📄 Staged Diffusion with Hybrid Mixture-of-Experts (MOE) for Multimodal Sentiment Analysis
#多模态模型 #扩散模型 #多模态模型 #语音情感识别 #鲁棒性
🔥 8.0/10 | 前25% | #语音情感识别 | #多模态模型 | #扩散模型 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kaiyang Zheng(上海交通大学计算机科学与技术学院)
- 通讯作者:Gehao Sheng(上海交通大学计算机科学与技术学院)
- 作者列表:Kaiyang Zheng(上海交通大学计算机科学与技术学院)、Gehao Sheng(上海交通大学计算机科学与技术学院)
💡 毒舌点评
亮点:该工作将扩散模型从生成任务“跨界”到语义修复,用于对齐和修正多模态下的噪声文本,是一个颇具巧思的“认知模拟”尝试,为处理模态缺失提供了新思路。短板:整体框架依赖外部的情绪描述生成模块(EDG),核心创新更侧重于框架整合与特定组件(如Hybrid MoE)的设计,而非底层原理突破;论文对“Semantic Cortex Emulator”等命名略显“包装”,部分机制解释深度有限。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/zhengky-paper-account/SDHM。
- 模型权重:未提及。
- 数据集:论文中使用了公开数据集CMU-MOSI和CH-SIMS,但未说明是否提供已处理好的数据或特定预处理脚本。
- Demo:未提供。
- 复现材料:论文给出了一些关键超参数(如扩散步数、beta范围、模型深度、专家数等),但未提供完整的训练配置文件、预训练权重或训练日志。
- 引用的开源项目:论文引用了DEVA、Linear-MoE等开源工作,并在其基础上进行改进。
📌 核心摘要
- 要解决的问题:多模态情感分析(MSA)中,文本模态常因口语化和ASR错误而包含噪声和歧义,现有方法处理此类噪声鲁棒性不足。
- 方法核心:提出受认知启发的两阶段框架SDHM。第一阶段,使用混合线性注意力与Transformer的MoE模型渐进增强单模态特征,并引入基于扩散模型的重建损失来对齐多模态线索、修复损坏内容。第二阶段,将重建后的语义特征与原始文本特征融合,形成鲁棒的主模态表示进行最终预测。
- 与已有方法相比新在哪里:首次在MSA领域将扩散模型用于文本模态的语义修复(而非高层融合或生成);设计了交替使用线性MoE和Transformer-MoE的“混合专家”结构,旨在平衡特征描述对齐与上下文语义提取,并抑制噪声放大。
- 主要实验结果:在MOSI和SIMS数据集的随机模态缺失设定下,SDHM取得了SOTA性能。在MOSI上,MAE降至0.698,相关系数Corr提升至0.800(均为p<0.01显著提升)。在模态缺失鲁棒性测试中,当缺失率为0.3时,其MAE仍比LNLN低0.086,Corr高0.084。消融实验证明,结合混合MoE与扩散损失能带来最大性能增益。
- 实际意义:提升了MSA模型在真实世界(多噪声、多缺失模态)场景下的预测准确性和鲁棒性,对人机交互、情感计算等应用有直接价值。
- 主要局限性:在极端模态缺失(如缺失率0.8)条件下,分类准确率(如Acc-7)仍略低于部分基线模型。框架依赖外部生成的情绪描述,增加了系统复杂度。
🏗️ 模型架构
SDHM是一个两阶段、多组件的端到端框架。其整体处理流程如下图所示(图1):
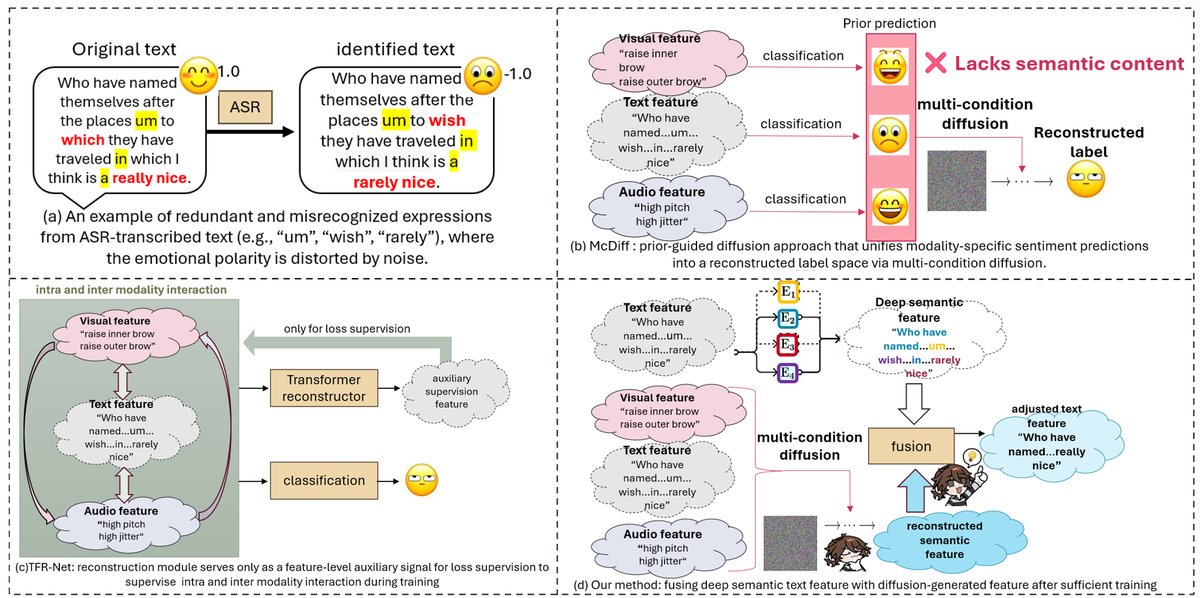
- 输入与预处理:所有模态(文本、音频、视觉)的原始特征首先被输入到情感描述生成器(EDG),为音频和视觉模态生成文本形式的情绪描述。这些描述与原始特征拼接,形成增强的输入。
- 单模态增强(Unimodal MoE Enhancement):每个模态的增强输入
Im经过轻量级序列建模(LSM)层(采用线性注意力,以提升对噪声的稳定性)和MoE层(使用稀疏路由的专家网络)。这一模块旨在丰富每个模态的情绪上下文,输出增强后的单模态表示。 - 语义皮层模拟器(Semantic Cortex Emulator, SCE):这是框架的核心,模拟人脑的“学习-推理”过程。
- 语义挖掘块:文本模态被
J个堆叠的Transformer-MoE块迭代处理,生成一系列深度语义表示H_t^j。 - 场景推理块:引入条件扩散模型。以最后一个Transformer-MoE层输出
H_t^J为锚点,将其与噪声文本Z_t进行扩散对齐,目标是学习从噪声中恢复纯净语义。条件向量C由文本、音频、视觉的特征拼接投影得到,并通过交叉注意力与噪声表征融合。训练目标是最小化预测噪声的损失。推理时仅执行一步去噪。 - 辅助模态对齐:利用文本的中间层表示
H_t^{j-1}作为查询,对音频和视觉特征进行跨模态注意力更新,使次要模态逐步与文本对齐。
- 语义挖掘块:文本模态被
- 融合与预测:经过SCE处理的文本语义特征(包括扩散修复后的
̂H_t)与对齐后的音频、视觉特征一起,输入到混合融合块(交替使用Transformer-MoE和Linear-MoE层)进行跨模态融合。最终,由基于Mamba的MoE-Head进行序列级抽象,输出情感预测结果。
关键设计选择:
- 两阶段设计:模仿“先对齐学习,再修正推理”的认知过程。
- 混合MoE:Linear-MoE(利用线性注意力)侧重特征与描述的对齐和低秩建模,Transformer-MoE侧重上下文语义理解。交替使用旨在形成“过滤-理解”循环。
- 扩散用于语义修复:将扩散模型的去噪目标应用于文本语义特征空间,而非原始像素或波形,是一种新颖的适配。
💡 核心创新点
- 认知启发的两阶段框架:提出���学习-修正”范式。第一阶段通过多模态线索学习并重建语义,第二阶段将重建结果与原始特征融合。这超越了传统的单阶段融合或简单的重构再预测。
- 基于扩散模型的文本语义修复:首次将扩散模型作为语义修复模块,嵌入到MSA流程中,利用多模态上下文条件,专门针对噪声文本进行去噪和语义对齐,而非用于最终生成。
- 混合专家(Hybrid MoE)结构设计:针对不同阶段任务,定制化地交替使用线性注意力MoE和Transformer-MoE。线性注意力MoE提供稳定的噪声处理能力,Transformer-MoE提供强大的上下文建模能力,二者结合提升了特征抽象的鲁棒性。
🔬 细节详述
- 训练数据:
- 数据集:CMU-MOSI(英文,情感强度-3至3)和CH-SIMS(中文,情感强度-1至1)。
- 规模:论文未明确给出两个数据集的具体样本数。
- 预处理:遵循前作DEVA,通过EDG从音频和视觉输入中提取情绪线索并转换为文本描述,与原始模态特征拼接。
- 数据增强:实验通过随机模态缺失(宏观)和随机token缺失(微观)来模拟噪声,作为测试集评估的设置,并非训练时的增强。
- 损失函数:采用可学习的不确定性加权多任务损失。
L_main:主要任务损失(分类或回归损失),未具体说明。L_diff:扩散重建损失(公式10),即预测噪声与真实噪声的均方误差。- 总损失
L通过可学习参数σ_main和σ_diff自动平衡(公式15),避免了手动调参。
- 训练策略:
- 优化器:AdamW。
- Batch Size:64。
- 学习率调度:未说明。
- 训练步数/轮数:未说明。
- 扩散过程:训练时使用100步扩散,beta范围为0.001–0.01,使用余弦噪声调度。推理时坍缩为单步去噪(t=0)。
- 关键超参数:
- 模型大小:总参数量114.35M。
- 融合层深度:3。
- 语义皮层模拟器(SCE)深度:2。
- 注意力头数:8。
- 专家数量与选择:5个专家,top-2选择。
- 融合比例:重建特征与原始文本特征在SIMS上为9:1,在MOSI上为1:1。
- 专家维度:每个专家是256维的MLP。
- 训练硬件:
- CPU:Intel Xeon Platinum 8457C。
- GPU:4 x NVIDIA L40。
- 训练时长:未说明。
- 推理细节:扩散模块在推理时仅执行一步去噪,无迭代采样,因此推理开销较小(平均29.50 ms/batch,batch size 16)。
- 正则化技巧:使用了Dropout(见公式8)。
📊 实验结果
表1:与SOTA方法在MOSI和SIMS数据集上的性能对比
| 方法 | MOSI | SIMS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | Acc-5↑ | Acc-3↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | |
| MISA | 43.05 | 48.30 | 82.78 | 82.83 | 0.771 | 0.777 | 40.55 | 63.38 | 78.19 | 77.22 | 0.449 | 0.576 |
| Self-MM | 42.81 | 52.38 | 85.22 | 85.19 | 0.720 | 0.790 | 40.77 | 64.92 | 78.26 | 78.00 | 0.421 | 0.584 |
| DEVA | 45.19 | 51.02 | 84.60 | 84.61 | 0.716 | 0.789 | 41.35 | 62.58 | 78.99 | 78.79 | 0.426 | 0.570 |
| Ours | 47.38 | 53.50 | 84.45 | 84.51 | 0.698 | 0.800 | 43.76 | 65.86 | 80.30 | 80.23 | 0.410 | 0.600 |
关键结论:SDHM在大部分指标上取得最优,尤其在回归指标(MAE, Corr)上优势明显(p < 0.01)。
表2:在宏观级模态缺失(随机缺失)条件下的鲁棒性对比(MOSI数据集)
| 方法 | τ=0.1 | τ=0.2 | τ=0.3 | τ=0.8 | ||||
|---|---|---|---|---|---|---|---|---|
| MAE↓ | Corr↑ | MAE↓ | Corr↑ | MAE↓ | Corr↑ | MAE↓ | Corr↑ | |
| LNLN | 0.820 | 0.724 | 0.891 | 0.668 | 0.953 | 0.617 | 1.283 | 0.314 |
| DEVA | 0.790 | 0.757 | 0.868 | 0.708 | 0.935 | 0.666 | 1.263 | 0.372 |
| OURS | 0.759 | 0.766 | 0.822 | 0.728 | 0.867 | 0.701 | 1.257 | 0.367 |
关键结论:在低到中等缺失率(0.1-0.3)下,SDHM显著优于对比模型。在极端缺失率(0.8)下,MAE仍最低,Corr与DEVA接近,展示了强大的鲁棒性。
表3:消融研究(在MOSI数据集上)
| 模块 | 指标 | ||
|---|---|---|---|
| ̂H_t^J (扩散特征) | MoE | L_diff (扩散损失) | ACC-5↑ |
| ✗ | ✗ | ✗ | 51.02 |
| ✗ | ✓ | ✗ | 51.31 |
| ✓ | ✗ | ✓ | 51.17 |
| ✗ | ✓ | ✓ | 53.00 |
| ✓ | ✓ | ✓ | 53.50 |
关键结论:完整模型(最后一行)性能最优。单独使用MoE带来有限提升;结合MoE与扩散损失(第四行)带来巨大提升,证明二者协同效应;最终加入扩散特征融合(第五行)达到最佳。
图2:微观级噪声(随机token缺失)下的特征可视化
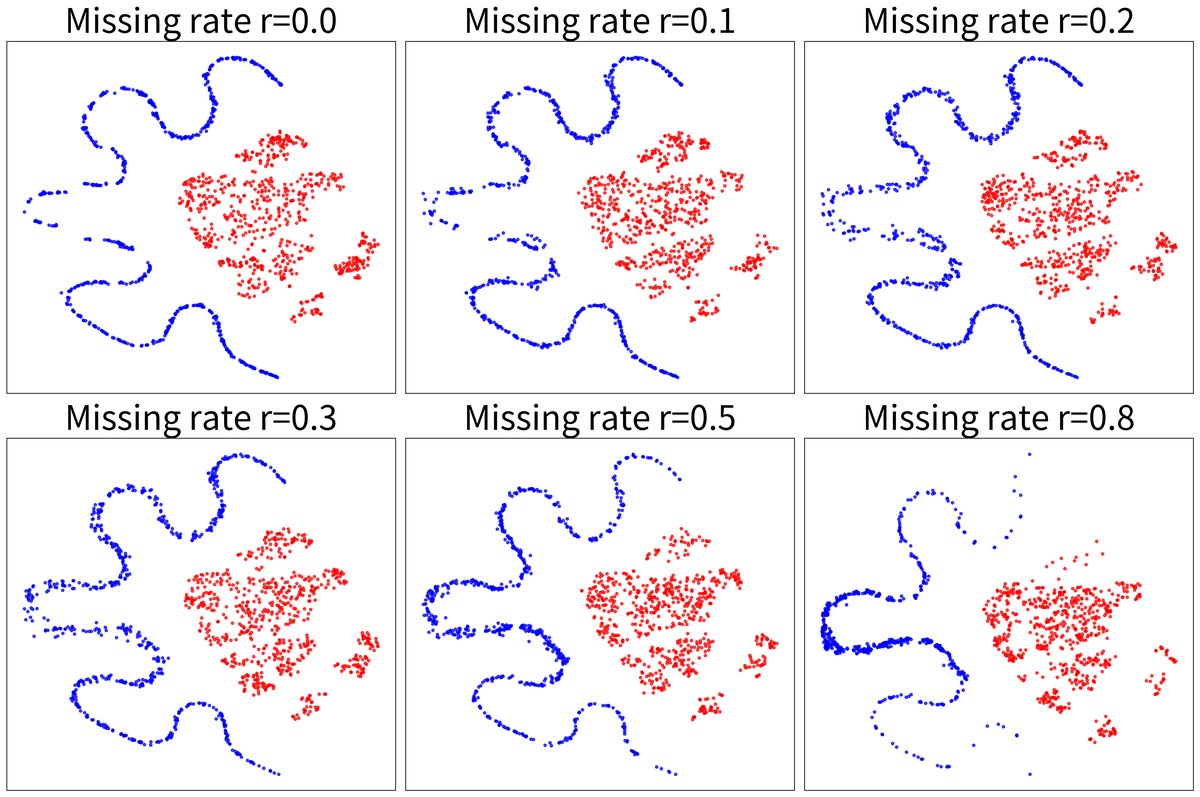 关键结论:随着文本token缺失率的增加,仅由损坏文本提取的特征(蓝色点)变得分散、模糊。而融合了扩散模型输出的增强特征(红色点)仍保持稳定聚类,直观证明了扩散机制修复语义、保持判别性的能力。
关键结论:随着文本token缺失率的增加,仅由损坏文本提取的特征(蓝色点)变得分散、模糊。而融合了扩散模型输出的增强特征(红色点)仍保持稳定聚类,直观证明了扩散机制修复语义、保持判别性的能力。
⚖️ 评分理由
- 学术质量:6.0/7:创新性方面,将扩散模型用于文本语义修复和设计混合MoE结构有明确的新意。技术正确性高,实验设计合理,在多个数据集和不同噪声场景下进行了全面评估,结果具有统计显著性。但部分组件依赖外部工作,且模型整体更偏向于工程创新与整合。
- 选题价值:1.5/2:解决MSA中的噪声问题是一个重要且实际的前沿课题,对提升模型在真实场景中的可用性有直接价值。音频/语音作为多模态输入的重要部分,本文方法对其噪声处理具有参考意义。
- 开源与复现加成:+0.5/1:提供了明确的GitHub代码链接,有助于复现。但未提及模型权重发布、完整的训练数据集获取细节(如数据预处理脚本),也未提供训练过程的检查点或详细超参数配置表,复现门槛中等。