📄 StreamMark: A Deep Learning-Based Semi-Fragile Audio Watermarking for Proactive Deepfake Detection
#音频深度伪造检测 #端到端 #鲁棒性 #数据集
🔥 8.0/10 | 前25% | #音频深度伪造检测 | #端到端 | #鲁棒性 #数据集
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Zhentao Liu(EPFL, Switzerland)
- 通讯作者:未说明
- 作者列表:Zhentao Liu(EPFL, Switzerland)、Milos Cernak(Logitech Europe, Switzerland)
💡 毒舌点评
这篇论文巧妙地将图像领域的“半脆弱水印”概念移植到音频,并精准定义了“良性”与“恶意”操作,为应对深度伪造提供了比传统鲁棒水印更聪明的“主动告警”方案,思路值得称赞。然而,其将所有深度伪造攻击简化为“变调”这一单一操作进行模拟,失真层的设计略显“偷懒”,可能无法完全覆盖未来更复杂的合成攻击(如更自然的音色替换或内容编辑),削弱了结论的绝对说服力。
🔗 开源详情
- 代码:提供了代码仓库链接:https://github.com/L1uZhentao/deepfake_benchmark
- 模型权重:论文中未提及公开预训练模型权重。
- 数据集:论文开源了用于评估的深度伪造基准测试集(Deepfake Benchmark),作为代码仓库的一部分发布。
- Demo:未提及。
- 复现材料:提供了充分的训练细节,包括数据集(LibriSpeech子集)、模型参数量、损失函数公式与权重、优化器超参数(Adam,β值,学习率)、训练硬件(2x RTX 2080),这为复现提供了良好基础。
- 论文中引用的开源项目:未提及依赖的其他开源工具或模型。
- 总结:论文在可复现性方面表现良好,开源了关键的数据和代码,但缺少现成的模型权重。
📌 核心摘要
要解决什么问题:现有的被动深度伪造音频检测方法面临泛化能力差、易被对抗攻击绕过、难以区分良性AI处理(如降噪)与恶意伪造的困境。传统鲁棒水印在伪造后仍能提取,反而无法证明音频已被篡改。
方法核心是什么:提出StreamMark,一种基于深度学习的半脆弱音频水印系统。其核心是设计一个Encoder-Distortion-Decoder架构,其中失真层包含并行的良性变换(如裁剪、加噪)和恶意变换(如变调,模拟音色/内容篡改)。通过复合损失函数训练,使水印在经历良性操作后仍可恢复,但在经历语义篡改的恶意操作后无法恢复(准确率降至随机水平)。
与已有方法相比新在哪里:首先,提出了音频水印的“半脆弱性”范式,改变了以“鲁棒性”为单一目标的传统思路。其次,采用了在STFT复数域(同时修改幅度和相位)嵌入水印的新技术,以提升不可感知性。最后,构建并开源了首个专门针对AI音频转换(包含良性与恶意)的深度伪造评估基准。
主要实验结果如何:
不可感知性与鲁棒性(测试集A):StreamMark达到了较高的PESQ分数(4.20),并保持了对Opus编码等真实世界良性失真的高鲁棒性(ACC > 99.89%)。
深度伪造基准(测试集B):面对VALL-E-X、FreeVC、VoiceCraft等深度伪造攻击时,水印恢复准确率(ACC)下降至约50%(随机猜测水平),体现其“脆弱性”;而在面对DeepAFX等良性风格迁移时,ACC保持在98%以上,体现其“鲁棒性”。
详细数据见下表: 表1:不可感知性与鲁棒性评估(测试集A)
方法 SNR (dB) PESQ SECS 裁剪 (70%) MP3 (8 kbps) Opus (60 ms) Patchwork 33.65 4.34 0.99 0.72 0.61 0.85 AudioSeal 25.41 4.30 0.99 1.00 0.85 0.57 Timbre 24.14 3.70 0.99 0.99 0.79 0.99 StreamMark 24.16 4.20 0.99 0.99 0.87 0.99 表2:深度伪造基准评估(测试集B)
类型 模型/风格 ACC (%) 期望行为 恶意 (脆弱性) VALL-E-X (TTS) 51.01 脆弱 (破坏) FreeVC (VC) 49.75 脆弱 (破坏) VoiceCraft (Editing) 51.79 脆弱 (破坏) 良性 (鲁棒性) DeepAFX (Bright) 100.00 鲁棒 (保留) DeepAFX (Broadcast) 98.73 鲁棒 (保留) DeepAFX (Telephone) 98.34 鲁棒 (保留)
实际意义是什么:为数字音频内容提供了一种主动的、可编程的真实性验证机制。音频在源头嵌入水印后,任何意图改变其语义的篡改都会导致水印失效,从而发出警报。这对于建立可信的通信链路(如企业会议、新闻广播)和对抗日益猖獗的AI语音诈骗具有重要应用价值。
主要局限性是什么:1) 恶意变换模拟简单:仅用变调来代表所有深度伪造攻击,可能无法涵盖未来更复杂的合成技术。2) 部署前提限制:该方案要求音频源头(如麦克风、录音设备)必须预先集成StreamMark编码器,这对于现有基础设施的改造是巨大挑战。3) 安全性讨论不足:未深入探讨攻击者可能通过逆向工程或对抗样本绕过水印的潜在风险。
🏗️ 模型架构
StreamMark采用 Encoder-Distortion-Decoder 的三阶段端到端架构(见图1),核心在于训练时引入模拟现实变换的失真层。
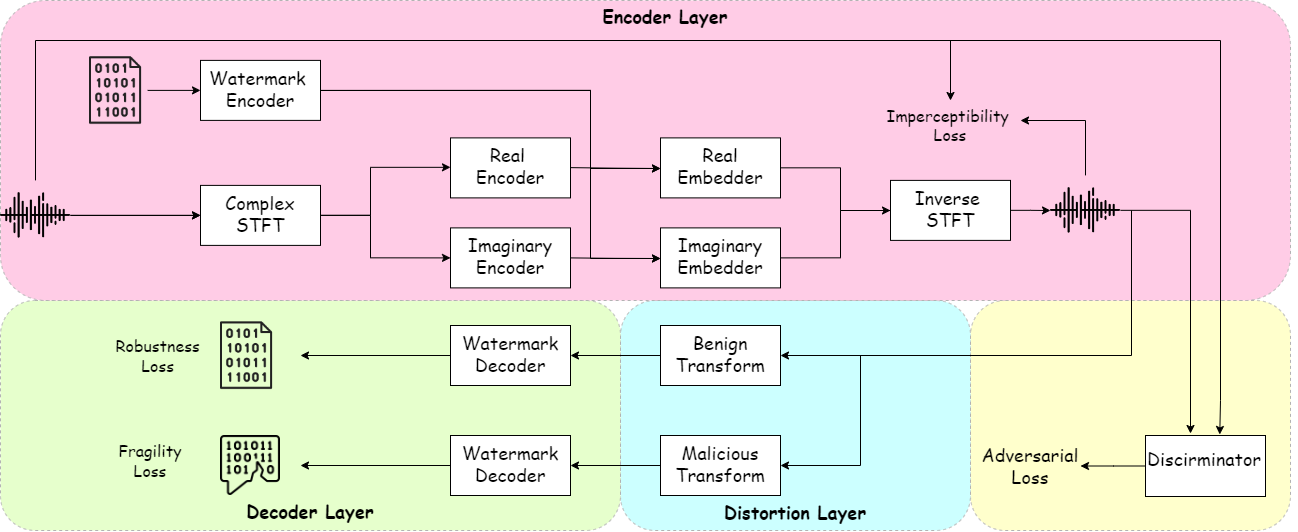
编码器层:负责将水印嵌入原始音频。
- 输入:原始音频信号。
- 流程:首先通过短时傅里叶变换(STFT)将音频从时域转换到频域,得到实部和虚部两个频谱分量。这两个分量被分别送入两个并行的实部编码器和虚部编码器(均为6层卷积网络,使用“skip gated block”作为基本单元)。这两个编码器生成“水印载体”。一个水印编码器(512维全连接层+LeakyReLU)将16位的水印消息编码为高维特征。最后,该特征被嵌入到实部和虚部的频谱中。
- 输出:嵌入水印后的实部和虚部频谱,再通过逆STFT转换回时域,得到含水印音频。
- 设计动机:在复数域(同时修改幅度和相位)嵌入水印,是基于人耳对相位失真相对不敏感的心理声学原理,旨在提升水印的不可感知性。
失真层:这是训练时特有的模块,模拟现实中的音频转换,不参与推理。
- 包含两组并行的变换操作:良性转换集和恶意转换集。训练时随机选择应用其中一种。
- 良性转换集:包括裁剪、高斯噪声、重采样、滤波、重量化等标准信号处理操作,模拟正常的录制、传输和存储过程。
- 恶意转换集:主要通过变调来模拟深度伪造攻击中常见的音色篡改。
- 作用:为模型提供区分两类操作的训练信号。
解码器层:负责从可能经过失真的音频中提取水印。
- 输入:含水印音频(可能已失真)。
- 流程:同样先进行STFT得到实部和虚部分量。然后通过两个并行的实部解码器和虚部解码器(结构与编码器类似)提取水印特征。最后,一个水印解码器(线性全连接层)将提取的特征还原为16位水印消息。
- 关键设计:解码器在时间维度上使用了平均池化,这增强了模型对裁剪和丢包等失同步攻击的鲁棒性。
- 输出:恢复的水印消息。
💡 核心创新点
- 半脆弱水印范式应用于音频深度伪造检测:首次在音频领域提出并实现了“半脆弱水印”概念。不同于传统水印追求“在任何情况下都鲁棒”,也不同于脆弱水印“任何改变都失效”,StreamMark旨在对良性的、语义不变的操作鲁棒,对恶意的、语义改变的伪造攻击脆弱。这从根本上改变了水印的目标,使其成为检测语义篡改的“指示器”。
- 复杂域嵌入技术:突破了大多数深度学习音频水印仅在幅度谱或实数域操作的限制,直接在STFT的复数域(实部+虚部)同时进行水印嵌入。这充分利用了相位信息,提升了水印的不可感知性,实验也证明其PESQ得分优于基线。
- 显式模拟双路径的训练目标:设计了包含良性与恶意变换的并行失真层,并构建了与之匹配的复合损失函数。该函数通过最小化良性变换后的解码误差和最大化恶意变换后的解码误差(通过负权重-λf实现),在训练中强制网络学习区分两类操作的特征,是实现半脆弱性的核心机制。
- 开源深度伪造音频基准:为评估水印的半脆弱性,构建并开源了一个新的深度伪造基准测试集,包含多种TTS、VC、语音编辑(恶意)以及风格迁移(良性)的AI转换模型,填补了该领域标准化评估工具的空白。
- 面向实时通信的轻量化设计:模型参数量较小(0.9M),且解码器设计考虑了抗失同步,使其适用于对延迟和效率敏感的实时通信场景(如企业耳机、在线会议)。
🔬 细节详述
- 训练数据:使用了LibriSpeech数据集的train-clean100子集进行训练,评估使用了同数据集test-clean中随机选择的500条录音。
- 损失函数:总损失 L = λᵢLᵢ + λdLd + λrLr − λfLf。
- Lᵢ:不可感知性损失,原始音频与含水印音频之间的MSE。
- Ld:对抗判别器损失,用于增强不可感知性。
- Lr:鲁棒性损失,原始消息与经良性变换后恢复消息的MSE,被最小化。
- Lf:脆弱性损失,原始消息与经恶意变换后恢复消息的MSE,被最大化(通过负权重)。
- 训练策略:
- 优化器:Adam (β₁=0.94, β₂=0.98)
- 学习率:0.0002
- 损失权重:λᵢ = λd = 0.01, λr = λf = 1.0
- 训练时长/步数:未说明。
- 关键超参数:
- 水印消息长度:固定为16位。
- 编码器参数量:StreamMark为0.9M,对比的Timbre为0.45M,AudioSeal为7.3M。
- 训练硬件:两块NVIDIA GeForce RTX 2080 (8GB) GPU。
- 推理细节:未说明推理时是否使用流式处理。解码时通过STFT、并行解码器处理实/虚部,最后通过线性层输出16位消息。
- 正则化/稳定训练技巧:使用“skip gated block”作为基础单元;在复数域嵌入以避免单独在相位嵌入导致的训练不稳定。
📊 实验结果
论文在两个主要测试集上进行了评估。
- 基线对比与不可感知性/鲁棒性评估(测试集A) 如表1所示,StreamMark与Patchwork(DSP方法)、AudioSeal(Meta)和Timbre Watermarking进行了对比。
- 不可感知性:StreamMark的PESQ为4.20,优于Timbre Watermarking(3.70),与AudioSeal(4.30)和Patchwork���4.34)接近,说明复数域嵌入有效。
- 对良性攻击的鲁棒性:
- 对于70%的大规模裁剪,StreamMark与Timbre、AudioSeal均保持极高准确率(>99%)。
- 对于8kbps的极低比特率MP3压缩,StreamMark准确率(87.26%)显著优于所有基线。
- 对于60ms帧的Opus编码(模拟WebRTC等实时通信场景),StreamMark达到了99.89%的极高准确率,远超AudioSeal(0.57%)和Patchwork(0.85%),证明了其在目标应用场景下的优越性。
- 深度伪造基准评估(测试集B)—— 核心半脆弱性验证 如表2所示,StreamMark展现了明确的半脆弱行为。
- 恶意变换(脆弱性):面对VALL-E-X(零样本TTS)、FreeVC(语音转换)、VoiceCraft(语音编辑)这三类不同的深度伪造攻击时,水印恢复准确率均下降到50%左右,相当于二元消息的随机猜测水平。这表明水印被有效破坏,系统发出了“音频语义已被篡改”的警报。
- 良性变换(鲁棒性):面对DeepAFX的三种不同风格迁移(明亮、广播、电话效果)时,水印恢复准确率均超过98%。这证实了脆弱性并非对任何神经网络处理都敏感,而是特异性地响应于改变语义的操作。
⚖️ 评分理由
- 学术质量:6.0/7。论文提出了一个新颖且逻辑自洽的范式(半脆弱水印),技术实现(复数域���入、复合损失)有创新性,实验设计周密,包含了详细的消融实验(验证对不同操作的反应)和与多个基线的对比。主要扣分点在于其模拟恶意攻击的失真层仅使用变调,简化了深度伪造的复杂性,且未深入探讨模型在更复杂攻击或对抗环境下的安全性。
- 选题价值:1.5/2。选题紧扣AI深度伪造这一重大安全威胁,提出的主动防御思路比被动检测更具前瞻性和根本性。水印技术本身已相对成熟,但将其目标从“生存”转向“侦测篡改”是一个有价值的视角转换,在媒体可信、通信安全等领域有明确的应用空间。
- 开源与复现加成:0.5/1。论文开源了代码和新颖的深度伪造评估基准,训练细节(数据、优化器、损失权重、硬件)描述详尽,复现门槛中等。扣分点在于未提供预训练的模型权重,用户需要自行训练,且部分实现细节(如具体网络层数、卷积核大小)未在正文中完全展开。