📄 Spike-Driven Low-Power Speech Bandwidth Extension
#语音增强 #脉冲神经网络 #低功耗 #流式处理
🔥 8.0/10 | 前25% | #语音增强 | #脉冲神经网络 | #低功耗 #流式处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Donghyun Kim (Department of Electronic Engineering, Hanyang University, Seoul, Republic of Korea)
- 通讯作者:Joon-Hyuk Chang† (Department of Electronic Engineering, Hanyang University, Seoul, Republic of Korea)
- 作者列表:Donghyun Kim (Hanyang University), Sangho Han (Hanyang University), Joon-Hyuk Chang (Hanyang University)
💡 毒舌点评
亮点:模型在效率上实现了质变,参数量仅为最强对比模型(AP-BWE)的约1/20,能耗降低了约93%,将语音带宽扩展任务拉入了“毫焦耳”时代。短板:在生成质量的“天花板”上并未超越现有最佳ANN模型,甚至在最重要的PESQ和ESTOI指标上落后约0.5分,表明SNN在捕获复杂生成任务的感知细节上可能仍有瓶颈。
🔗 开源详情
- 代码:论文提到“Demo is available at here”并隐含引用代码库(链接指向TUNet的GitHub仓库:https://github.com/NXTProduct/TUNet)。推测SpikeBWE的代码可能基于此仓库修改,但论文未明确提供独立的代码仓库链接。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用公开的TIMIT数据集,但论文未说明数据集的获取方式。
- Demo:论文摘要中提及提供在线Demo(“Demo is available at here”),但未提供具体URL。
- 复现材料:提供了部分训练细节(优化器、学习率、批量大���、训练轮数),但缺失关键信息如模型具体维度(卷积通道数、ESN隐藏单元数等)和训练硬件环境。
- 论文中引用的开源项目:
- TUNet:作为基线模型,其代码被直接引用(https://github.com/NXTProduct/TUNet)。
- auraloss v2.0.1:用于计算STFT损失。
- Adam optimizer:标准优化器。
📌 核心摘要
- 要解决什么问题:传统的基于深度学习的语音带宽扩展(BWE)方法在追求高质量的同时,模型复杂度(参数、计算量、能耗)不断增加,限制了其在功耗和资源受限的边缘设备上的实际部署。
- 方法核心是什么:提出了一种名为SpikeBWE的脉冲神经网络(SNN)框架。该框架将传统的ANN替换为事件驱动、计算稀疏的SNN,并采用基于脉冲卷积(SConv)的编码器和高效脉冲神经元(ESN,基于GSU)的瓶颈来建模长程依赖,同时采用子带损失和因果设计。
- 与已有方法相比新在哪里:这是首次将SNN成功应用于BWE任务,而非简单替换。其创新在于针对BWE任务特性设计的轻量级SNN架构(ESN、SConv)和训练策略(替代梯度、子带损失)。
- 主要实验结果如何:
- 在TIMIT数据集(8kHz -> 16kHz)上,SpikeBWE在多项指标上超越了早期基线(TUNet, SGMSE+M),并与最新SOTA模型(AP-BWE)在LSD(谱失真)指标上持平(均为1.37)。
- 其核心优势在于效率:参数量仅1.4M,计算量(MACs)为0.634G,估算能耗为0.848 mJ,功率代理指标(Pproxy)为0.942 GOps/s,均显著低于所有对比的ANN模型。
- 消融实验表明,ESN、SConv和子带损失的组合对降低LSD和能耗均有贡献,因果设计在仅轻微增加LSD的情况下保持了高效率。
关键数据表格:
方法 PESQ (↑) ESTOI (↑) LSD (↓) 参数量 (M) ↓ 计算量 (GMACs) ↓ 能耗 (mJ) ↓ TUNet 2.72 0.965 1.75 2.9 1.49 6.86 AP-BWE 3.83 0.994 1.37 29.8 2.99 13.8 SpikeBWE 3.30 0.985 1.37 1.4 0.634 0.848
- 实际意义是什么:为在智能手机、可穿戴设备、IoT终端等对功耗极其敏感的平台上实现实时语音增强和音质提升提供了可行的解决方案,推动了语音处理技术的“绿色化”和边缘化部署。
- 主要局限性是什么:生成语音的感知质量(PESQ, ESTOI)尚未达到最新ANN模型的最佳水平;研究主要基于标准TIMIT数据集,在噪声环境、不同说话人、不同语言等更复杂场景下的泛化能力有待进一步验证。
🏗️ 模型架构
SpikeBWE采用经典的U-Net编码器-解码器架构,但其内部所有组件均被改造为在脉冲域(Spike Domain)运行,以处理离散事件。
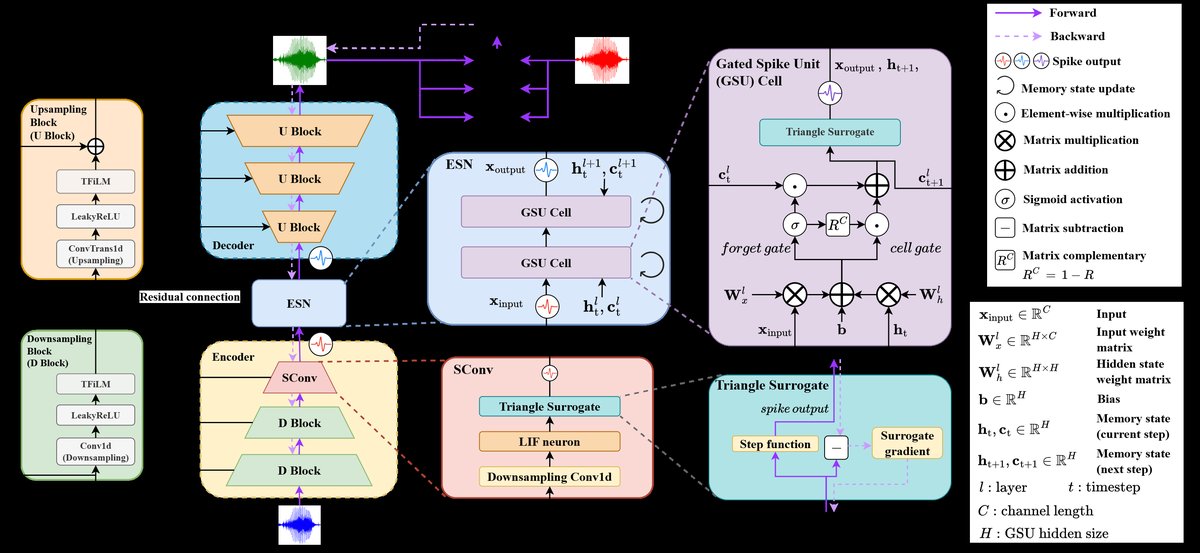 图1:SpikeBWE的网络架构示意图。展示了其U型结构,以及关键模块Spiking Convolutional (SConv) 和 Efficient Spiking Neuron (ESN) Block的位置。
图1:SpikeBWE的网络架构示意图。展示了其U型结构,以及关键模块Spiking Convolutional (SConv) 和 Efficient Spiking Neuron (ESN) Block的位置。
- 输入/输出:输入是8kHz采样的带限语音波形,输出是恢复的16kHz高分辨率语音波形。
- 编码器(Encoder):
- 由3个下采样块组成。每个块的核心是脉冲卷积(SConv)层,它取代了传统的卷积层。SConv层直接从输入波形的时间上下文中提取特征,并将其转化为稀疏的脉冲表示,这是整个网络进入事件驱动计算模式的关键起点。
- 每个下采样块通常包含SConv、激活(如LeakyReLU的脉冲对应物)和下采样操作。
- 瓶颈(Bottleneck):
- 这是架构最大的改动之处,用高效脉冲神经元(ESN)模块取代了原始TUNet中的Transformer。
- ESN模块由级联的两个门控脉冲单元(GSU)构成。GSU受传统RNN中GRU的启发,通过门控机制在脉冲网络内控制信息流,旨在高效捕获语音信号中的长时程依赖关系,这对于生成新的高频内容至关重要。
- 解码器(Decoder):
- 与编码器对称,由3个上采样块组成,通过转置脉冲卷积(或类似操作)进行上采样,并与编码器对应层的脉冲特征通过跳跃连接(Skip Connections) 相融合,以恢复细节。
- 损失函数模块:
- 输出波形与真实值通过三个损失函数共同优化:时域损失(Ltime)(均方误差)、多分辨率STFT损失(LSTFT) 和子带损失(Lsubband)。子带损失通过伪正交镜像滤波器(PQMF)将信号分解到子带进行STFT计算,旨在优化重建语音的感知质量和可懂度。
- 因果性设计:
- 所有卷积层和SNN层均通过非对称左侧填充实现因果卷积,确保模型在任何时间步t只依赖当前及过去的信息,使其适用于实时流式处理。
💡 核心创新点
首次将脉冲神经网络(SNN)应用于语音带宽扩展(BWE)任务:
- 局限性:传统ANN-BWE为追求质量,模型日益庞大复杂,能耗高。
- 创新与作用:利用SNN的事件驱动和稀疏计算特性,从根本上改变计算范式,旨在大幅降低能耗。
- 收益:实现了数量级(约8倍)的能耗降低,为低功耗部署开辟了新路径。
设计针对BWE任务的高效SNN架构(ESN与SConv):
- 局限性:简单将ANN模型转为脉冲版本可能无法发挥SNN优势,或效果不佳。
- 创新与作用:提出了ESN模块(基于GSU)来高效建模长程依赖,替代了计算密集的Transformer;使用SConv从源头进行脉冲特征提取。
- 收益:在保持模型极轻量(1.4M参数)的同时,实现了有竞争力的重建质量(LSD 1.37),效率远超基线。
融合子带损失与替代梯度学习的训练策略:
- 局限性:SNN因脉冲函数不可微分,训练困难;BWE任务需要关注频段特定质量。
- 创新与作用:采用替代梯度(Surrogate Gradient) 方法解决SNN的训练问题;引入子带损失(Subband Loss) 专注于优化各频带的重建质量。
- 收益:确保了深层SNN的稳定训练,并直接针对BWE任务的感知目标进行优化,有助于提升语音可懂度和频谱相似度(尤其体现在LSD-LF指标上)。
🔬 细节详述
- 训练数据:
- 数据集:TIMIT语音语料库。
- 规模:总时长约5.4小时,来自630名说话人,采样率16kHz。
- 预处理:使用切比雪夫I型低通滤波器将信号截断至4kHz并下采样至8kHz,作为模型输入。原始16kHz信号作为目标。
- 数据划分:4620个语句用于训练(90%训练,10%验证),1620个语句用于测试。
- 损失函数:
- 总损失(Ltotal):α Ltime + β LSTFT + Lsubband。
- 权重:α = 1×10⁴,β = 1。
- Ltime:波形均方误差(MSE)。
- LSTFT:多分辨率STFT损失,包含谱收敛损失和对数幅度损失。
- Lsubband:对经过PQMF分析滤波器(B=4)得到的子带信号计算多分辨率STFT损失。
- 训练策略:
- 优化器:Adam。
- 初始学习率:3 × 10⁻⁴。
- 学习率调度:采用基于验证损失平台期的调度策略。当验证损失连续三个epoch不再下降时,学习率减半。
- 批量大小:16。
- 训练轮数:100 epochs。
- 关键超参数:
- 模型参数量:1.4M。
- 计算量(MACs):0.634G。
- 训练硬件:论文中未说明具体的GPU/TPU型号和数量。
- 推理细节:
- 由于模型设计为全因果,特别适用于实时、低延迟的流式场景。
- 推理过程即前向传播,利用替代梯度方法仅在训练时使用,推理时直接使用Heaviside阶跃函数产生脉冲。
- 正则化或稳定训练技巧:使用了学习率平台期调度以防止过拟合和促进收敛。
📊 实验结果
论文在TIMIT数据集上进行了全面的对比实验和消融研究。
主要对比结果(Table 1):
| 方法 | 年份 | PESQ (↑) | ESTOI (↑) | LSD (↓) | LSD-HF (↓) | LSD-LF (↓) | 参数 (M) ↓ | MACs (G) ↓ | 能耗 (mJ) ↓ | Pproxy (GOps/s) ↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| TUNet | 2022 | 2.72 | 0.965 | 1.75 | 3.00 | 0.488 | 2.9 | 1.49 | 6.86 | 2.97 |
| SGMSE+M | 2023 | 3.17 | 0.982 | 2.13 | 3.69 | 0.565 | 64.8 | 47,984 | 220,726 | 95,968 |
| AERO | 2023 | 3.61 | 0.986 | 1.48 | 2.31 | 0.642 | 19.4 | 70.9 | 326 | 142 |
| AP-BWE | 2025 | 3.83 | 0.994 | 1.37 | 2.20 | 0.534 | 29.8 | 2.99 | 13.8 | 5.97 |
| SpikeBWE | 2026 | 3.30 | 0.985 | 1.37 | 2.47 | 0.267 | 1.4 | 0.634 | 0.848 | 0.942 |
| 结论:SpikeBWE在保持与最先进模型AP-BWE相当的LSD(1.37)的同时,在所有效率指标(参数、计算量、能耗)上实现了数量级的领先。其在LSD-LF(低频失真)上取得了最佳结果(0.267),但在感知质量指标PESQ和ESTOI上落后于AP-BWE约0.5分和0.009分。 |
消融实验结果(Table 2):
| 方法 | ESN | SConv | Subband | Causality | LSD (↓) | 能耗 (mJ) ↓ | Pproxy (GOps/s) ↓ |
|---|---|---|---|---|---|---|---|
| TUNet Baseline | 1.75 | 6.86 | 2.97 | ||||
| Variant - A | ✓ | 1.51 | 0.954 | 1.06 | |||
| Variant - B | ✓ | ✓ | 1.46 | 0.848 | 0.942 | ||
| Variant - C | ✓ | ✓ | ✓ | 1.39 | 0.902 | 1.00 | |
| SpikeBWE | ✓ | ✓ | ✓ | 1.37 | 0.848 | 0.942 | |
| Causal SpikeBWE | ✓ | ✓ | ✓ | ✓ | 1.44 | 0.850 | 0.944 |
| 结论:每个组件(ESN, SConv, Subband Loss)的加入都能逐步改善LSD。ESN替换Transformer是能耗降低的关键。SConv在进一步降低LSD的同时保持了最佳能耗。因果设计使LSD轻微上升至1.44,但几乎不影响能耗和功率,证明了其适用于实时应用。 |
⚖️ 评分理由
- 学术质量:6.0/7:本文提出了一个清晰的、有目的性的新框架(SpikeBWE),首次将SNN引入BWE。技术路线正确,通过精心的架构设计(ESN, SConv)和损失函数设计(Subband Loss)取得了显著的效率提升和有竞争力的质量。实验设计较为完整,包含对比实验和消融实验,数据可信。扣分点在于:1)生成质量的“天花板”未突破现有最佳ANN(AP-BWE);2)缺乏在更具挑战性的实际场景(如噪声、远讲)下的评估。
- 选题价值:1.5/2:选题精准切入语音处理模型的高能耗痛点,提出的低功耗BWE方案对移动设备、IoT等资源受限场景有明确的应用价值和市场需求。对于关注模型效率和边缘部署的语音AI从业者具有较高参考意义。
- 开源与复现加成:0.5/1:论文提供了代码仓库链接(指向TUNet官方代码库,暗示SpikeBWE代码可能在此基础上扩展)和在线Demo,这是加分项。但未提供训练好的SpikeBWE模型权重、详细的网络配置文件、训练日志或超参数搜索细节,复现所需信息不完全充分。