📄 Synthcloner: Synthesizer-Style Audio Transfer via Factorized Codec with ADSR Envelope Control
#音频生成 #解耦表征学习 #因子分解 #合成器 #音频迁移
🔥 8.5/10 | 前25% | #音频生成 | #解耦表征学习 | #因子分解 #合成器
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Jeng-Yue Liu(国立台湾大学,中央研究院,卡内基梅隆大学)
- 通讯作者:未说明(论文标注“Jeng-Yue Liu1,2,3∗, Ting-Chao Hsu1∗”为共同第一作者,未明确通讯作者)
- 作者列表:Jeng-Yue Liu(国立台湾大学,中央研究院,卡内基梅隆大学)、Ting-Chao Hsu(国立台湾大学)、Yen-Tung Yeh(国立台湾大学)、Li Su(中央研究院)、Yi-Hsuan Yang(国立台湾大学)
💡 毒舌点评
论文直击合成器音频迁移中“包络控制”这个长期被忽略的痛点,并给出了一个从数据集到模型的完整解决方案,消融实验清晰地证明了显式建模ADSR的必要性,技术路线扎实。然而,其核心依赖的“音色”定义(从平稳区域提取one-shot)和数据集构建(依赖特定商业软件Serum及其预设)可能限制了模型对真实世界复杂合成器声音的泛化能力,使得“通用合成器迁移”的承诺打了一点折扣。
🔗 开源详情
- 代码: 论文提供了代码仓库链接:
https://buffett0323.github.io/synthcloner/。 - 模型权重: 论文明确提到提供了模型检查点(model checkpoint),可通过上述链接获取。
- 数据集: 论文提出了SynthCAT数据集,并说明了其构成和渲染管线,但具体下载方式需查阅提供的链接或项目主页。
- Demo: 论文提供了音频示例(audio examples)链接。
- 复现材料: 论文给出了详细的训练细节(实现框架、优化器、学习率、损失函数及权重、批量大小、训练步数、硬件),超参数(RVQ配置、音频段长)也已说明。
- 论文中引用的开源项目: 引用了audiotools(用于计算MSTFT)、torchcrepe(用于提取F0)等开源工具。模型架构灵感来源于FACodec和NANSY。
- 论文中未提及开源计划: 论文未提及。
📌 核心摘要
本文针对合成器风格音频迁移(SAT)任务,指出现有方法缺乏对ADSR包络(声音的时域动态)的显式控制。为此,作者提出了两个核心贡献:1)SynthCloner,一个因子分解编解码器模型,将音频解耦为ADSR包络、音色(时不变频谱特征)和内容(音高序列)三个独立属性,并支持对它们的独立控制和迁移;2)SynthCAT,一个通过系统化渲染流程构建的大规模合成器数据集,覆盖了250种音色、120种ADSR包络和100个MIDI序列的笛卡尔积,总计约3M样本。实验表明,在SynthCAT数据集上,SynthCloner在客观指标(多尺度STFT损失、对数RMS距离、F0 RMSE)和主观评估(音色相似度、ADSR包络相似度、内容相似度MOS)上均显著优于SS-VAE和CTD等基线模型。消融实验证实了显式ADSR建模对于高保真迁移至关重要。该工作为电子音乐制作提供了新的自动化工具,但其模型和数据集目前聚焦于单声道基础合成器声音,尚未涵盖LFO等复杂调制效果。
| 模型/方法 | MSTFT↓ | LRMSD↓ | F0RMSE↓ | TMOS↑ | ADSRMOS↑ | CMOS↑ |
|---|---|---|---|---|---|---|
| Ground Truth | – | – | – | 4.08 | 3.96 | 4.25 |
| SS-VAE [4] | 7.22 | 0.92 | 641.62 | 2.20 | 2.25 | 3.41 |
| CTD [6] | 5.69 | 0.89 | 583.01 | 2.34 | 2.48 | 1.86 |
| SynthCloner (ours) | 3.00 | 0.17 | 20.64 | 3.91 | 3.94 | 4.11 |
| – w/o ADSR envelope path | 3.84 | 0.42 | 29.04 | 3.09 | 2.40 | 3.76 |
表1:合成器风格音频迁移的客观和主观结果(摘自论文)。
🏗️ 模型架构
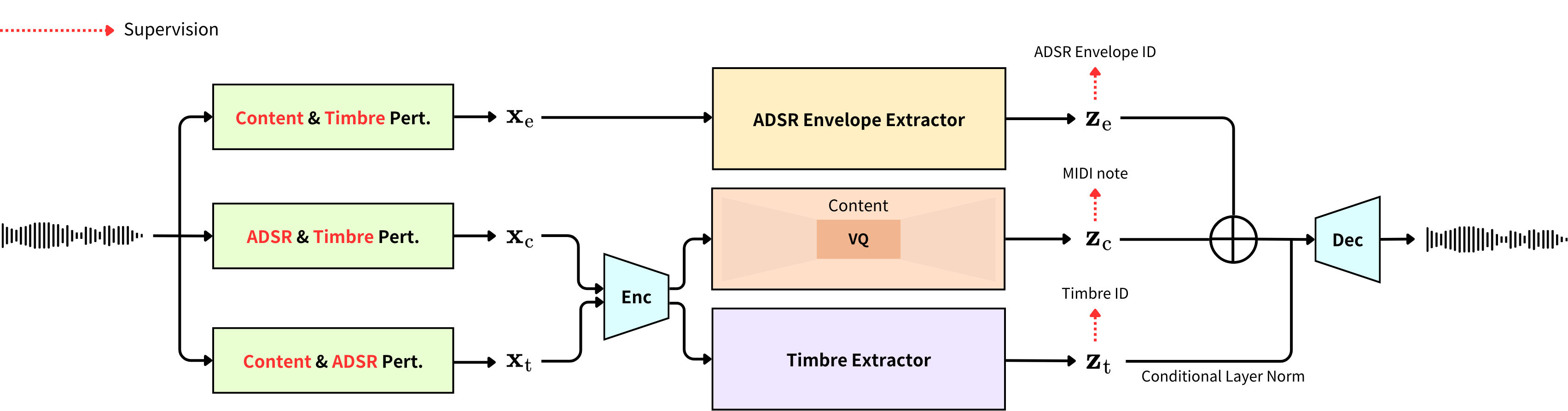 图2:SynthCloner模型架构示意图(摘自论文)。
图2:SynthCloner模型架构示意图(摘自论文)。
SynthCloner是一个因子分解编解码器模型,其核心思想是将输入音频x通过三条独立的处理路径解耦为三个潜在表示,并在重建时组合它们。
完整输入输出流程:
- 编码/解耦阶段: 输入音频
x被复制成三个扰动版本(x_e,x_c,x_t),分别输入三条路径,生成三个解耦的潜在嵌入:ADSR包络嵌入z_e(形状D×T)、内容嵌入z_c(形状D×T)、音色嵌入z_t(形状D)。 - 解码/重建阶段: 首先将
z_e与z_c进行加法融合,然后将融合结果通过以z_t为条件的条件层归一化(Conditional Layer Normalization)进行调制,最后送入解码器生成重建波形x̂。 - 迁移/推理: 为了执行SAT,将参考音频(提供目标音色和ADSR包络)的音频波形同时作为
x_e和x_t的输入,而源音频(提供内容)的音频波形作为x_c的输入。模型将输出具备源音频内容、参考音频音色和ADSR包络的新音频。
主要组件:
- ADSR包络路径:
- 功能: 提取音频中随时间变化的幅度包络(即ADSR包络)特征。
- 内部结构: 首先将扰动输入
x_e转换为对数RMS值,然后通过一个时序多尺度卷积-双向长短时记忆网络(Conv-BiLSTM)。这个网络能够捕捉包络的长期动态和不同时间尺度上的特征。
- 内容路径:
- 功能: 提取音频中不随时间变化的核心内容(主要是音高序列)。
- 内部结构: 采用与FACodec相似的设计,包含一个共享的编码器和一个残差向量量化器(RVQ)。编码器将
x_c转换为连续特征,RVQ则将其离散化为内容嵌入z_c。RVQ由1024条目的码本和8层量化层组成。
- 音色路径:
- 功能: 提取音频中整体的、时不变的频谱特征,即“音色”。
- 内部结构: 使用与内容路径共享权重的同一编码器处理
x_t,然后通过一个基于Conformer架构的音色提取器,并进行全局平均池化,生成一个全局音色嵌入z_t。
- 解码器:
- 功能: 将融合并调制后的潜在表示恢复为波形。
- 交互方式:
z_e和z_c在特征维度上相加,得到时序特征z_{ec}。然后,z_t作为条件,通过条件层归一化对z_{ec}的每个通道进行仿射变换(调制),最终送入解码器。
关键设计选择与动机:
- 三路径分离: 动机是合成器声音由内容(音符序列)、音色(静态频谱)和动态包络(ADSR)三个相对独立的方面决定。显式分离是为了实现独立控制。
- 信息扰动: 借鉴NANSY,在训练时对每个路径的输入进行特定扰动(例如,训练包络编码器时,固定包络但改变内容和音色),强迫编码器只关注其目标属性,这是实现解耦的关键。
- 共享编码器与条件归一化: 共享编码器(内容/音色路径)提高了参数效率。条件层归一化允许全局的音色调制时序的内容-包络特征,模拟了合成器中“振荡器(音色)被包络发生器(ADSR)调制”的信号流。
💡 核心创新点
- 首个显式建模ADSR包络控制的合成器风格音频迁移模型:
- 之前局限: 现有音色迁移方法(如SS-VAE, CTD)主要关注频谱相似性,隐含地假设输入输出包络不变,这不符合合成器设计逻辑。
- 如何起作用: 专门设计了ADSR包络路径和相应的损失函数,从音频中显式提取并重建包络。
- 收益: 消融实验(表1)显示,移除ADSR路径后,包络相似度(LRMSD从0.17升至0.42,ADSRMOS从3.94降至2.40)和频谱保真度(MSTFT从3.00升至3.84)显著下降,证明了该建模的必要性。
- 属性解耦的因子分解编解码器架构:
- 之前局限: 虽然已有因子分解模型(如FACodec),但未针对合成器声音的特殊性(音色与包络的强相关性)设计。
- 如何起作用: 通过结构上的三路径设计,结合针对各路径的信息扰动训练策略和辅助分类任务(对120种包络和250种音色进行分类),强制潜在表示
z_e,z_c,z_t各司其职。 - 收益: 使得迁移时能够独立、精准地替换音色或包络。消融实验(表2)证实,移除任一转换都会影响对应指标而不严重影响其他指标。
- SynthCAT数据集及其系统化渲染管线:
- 之前局限: 现有数据集(如NSynth, Synth1B1)缺乏音色、包络和内容的系统组合,难以支持解耦模型的训练和评估。
- 如何起作用: 设计了一个从长音中提取纯净音色one-shot,再通过音高偏移、时长对齐和ADSR包络塑形来渲染短句的管线,确保了每个样本的三个属性可控且可组合。
- 收益: 提供了3M样本、覆盖广泛组合的专用数据集,为SAT任务建立了基准。其严格的渲染流程是训练解耦模型的基础。
🔬 细节详述
- 训练数据: 使用新提出的SynthCAT数据集。数据来源:使用Serum合成器渲染。规模:300万单声道音频样本,约2500小时,44.1 kHz。预处理:从长音平稳区域提取1秒one-shot作为音色(平坦度>0.95),然后通过音高变换和ADSR包络塑形生成短句。数据增强:数据集本身通过笛卡尔积组合实现了极大的多样性。
- 损失函数: 总损失为多项加权和。包括:
- 多尺度梅尔频谱损失
Lmel:权重λmel=15.0,使用7个尺度(FFT窗长32至2048)计算预测与目标间的L1距离。 - 特征匹配损失
Lfeat:权重λfeat=2.0,比较判别器中间层的特征。 - 对抗损失
Ladv:权重λadv=1.0,来自GAN训练。 - 承诺损失
Lcommit:权重λcommit=0.25,用于RVQ。 - 码本损失
Lcodebook:权重λcodebook=1.0,用于RVQ。 - 辅助分类损失:权重均为5.0。包括:
Ltimbre:对z_t进行250类(音色ID)分类。Lcontent:对z_c进行帧级MIDI音高标签监督。Ladsr:对z_e进行120类(包络ID)分类。
- 多尺度梅尔频谱损失
- 训练策略: 优化器:AdamW。初始学习率:10⁻⁴。衰减策略:指数衰减,速率0.999996。批次大小:8。训练步数:400k步。硬件:单张NVIDIA RTX 6000 Ada GPU。
- 关键超参数: 音频段长:1秒。RVQ码本大小:1024。RVQ层数:8。嵌入维度
D:论文未明确说明具体数值,但架构图显示三个嵌入维度一致。 - 推理细节: 论文未提供具体推理时的解码策略、温度或beam size信息。根据架构描述,推理时直接使用编码器和解码器前向传播即可。
- 正则化/稳定训练技巧: 信息扰动策略本身是一种正则化。采用指数学习率衰减以稳定训练后期。���用对抗训练提高生成质量。
📊 实验结果
主要评估在SynthCAT的测试集(50k样本)上进行,每个测试样本有10个参考样本。与两个基线(SS-VAE, CTD)以及一个模型变体(w/o ADSR路径)进行对比。
主要基准与指标:
- 客观指标: 多尺度STFT损失(MSTFT↓),对数RMS距离(LRMSD↓),F0均方根误差(F0RMSE↓)。
- 主观指标: 音色相似度(TMOS↑),ADSR包络相似度(ADSRMOS↑),内容相似度(CMOS↑),采用5分制MOS。
关键结果表格: 表1:合成器风格音频迁移的客观和主观结果(已在核心摘要部分列出)。
与最强基线/ SOTA的差距: 论文明确声称SynthCloner在所有指标上优于基线。具体差距:
- 频谱保真度(MSTFT): SynthCloner (3.00) 相比次优的CTD (5.69) 降低了约47%。
- 包络精度(LRMSD): SynthCloner (0.17) 相比次优的CTD (0.89) 降低了约81%,优势巨大。
- 内容保真度(F0RMSE): SynthCloner (20.64) 相比次优的CTD (583.01) 降低了约96%,优势显著。
- 主观感知: SynthCloner的MOS值(TMOS: 3.91, ADSRMOS: 3.94, CMOS: 4.11)已非常接近真实音频(Ground Truth),而基线模型在2.2-2.5之间,差距明显。
关键消融实验(独立属性控制,表2): 表2:独立属性控制的客观结果(摘自论文)。
| 设置 | MSTFT↓ | LRMSD↓ | F0RMSE↓ |
|---|---|---|---|
| Proposed(完整模型) | 3.00 | 0.17 | 20.64 |
| 不转换音色 (w/o timbre conv.) | 5.97 | 0.19 | 24.54 |
| 不转换ADSR包络 (w/o ADSR conv.) | 4.15 | 0.39 | 24.06 |
- 不转换音色: MSTFT大幅上升(3.00→5.97),表明音色对频谱影响巨大;LRMSD几乎不变(0.17→0.19),表明包络转换不受影响。
- 不转换ADSR包络: LRMSD显著上升(0.17→0.39),表明包络匹配失败;MSTFT也上升(3.00→4.15),说明包络也影响频谱保真度。
- 两者都导致内容保真度(F0RMSE)轻微下降,但影响不大。
- 结论: 模型能够独立控制音色和ADSR包络,且任何一项的缺失都会影响整体迁移质量。
⚖️ 评分理由
- 学术质量:6.0/7。创新性明确,针对一个具体且重要的子问题提出了解耦方案;技术实现基于成熟的FACodec和NANSY思想,正确性有保障;实验设计严谨,提出了新的数据集、进行了充分的对比和消融实验,并包含客观和主观评估,证据链条完整可信。主要不足是对比基线数量有限(2个),且均非专门针对合成器迁移设计,可能无法全面反映在更广泛技术背景下的竞争力。
- 选题价值:1.5/2。选题聚焦于电子音乐制作中的实际需求——合成器声音的快速迁移与设计,具有明确的潜在应用价值和商业前景。对于音频生成和音乐信息检索领域的研究者,这是一个有意义的垂直方向。但相比通用的语音或音乐生成,其受众面相对较窄。
- 开源与复现加成:1.0/1。论文提供了完整的代码仓库、模型检查点、数据集获取链接以及详尽的训练配置(优化器、学习率、损失权重、硬件),极大地便利了复现和后续研究。这是论文的一大亮点。