📄 Style-Disentangled Diffusion for Controllable and Identity-Generalized Speech-Driven Body Motion Generation
#语音驱动动作生成 #扩散模型 #对比学习 #解耦学习
✅ 7.0/10 | 前25% | #语音驱动动作生成 | #扩散模型 | #对比学习 #解耦学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Zixiang Lu(西安电子科技大学计算机科学与技术学院)
- 通讯作者:Zhitong He, Qiguang Miao(西安电子科技大学计算机科学与技术学院)
- 作者列表:Zixiang Lu(西安电子科技大学计算机科学与技术学院)、Zhitong He(西安电子科技大学计算机科学与技术学院)、Zixuan Wang(未说明)、Yunan Li(未说明)、Qiguang Miao(西安电子科技大学计算机科学与技术学院)
💡 毒舌点评
亮点:风格解耦模块的设计很巧妙,通过对比学习拉近同一说话人风格码的距离,并用梯度反转从内容特征中剥离身份信息,理论上提升了可控性和可解释性。短板:论文声称的“Identity-Generalized”能力仅在单一数据集(BEATX)的同一说话人测试集上进行定量评估,缺乏跨数据集或对未知说话人的严格泛化验证,说服力稍显不足。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的BEATX数据集,论文中未说明是否提供其他自定义数据。
- Demo:未提及在线演示。
- 复现材料:论文给出了损失函数的权重配置,但缺少训练超参数、模型架构细节等关键复现信息。
- 论文中引用的开源项目:未在正文中明确引用特定开源项目。方法部分参考了Syntalker [11]的分割策略,数据集使用了BEATX [12]。
- 论文中未提及开源计划。
📌 核心摘要
本文针对现有语音驱动身体动作生成方法难以生成匹配抽象个人风格、解耦不充分、可解释性差的问题,提出了名为DSfusion的可控与身份泛化动作生成框架。其核心是通过一个风格解耦模块,从参考动作序列中学习并分离出个人风格特征,同时从语音中提取内容特征,并利用对比学习、梯度反转等技术增强分离效果。与已有方法相比,该模型首次在多身份(Multi-ID)数据集上进行训练,并引入了一个运动精炼模块,以防止解耦后的风格信号在融合过程中被平均化动作所覆盖。在BEATX数据集上的实验表明,该方法在Fréchet Gesture Distance(FGD,5.144 vs 次优5.423)和运动多样性(Diversity,13.912 vs 次优13.057)指标上均优于现有SOTA方法(见表1)。该研究的意义在于提升了语音驱动动画的个性化控制能力和动作的多样性与真实感。主要局限性在于扩散模型带来的推理延迟,以及泛化能力验证的场景有限。
表1:在BEATX测试集上的定量结果对比
| 方法 | FGD ↓ | BC ↑ | Diversity ↑ |
|---|---|---|---|
| Trimodal | 19.759 | 6.442 | 8.894 |
| DisCo | 21.170 | 6.571 | 10.378 |
| CaMN | 8.752 | 6.731 | 9.279 |
| DiffStyleGesture | 10.137 | 6.891 | 11.075 |
| TalkShow | 7.313 | 6.783 | 12.859 |
| EMAGE | 5.423 | 6.794 | 13.057 |
| SynTalker | 6.413 | 7.971 | 12.721 |
| Ours | 5.144 | 7.029 | 13.912 |
| (FGD ×10⁻¹, BC ×10⁻¹) |
🏗️ 模型架构
模型DSfusion的整体架构旨在将语音驱动的身体动作生成重构为一个解耦再重组的任务。整体流程如图1所示。
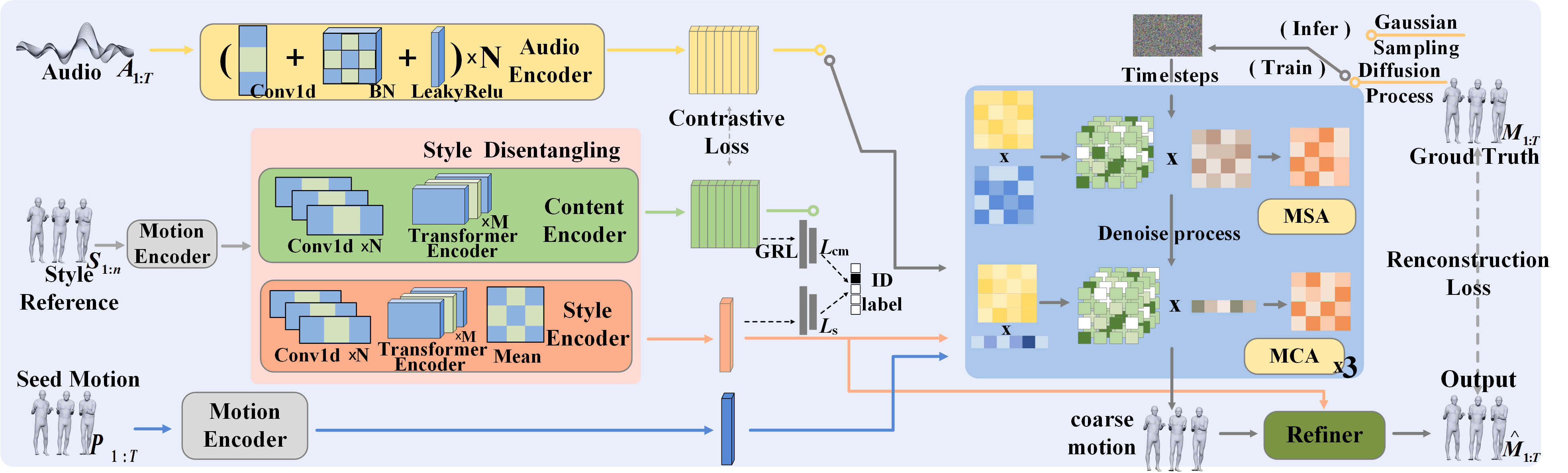 图1:DSfusion框架概览。图中展示了将身体运动分解为语义和风格组件,然后从不同输入中重组的过程。核心流程包括:从输入音频中提取内容特征,从参考动作序列中提取风格特征,通过一个潜在扩散模型(LDM)将这些特征与噪声结合生成粗糙动作,最后通过运动精炼模块输出最终动作。
图1:DSfusion框架概览。图中展示了将身体运动分解为语义和风格组件,然后从不同输入中重组的过程。核心流程包括:从输入音频中提取内容特征,从参考动作序列中提取风格特征,通过一个潜在扩散模型(LDM)将这些特征与噪声结合生成粗糙动作,最后通过运动精炼模块输出最终动作。
- 输入:音频序列A和风格参考动作序列S。
- 运动表示模块:采用RVQ-VAE作为量化骨干,将人体动作离散化到潜在空间。根据Syntalker的策略,将全身动作分割为上半身、手部和下半身,并为每个区域独立训练一组RVQ-VAE。
- 风格解耦模块:这是核心组件,包含三个编码器:
- 内容编码器:一个Transformer,建模音频的时间依赖性,输出帧对齐的内容序列
c1:k。 - 风格编码器:并行分支,通过时间平均池化聚合时间信息,输出一个近似时间不变的风格码
s。 - 语义编码器:将语音视为内容主导信号进行编码
A1:T。 - 该模块引入一个可学习的风格分类器,用于对齐相同身份的风格码;使用内容-对比损失建模语音内容与动作语义特征的共时相关性;并采用一致性目标,确保解耦的特征与从生成动作重新编码得到的特征一致。
- 关键设计:在语义特征上应用梯度反转层与逆分类器,强制内容编码器在编码时消除身份信息,从而实现更干净的风格-内容分离。
- 内容编码器:一个Transformer,建模音频的时间依赖性,输出帧对齐的内容序列
- 潜在扩散模块(LDM):以去噪扩散概率模型为基础,以风格码、前序动作序列特征和内容特征为条件,逐步去噪生成动作序列。训练目标是预测噪声(公式8)。在训练时,内容特征分别从语音和动作中提取;推理时,仅使用语音流的内容特征进行驱动。
- 运动精炼模块:一个包含多层Transformer编码器的模块,通过多头注意力融合风格码,对粗糙生成的动作序列进行精炼,以提升动作质量和风格一致性,防止风格信号被平均化。损失函数为顶点级重构损失(公式9)。
- 输出:精炼后的连续肢体动作序列M。
💡 核心创新点
- 抽象级别的风格解耦与融合架构:提出了一种在潜在空间中将动作分解为内容(语义)和风格两个独立成分的端到端框架。这与以往依赖外部标签(如one-hot ID/情绪)或单ID训练的方法不同,实现了更灵活、数据驱动的风格学习与迁移。
- 增强风格解耦与可解释性的模块:引入了风格分类器、内容-对比损失、一致性损失和梯度反转技术的组合。梯度反转层是关键,它使得内容表示在优化过程中主动“忘记”身份信息,从而确保风格特征承载了主要的身份/个性化信息,大大提升了特征分离的彻底性和结果的可解释性。
- 双阶段流水线(解耦-生成-精炼):在扩散生成后,增加了一个运动精炼模块。这一设计针对多身份数据训练时容易产生的“平均化”偏差问题,确保在最终输出阶段,通过风格引导的融合与精炼,能够有效保护和强化特定的风格信号,从而在保持跨身份泛化能力的同时,增强对个体风格的忠实捕捉。
- 多身份数据训练与泛化:不同于先前方法仅在单个说话人数据(如BEATX Speaker 2)上训练,本文主张并实践在完整的多说话人数据集上训练,这直接提升了模型处理多个身份的能力,使其更适用于现实场景中说话人不固定的应用。
🔬 细节详述
- 训练数据:使用BEATX数据集,一个30小时的多身份多模态语料库,包含30位说话人的同步语音-动作数据。本文使用了所有说话人的数据进行训练,以提升多ID泛化能力。
- 损失函数:总损失L是多个损失的加权和(公式10),包括:
- L_style:风格分类损失(交叉熵),增强身份-风格一致性。
- L_contrastive:内容-对比损失,建模共时语音与动作语义的相关性。
- L_consistency(Ls_consistency和Lc_consistency):一致性损失,确保解耦特征与重构特征匹配。
- L_cm:逆分类损失(带梯度反转),剥离内容特征中的身份信息。
- L_diff:扩散模型训练目标(预测噪声)。
- L_recon:运动精炼模块的顶点重构损失。
- 各损失权重已给出具体数值(如λ_diff=1.0, λ_recon=0.5等)。
- 训练策略:论文未详细说明学习率、优化器、batch size、训练步数/轮数等具体训练策略。
- 关键超参数:模型架构细节如Transformer层数、隐藏维度、RVQ-VAE的码本大小、潜空间维度等论文中未具体说明。
- 训练硬件:论文中未提供训练所用的GPU型号、数量及训练时长。
- 推理细节:推理时,LDM使用来自语音流的内容特征、风格码以及前序动作序列特征作为条件生成动作。扩散过程的具体采样步数等细节未说明。
- 正则化或稳定训练技巧:除梯度反转层外,未提及其他特定的正则化技巧。
📊 实验结果
- 主要基准与数据集:在BEATX数据集上进行实验,为了公平比较,与其他方法一样在Speaker 2的测试集上进行定量评估。
- 主要指标与数值(见上文表1):
- FGD:本方法为5.144,优于次优的EMAGE(5.423),降低约5%。
- Diversity:本方法为13.912,优于次优的EMAGE(13.057),提升约6.6%。
- BC:本方法为7.029,略低于SynTalker(7.971),但高于其他方法。
- 与最强基线对比:在FGD和多样性两个核心指标上,DSfusion取得了最佳成绩。
- 消融实验(见下文表2):
- 移除风格分类器(w/o Lstyle)导致FGD大幅上升(7.829),多样性下降至9.794,说明身份风格对齐至关重要。
- 移除一致性损失(w/o Ls_consistency)或逆分类损失(w/o Lcm)也导致性能下降,验证了这些解耦设计组件的有效性。
- 移除对比损失(w/o L_contrastive)同样损害了性能。
- 移除精炼模块(w/o Refiner)后,虽然性能仍优于基线(FGD 6.013, Diversity 12.938),但加入精炼模块后各项指标均有提升,证明了其在提升动作保真度方面的作用。
表2:消融研究结果
| 方法 | FGD ↓ | BC ↑ | Diversity ↑ |
|---|---|---|---|
| GT | 0.000 | 6.897 | 12.755 |
| Ours w/o Lstyle | 7.829 | 6.471 | 9.794 |
| Ours w/o Ls_consistency | 6.827 | 6.775 | 10.913 |
| Ours w/o Lcm | 6.107 | 7.018 | 11.033 |
| Ours w/o L_contrastive | 7.548 | 6.994 | 10.902 |
| Ours w/o Refiner | 6.013 | 6.990 | 12.938 |
| Ours | 5.144 | 7.029 | 13.912 |
| (FGD ×10⁻¹, BC ×10⁻¹) |
- 定性评估:
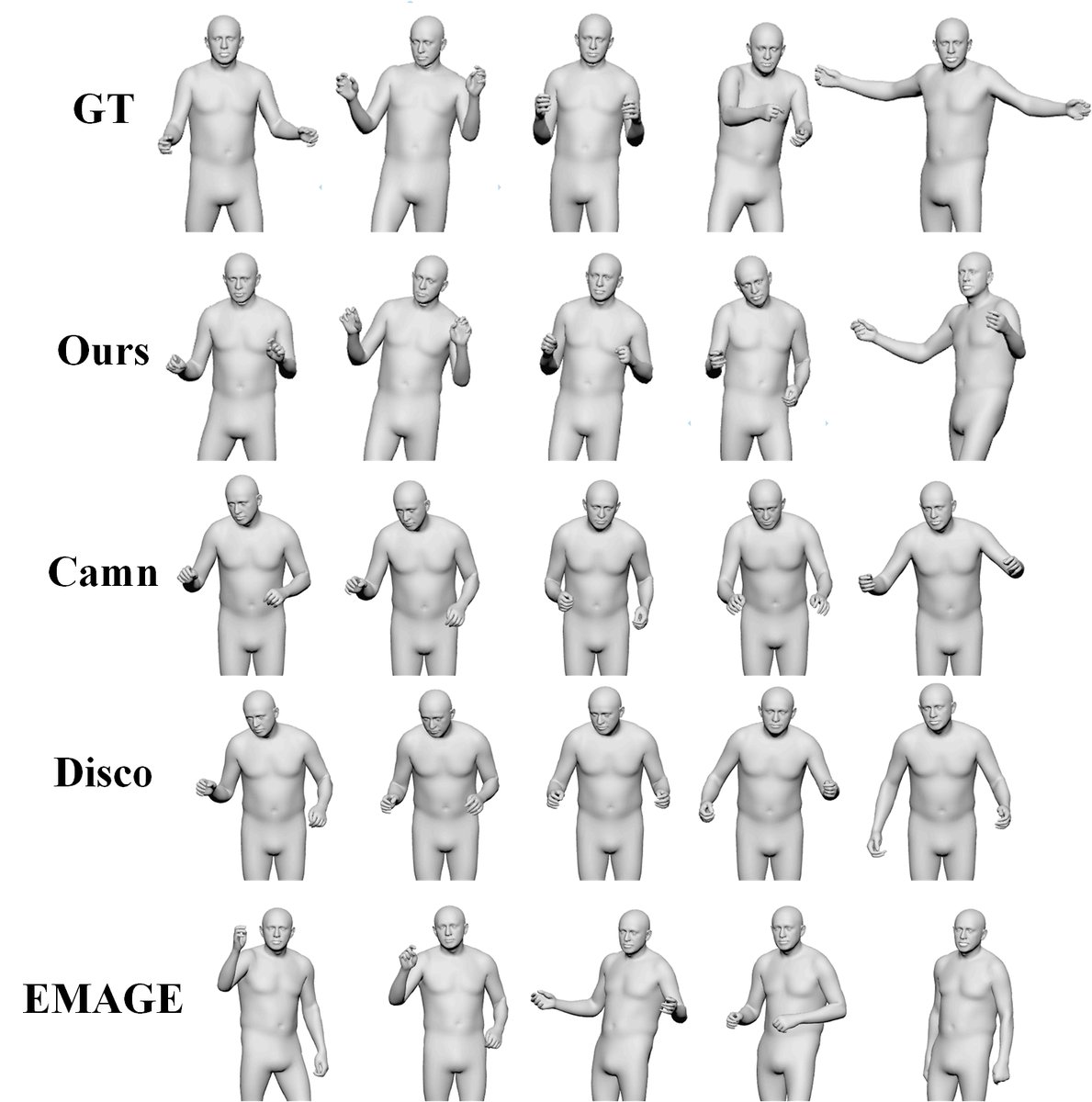 图2:生成的动作序列对比。从上到下为:真实值(GT)、Ours、CaMN、DisCo、EMAGE。展示了在Speaker-2测试片段上生成的动作,表明本方法能可靠地实现语音同步的手势合成。
图2:生成的动作序列对比。从上到下为:真实值(GT)、Ours、CaMN、DisCo、EMAGE。展示了在Speaker-2测试片段上生成的动作,表明本方法能可靠地实现语音同步的手势合成。
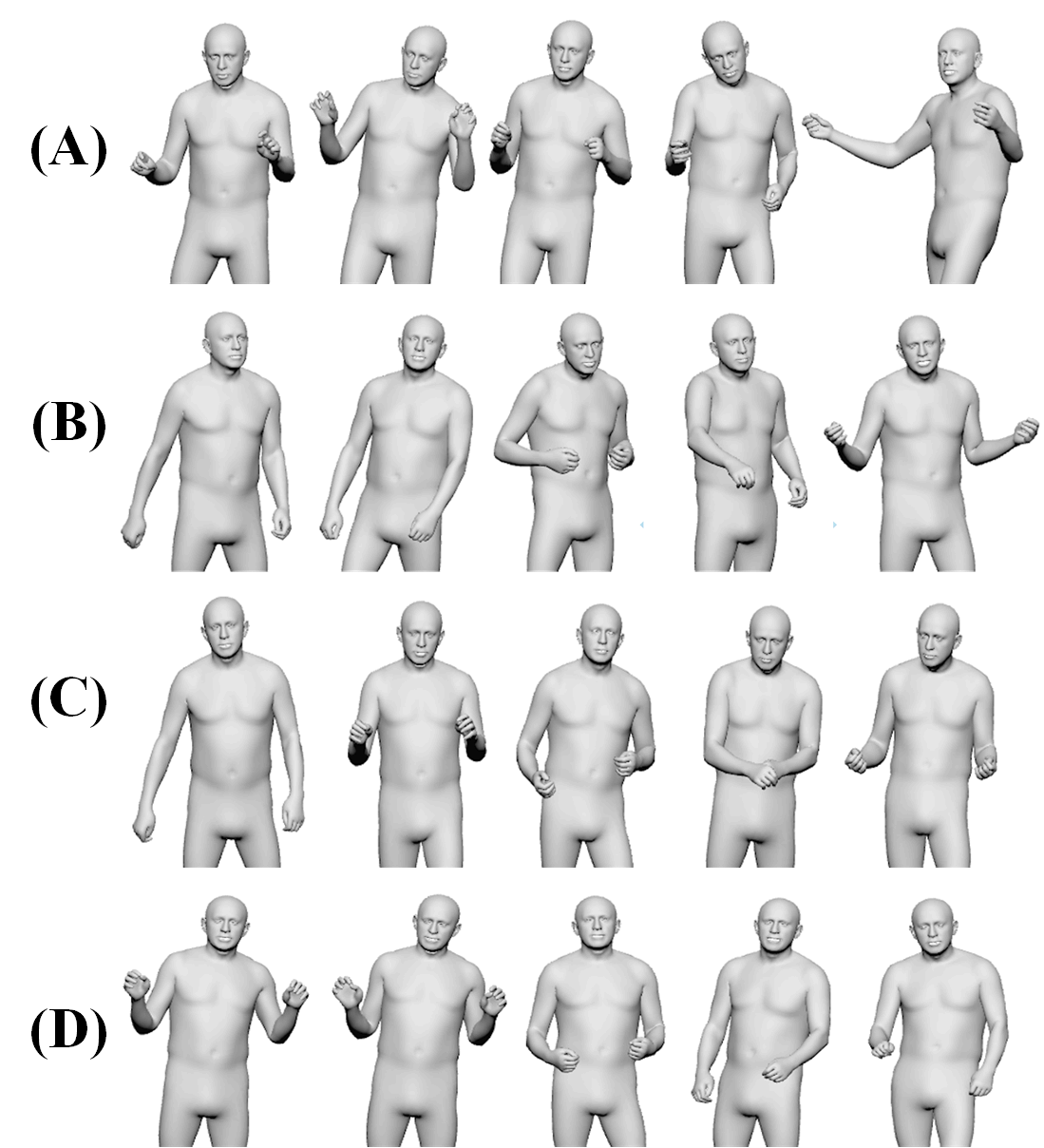 图3:不同风格码生成的身体动作。表明即使输入相同的语音内容,切换风格码也会产生不同的动作模式,验证了风格特征的成功解耦。
图3:不同风格码生成的身体动作。表明即使输入相同的语音内容,切换风格码也会产生不同的动作模式,验证了风格特征的成功解耦。
⚖️ 评分理由
- 学术质量:6.5/7。创新性体现在提出的风格解耦架构和梯度反转等技术组合上。技术方案完整,逻辑自洽。实验在选定数据集上充分,消融研究有力地支持了各模块的贡献。扣分点在于技术细节(如模型具体配置)未完全公开,且泛化能力验证范围较窄。
- 选题价值:1.5/2。语音驱动动作生成是计算机图形学和人机交互的前沿课题,提升其可控性和个性化是重要方向,具有广泛的应用潜力。
- 开源与复现加成:0.5/1。论文使用了公开数据集(BEATX),这有利于复现基础实验。但论文未提供代码、预训练模型权重或详细的训练配置(如优化器设置、完整超参数),使得独立复现其完整框架存在较大困难。