📄 Stereophonic Acoustic Echo Cancellation Using an Improved Affine Projection Algorithm with Adaptive Multiple Sub-Filters
#语音增强 #自适应滤波 #实时处理 #声学回声消除
✅ 6.0/10 | 前50% | #语音增强 | #自适应滤波 | #实时处理 #声学回声消除
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Gagandeep Singh (印度Dr B R Ambedkar国立技术学院电子与通信工程系)
- 通讯作者:未说明
- 作者列表:Gagandeep Singh (印度Dr B R Ambedkar国立技术学院电子与通信工程系)、Asutosh Kar (英国伯明翰城市大学建筑、建成环境、计算与工程学院)、Rohit Singh (印度Dr B R Ambedkar国立技术学院电子与通信工程系)、Vasundhara (印度国立技术学院瓦朗加尔分校电子与通信工程系)、Jesper R. Jensen (丹麦奥尔堡大学音频分析实验室)、M.G. Christensen (丹麦奥尔堡大学音频分析实验室)
💡 毒舌点评
本文系统性地将多子滤波器(MSF)结构、基于递推均方偏差的可变步长机制以及能量方差跟踪重置策略相结合,为解决立体声回声消除中信号高相关性与非圆性难题提供了一个工程上完整且有效的方案,在特定条件下提升了收敛速度和追踪能力。但其创新点更像是“乐高积木”式的组合,缺乏底层理论突破,且完全忽略了双讲(double-talk)和非线性失真这两个实际场景中的核心挑战,限制了其在复杂真实环境中的适用性。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及。
- 数据集:仿真使用的声学脉冲响应和语音信号未公开,也未说明如何获取。
- Demo:未提供在线演示。
- 复现材料:给出了部分仿真参数(如$s, P, \delta, \sigma_v^2, T_{60}, t$),但未提供生成图1-5所需的所有原始数据和完整代码,难以完整复现。
- 引用的开源项目:论文中引用了多篇文献,但未明确提及依赖的具体开源工具或模型库。
📌 核心摘要
- 问题:立体声声学回声消除(SAEC)因左右声道输入信号高度相关且具有非圆性,导致传统自适应算法收敛慢、稳态性能差。
- 方法核心:提出一种基于多子滤波器(MSF)的可变步长改进仿射投影算法(VSS-CAPA)。通过将左右声道信号组合为复数信号输入,并利用多个子滤波器并行处理。核心创新在于:a) 设计了一种基于递推均方偏差(MSD)分析的动态步长调整策略(公式16-19);b) 引入能量方差跟踪指标(公式20-21),在回声路径突变时重置步长以加速重收敛。
- 创新性:与已有方法(如VSS-APA、EOAPA、VSS-CLMS)相比,本文系统性地结合了MSF结构与复数APA,并提出了具体的、基于MSD分析的变步长调整规则和突变检测重置机制。
- 实验结果:在合成信号和真实语音实验中,所提方法在0-35 dB SNR范围内的ERLE(回声回损增强)均优于基线方法。例如,在SNR=35 dB时,所提βMSF VSS-CAPA在真实语音上的ERLE达到24.3 dB,比单滤波器SLF VSS-CAPA(21.7 dB)和βMSF VSS-CLMS(20.9 dB)分别高出2.6 dB和3.4 dB。在动态回声路径突变测试中,该方法表现出更快的重新收敛速度(图5)。
- 实际意义:该算法旨在提升实时通信系统(如电话会议)中的回声消除效果和用户体验,尤其适用于回声路径可能动态变化的环境。
- 主要局限性:论文未考虑双讲(near-end speech存在时)和非线性扬声器失真情况,这两者是实际SAEC系统中必须处理的复杂场景。此外,计算复杂度随子滤波器数量s线性增加(表2)。
🏗️ 模型架构
论文提出的系统架构如图1所示。其核心是一个基于多子滤波器(βMSF)的变步长复数仿射投影算法(VSS-CAPA)。
- 输入流程:远端立体声信号$x_L(n)$和$x_R(n)$通过一个控制参数$t=0.5$的半波整流处理,以引入非圆性。随后,采用一种“augmented approach”,将两个实数通道组合成一个复数信号$x(n)=x_L(n)+jx_R(n)$。这个复数信号被分成$s$个重叠的子段(sub-filters),每个子段对应一个子滤波器的输入$x_i(n) = x_{L,i}(n) + j x_{R,i}(n)$。
- 滤波与输出:每个子滤波器$w_i(n)$独立地对相应的输入子段进行滤波,产生输出$y_i(n) = \mathbf{x}_i^H(n) \mathbf{w}i(n)$。所有子滤波器的输出求和,得到总的回声估计$\sum{i=1}^{s} y_i(n)$。该估计值从近端麦克风信号$d(n)$中减去,得到误差信号$e(n)$。
- 权重更新:每个子滤波器的权重向量采用复数APA进行更新(公式8)。更新步长$\mu(n)$是时变的,并由一个中央控制器根据递推MSD估计值(公式18)和两个候选步长$\mu_1(n), \mu_2(n)$动态选择(公式19)。
- 动态适应机制:一个额外的跟踪模块(公式20)计算权重向量变化的能量方差$\chi_w(n)$。当$\chi_w(n)$发生突变(公式21)时,表明回声路径改变,此时会重置步长$\mu(n)$为1,以促进快速重新收敛。
- 设计动机:MSF结构可以降低输入信号的高相关性。复数APA和VSS机制旨在分别处理信号的非圆性并优化收敛速度。突变检测机制旨在增强算法在动态环境下的鲁棒性。
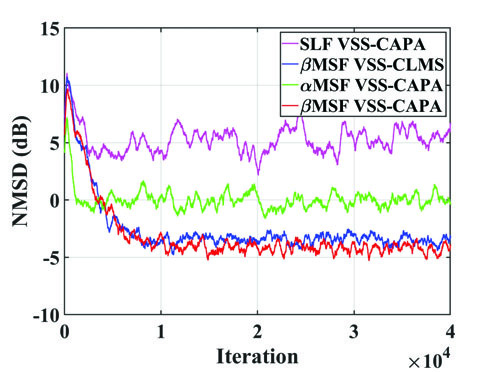 图1展示了系统整体结构。远端立体声信号经过处理后形成复数输入,并被分割为多个子段。每个子段由一个独立的自适应滤波器(子滤波器)处理,其输出求和后与近端信号比较得到误差。变步长控制器和路径变化检测模块共同管理所有子滤波器的更新过程。
图1展示了系统整体结构。远端立体声信号经过处理后形成复数输入,并被分割为多个子段。每个子段由一个独立的自适应滤波器(子滤波器)处理,其输出求和后与近端信号比较得到误差。变步长控制器和路径变化检测模块共同管理所有子滤波器的更新过程。
💡 核心创新点
- 基于递推MSD的变步长策略:不同于固定步长或经验性调整的变步长方法,本文从APA的MSD分析中推导出一个递推关系(公式16)。利用此关系,通过评估两个临近步长$\mu_1(n)$和$\mu_2(n)$所对应的预测MSD(公式18),选择能使预测MSD最小化的那个作为当前步长(公式19)。这为步长调整提供了理论依据。
- 能量方差驱动的步长重置机制:为了应对回声路径的突变(如用户移动),引入了能量方差指标$\chi_w(n)$(公式20)来监控权重向量的剧烈变化。当检测到变化超过阈值$\tau$时(公式21),立即将步长重置为较大值(如1),强制算法进行快速搜索和重新适应。这增强了算法在非平稳环境下的跟踪能力。
- βMSF与VSS-CAPA的系统性结合:将多子滤波器结构与上述变步长机制和突变检测策略相结合,形成一个完整的SAEC解决方案。MSF处理相关性和非圆性,VSS-CAPA优化收敛,突变检测提供鲁棒性,三者协同工作。
🔬 细节详述
- 训练数据/仿真设置:
- 声学环境:使用镜像法(method of images)生成真实声学脉冲响应$h_{LL}, h_{LR}, h_{RL}, h_{RR}$,混响时间$T_{60}=120$ ms。
- 输入信号:1) 合成信号:包含伯努利-高斯噪声的信号。2) 真实语音:16 kHz采样的真实语音信号。
- 预处理:对输入信号进行半波整流(控制参数$t=0.5$)以模拟非线性并产生非圆性。
- 噪声:近端噪声$\eta(n)$设为零均值非圆高斯噪声,方差$\sigma_v^2 = 10^{-3}$。
- 模型超参数:
- 子滤波器数量$s=4$。
- 投影阶数$P=4$。
- 正则化参数$\delta=0.01$。
- 初始步长$\mu_1(n)=1$。
- 步长评估比例因子$\rho \in (0.9, 1)$(公式17)。
- 能量方差跟踪控制参数$b \in (0.9, 1)$(公式20)。
- 突变检测阈值$\tau$:具体值未说明。
- 步长范围:为保证收敛,步长$\mu(n)$需满足 $0 \leq \mu(n) \leq \sqrt{1 - \sqrt{1 - N/P}}$(公式24)。
- 训练/推理细节:本文是自适应滤波算法,没有传统意义上的“训练”过程。算法在测试阶段持续在线更新。未提及优化器、学习率调度、batch size等深度学习概念。
- 硬件:未说明。
- 正则化:APA中使用了正则化项$\delta \mathbf{I}_P$(公式8)来避免矩阵求逆时的数值不稳定。
📊 实验结果
论文主要通过ERLE(Echo Return Loss Enhancement,单位dB)来评估性能,ERLE值越高表示回声消除效果越好。 表1:不同SNR下ERLE(dB)比较(合成信号Syn与真实语音Real)
| 算法 | 0 dB | 5 dB | 10 dB | 15 dB | 20 dB | 25 dB | 30 dB | 35 dB |
|---|---|---|---|---|---|---|---|---|
| Syn/Real | Syn/Real | Syn/Real | Syn/Real | Syn/Real | Syn/Real | Syn/Real | Syn/Real | |
| SLF VSS-CAPA | 12.3/10.5 | 14.7/12.8 | 17.9/15.4 | 20.1/17.6 | 22.0/19.5 | 23.2/20.7 | 24.0/21.3 | 24.4/21.7 |
| β-MSF VSS-CLMS | 11.5/9.8 | 13.4/11.9 | 16.5/14.2 | 19.0/16.8 | 21.1/18.7 | 22.4/19.8 | 23.0/20.4 | 23.5/20.9 |
| α-MSF VSS-CAPA | 13.0/11.2 | 15.2/13.3 | 18.3/16.1 | 21.5/18.9 | 23.5/20.8 | 24.6/21.9 | 25.3/22.6 | 25.8/23.1 |
| Proposed (βMSF VSS-CAPA) | 14.2/12.7 | 16.5/14.8 | 19.6/17.5 | 22.8/20.2 | 24.9/22.1 | 26.0/23.2 | 26.8/23.9 | 27.2/24.3 |
关键结论:所提方法(Proposed)在所有SNR条件下,无论对合成信号还是真实语音,ERLE均最高。例如,在SNR=35dB真实语音测试中,其ERLE(24.3 dB)比次优的α-MSF VSS-CAPA(23.1 dB)高1.2 dB,比传统的SLF VSS-CAPA(21.7 dB)高2.6 dB。
图2:合成信号下的归一化均方偏差(NMSD)比较
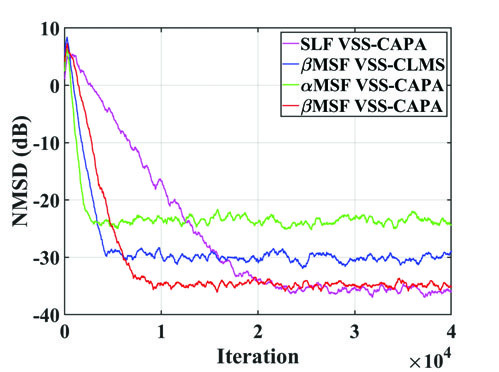 图2显示了不同算法在两种SNR下的收敛曲线。所提方法(Proposed)在两种情况下都达到了更低的稳态NMSD(即更低的失配),验证了其在理想条件下的优越性。
图2显示了不同算法在两种SNR下的收敛曲线。所提方法(Proposed)在两种情况下都达到了更低的稳态NMSD(即更低的失配),验证了其在理想条件下的优越性。
图3:真实语音信号的频谱图
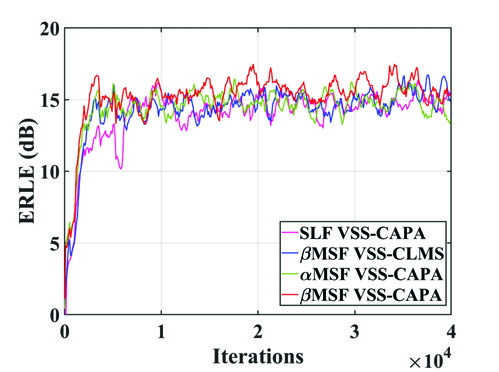 图3对比了不同算法处理后语音的频谱。图(d)(所提方法)相比(b)和(c),能更清晰地恢复出语音的频谱结构,残留的回声“阴影”更少,直观证明了其更好的回声抑制效果。
图3对比了不同算法处理后语音的频谱。图(d)(所提方法)相比(b)和(c),能更清晰地恢复出语音的频谱结构,残留的回声“阴影”更少,直观证明了其更好的回声抑制效果。
图4:真实语音下的ERLE曲线
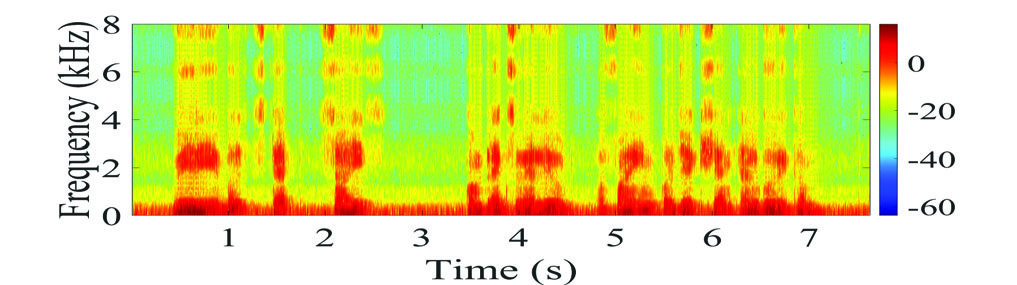 图4展示了ERLE随时间收敛的过程。所提方法(Proposed)在两个SNR下都收敛最快,且稳态ERLE最高,与表1数据一致。
图4展示了ERLE随时间收敛的过程。所提方法(Proposed)在两个SNR下都收敛最快,且稳态ERLE最高,与表1数据一致。
图5:动态路径突变下的跟踪性能
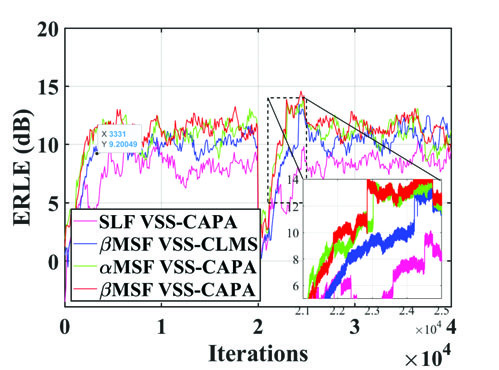 图5是验证算法跟踪能力的关键实验。在n=20,000时回声路径发生突变。所提方法(Proposed)的NMSD在突变后下降速度最快,能迅速重新收敛到低失配状态,证明了其提出的步长重置机制的有效性。
图5是验证算法跟踪能力的关键实验。在n=20,000时回声路径发生突变。所提方法(Proposed)的NMSD在突变后下降速度最快,能迅速重新收敛到低失配状态,证明了其提出的步长重置机制的有效性。
表2:计算复杂度比较
| 算法 | 乘法次数 | 加法次数 |
|---|---|---|
| βMSF VSS-CLMS | 9sN | 7sN |
| SLF CAPA | 12N + 9 | 14N + 10 |
| SLF VSS-CAPA | 15N + 12 | 14N + 13 |
| Proposed (βMSF VSS-CAPA) | s(15N + 12) | s(14N + 13) |
| 注:s为子滤波器数量,N为滤波器长度。 | ||
| 关键结论:所提方法的计算复杂度是单滤波器VSS-CAPA的s倍。这表明性能提升是以更高的计算成本为代价的,是一个明确的工程权衡。 |
⚖️ 评分理由
- 学术质量:5.5/7 - 技术推导严谨,方法设计有逻辑,实验设计全面(静态/动态,合成/真实信号),并提供了定量的性能对比和复杂的消融分析(如不同MSF变体)。扣分点在于核心创新属于现有技术的系统集成,而非提出新的理论或模型;且实验未覆盖实际SAEC中至关重要的双讲和非线性场景,结论的普适性受限。
- 选题价值:1.0/2 - 解决实际工程问题(SAEC),有明确的应用场景。但该领域已是自适应信号处理的经典方向,研究相对成熟,增量式改进的影响力有限。
- 开源与复现加成:-0.5/1 - 论文完全未提供代码、数据集���或详细到可直接复现的配置(如具体的脉冲响应文件、语音文件、完整超参数列表)。这显著增加了他人验证和借鉴该工作的难度。