📄 Structure-Aware Diffusion Schrödinger Bridge
#数据集对齐 #扩散模型 #领域适应
✅ 7.7/10 | 前50% | #数据集对齐 | #扩散模型 | #领域适应
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:未说明
- 通讯作者:未说明
- 作者列表:Dawnlicity Charls (新南威尔士大学电气工程与电信学院)、Tharmakulasingam Sirojan (新南威尔士大学电气工程与电信学院)、Vidhyasaharan Sethu (新南威尔士大学电气工程与电信学院)、Beena Ahmed (新南威尔士大学电气工程与电信学院)
💡 毒舌点评
亮点:巧妙地将Gromov-Wasserstein距离的核心思想(保持相对结构)转化为一个可直接加入扩散模型训练的正则化损失项,用最小的“补丁”解决了Schrödinger Bridge在数据对齐中破坏数据拓扑的实际痛点。短板:整篇论文的实验说服力严重依赖“在合成数据上效果好”这一环,若没有在如MRI-CT转换、跨域图像翻译等真实且公认的挑战性任务上展示其“结构保持”带来的下游性能提升(如分类准确率),这篇工作更像一个“技术上可行、但尚未证明实用价值”的实验性探索。
🔗 开源详情
- 代码:论文中未提及本工作(SDSB)的代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用了合成数据集,未提及是否公开具体生成脚本或数据文件。
- Demo:未提供在线演示。
- 复现材料:论文提及了基于DSBM [8]的代码库进行实现,并给出了关键超参数(λ=100,内/外层迭代次数,网络结构等),但未提供完整的训练配置文件或详细步骤。论文中未提及开源计划。
- 论文中引用的开源项目:明确引用并基于 [8] Diffusion Schrödinger Bridge Matching 的代码库进行实验。
📌 核心摘要
- 解决什么问题:现有的基于Schrödinger Bridge (SB)的数据集对齐方法在学习分布间的映射时,缺乏对数据内在几何结构(如聚类、相对距离)的感知,可能导致在传输过程中破坏这些对下游任务至关重要的结构。
- 方法核心:提出Structure-aware Diffusion Schrödinger Bridge (SDSB),在原始Diffusion Schrödinger Bridge (DSB)的训练损失中,加入一个基于Gromov-Wasserstein (GW) 距离的结构正则化项。该正则化项通过最小化每个扩散步前后样本距离矩阵的差异,迫使模型在传输分布的同时保持样本间的相对关系。
- 与已有方法相比新在哪里:与需要成对数据的SB-ALIGN相比,SDSB完全无监督;与解决离散最优传输的Gromov-Wasserstein方法相比,SDSB能在连续空间操作;最重要的是,与标准DSB相比,SDSB通过显式约束改变了优化目标,从纯粹的熵最优传输变为结构感知的传输。
- 主要实验结果:在合成数据集(双月形、高斯混合)上验证了SDSB的有效性。
- 几何保持:将月牙数据旋转60°时,DSB会分裂月牙,而SDSB保持了其完整形状(如图2所示)。
- 尺度不变性:将月牙数据旋转并缩放时,SDSB能更好地学习旋转变换,生成的样本更贴合目标分布(如图4所示)。
- 聚类保持:在高斯混合模型传输实验中,SDSB的聚类传输分数显著高于DSB,更接近理想值,表明其更好地保持了聚类结构(定量结果见下表)。
| 维度 | DSB | SDSB (本文) | 真实分布 |
|---|---|---|---|
| 2 | -21.8 | -3.8 | -2.8 |
| 5 | -31.3 | -9.3 | -7.1 |
| 10 | -38.8 | -17.4 | -14.2 |
| 20 | -50.2 | -32.7 | -28.4 |
| 50 | -100.8 | -76.7 | -71.0 |
| 表:高斯混合模型聚类传输分数(越高越好)。 | |||
| 5. 实际意义:为需要保持数据内在结构(如类别、相对关系)的数据集对齐任务(如无监督域适应、跨域图像翻译)提供了一种新的、完全无监督的算法选择。 | |||
| 6. 主要局限性:论文所有验证均在低维合成数据集上进行,未在任何真实世界的高维数据集(如图像、语音)上进行评估,其实用性和泛化能力未得到证明。训练时间加倍也是潜在的应用障碍。 |
🏗️ 模型架构
本文未提出全新的神经网络架构,而是在现有的Diffusion Schrödinger Bridge (DSB)训练框架上添加了一个正则化项。SDSB的整体架构/训练流程如下:
- 基础模型:沿用DSB [7]的架构,包含两个神经网络模型(通常为MLP),分别参数化前向扩散过程 \(\theta_f\) 和后向扩散过程 \(\theta_b\)。每个模型输入是时间步 \(t\) 和样本 \(X_t\),输出是对扩散过程的预测。
- 训练框架:采用迭代比例拟合 (IPF) 进行交替训练。在每个“外层迭代”中,固定一个模型(如 \(\theta_b\)),用来自目标分布 \(p_1\) 的数据训练另一个模型(\(\theta_f\))来逆转其步骤,然后交换角色。
- 核心创新组件 - 结构正则化项 (SL):
- 计算过程:在一个训练批次中,先按时间步 \(t\) 对样本分组。对于时间步 \(t\) 下的样本集 \(X_t\),使用当前模型 \(\theta\) 计算扰动后的预测样本 \(X_{t+\theta}\)。然后计算 \(X_t\) 和 \(X_{t+\theta}\) 之间的归一化GW损失 \(D(X_t, X_{t+\theta})\)(公式2,3)。批次上的结构损失SL是这些时间步损失的均值(公式4)。
- 集成方式:最终训练损失为原始DSB损失 \(L_{DSB}\) 与结构损失SL的加权和:\(L_{DSB} + \lambda SL\)(公式5)。该正则化在前向和后向模型训练时均被应用。
- 数据流:训练时,在每个优化步骤中,对于一个批量数据,模型需要同时最小化其将数据分布向目标分布传输的损失(\(L_{DSB}\)),以及最小化在该传输步骤中改变数据相对结构的损失(SL)。这迫使模型在每一步都寻找一个“结构友好”的传输方向。 论文中未提供模型架构图。
💡 核心创新点
- 无监督的结构保持对齐:在完全不使用任何配对数据或标签信息的前提下,通过修改DSB的训练目标,实现了对数据几何结构(聚类、相对距离)的感知和保持。这解决了现有SB方法在无监督设置下的核心缺陷。
- 基于Gromov-Wasserstein距离的正则化设计:将原本用于计算两个分布间结构差异的GW距离,巧妙地转化为一个在扩散训练过程中可微分的正则化损失项。通过最小化每个扩散步前后样本距离矩阵的差异,实现了对局部传输结构的约束。
- 尺度不变的结构匹配:通过将距离矩阵元素除以平均距离进行归一化(公式3),使得结构匹配对数据的整体缩放不敏感,增强了方法在面对不同尺度目标分布时的鲁棒性。
🔬 细节详述
- 训练数据:使用合成数据集,包括二维/高维双月形数据、高斯混合模型数据。数据规模:每个数据集10000个训练样本。预处理:未说明具体预处理,推测为直接使用生成的坐标点。
- 损失函数:主损失为原始DSB损失 \(L_{DSB}\) [7]。正则化损失为公式(4)和(5)定义的结构损失SL。正则化权重 \(\lambda\) 经验性设置为100。
- 训练策略:基于DSB的IPF训练。每个扩散模型使用MLP(2层隐藏层,每层256神经元)。训练参数:1000内层迭代(每个模型的梯度更新步数),40外层迭代(除非特别说明),20个时间步。学习率:\(1 \times 10^{-4}\)。优化器:未说明。批量大小:128。
- 关键超参数:正则化权重 \(\lambda = 100\)。结构损失计算依赖于批量内样本按时间步的分组,平均每个时间步约6个样本。
- 训练硬件:论文中未提及。
- 推理细节:论文中未详细说明推理(采样)过程的细节,仅提到生成样本和轨迹。
- 正则化或稳定训练技巧:本文提出的结构损失本身就是一种正则化。论文提到其计算成本与生成训练轨迹的成本相当,导致SDSB训练时间约为DSB的两倍。
📊 实验结果
所有实验均在合成数据集上进行,旨在验证结构保持能力。 主要对比实验:
双月形数据旋转:
- 结果:如图2所示。旋转45°时,DSB生成的样本密度不正确(中间密、两端疏),而SDSB生成更均匀、更接近目标分布的月牙。旋转60°时,DSB会分裂月牙结构以最小化传输成本,而SDSB成功保持了月牙的完整性和簇结构。
- 损失曲线:图3显示,DSB的结构损失(SL)在训练中保持较高水平,而SDSB的SL则收敛到很低,表明结构差异被有效抑制。
双月形数据旋转并缩放:
- 结果:如图4所示。当目标月牙被缩小时,DSB在两个月牙之间生成了错误的样本;当目标月牙被放大时,DSB会将同一月牙的部分样本错误传输到不同月牙。SDSB则能更好地学习旋转变换,生成的样本更贴合目标分布,尤其在处理尺度变化时优势明显。
高斯混合模型传输:
- 结果:如图5所示(2维)。DSB将初始的两个高斯簇拆开以最小化传输成本,而SDSB将每个簇完整地传输到目标位置。
- 定量指标(聚类传输分数):见上文核心摘要中的表格。在所有维度(2至50维)上,SDSB的分数均显著优于DSB,且更接近理想的真实分布分数,量化证明了其在聚类保持上的优越性。
实验结果图表:
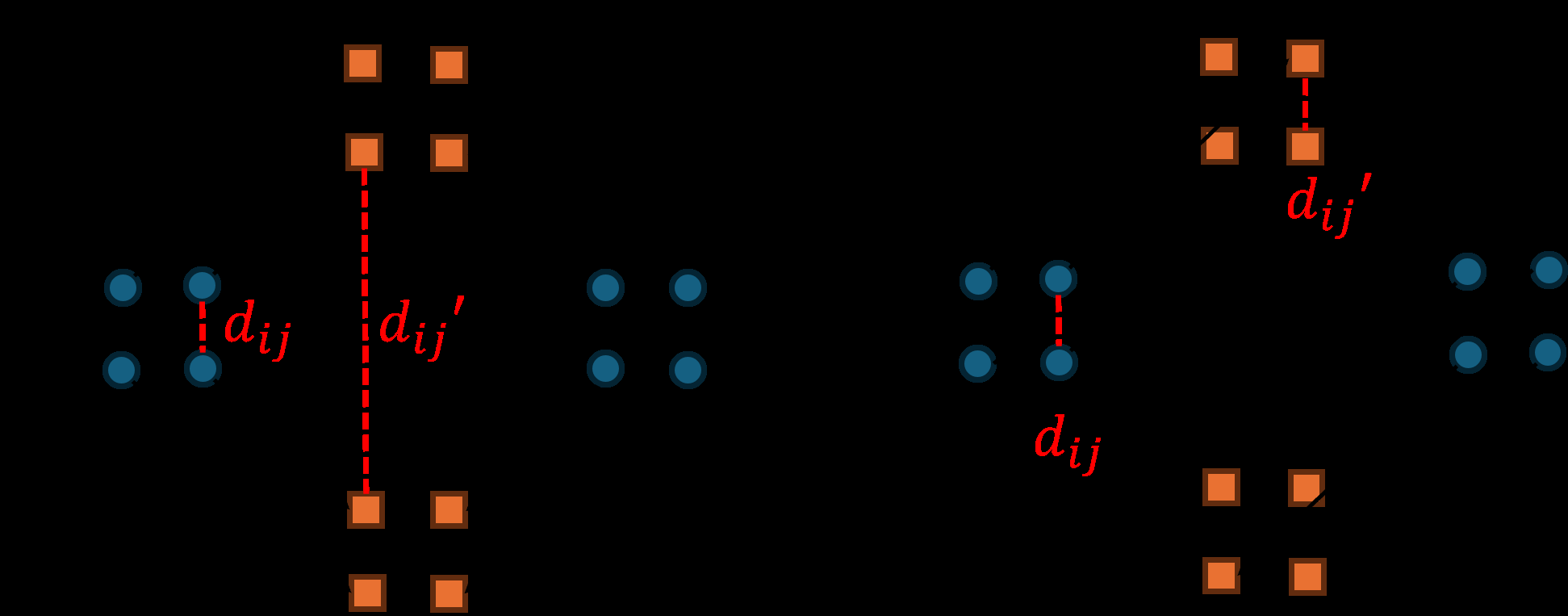 图1说明:直观展示了标准最优传输(OT/SB)可能破坏数据簇结构(a),而本文追求的是保持样本间相对距离的映射(b),这是提出正则化项的动机。
图1说明:直观展示了标准最优传输(OT/SB)可能破坏数据簇结构(a),而本文追求的是保持样本间相对距离的映射(b),这是提出正则化项的动机。
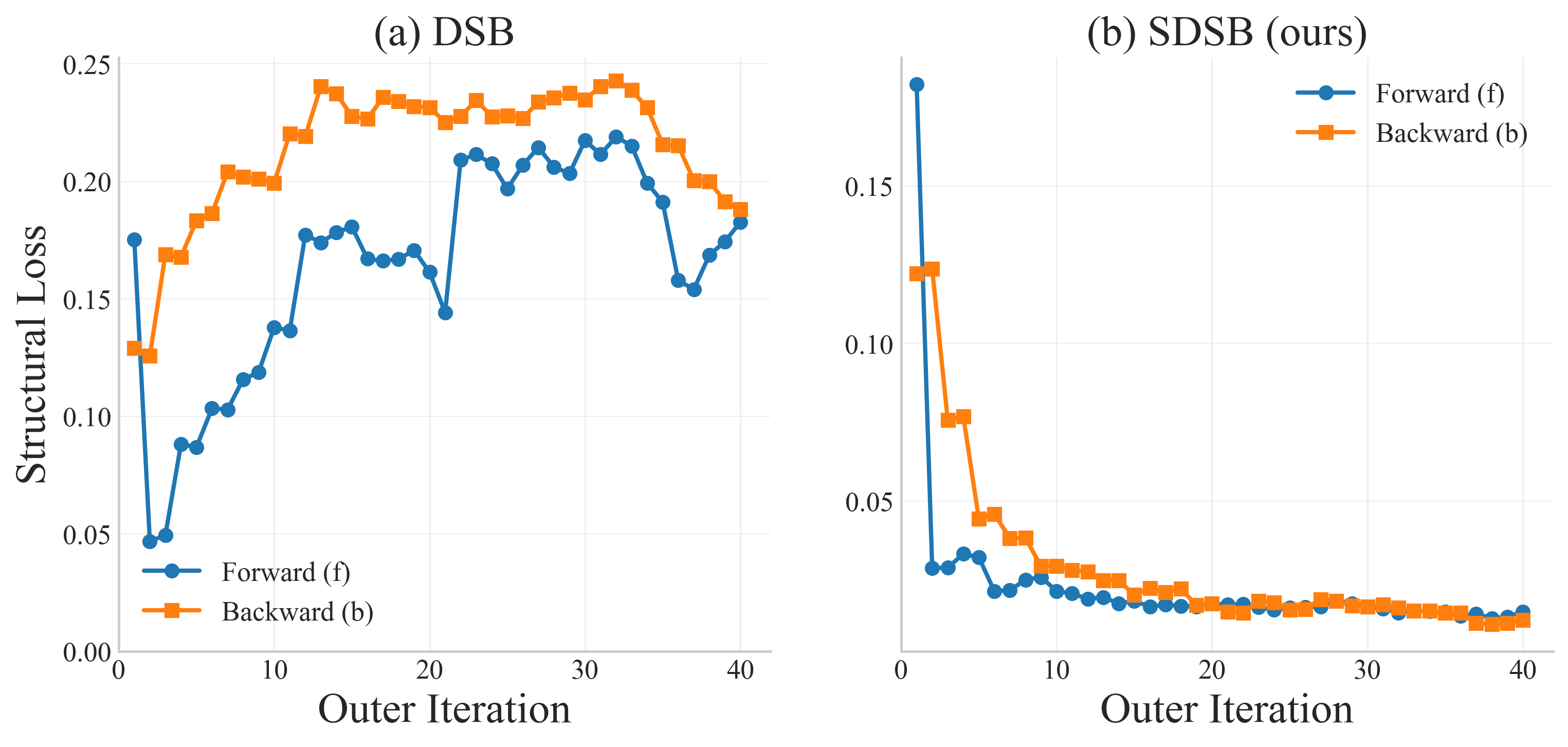 图2说明:展示了DSB与SDSB在不同旋转角度下的传输轨迹和生成样本。关键结论是SDSB在更大角度下仍能保持月牙几何形状。
图2说明:展示了DSB与SDSB在不同旋转角度下的传输轨迹和生成样本。关键结论是SDSB在更大角度下仍能保持月牙几何形状。
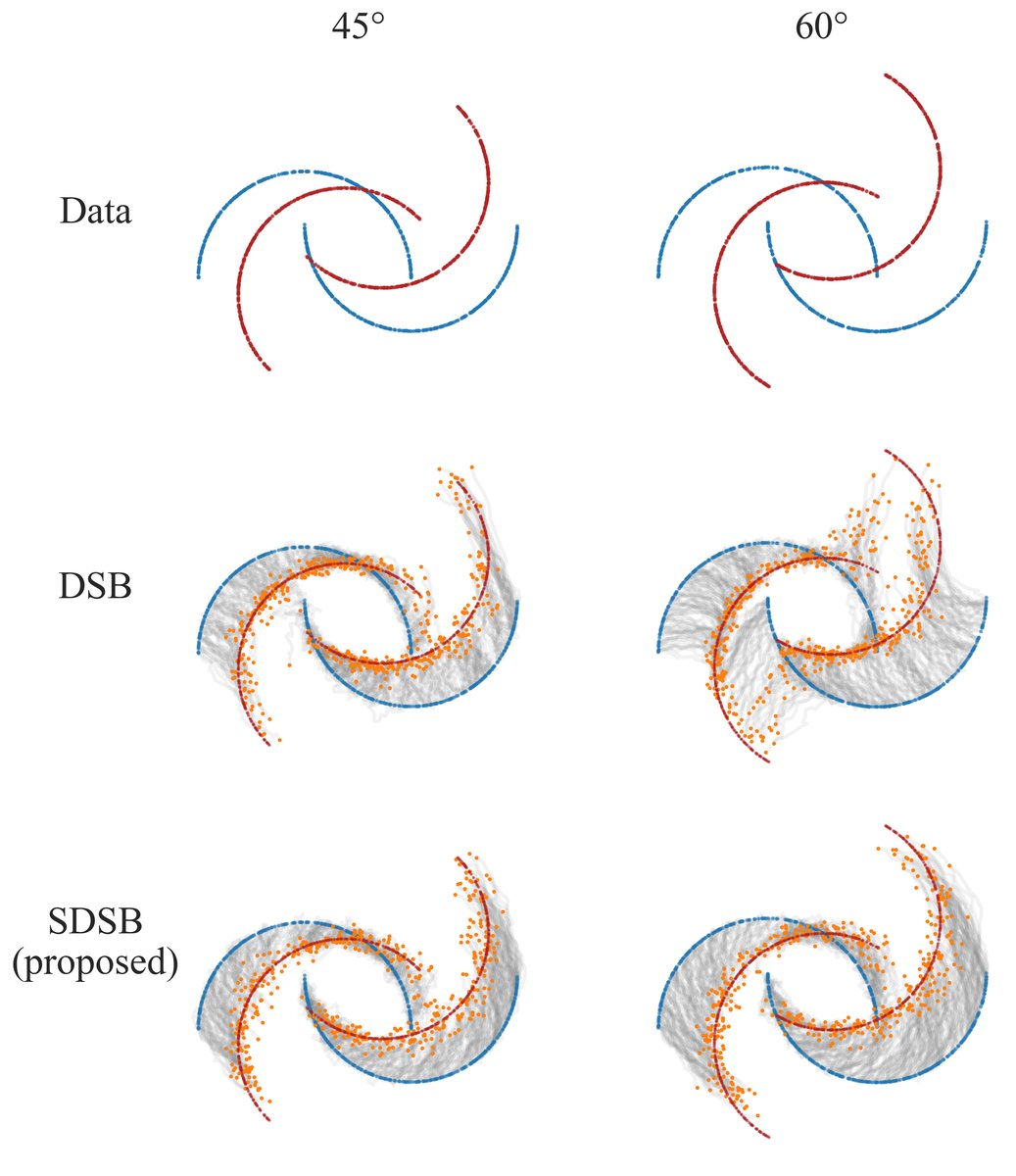 图3说明:展示了在月牙->60°月牙任务中,DSB和SDSB训练过程中结构损失的变化。关键结论是SDSB的结构损失能有效收敛至低值。
图3说明:展示了在月牙->60°月牙任务中,DSB和SDSB训练过程中结构损失的变化。关键结论是SDSB的结构损失能有效收敛至低值。
 图4说明:展示了在目标分布发生尺度变化时,DSB与SDSB的传输效果。关键结论是SDSB的结构保持具有尺度不变性。
图4说明:展示了在目标分布发生尺度变化时,DSB与SDSB的传输效果。关键结论是SDSB的结构保持具有尺度不变性。
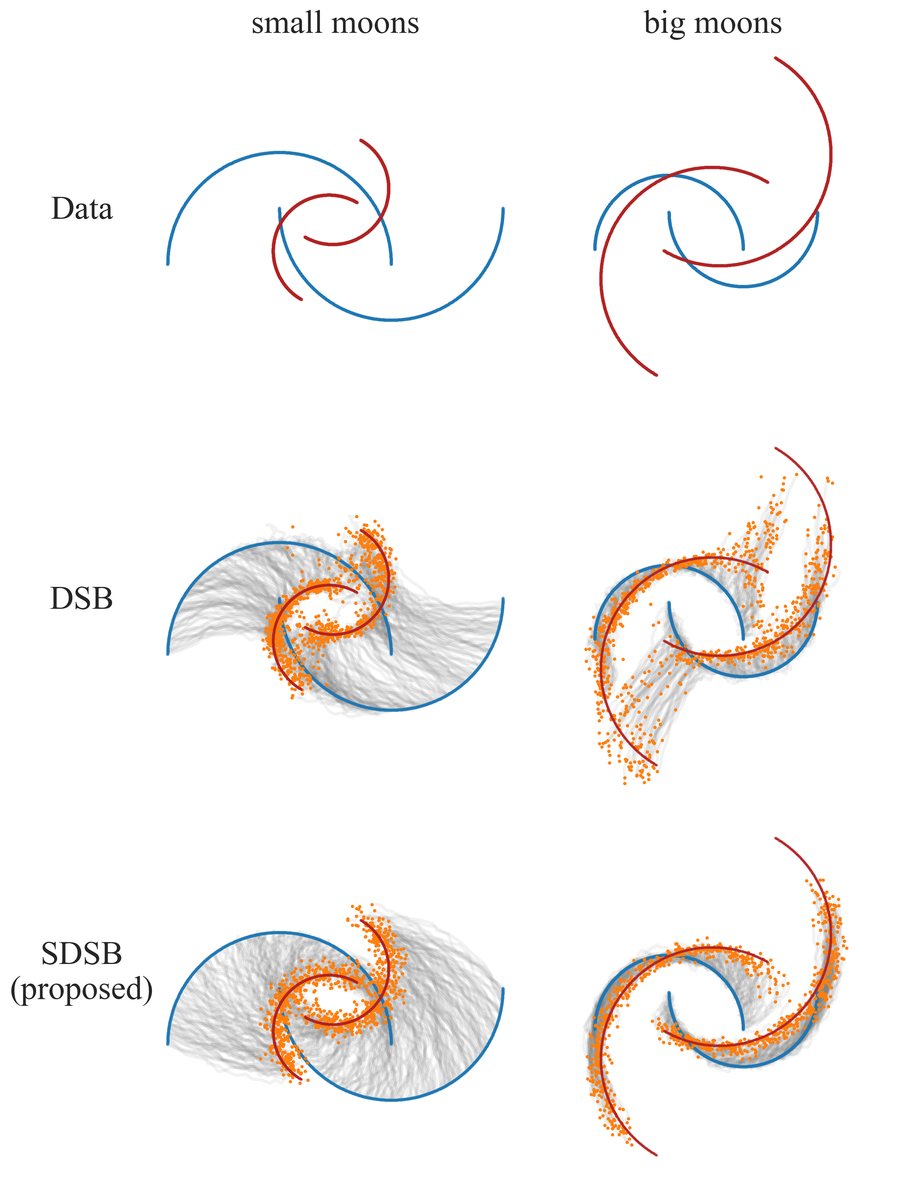 图5说明:展示了2维高斯混合模型的传输轨迹。关键结论是DSB会分裂聚类,而SDSB能保持聚类完整。
图5说明:展示了2维高斯混合模型的传输轨迹。关键结论是DSB会分裂聚类,而SDSB能保持聚类完整。
⚖️ 评分理由
- 学术质量:6.2/7。论文提出了一个清晰、合理的创新点(结构正则化),技术路线正确,理论动机充分。实验在合成数据上设计得当,提供了可视化和定量证据(聚类传输分数表)来支持其主张。主要失分点在于实验场景过于简单(仅限低维合成数据),未能在高维、真实世界任务上展示其价值,也缺乏与同领域强基线的全面比较,使得结论的影响力大打折扣。
- 选题价值:1.5/2。解决数据集对齐中的结构破坏问题具有明确的理论价值和广泛的应用背景。选题聚焦于现有SB方法的一个实际弱点,方向正确。扣分是因为论文展示的应用潜力受限于实验验证的局限性,未能充分展现其在更复杂场景下的必要性。
- 开源与复现加成:0.0/1。论文未提供任何代码、模型或详细复现指南,尽管提到了基于公开代码实现,但独立复现本工作仍存在较大不确定性,因此无加成。