📄 Spiking Temporal-Enhanced Network for Zero-Shot Audio-Visual Learning
#音视频 #脉冲神经网络 #零样本 #音频分类 #多模态模型
✅ 7.0/10 | 前50% | #音频分类 | #脉冲神经网络 | #音视频 #零样本
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Ziyu Wang(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)
- 通讯作者:Wenrui Li(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)
- 作者列表:Ziyu Wang(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)、Wenrui Li(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)、Hongtao Chen(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)、Jisheng Chu(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)、Hengyu Man(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)、Xiaopeng Fan(哈尔滨工业大学,鹏城实验室,哈尔滨工业大学苏州研究院)
💡 毒舌点评
亮点:论文敏锐地抓住了音视频零样本学习中“时间建模”和“能效”两大痛点,提出的STFE和ETS模块设计目标明确,且通过减少时间步长实现了可观的能耗降低。短板:模型在复杂长视频(ActivityNet)上表现出的“过拟合已见类别、损害未知类别泛化”的现象,恰恰点出了其时间建模可能“用力过猛”而牺牲了通用性,这一核心矛盾在论文中未得到充分讨论和解决。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用公开数据集(VGGSound, UCF101, ActivityNet),未提及额外数据。
- Demo:未提供在线演示。
- 复现材料:提供了主要超参数(见03.细节详述),但缺少优化器、学习率调度、数据预处理/增强细节、完整训练配置文件等。
- 论文中引用的开源项目:引用了预训练模型SeLaVi[17](“Labelling unlabelled videos from scratch with multi-modal self-supervision”),但未提供其具体开源链接。
- 总体开源情况:论文中未提及开源计划。
📌 核心摘要
- 问题:现有音视频零样本学习(AVZSL)方法普遍存在时间线索利用不足的问题,常依赖简单的特征平均或基础脉冲神经元,无法捕捉深层时间依赖,且能效有待优化。
- 方法核心:提出脉冲时序增强网络(STEN)。其核心是在Spikeformer架构中集成可学习三元脉冲神经元(LTS) 和时空融合模块(STFE),并通过增强时序Spikeformer(ETS) 自适应整合相邻时间步信息。
- 新意:相比已有方法(如AVMST),STEN通过LTS增强特征表示能力,通过STFE联合建模时间局部动态和通道依赖,通过ETS捕获微观时序变化。同时利用脉冲神经网络(SNN)的事件驱动稀疏性,通过优化时间步长大幅降低能耗。
- 主要实验结果:
- 在VGGSound数据集上,GZSL调和平均(HM)达到8.04,比基线AVMST(7.68)提升4.7%,ZSL指标提升13.6%。
- 在UCF101数据集上,GZSL的HM达到34.27,比AVMST(29.91)提升14.6%,Seen类准确率大幅提升。
- 在ActivityNet数据集上,Seen类指标提升40.8%,但Unseen类和HM略有下降。
- 能效方面,与AVMST相比,SNN能耗降低41.7%,总能耗降低15.6%。
- 实际意义:为AVZSL任务提供了一种在保持竞争力的同时,显著降低计算能耗的解决方案,有助于将该技术部署到资源受限的边缘设备。
- 主要局限性:在时序更复杂、视频更长的ActivityNet数据集上,模型表现出对已见类别过拟合的倾向,牺牲了在未见类别上的泛化能力,表明其时间建模策略的稳健性有待提升。此外,论文未提及开源计划,可复现性存疑。
🏗️ 模型架构
STEN的整体架构如图1所示。其处理流程可分为四个主要阶段:
- 特征提取阶段:使用预训练的SeLaVi模型作为音频(Aenc)和视觉(Venc)编码器的初始化,提取初始特征。同时,每种模态还有一个独立的脉冲时序特征提取(STFE)模块,用于从原始特征中直接提取时间动态信息。
- 跨模态时间-语义融合阶段:
- 每种模态(音频a、视觉v)的编码器输出C_m与STFE输出的时序特征S_m通过交叉注意力(CA) 融合,生成时间-语义联合表示 Fts_m。这步旨在将原始特征与捕捉到的时序动态进行初步结合。
- 核心时序建模阶段:
- STFE模块:内部包含多个SNN块。每个块由线性层、批归一化和可学习三元脉冲神经元(LTS) 构成。LTS将膜电位映射为{-α, 0, α}三元输出,相比传统二进制脉冲,信息表示更丰富。STFE不使用平均池化,而是保留所有时间步的特征为3D张量,以避免信息丢失。
- 时空融合模块(STFM):接收STFE输出的3D时序特征张量,通过时间局部注意力(沿时间轴滑动卷积核)和通道局部注意力(沿特征维度操作),联合建模时间上的局部运动模式和特征通道间的语义相关性,得到融合特征F_{i,j}。
- 增强时序Spikeformer(ETS):这是一个改进的脉冲自注意力模块。它首先对输入进行脉冲层和线性投影得到Q, K, V。然后用1D卷积层分别处理Q, K, V,以自适应整合相邻时间步的信息。之后调整计算顺序为先计算K和V的关系,再与Q交互,并用脉冲神经元替换Softmax,最终输出。
- 最终融合与投影阶段:将前两个阶段得到的Fts_a, Fts_v和ETS融合的音频-视觉时序特征S_av输入一个跨模态Transformer,生成最终的音视频联合表示Ots_av。最后,通过投影层和重构层将该表示映射到与文本特征对齐的语义空间。
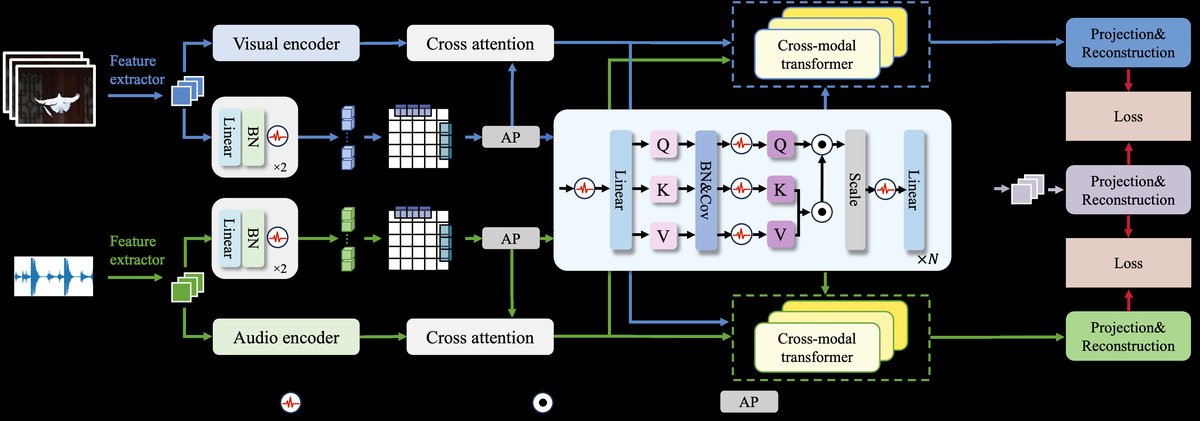 图1:STEN架构示意图。图中显示了特征提取、STFE、STFM(橙色模块)和ETS(蓝色模块)的流程,以及最终跨模态Transformer的整合。关键创新在于蓝色模块中ETS的计算顺序调整(先KV后Q)和STFM的联合时空建模。
图1:STEN架构示意图。图中显示了特征提取、STFE、STFM(橙色模块)和ETS(蓝色模块)的流程,以及最终跨模态Transformer的整合。关键创新在于蓝色模块中ETS的计算顺序调整(先KV后Q)和STFM的联合时空建模。
💡 核心创新点
可学习三元脉冲神经元(LTS)引入:
- 局限:传统整合发放(IF)神经元产生二进制脉冲,存在信息损失。
- 作用与收益:LTS根据膜电位产生三值输出,增强了网络的表示能力。消融实验表明,在UCF101上,用LTS替换IF神经元使调和平均(HM)从28.85提升至34.27,性能提升显著。
时空融合模块(STFM):
- 局限:简单平均池化或仅关注单维度注意力会损失时空耦合信息。
- 作用与收益:STFM通过两个局部注意力机制,联合建模时间维度上的局部动态和特征通道间的依赖关系。消融实验显示,移除STFM导致HM在UCF101上下降15.06%,证明其对性能至关重要。
增强时序Spikeformer(ETS):
- 局限:标准Spikeformer对相邻时间步信息的整合能力有限。
- 作用与收益:ETS通过前置的1D卷积层“预处理”Q、K、V,使其能感知邻域信息,并调整自注意力计算顺序。这使网络能动态捕捉微观的时序变化。消融实验中移除ETS会导致性能下降。
脉冲神经网络能效优化:
- 局限:SNN通常需要多个时间步来积累信息,带来计算开销。
- 作用与收益:通过上述模块设计和直接减少时间步长(从10步减至2步),STEN在保持或提升性能的同时,实现了SNN能耗降低41.7%,总能耗降低15.6%。
🔬 细节详述
- 训练数据:使用VGGSound、UCF101和ActivityNet三个标准音视频数据集,数据集划分遵循文献[4]。
- 损失函数:采用复合损失 L = Ls + Lp + Lr。
- Ls(三元组损失):包含模态内和跨模态的正负样本对,用于拉开异类距离、拉近同类距离。
- Lp(投影损失):直接最小化投影后的音视频嵌入与对应文本标签嵌入的距离。
- Lr(重构损失):最小化从音视频嵌入重构出的嵌入与原始文本嵌入的距离,以增强表示的鲁棒性。
- 训练策略:
- 优化器:论文未说明。
- 学习率/调度:论文未说明。
- Batch Size:论文未说明。
- 训练轮数:50 epochs。
- 关键超参数(按VGGSound/UCF101/ActivityNet顺序):
- 输入时间步长Tin: 512
- 隐藏层维度Thid: 512
- 投影维度Tproj: 64
- 最终维度Tfin: 300
- 编码器Dropout denc: 0.15 / 0.05 / 0.1
- 重构器Dropout drec: 0.15 / 0.2 / 0.05
- 投影层Dropout dwproj: 0.25 / 0.1 / 0.0
- 核心时间步长T:4 / 2 / 4(这是能效提升的关键)
- Transformer头数Transheads: 8
- Transformer层数Transdepth: 1 / 1 / 4
- 三元组损失边距γ=β: 1
- 训练硬件:单张NVIDIA RTX 3090 GPU。
- 推理细节:论文未提及解码策略、温度、beam size等,因本任务非生成任务。
- 正则化技巧:使用了Dropout(如上所列)和Batch Normalization。
📊 实验结果
主要性能对比如表1所示,关键消融实验如表2、表3所示,能效对比如表4所示。
表1:三大基准数据集性能对比
| 模型 | VGGSound-GZSL | UCF-GZSL | ActivityNet-GZSL | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | U | HM | ZSL | S | U | HM | ZSL | S | U | HM | ZSL | |
| AVMST[6] | 14.14 | 5.28 | 7.68 | 6.61 | 44.08 | 22.63 | 29.91 | 28.19 | 17.75 | 9.90 | 12.71 | 10.37 |
| MSTR[8] | 13.70 | 5.48 | 7.83 | 6.38 | 86.32 | 19.97 | 32.43 | 23.57 | 22.92 | 9.28 | 13.21 | 9.65 |
| STEN (ours) | 14.11 | 5.62 | 8.04 | 7.51 | 72.31 | 22.45 | 34.27 | 24.49 | 25.00 | 7.55 | 11.60 | 7.87 |
| 表1:STEN在VGGSound和UCF101的GZSL调和平均(HM)及ZSL指标上取得最优,在ActivityNet上Seen类(S)大幅提升,但Unseen类(U)和HM略有下降。 |
表2:脉冲神经元类型消融实验(UCF101-GZSL)
| 模型 | S | U | HM | ZSL |
|---|---|---|---|---|
| IF | 42.45 | 21.85 | 28.85 | 21.94 |
| LTS | 72.31 | 22.45 | 34.27 | 24.49 |
| 表2:使用可学习三元脉冲(LTS)相比传统IF神经元,所有指标均有大幅提升,证明了LTS的有效性。 |
表3:模块有效性消融实验(UCF101-GZSL)
| 模型 | S | U | HM | ZSL |
|---|---|---|---|---|
| W/o STFM | 55.44 | 19.73 | 29.11 | 20.24 |
| W/o ETS | 77.46 | 20.26 | 32.12 | 22.18 |
| W/o New SNN Line | 77.94 | 19.14 | 30.74 | 22.03 |
| STEN | 72.31 | 22.45 | 34.27 | 24.49 |
| 表3:移除任何一个核心模块(STFM、ETS或新SNN路径)都会导致性能(尤其是HM)下降。值得注意的是,移除ETS或新SNN路径后,Seen类(S)准确率反而更高,但Unseen类(U)和ZSL下降更多,表明这些模块更侧重于提升泛化能力而非简单拟合已知类别。 |
表4:能效对比
| 模型 | 时间步 (T) | 脉冲率 | 总能耗 (mJ) |
|---|---|---|---|
| AVMST [6] | 10 | 9.24% | 0.1427 |
| STEN (Ours) | 2 | 14.88% | 0.1205 |
| 表4:STEN通过将时间步从10��少到2,尽管脉冲率略有增加,但实现了SNN能耗降低41.7%,总能耗降低15.6%。 |
⚖️ 评分理由
- 学术质量(5.5/7):论文工作完整,提出了针对性模块并进行了有效验证,但创新深度有限(模块级改进),且存在实验结果不稳定(ActivityNet)和消融结果反常(W/o ETS时Seen类更高)未深入分析的问题。缺乏代码导致技术正确性和可复现性的验证打了折扣。
- 选题价值(1.5/2):将SNN与AVZSL结合以提升能效是一个有价值且符合当前趋势的方向,但音视频零样本学习本身应用面相对垂直。
- 开源与复现加成(0.0/1):论文中未提及任何代码、模型权重或详细训练脚本的开源信息,严重阻碍了复现和后续研究,因此加成分为0。