📄 StylePitcher: Generating Style-Following and Expressive Pitch Curves for Versatile Singing Tasks
#歌唱语音合成 #流匹配 #音频生成 #语音转换 #零样本
✅ 7.5/10 | 前25% | #歌唱语音合成 | #流匹配 | #音频生成 #语音转换
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jingyue Huang (University of California San Diego, Smule Labs)
- 通讯作者:未说明
- 作者列表:Jingyue Huang(△University of California San Diego, ◦Smule Labs)、Qihui Yang(△University of California San Diego, ◦Smule Labs)、Fei-Yueh Chen(†University of Rochester, ◦Smule Labs)、Julian McAuley(△University of California San Diego)、Randal Leistikow(◦Smule Labs)、Perry R. Cook(◦Smule Labs)、Yongyi Zang(◦Smule Labs)
💡 毒舌点评
亮点在于它敏锐地抓住了唱歌音高曲线“既要符合乐谱,又要保留歌手个人风格”这个核心矛盾,并用一个优雅的掩码填充框架将其统一解决,体现了扎实的工程直觉和对音乐的理解。短板是,虽然实验覆盖了多个任务,但其作为“通用模块”的潜力在很大程度上依赖于下游系统本身,论文并未深入探讨在极端风格差异或复杂旋律转移场景下的鲁棒性边界。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:训练数据为DAMP-VSEP和DAMP-VPB,论文未说明其是否公开或获取方式。评测数据集GTSinger, VocalSet等为公开数据集。
- Demo:提供在线演示网站链接:https://stylepitcher.github.io/
- 复现材料:论文提供了详细的模型架构、训练超参数、数据处理步骤和评估方法,复现信息较为充分。
- 论文中引用的开源项目:RMVPE(用于F0估计)、Basic Pitch(用于MIDI提取)、torchdiffeq(用于ODE求解)、FlashAttention-2(用于加速训练)、librosa(用于评估指标计算)。
📌 核心摘要
问题:现有音高曲线生成器存在两大问题:一是忽视了歌手的个人表达风格(如颤音、滑音),导致生成的声音缺乏个性;二是通常为特定任务(如音高校正、歌声合成)设计,作为专用模块,跨任务泛化能力差,需要重新训练。
方法核心:提出StylePitcher,一个通用的风格跟随音高曲线生成器。其核心思想是将音高生成建模为“条件填充”问题:给定周围音高上下文和乐谱符号,模型学习生成缺失的音高片段,使其延续上下文的风格模式。该方法基于校正流匹配(Rectified Flow Matching)架构,使用扩散Transformer(DiT)实现。
新意:它是第一个为多种唱歌任务设计的、通用的风格跟随音高曲线生成模型。创新点在于:首次将流匹配应用于音高生成;引入MIDI平滑算法自动获取可靠乐谱条件;通过掩码填充机制实现零样本风格迁移,无需针对不同任务重新训练。
实验结果:在自动音高校正(APC)、零样本歌声合成(SVS)和歌声转换(SVC)三个任务上进行了评估。
- 客观评估:在GTSinger数据集上,StylePitcher在风格相似度(LSTM判别器准确率接近随机的50%,为51.85%)和音高准确度(OA为73.04%)上均优于或持平于任务专用基线(Diff-Pitcher: OA 70.30%, Acc. 69.43%)。
- 主观评估:人类听众评分(MOS)显示,在风格保留/捕捉(MOS-S)和整体质量(MOS-Q)方面,StylePitcher在APC和SVC任务上优于基线;在SVS任务上,其风格捕捉能力(3.33)优于StyleSinger(3.07),质量接近(3.11 vs 3.07)。具体MOS分数见下表。
任务 模型 MOS-P (音高) MOS-S (风格) MOS-Q (质量) APC Diff-Pitcher [4] 4.18±0.21 3.21±0.22 3.03±0.22 StylePitcher 3.84±0.22 3.64±0.20 3.26±0.18 SVS StyleSinger [9] - 3.07±0.19 3.18±0.21 StylePitcher - 3.33±0.23 3.11±0.23 SVC In-house SVC - 2.62±0.23 3.03±0.22 StylePitcher - 2.95±0.25 2.72±0.22 实际意义:StylePitcher作为一个即插即用的模块,可以无缝集成到现有的歌声处理系统中,提升其输出的风格表现力和质量,无需为每个新任务或歌手重新训练模型,降低了应用门槛。
主要局限性:在歌声转换(SVC)任务中,由于缺乏对内容(歌词)的显式感知,有时会在转移强烈风格(如颤音)时产生不自然的音频结果(论文中提及)。模型的通用性最终仍受限于其训练数据的覆盖范围。
🏗️ 模型架构
 StylePitcher的模型架构和工作流程如图1(a)所示。其核心是将音高曲线生成问题转化为一个条件掩码填充任务。
StylePitcher的模型架构和工作流程如图1(a)所示。其核心是将音高曲线生成问题转化为一个条件掩码填充任务。
输入处理:
- 音高曲线 (Pitch Curve):原始F0曲线
x。 - 乐谱 (Musical Score):对应的音符序列
y,通过论文提出的MIDI平滑算法获得(见3.3节)。 - 掩码 (Masking):随机生成一个二进制掩码
m,用于遮盖音高曲线的一部分(xmask = m ⊙ x),保留另一部分作为上下文(xctx = (1 - m) ⊙ x)。训练时,掩码率r在70%-100%之间均匀采样。 - 可选输入:无声段指示序列
u(1表示有声,0表示无声),用于指导生成正F0值并与语音音素对齐。
- 音高曲线 (Pitch Curve):原始F0曲线
模型核心:
- 架构:采用一个8层、8头的扩散Transformer (DiT),隐藏维度为512,使用旋转位置编码(RoPE)。总参数量为49M。
- 流匹配:模型学习一个速度场
vθ(xt, t, c),将从高斯噪声π0采样的x0,通过常微分方程(ODE)dxt = vθ(xt, t, c)dt推送到数据分布π1中的x1(即真实音高曲线)。xt = (1-t)x0 + t x1是线性插值。 - 条件注入:音高曲线
xt、上下文xctx和音符y分别被线性投影为嵌入向量(H1=512, H2=256),在帧维度拼接并投影后作为Transformer的输入。流步t通过正弦位置编码调制表示。
训练与推理:
- 训练目标:损失函数(公式4)仅在被掩码的帧上计算,鼓励模型预测真实速度场(
x - ϵ)。使用分类器无引导(CFG),训练时随机丢弃条件y, xctx, u,推理时通过调整引导强度α(默认1.25)来增强条件控制。 - 推理:从噪声开始,通过
K=16步ODE求解(使用中点法),逐步生成完整的音高曲线xhat。生成的曲线xhat根据原始掩码位置,提供修正/转换/合成所需的目标音高段。
- 训练目标:损失函数(公式4)仅在被掩码的帧上计算,鼓励模型预测真实速度场(
任务适配:如图1(b)所示,StylePitcher本身是一个与任务无关的填充模型。通过巧妙地构造输入
x、y和掩码模式m,即可适配不同任务:- APC:输入原始走调的音高
xoff与目标音符yin拼接,并掩码后半部分(即需要修正的部分)。 - SVS:将参考音高
xref、目标音符ytgt与内容占位xtgt拼接,掩码xtgt部分,生成遵循参考风格的目标音高。 - SVC:将参考音高
xref与目标内容音高xtgt拼接,掩码xtgt部分进行重新生成,以传递风格。
- APC:输入原始走调的音高
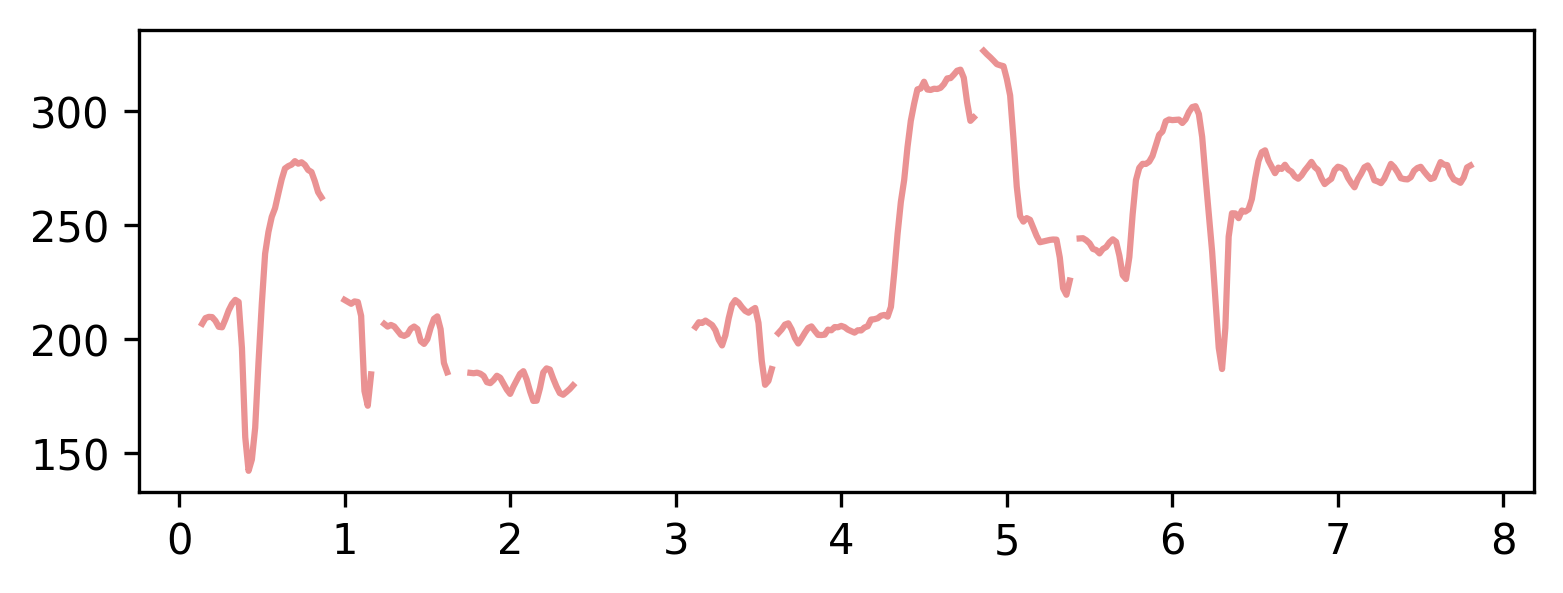
 图2展示了StylePitcher在三个任务上的实际效果。蓝色为输入曲线,红色为StylePitcher生成的曲线,绿色为基线方法的曲线。可以看到,StylePitcher能更好地从输入曲线中捕捉并保留滑音(a)、颤音(b, c)等风格特征。
图2展示了StylePitcher在三个任务上的实际效果。蓝色为输入曲线,红色为StylePitcher生成的曲线,绿色为基线方法的曲线。可以看到,StylePitcher能更好地从输入曲线中捕捉并保留滑音(a)、颤音(b, c)等风格特征。
💡 核心创新点
- 首个通用风格跟随音高生成器:不同于以往为特定任务(APC, SVS)设计的模块化音高预测器,StylePitcher首次提出了一个独立、通用的音高曲线生成框架。它通过统一的掩码填充范式,无需针对不同任务重新训练,即可作为即插即用模块适配多种应用。
- 基于流匹配的掩码填充架构:将校正流匹配(一种更稳定高效的生成模型)与VoiceBox风格的掩码填充相结合用于连续音高信号的生成。掩码填充机制使其能够通过上下文学习隐式建模歌手风格,无需显式的歌手标签或嵌入,从而支持对未见歌手的零样本风格迁移。
- 用于条件构建的MIDI平滑算法:提出了一个自动化的数据处理流程:使用Basic Pitch提取MIDI后,通过高斯模糊对多音高激活图进行平滑,以去除因颤音等表达技巧产生的短音符噪声,再通过后处理去除短休止和音符,从而获得作为可靠条件的干净乐谱符号
y,免除了人工标注。
🔬 细节详述
- 训练数据:使用来自DAMP-VSEP和DAMP-VPB两个多说话人歌唱数据集的共计1916小时的歌唱语音。
- 数据预处理与增强:
- 音频先进行人声分离和去噪。
- 使用RMVPE进行F0估计(16kHz,帧长1024,移位160)和无声检测。
- 使用Basic Pitch进行MIDI提取,但将其多音高激活替换为RMVPE的以提高准确性。
- 输出F0范围为C1 (32.7 Hz) 到 B6 (1975.5 Hz),共72个音高类别。
- 数据增强:随机将音高曲线和音符在[-4, 4]半音范围内平移。
- 损失函数:采用公式(4)所示的流匹配损失,即预测速度场与真实速度场
(x - ϵ)之间的L2距离,仅计算在掩码帧上。 - 训练策略:
- 优化器:AdamW。
- 学习率:预训练阶段1e-4,微调阶段1e-5。
- Warmup:5k步线性warm-up。
- Batch Size:512。
- 训练步数:预训练100k步(无
u条件),微调90k步(有u条件)。 - 调度策略:余弦学习率调度器。
- 正则化:CFG训练时,条件
y, xctx, u的丢弃概率pc = 0.5。
- 关键超参数:
- 模型:8层 DiT,8个注意力头,隐藏维度512。
- 序列长度:最大1024帧(对应20.48秒@50Hz)。
- 掩码率:
r ∼ U[70, 100]。 - 流匹配时间表:使用余弦时间表,更关注低
t值(噪声较少)阶段。
- 训练硬件:论文未说明具体的GPU/TPU型号、数量和训练时长。
- 推理细节:
- 求解器:使用
torchdiffeq库的中点法。 - 采样步数:
K=16。 - CFG强度:
α=1.25。 - 输出处理:生成的F0曲线可以被插值以匹配下游任务所需的F0采样率。
- 求解器:使用
- 稳定训练技巧:使用了FlashAttention-2加速训练。
📊 实验结果
客观评估 (在GTSinger数据集):
| 模型 | RPA (%) ↑ | RCA (%) ↑ | OA (%) ↑ | Acc. (%) ↓ |
|---|---|---|---|---|
| Diff-Pitcher (APC基线) | 67.37 | 67.40 | 70.30 | 69.43 |
| StyleSinger (SVS基线) | - | - | - | 71.48 |
| StylePitcher | 68.64 | 68.74 | 73.04 | 51.85 |
| - w/o smo. (消融) | 69.49 | 69.61 | 73.61 | 52.71 |
| - w/o ctx. (消融) | 66.71 | 66.82 | 71.34 | 52.12 |
- 音高准确度:StylePitcher在整体准确度(OA)上达到73.04%,显著优于Diff-Pitcher的70.30%。
- 风格相似度:训练的LSTM判别器在区分StylePitcher生成曲线与真实曲线时的准确率(Acc.)仅为51.85%,接近随机猜测(50%),表明生成曲线与真实分布高度相似,优于Diff-Pitcher(69.43%)和StyleSinger(71.48%)。
- 消融实验:
- 去掉平滑(w/o smo.):音高对齐指标(RPA, RCA, OA)略有提升(如OA 73.61%),但风格相似度轻微下降(Acc. 52.71%)。说明平滑算法在保留风格表达与严格对齐乐谱间做了权衡。
- 去掉上下文(w/o ctx.):所有指标均下降,尤其风格相似度显著变差(Acc. 52.12% vs 51.85%),证明了基于上下文的填充机制对风格建模的重要性。
主观评估: 详细MOS分数已在核心摘要部分表格列出。关键发现:
- APC:StylePitcher在风格保留(3.64 vs 3.21)和整体质量(3.26 vs 3.03)上显著优于Diff-Pitcher,但在音高校正准确性(MOS-P)上略低(3.84 vs 4.18),这表明它更倾向于生成个性化修正而非机械对齐。
- SVS:StylePitcher的风格捕捉能力(3.33)优于StyleSinger(3.07),质量相当(3.11 vs 3.07),验证了其作为即插即用模块的有效性。
- SVC:与使用原始F0的基线相比,StylePitcher在风格捕捉(2.95 vs 2.62)上有提升,但整体质量(2.72 vs 3.03)略低,印证了论文提到的在缺乏内容感知时可能产生不自然结果的局限性。
(此图已在“模型架构”部分引用并说明)
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个清晰、统一的框架来解决唱歌音高生成的两个核心问题(风格与通用性)。技术路线(流匹配+掩码填充)选择合理,实验设计全面,覆盖了三个不同的下游任务,并进行了充分的消融研究。证据链完整,从客观指标到主观听感都能支撑其结论。扣分点在于,作为一篇应用导向的论文,理论深度一般,且对于“通用”这一声称,在更复杂、更极端的风格差异场景下的泛化能力未被充分验证。
- 选题价值:1.5/2:唱歌音高建模是音乐生成与转换领域的关键中间表示,其质量直接影响最终音频的表现力。该工作直面现有方法的痛点,提出的即插即用解决方案具有明确的实际应用价值(如音乐制作、卡拉OK应用、虚拟歌手)。标签为#歌唱语音合成,属于垂直但重要的音乐信息处理领域。
- 开源与复现加成:0.5/1:论文提供了在线Demo链接(https://stylepitcher.github.io/),并给出了非常详细的训练配置(模型尺寸、优化器、学习率、调度、数据处理流程等),复现基础良好。然而,论文未明确提及是否开源代码、模型权重和预处理数据集,因此无法给予更高的加成。