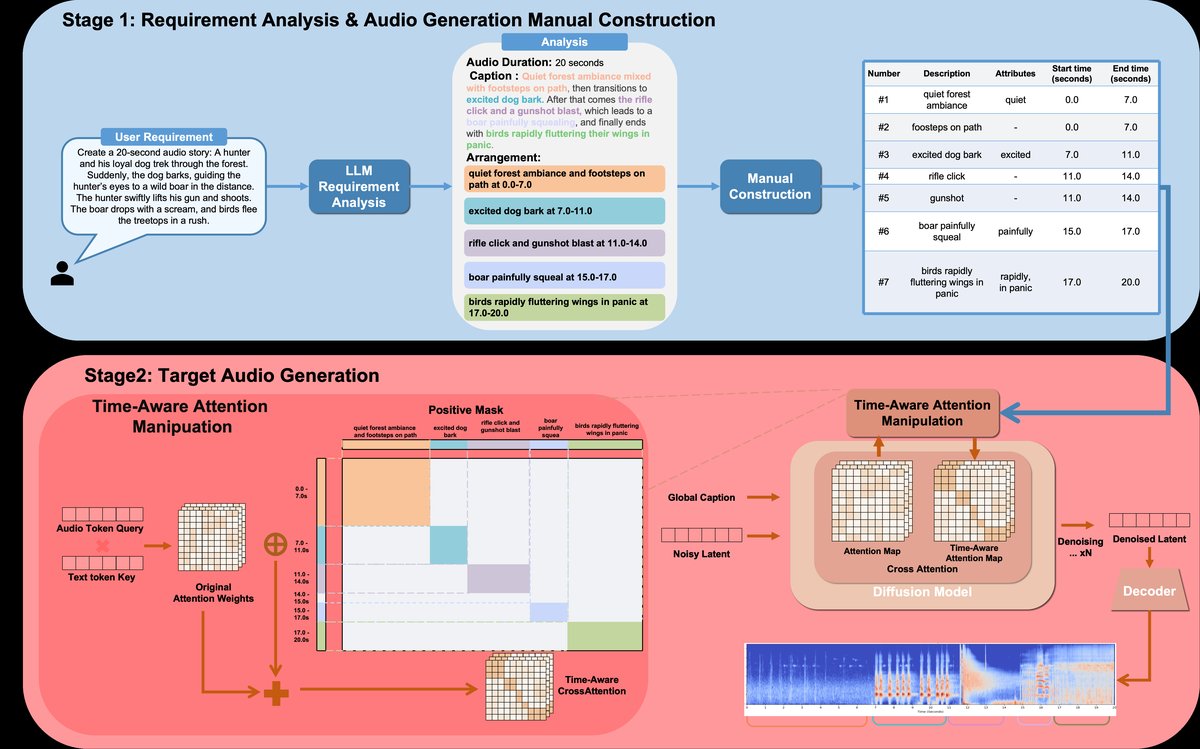 图1 展示了TAG的整体框架:上半部分是“音频生成手册构建”阶段,下半部分是“基于注意力的时间控制音频生成”阶段。
图1 展示了TAG的整体框架:上半部分是“音频生成手册构建”阶段,下半部分是“基于注意力的时间控制音频生成”阶段。
第一阶段:音频生成手册构建 (Audio Generation Manual Construction)
- 输入:复杂的文本提示。
- 流程:利用大语言模型进行两步处理:
- 需求分析:LLM首先进行重述(Recaption),生成更明确、利于生成的描述,并分解音频事件间的时间关系,进行时间规划。
- 手册构建:LLM考虑基础生成模型的能力(如是否有精修模块),生成最终的“音频生成手册”。
- 输出:一份结构化的手册,包含每个音频事件的时间信息(起止时间)、内容描述、属性信息以及可用模型能力。这份手册作为第二阶段的直接控制输入。
第二阶段:基于注意力的时间控制音频生成 (Attention-based Temporal Control Audio Generation)
- 核心组件:基于交叉注意力调制的免训练控制机制。
- 核心操作:在扩散模型的去噪过程中,对文本提示token与音频潜变量token之间的注意力图
A进行动态调制,得到A'。 - 工作原理:
- 基础调制:为每个文本token定义一个时间感知的调制矩阵
M。对于属于事件i时间区间内的音频token,增强其与对应文本token的注意力(正调制Mpos);对于区间外的,则抑制(负调制Mneg)。调制强度由标量λpos和λneg控制。 - 值域自适应:为防止调制破坏预训练模型的生成能力,
Mpos和Mneg的计算基于原始注意力分数Aorig的动态范围(max(Aorig) - Aorig和Aorig - min(Aorig)),确保调制后的值仍在原始分布内。 - 并发事件自适应:引入基于注意力的检测机制。对于属于某事件时间区间的音频token,计算其关注对应文本token的总注意力
D_i(j),并与来自其他文本token的注意力之和θ_j^i比较。如果D_i(j)过低(表明事件可能缺失),则在早期时间步(t > T_min)施加更强的负调制(γ * ω_neg),以“强制”模型关注该事件。 - 动态属性控制(扩展):该机制还可扩展到对音频属性(如响度、音高)进行随时间变化的动态控制,通过为属性token设计时变的强度曲线
I_j(t)来调制注意力。
- 基础调制:为每个文本token定义一个时间感知的调制矩阵
组件交互:第一阶段生成的手册提供了精确的时间区间 (t_start, t_end) 和事件描述,这些信息直接用于构造第二阶段的调制矩阵 M。控制信息是解释性的、可编辑的。
💡 核心创新点
LLM作为生成规划器与结构化信息桥梁:
- 局限:以往方法独立构建音频结构,不考虑生成模型特性,导致灵活性差。
- 创新:将LLM深度集成,不仅用于解析复杂提示,更结合具体生成模型的能力(如精修)来规划生成策略,输出一个富含语义和控制信息的“音频生成手册”。
- 收益:实现了从模糊文本到精确、模型友好的控制信息的优雅转换,提升了框架的通用性和适应性。
免训练、即插即用的交叉注意力图动态调制机制:
- 局限:现有时间控制方法要么需要重新训练模型(计算开销大),要么控制粒度粗或适应性差。
- 创新:提出了一套精细的注意力调制方案(包括基础调制、值域自适应、并发事件自适应),无需任何额外训练,直接在推理时操纵预训练扩散模型的内部注意力分布。
- 收益:实现了精确到事件级别的时间控制,同时保持了音频的连贯性和质量。该方法可作为“外挂”应用于多种主流架构(如基于UNet的TANGO2和基于DiT的Stable Audio Open)。
自适应的并发音频事件处理机制:
- 局限:简单地按时间段分割注意力,在处理多个同时发生的声音事件时容易导致某些事件丢失或混淆。
- 创新:设计了基于注意力分布对比的检测与强抑制机制,在生成的关键早期阶段,动态调整对“被忽视”事件的抑制强度,确保所有事件都能获得足够的注意力资源。
- 收益:显著提升了生成复杂、多层次音频场景的成功率和准确性。
🔬 细节详述
- 训练数据:论文中未明确说明第一阶段LLM训练所使用的数据集。第二阶段控制机制无需训练。
- 损失函数:论文中未提及任何损失函数,因为其核心控制机制是免训练的。
- 训练策略:不适用。论文未说明对基础生成模型的微调或TAG本身的训练策略。
- 关键超参数:
- 控制参数:
λ_pos = 0.1,ω_neg = 0.9,T_min = 0.1(具体时间步阈值)。这些值通过经验研究确定。 - 发现负调制(
λ_neg)比正调制(λ_pos)对保持音频质量更重要,因此使用了不同的时间步标量。 - 并发事件检测中的放大因子
γ > 1,但未给出具体数值。
- 控制参数:
- 训练硬件:未说明。
- 推理细节:
- 使用预训练的扩散模型(TANGO2, Stable Audio Open)作为生成骨干。
- 控制过程在扩散模型的多个时间步动态进行,仅在早期时间步(
t > T_min)进行强干预以保持整体连贯性。 - 未提供具体的解码策略、温度或batch size等信息。
- 正则化或稳定训练技巧:不适用(免训练)。但其值域自适应机制可视为一种稳定生成过程的技巧。
📊 实验结果
主要Benchmark与数据集:
- 音频质量评估:在 Audiocaps 测试集上评估。
- 时间控制精度评估:在 AudioCondition 测试集上评估。
关键对比实验及数字:
表1:音频质量评估 (Audiocaps测试集)
| 方法 | FAD↓ | FD↓ | KL↓ | CLAP↑ |
|---|---|---|---|---|
| TANGO2 | 1.79 | 3.07 | 0.47 | 63.0% |
| Stable Audio Open | 2.30 | 5.21 | 0.83 | 34.1% |
| TANGO2 + TAG | 1.87 | 2.64 | 0.56 | 63.1% |
| Stable Audio Open + TAG | 1.37 | 4.91 | 0.74 | 35.0% |
结论:加入TAG后,模型的音频质量指标(FAD, FD, KL)普遍得到改善或保持,文本-音频对齐度(CLAP)均有提升,证明了TAG在不牺牲质量的前提下增强语义控制的能力。
表2:时间控制评估与消融研究 (AudioCondition测试集)
| 方法 | Eb↑ | At↑ |
|---|---|---|
| Ground Truth | 43.37 | 67.53 |
| AudioLDM2 Full Large | 6.93 | 20.47 |
| Stable Audio Open | 8.13 | 56.96 |
| TANGO2 | 7.47 | 52.58 |
| CCTA | 14.57 | 18.27 |
| MC-Diffusion | 29.07 | 47.11 |
| AudioComposer-L | 44.40 | 63.30 |
| TG-Diff | 26.70 | 60.06 |
| FreeAudio | 44.34 | 68.50 |
| TANGO2 + TAG (w/o LLM stage) | 39.61 | 66.80 |
| Stable Audio Open + TAG (w/o LLM stage) | 44.56 | 70.12 |
| TANGO2 + TAG | 43.34 | 73.45 |
| Stable Audio Open + TAG | 47.21 | 74.77 |
结论:
- 显著提升:TAG框架(尤其是与Stable Audio Open结合时)在Eb和At指标上大幅超越了所有基线模型和已发表的SOTA方法,甚至接近或超过真实音频的Eb值。
- 消融实验:移除LLM阶段(w/o LLM stage)直接使用原始时间注释时,性能已很高,但加入LLM阶段后,两项指标均有进一步提升(如TANGO2+TAG的Eb从39.61提升至43.34,At从66.80提升至73.45),证明了LLM进行需求分析和手册构建的有效性。
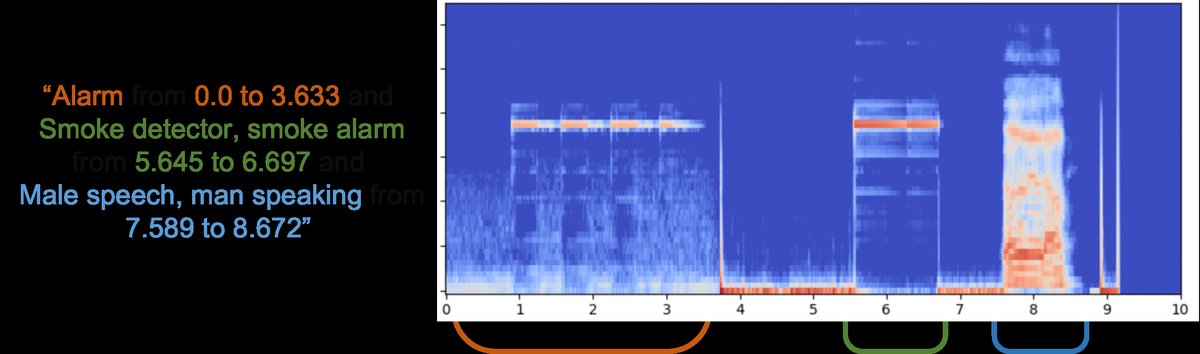 图2 (Audiocaps案例):展示了基线模型在处理多个事件时容易遗漏或错序,而TAG框架能成功安排并生成所有指定事件并保持时序关系。
图2 (Audiocaps案例):展示了基线模型在处理多个事件时容易遗漏或错序,而TAG框架能成功安排并生成所有指定事件并保持时序关系。
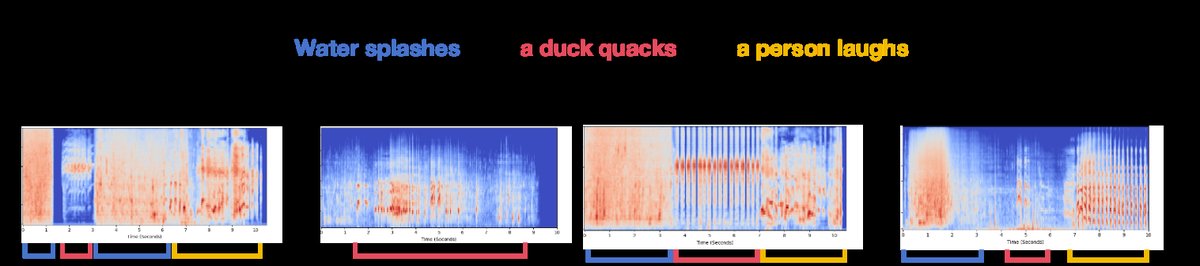 图3 (AudioCondition案例):展示了集成TAG的Stable Audio Open模型能实现精确的时间控制。
图3 (AudioCondition案例):展示了集成TAG的Stable Audio Open模型能实现精确的时间控制。
⚖️ 评分理由
- 学术质量:6.5/7 - 论文提出了一套完整、新颖���技术上合理的解决方案,创新点明确。实验设计全面,结果令人信服地证明了方法的有效性。不足之处在于对LLM阶段的内部机制和潜在失败案例分析稍显简略,部分超参数的具体选择依据未完全展开。
- 选题价值:1.5/2 - 选题切中当前音频生成领域的核心痛点之一(精确、可控、结构化生成),方法具有很强的实用性和推广潜力,对相关领域的研究者和从业者有直接参考价值。
- 开源与复现加成:+0.5/1 - 论文最大的优势“免训练”本身有利于复现,但论文中未提及具体的代码仓库、预训练模型配置文件、详细的推理脚本或关键的提示工程示例。这增加了精确复现其全部实验结果的难度,因此只给予有限加分。