📄 Streamingbench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding
#基准测试 #模型评估 #多模态模型 #音视频
✅ 7.5/10 | 前25% | #基准测试 | #多模态模型 | #模型评估 #音视频
学术质量 5.8/7 | 选题价值 1.8/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Junming Lin(BUPT)(论文中Junming Lin标记为1⋆,表明是主要贡献者之一,但未明确“第一作者”;机构BUPT在作者列表中标注)
- 通讯作者:未说明(论文中未明确标注通讯作者。Maosong Sun标记为1†,但†符号在作者列表中未定义为通讯作者)
- 作者列表:Junming Lin3⋆(BUPT)、Zheng Fang1⋆(未说明)、Chi Chen1†(清华大学计算机系)、Haoxuan Cheng4(西安交通大学)、Zihao Wan1(未说明)、Fuwen Luo1(未说明)、Ziyue Wang1(未说明)、Peng Li2(清华大学AIR)、Yang Liu1,2(清华大学计算机系、清华大学AIR)、Maosong Sun1†(清华大学计算机系、清华大学AIR)
💡 毒舌点评
本文最大的贡献是“承认差距”——它用一套精心设计的考卷,无情地证明了当前最聪明的多模态大模型在“边看边想边答”的能力上,依然是个不及格的“学龄前儿童”(最佳模型比人类低21.4%),这记耳光打得非常及时且必要。然而,它只负责“诊断”却未开“药方”,深度的分析和指明的改进方向(如处理并发线索、主动输出)虽有价值,但停留在表面,更像一份详尽的“体检报告”而非“手术方案”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及公开本文评估的模型权重(这些权重属于各模型原作者)。
- 数据集:论文明确指出StreamingBench已公开(“we hope our work facilitates further advancements…”),但未给出具体获取链接。论文中详细描述了数据构建过程,理论上可部分复现。
- Demo:未提及。
- 复现材料:论文在附录(未提供)中应包含更详细的评估设置说明(如对非流式模型的评估方法)。正文中给出了一些评估配置(如输入帧数、分辨率处理)。
- 引用的开源项目:论文引用了大量开源模型作为评估对象,包括LLaVA-OneVision, Qwen2-VL, InternVL2, MiniCPM系列, VideoLLM-online, Flash-VStream等。
📌 核心摘要
- 问题:当前多模态大语言模型(MLLMs)主要针对离线视频理解(处理完整视频后回答问题),与人类能实时“观看、聆听、思考、回应”流式视频输入的能力存在显著差距。现有基准无法有效评估这种流式能力。
- 方法核心:提出StreamingBench,首个专门评估MLLMs流式视频理解能力的综合基准。该基准包含900个视频和4500个精心制作的问题对,每个视频设有5个不同时间点的问题以模拟连续流场景。它从三个核心维度评估:实时视觉理解、全模态(视觉+音频)理解和上下文理解。
- 新意:与传统离线基准相比,StreamingBench的关键创新在于强调了时间性(问题需在特定时间点回答)、交互性(支持多轮任务)和多模态同步性(需对齐处理视觉和音频流)。
- 主要实验结果:评估了3个闭源和20个开源MLLMs。即使是最强的闭源模型Gemini 1.5 Pro(总分70.26%),也比人类平均水平(91.66%)低21.4个百分点。开源模型中MiniCPM-o 2.6表现最好(66.01%)。模型在处理“并发线索”和“后续线索”时性能显著下降,表明其上下文记忆和实时对齐能力薄弱。分析还发现,使用语音指令会降低模型性能,而直接处理原生音频比使用ASR转录效果更好。关键性能对比如下表:
| 模型类型 | 模型名称 | 总体得分(%) | 实时视觉(%) | 全模态(%) | 上下文(%) |
|---|---|---|---|---|---|
| 人类 | Human | 91.66 | 91.46 | 90.26 | 93.55 |
| 闭源 | Gemini 1.5 Pro | 70.26 | 77.39 | 67.80 | 51.06 |
| GPT-4o | 64.31 | 74.54 | 50.95 | 49.06 | |
| Claude-3.5-sonnet | 60.06 | 74.04 | 41.40 | 39.70 | |
| 开源 (~7B) | MiniCPM-o 2.6 | 66.01 | 79.88 | 53.40 | 38.45 |
| InternVL2.5 | 64.36 | 78.32 | 46.70 | 43.14 | |
| InternLM-XComposer2.5-OmniLive | 60.80 | 75.36 | 46.20 | 33.58 |
- 实际意义:为评估和推进真正具有实时交互能力的多模态AI系统(如个人助理、实时翻译、智能监控)提供了首个标准化测试集和基线,明确了当前技术的主要短板和未来发展方向。
- 主要局限性:本文是一项评估研究,未提出任何新的模型或算法来解决所发现的问题。其深度分析停留在现有模型的能力表征上,未进行根本性的模型架构或训练方法的探索。此外,视频来源为YouTube,可能无法完全覆盖所有现实流式场景。
🏗️ 模型架构
本文是一篇基准测试与评估论文,并未提出一个新的模型架构。其核心贡献在于定义和构建了一个评估框架(StreamingBench),并利用该框架测试了多种现有的MLLMs。
论文中描述的是评估框架的架构,主要体现在数据构建流程(图2)和评估流程上。
- 数据构建流程:见图2。主要分为视频选择(从YouTube选取8类视频)、问题生成(实时视觉任务用GPT-4o生成带时间戳的QA对,全模态和上下文任务由人工标注)、质量控制(人工审核、修订、打乱选项)。
- 评估流程:模拟流式场景。对于每个视频,在5个不同时间点向模型提出问题。模型需要基于截至该时间点已接收的视频(和音频)流片段来回答问题。对于不支持流式输入的模型,会采用剪裁视频并附加文本上下文的方式进行适应性评估。
- 评估维度:三大类18个任务,覆盖了感知、推理、记忆、多模态对齐等能力(图1)。
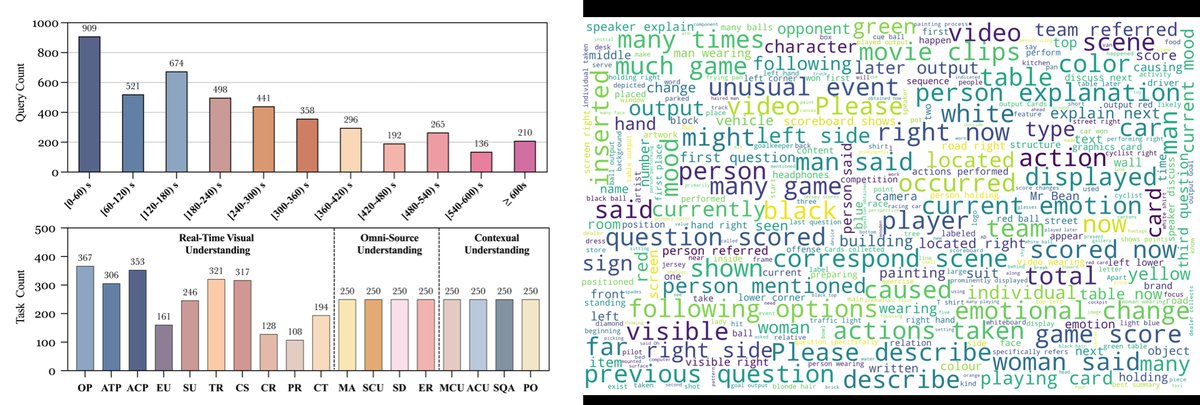 图2: StreamingBench数据构建流程。左侧列出了视频类别,右侧展示了从视频选择到质量控制的步骤。
图2: StreamingBench数据构建流程。左侧列出了视频类别,右侧展示了从视频选择到质量控制的步骤。
💡 核心创新点
- 首个针对“流式”视频理解的全面基准:区别于现有离线基准,StreamingBench首次系统性地将“时间性”、“交互性”和“多模态同步性”作为核心评估要素,填补了评估空白。
- 多维度、细粒度的任务设计:基准涵盖了从基础感知(物体、动作)到复杂推理(因果、预测)再到高级交互(上下文记忆、主动输出)的三个大类18个具体任务,能够全方位诊断模型能力。
- 揭示当前模型与人类能力的巨大差距:通过大规模实验,用具体数字(如最佳模型落后人类21.4%)证实了当前MLLMs在流式理解上的严重不足,并通过分析指出具体短板(如处理并发线索、原生音频处理、主动响应)。
🔬 细节详述
- 训练数据:本文未涉及训练数据。它评估的是现有模型,使用的是自己构建的StreamingBench评估集(900视频,4500问答对,时长3秒到24分钟)。
- 损失函数:未说明。
- 训练策略:未说明。本文评估的模型其训练细节均参考各自原始论文。
- 关键超参数:未说明。评估时使用的帧数(如32, 64, 128帧或1fps)是各模型的官方配置。
- 训练硬件:未说明。
- 推理细节:评估设置了两种模式(表5):
- 离线模式:将整个视频一次性输入模型。
- 流式模式:采用增量式流式预填充,逐步输入视频片段。 对于不支持流式的模型,采用裁剪视频+文本上下文的方式进行近似评估。解码策略等具体参数未提及。
- 正则化或稳定训练技巧:不适用,本文不涉及模型训练。
📊 实验结果
- 主要模型性能对比(表1,关键数据摘录):
| 模型名称 | 参数量 | 输入帧 | 总体准确率(%) |
|---|---|---|---|
| 人类(Human) | - | - | 91.66 |
| Gemini 1.5 Pro | - | video | 70.26 |
| GPT-4o | - | 32 | 64.31 |
| Claude-3.5-sonnet | - | 20 | 60.06 |
| MiniCPM-o 2.6 | 7B | 64 | 66.01 |
| InternVL2.5 | 8B | 32 | 64.36 |
| LLaVA-OneVision | 72B | 32 | 61.39 |
| VideoLLM-online | 8B | 64 | 33.68 |
| Flash-VStream | 7B | 64 | 26.75 |
结论:最强闭源模型Gemini 1.5 Pro得分为70.26%,最强开源模型MiniCPM-o 2.6为66.01%,均远低于人类水平91.66%。专门为流式设计的模型(如VideoLLM-online, Flash-VStream)性能反而垫底,说明它们在“理解”能力上存在严重不足。
- 不同线索类型下的性能分析(表2): 论文将问题线索分为“先验”(答案线索在问题前)、“并发”(线索与问题同步)和“后续”(线索在问题后)。
| 线索类型 | 问题数 | 平均准确率(%) |
|---|---|---|
| 先验 | 1408 | 53.75 |
| 并发 | 2842 | 43.92 |
| 后续 | 50 | 27.06 |
| 总计 | 4300 | 46.74 |
结论:模型在“先验”类型上表现最好,在“并发”和“后续”类型上性能显著下降。这表明模型严重依赖历史信息,而处理实时同步信息和未来信息的能力非常薄弱。
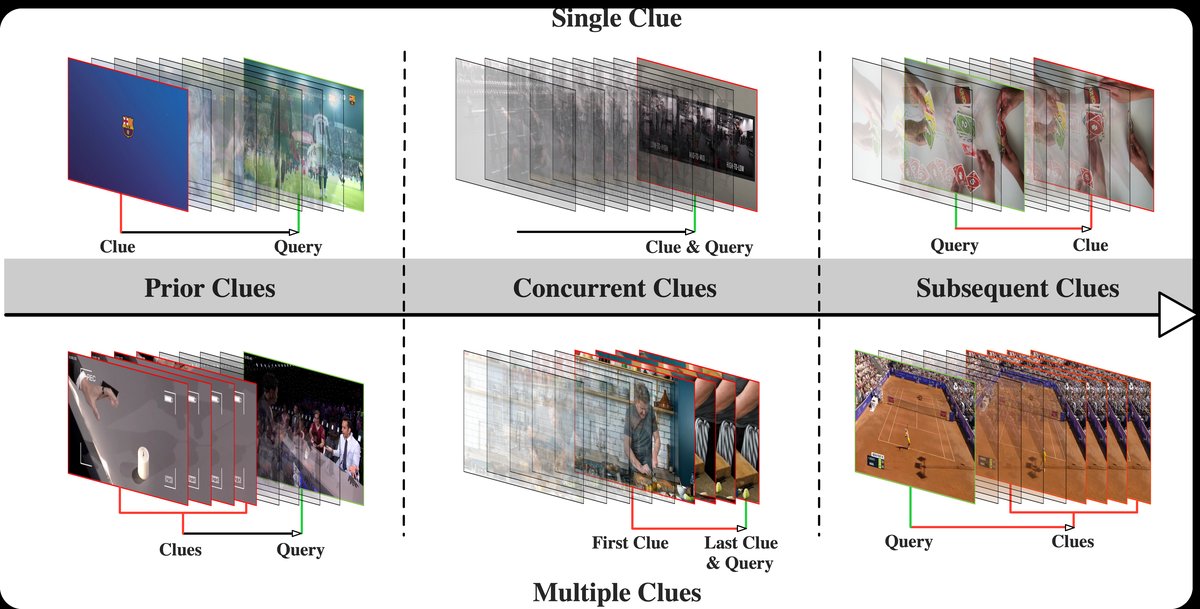 图5: 先验、并发和后续问题的示例,以及单线索和多线索维度。
图5: 先验、并发和后续问题的示例,以及单线索和多线索维度。
- 语音指令与原生音频的影响(表3, 4):
- 语音指令降低性能:在实时视觉理解任务上,使用语音指令比文本指令导致模型性能显著下降(例如,MiniCPM-o 2.6从79.88%降至64.77%)。
- 原生音频输入至关重要:在“全模态理解”任务上,能直接处理原生音频的模型(表4中未列出)比使用ASR转录文本的模型性能更优。ASR能带来约4-6个百分点的提升,但仍存在差距。
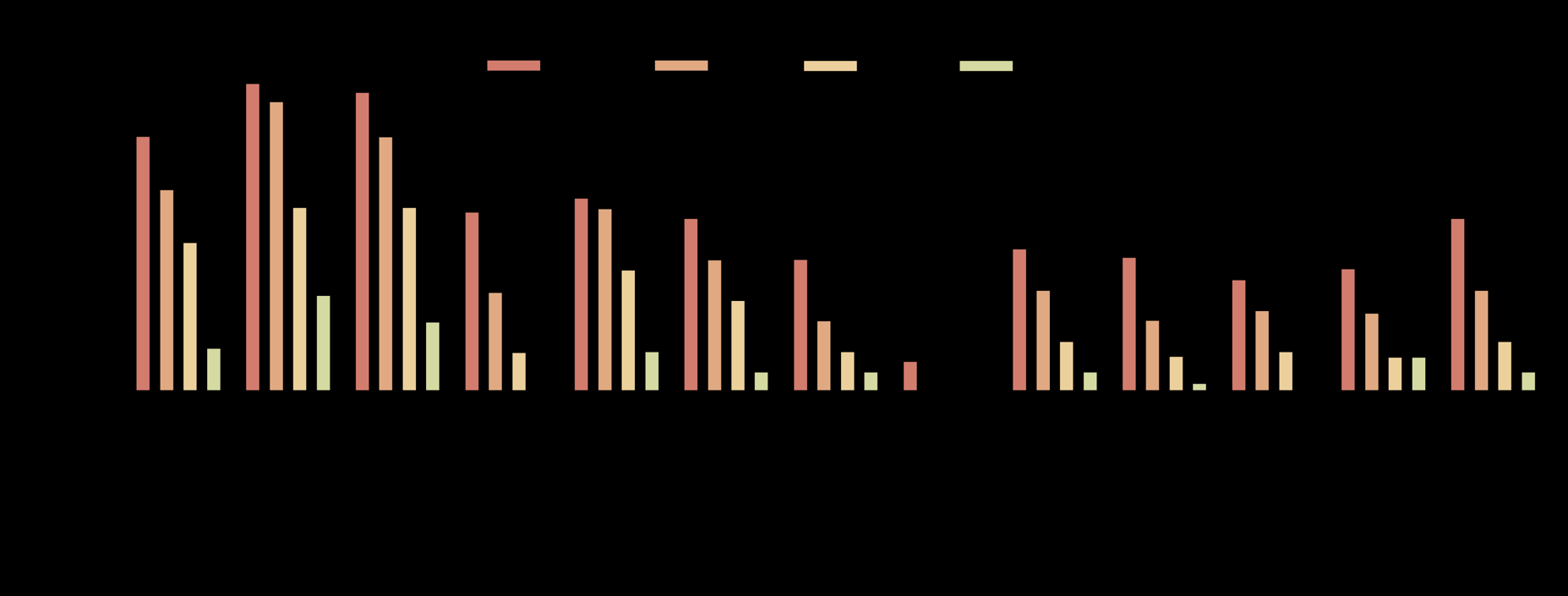 图6: 左图显示在序列问答(SQA)任务中,明确指代消解能略微提升模型性能,但仍远低于人类。右图显示将主动输出(PO)任务转化为被动问答后,性能显著提升。
图6: 左图显示在序列问答(SQA)任务中,明确指代消解能略微提升模型性能,但仍远低于人类。右图显示将主动输出(PO)任务转化为被动问答后,性能显著提升。
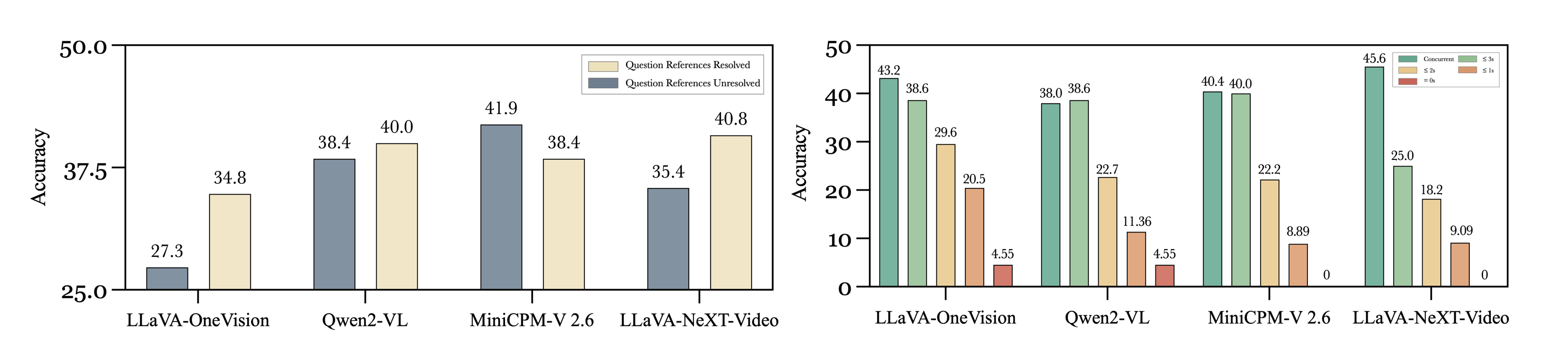 图7: 不同模型在主动输出(PO)任务上的性能。当允许答案时间有数秒偏差(≤xs)时,性能有所提升,但整体依然很低,表明模型缺乏主动、精确定时输出的能力。
图7: 不同模型在主动输出(PO)任务上的性能。当允许答案时间有数秒偏差(≤xs)时,性能有所提升,但整体依然很低,表明模型缺乏主动、精确定时输出的能力。
- 延迟与首Token时间(TTFT)分析(表5):
- 在流式模式下,采用增量预填充的模型(如MiniCPM-o 2.6, VideoLLM-online)比离线模式有显著更低的TTFT和总延迟。
- 需要额外ASR步骤的模型(如InternLM-XComposer2.5-OmniLive + ASR)延迟大幅增加。
⚖️ 评分理由
- 学术质量:5.8/7:作为评估论文,其价值在于发现问题而非解决问题。基准设计全面、科学,评估实验规模大、分析多角度,结论具有说服力和启发性。主要创新点是填补评估空白,而非算法创新。
- 选题价值:1.8/2:选题处于多模态AI从“感知”迈向“交互”的关键拐点,具有极高的前瞻性和行业推动力,直接回应了GPT-4o等产品展示的新能力方向。
- 开源与复现加成:0.5/1:公开了核心评估数据集(StreamingBench),这是最主要的贡献。但未提供完整的评测代码、模型权重或训练配置,未能达到完全开源复现的标准。