📄 Still Thinking or Stopped Talking? Dialogue Silence Intention Classification Using Multimodal Large Language Model
#语音对话系统 #多模态模型 #数据集 #大语言模型
✅ 6.5/10 | 前25% | #语音对话系统 | #多模态模型 | #数据集 #大语言模型
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Muyun Wu(京都大学信息学院)
- 通讯作者:未说明
- 作者列表:Muyun Wu(京都大学信息学院)、Zi Haur Pang(京都大学信息学院)、Koji Inoue(京都大学信息学院)、Tatsuya Kawahara(京都大学信息学院)
💡 毒舌点评
亮点:论文精准地抓住了对话系统中一个被长期忽视但至关重要的细节——沉默的意图解读,并为此构建了首个专门的多模态数据集,这种对具体问题的深入挖掘值得肯定。 短板:模型更像是现有成熟组件(Whisper, SigLip2, Q-former, Qwen3)的“乐高式”拼装,在多模态融合的核心技术上缺乏原创性。数据集规模相对较小(仅63名说话人),且仅针对日语,结论的普适性存疑。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:论文详细描述了数据集构建方法,但未明确说明是否会公开发布该数据集。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了模型架构、训练策略(优化器、学习率、LoRA参数)、推理设置等复现所需的关键框架信息,但缺少损失函数、完整超参、训练日志等细节。
- 论文中引用的开源项目:CLIP [13], SigLip2 [14], AV-HuBERT [15], Marlin [16], Whisper, HuBERT, BLIP-2/Q-former [17], MMS-LlaMA [18], VideoLLaMA2/STPConnector [12], Qwen3, Llama3.2, Perceiver IO [19], Adam [20], LoRA [21]。
- 总结:论文中未提及明确的开源计划。
📌 核心摘要
本文旨在解决对话式语音系统(SDS)中用户长暂停(沉默)意图不明确的问题,即无法判断用户是在“思考”还是已“停止发言”。方法核心是将此问题重新定义为多模态(音频-视频)分类任务,并构建了一个包含63名日语母语者与“倾听系统”交互的专用数据集,对2秒以上的静音区间基于前后文语言线索、视觉线索和后续行为进行标注。基于此数据集,作者提出了一种名为SilenceLLM的多模态大语言模型架构,该架构结合了视觉编码器(评估了CLIP, SigLip2, AV-HuBERT, Marlin)、音频编码器(Whisper, HuBERT)、AV Q-former和LLM解码器。与已有方法相比,其新意在于专门针对沉默理解设计了数据集和端到端的分类框架,并在多个组件组合上进行了系统性对比。实验表明,最优配置(Qwen3-1.7B + SigLip2 (带STPConnector) + Whisper)达到了0.857的宏F1分数,显著优于单模态基线(音频0.662, 视频0.392),且与通用多模态LLM(如MMS-LlaMA)相比也有显著提升(p<0.05)。这项工作的实际意义在于为提升对话系统的交互自然性提供了关键模块和评估数据集。主要局限性是数据集规模较小、语种单一,且模型的创新性更多体现在系统集成而非底层算法突破。
🏗️ 模型架构
SilenceLLM是一个端到端的多模态分类模型,其输入为一段5秒的语音区间和紧随其后的2秒静音区间(共7秒的音频-视频数据),输出为静音意图的分类标签(“Thinking”或“Stopped”)。
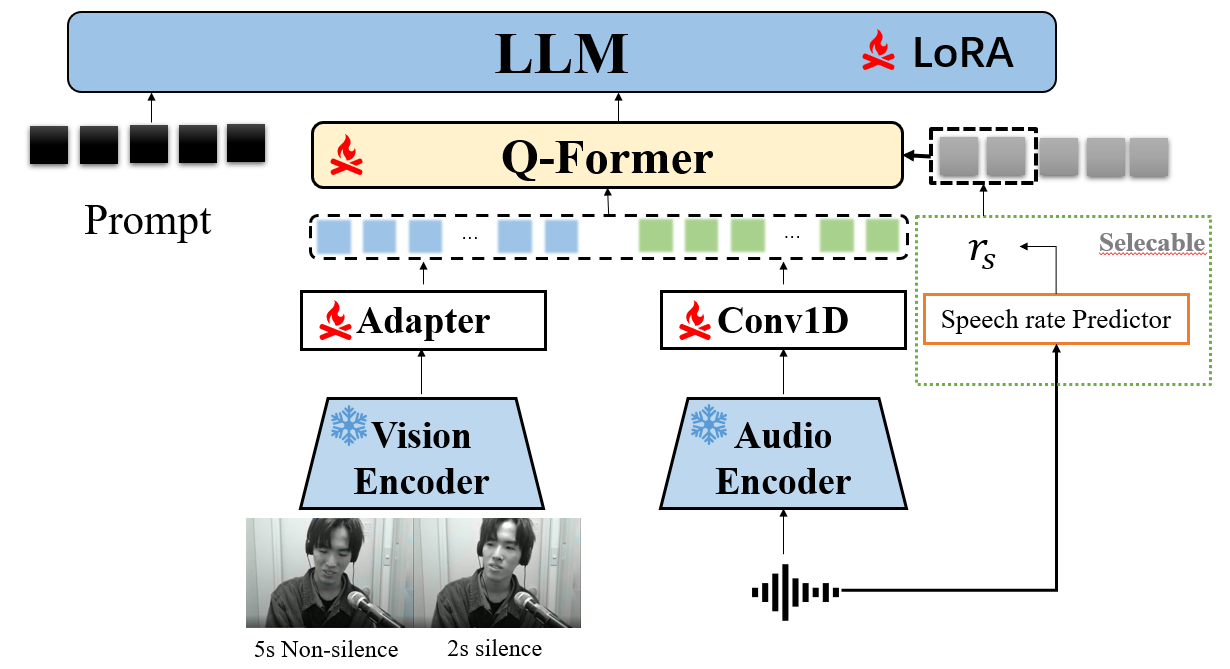 模型架构如图1所示,包含五个主要组件:
模型架构如图1所示,包含五个主要组件:
- 视觉编码器:处理输入的视频帧(25Hz),将人脸和上半身的视觉信息编码为固定长度的特征向量。论文对比了四种编码器。
- 音频编码器:处理输入的音频(16kHz),使用Whisper或HuBERT提取特征,并通过1D卷积下采样至25Hz,以与视频特征对齐。
- 早期特征融合:在编码器输出后,将音频和视频特征在时间维度上进行拼接(Concatenation),这是最终选定的融合方法。
- AV Q-former:这是一个关键组件,源自BLIP-2。它接收融合后的多模态特征,并使用可学习的查询(Query)将它们转换为固定数量的、可被LLM理解的“多模态令牌”。论文探索了两种查询策略:基于预测语速的变长查询(Length-variable)和固定速率查询(每秒3个查询)。
- LLM解码器:接收Q-former输出的多模态令牌,并结合一个结构化的提示(Prompt),以自回归方式生成分类结果。论文尝试了Qwen3-0.6B, Qwen3-1.7B, Llama3.2-3B和Perceiver IO。最终选择Qwen3-1.7B。
此外,为了将图像编码器(CLIP, SigLip2)适配于视频理解,论文引入了时空池化连接器(STP Connector),它通过3D卷积和ReStage模块减少空间-时间令牌数量,同时保留其顺序信息。一个可选的语音速率预测器可用于生成语速rs,以驱动AV Q-former的变长查询分配,但在本研究中效果不明显。
💡 核心创新点
- 问题重新定义与数据集构建:将对话中模糊的“沉默”现象,重新定义为一个清晰的“思考/停止”二分类任务,并为此构建了首个大规模、多模态、带标注的专用数据集。这是论文最实质的贡献。
- 针对沉默理解的端到端多模态框架:设计并评估了SilenceLLM架构,该架构系统性地结合了先进的视觉、音频编码器和LLM,并通过AV Q-former进行跨模态对齐,专注于解决沉默意图分类这一特定任务。
- 多模态信息的必要性验证:通过严谨的消融实验证明,仅依靠音频或视频单模态信息无法有效分类沉默意图(宏F1分别仅为0.662和0.392),而音视频融合(0.857)能带来巨大性能提升,证实了该任务本质上的多模态属性。
🔬 细节详述
- 训练数据:自建数据集,来自63名日语母语者与“倾听系统”的交互。训练、验证、测试集按说话人划分(见表1)。总样本数:训练集898(Stopped 624, Thinking 274), 验证集273(Stopped 168, Thinking 105), 测试集343(Stopped 221, Thinking 122)。数据预处理包括将视频重采样至25fps,音频保持16kHz。使用VAD提取>2秒的静音段,并截取其前5秒语音+该2秒静音作为样本。
- 损失函数:论文中未说明具体的损失函数,推测为标准的交叉熵损失用于分类。
- 训练策略:使用Adam优化器(β1=0.9, β2=0.98),余弦学习率调度,初始学习率1e-5, warmup比例10%。Q-former和投影层从头训练。LLM解码器使用LoRA进行微调(rank=16, α=32, dropout=0.05),应用于query, key, value, output投影层。
- 关键超参数:未提供模型的具体层数、隐藏维度等。关键设计选择包括:输入为5s语音+2s静音;视觉编码器输出25Hz;音频特征下采样至25Hz;AV Q-former每秒3个查询(固定速率);使用LoRA微调LLM。
- 训练硬件:论文中未提及。
- 推理细节:使用波束搜索解码(beam search),温度参数0.3。输出为结构化JSON格式,提示模板如4.3节所述。
- 正则化/稳定技巧:使用了LoRA进行参数高效微调,可能有助于稳定训练和防止过拟合。
📊 实验结果
论文在自建数据集上进行评估,主要指标为宏F1分数和加权F1分数。
表2:与不同多模态LLM的对比
| 模型 | LLM解码器 | 音频编码器 | 视觉编码器 | 视觉投影器 | 变长查询 | 宏F1 | 加权F1 |
|---|---|---|---|---|---|---|---|
| Video-LlaMA2 | Llama3.2-3B | Whisper | CLIP | STPConnector | 否 | 0.855 | 0.866 |
| MMS-LlaMA | Llama3.2-3B | Whisper | AV-Hubert | - | 否 | 0.849 | 0.861 |
| MMS-LlaMA | Llama3.2-3B | Whisper | AV-Hubert | - | 是 | 0.841 | 0.854 |
| SilenceLLM (ours) | Qwen3-1.7B | Whisper | SigLip2 | STPConnector | 否 | 0.859 | 0.870 |
| - 仅音频 | Qwen3-1.7B | Whisper | - | - | 否 | 0.662 | 0.678 |
| - 仅视频 | Qwen3-1.7B | - | SigLip2 | STPConnector | 否 | 0.392 | 0.505 |
关键结论:SilenceLLM(Qwen3-1.7B + Whisper + SigLip2 + STPConnector)取得最佳性能(宏F1=0.859)。McNemar检验显示其显著优于MMS-LlaMA(p=4.31e-7 < 0.05)。单模态消融证明多模态融合的必要性。
表3:消融研究
| LLM解码器 | 音频编码器 | 视觉编码器 | 视觉投影器 | 变长查询 | 宏F1 | 加权F1 |
|---|---|---|---|---|---|---|
| Qwen3-0.6B | Whisper | SigLip2 | STPConnector | 否 | 0.839 | 0.852 |
| Qwen3-1.7B | Whisper | AV-Hubert | - | 否 | 0.819 | 0.837 |
| Qwen3-1.7B | Whisper | Marlin | - | 否 | 0.843 | 0.855 |
| Qwen3-1.7B | Whisper | SigLip2 | STPConnector | 否 | 0.859 | 0.870 |
| Qwen3-1.7B | Whisper | SigLip2 | STPConnector | 是 | 0.848 | 0.861 |
| Qwen3-1.7B | Hubert | SigLip2 | STPConnector | 否 | 0.491 | 0.568 |
| Llama3.2-3B | Whisper | AV-Hubert | - | 否 | 0.849 | 0.861 |
| Llama3.2-3B | Whisper | Marlin | - | 否 | 0.818 | 0.834 |
| Llama3.2-3B | Whisper | SigLip2 | STPConnector | 否 | 0.849 | 0.861 |
关键结论:
- 音频编码器:Whisper(0.859)远优于HuBERT(0.491),可能因Whisper对语音内容理解更强。
- 视觉编码器:SigLip2 + STPConnector组合(0.859)优于AV-Hubert(0.819/0.849)和Marlin(0.843/0.818),表明其捕获时空信息更有效。
- LLM解码器:轻量级的Qwen3-1.7B(0.859)优于更大的Llama3.2-3B(0.849),Qwen3-0.6B(0.839)也表现不错,暗示Qwen3的MoE架构和思考模式对此任务有益。
- 查询策略:变长查询(0.848)未带来提升,因数据集中语速差异小。
⚖️ 评分理由
- 学术质量:5.5/7:论文工作完整,定义了清晰问题,构建了专用数据集,设计并评估了一个多模态分类系统,实验设计包含对比和消融。主要扣分点在于模型架构缺乏原创性,是现有技术的组合;且实验仅在一个自建的小规模数据集上验证,基线对比的统计显著性报告不充分(仅与MMS-LlaMA对比)。
- 选题价值:1.0/2:选题切中对话系统自然交互的痛点,具有实际应用价值。但研究任务(二分类)和场景(特定倾听系统)较为垂直,对更广泛的对话AI领域的影响可能有限。
- 开源与复现加成:0.0/1:论文详细描述了数据集构建和模型配置,对复现有一定指导作用。但未承诺公开数据集、代码或模型权重,关键训练细节(如损失函数、具体训练步数)也缺失,复现门槛较高。