📄 Speech Emotion Recognition based on Hierarchical Transformer with Shifted Windows
#语音情感识别 #分层Transformer #预训练 #对比学习 #音频分类
🔥 8.0/10 | 前25% | #语音情感识别 | #分层Transformer | #预训练 #对比学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:张文浩 (Wenhao Zhang)(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院))
- 通讯作者:张鹏 (Peng Zhang)*(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院))
- 作者列表:张文浩(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院)),张鹏(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院)),赵伟(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院)),王富强(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院)),李烨(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院)),吴晓明(山东计算中心(国家超级计算济南中心)、齐鲁工业大学(山东省科学院))
💡 毒舌点评
这篇论文将图像领域的Swin Transformer思路迁移到语音情感识别,构建了一个从帧级到语句级的清晰分层建模框架,思路系统且有效。然而,其核心组件(如滑动窗口注意力)创新性相对有限,更像是对成熟技术的精巧组合与适配;此外,在MELD等数据集上对少数类(如“恐惧”和“厌恶”)的识别瓶颈并未得到根本解决,说明模型对数据不平衡的鲁棒性仍有提升空间。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:
https://github.com/AY549/HTSW-for-SER。 - 模型权重:论文中未提及是否公开模型权重。
- 数据集:使用了公开数据集(IEMOCAP, MELD, CASIA),但论文未涉及数据集的公开或分发工作。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文详细给出了模型的层数、窗口大小、学习率、优化器、训练轮数等关键训练细节和超参数,复现信息较为充分。
- 论文中引用的开源项目:主要依赖预训练模型WavLM(论文中引用了相关文献[13])。
📌 核心摘要
- 要解决的问题:传统基于全局自注意力机制的Transformer在语音情感识别中弱化了局部情感特征的表示能力,而语音信号丰富的时序动态对分层建模提出了挑战。
- 方法核心:提出一种基于移位窗口的分层Transformer模型(HTSW)。该模型首先使用预训练WavLM提取特征,然后通过三个阶段的移位窗口Transformer和块合并操作,实现从帧级到语句级的多尺度特征学习;最后在顶层使用全局注意力机制整合全局上下文信息,完成情感分类。
- 与已有方法相比新在哪里:相较于传统Transformer,该方法引入了层次化、多尺度的局部窗口注意力机制,能更有效地捕捉语音中不同时间粒度(音素、词、短语)的情感特征。其设计的滑动重叠窗口和块合并下采样策略,在保持计算效率的同时,促进了特征层级间的交互与融合。
- 主要实验结果:
- IEMOCAP (5-fold):WAR 73.3%, UAR 74.6%,优于表1中所有对比方法(如DST: 71.8%/73.6%)。
- MELD:WF1 48.2%,与最佳对比方法(ENT: 73.9% UAR)相当或略低,论文指出类别不平衡是主要挑战。
- CASIA (leave-one-speaker-out):WAR和UAR均为66.7%,显著优于表2中所有对比方法(如SpeechSwin-TF: 54.3%)。
- 消融实验 (Table 3):在IEMOCAP和MELD上,所提HTSW方法(WAR 73.3%/WF1 48.2%)显著优于固定窗口Transformer(69.4%/44.2%)和稀疏窗口注意力(70.1%/45.7%)。
- 实际意义:该工作为语音情感识别提供了一种高效且性能优越的建模框架,特别是在处理长语音序列时,其分层结构能有效降低计算复杂度,对实际应用(如客服情感分析、人机交互)具有参考价值。
- 主要局限性:模型在极端类别不平衡的数据集(如MELD)上,对少数类情感的识别能力仍然有限。所采用的窗口大小为固定值,缺乏自适应调整机制以更灵活地匹配不同情感动态。
🏗️ 模型架构
模型的整体输入是原始语音,输出是情感类别概率。
- 特征提取与编码:首先使用预训练的WavLM模型将原始语音转换为特征序列
x ∈ R^(T×D),并添加位置编码以注入时序信息。 - 分层特征提取(Stage 1-3):
- Stage 1-3 均由移位窗口Transformer(SW-Transformer) 和块合并(Patch Merging) 模块交替构成。
- 移位窗口Transformer:核心是滑动重叠窗口注意力(SWAttention) 模块。与标准全局自注意力不同,它在每个时间步
t处,以t为中心定义一个长度为i的局部窗口,仅对窗口内的Key进行注意力计算,从而高效地建模局部情感依赖。该模块包含多头自注意力(MHA)、残差连接、层归一化(LN)、Dropout和前馈网络(FFN)。 - 块合并:作用是对特征序列进行下采样。具体操作是:将输入序列在时间维度上分组并进行平均池化,然后通过线性层扩展特征通道数,最后进行层归一化。这实现了时间维度压缩和特征维度扩展,类似于图像中的池化操作。
- 三个阶段的窗口长度依次设为5、20、50,对应不同的特征聚合尺度,逐步从细粒度(帧级)建模过渡到粗粒度(短语级)建模。
- 全局上下文建模(Stage 4):使用标准的全局多头注意力(MHA) 机制。此时输入特征已经过下采样,序列长度较短,全局注意力可以高效地对前三个阶段提取的多尺度局部特征进行全局信息整合,捕捉长程语境。
- 分类:全局注意力输出的特征经过平均池化和层归一化后,送入一个三层MLP分类器,输出最终���情感概率预测。
💡 核心创新点
- 面向语音的分层窗口Transformer架构:将Swin Transformer的层次化设计成功适配到语音情感识别任务。通过三阶段的移位窗口操作,系统地构建了从微观(帧)到宏观(短语)的特征表示,解决了传统Transformer对局部情感特征建模不足的问题。
- 滑动重叠窗口注意力机制:针对语音的连续性,提出SWAttention。通过滑动计算和重叠窗口,确保了相邻时间窗口间信息的连续性和上下文的平滑性,增强了模型对关键情感片段的捕获能力。
- 高效的块合并下采样策略:借鉴Swin-T的Patch Merging,在Transformer层之间插入块合并操作。这不仅降低了后续层的计算复杂度,还通过通道扩展和特征融合,增强了不同层级特征之间的交互与语义抽象能力。
- 局部-全局注意力混合设计:前三个阶段专注于高效的局部特征提取,最后一个阶段切换到全局注意力进行信息整合。这种“先局部后全局”的设计,平衡了建模效率与全局上下文感知能力。
🔬 细节详述
- 训练数据:
- IEMOCAP:约12小时,5531条语音,4类情感。采用5折(留一session)和10折(留一speaker)交叉验证。
- MELD:13,708条语音,7类情感。使用官方划分的训练/验证/测试集。
- CASIA:1200条语音,6类情感,4位说话人。采用留一说话人交叉验证。
- 预处理:所有语音首先通过预训练的WavLM模型提取特征。
- 损失函数:交叉熵损失。
- 训练策略:
- 优化器:SGD。
- 学习率:初始学习率为0.0005。
- 调度:采用余弦预热(cosine warmup)和余弦退火(cosine annealing)。
- 批大小:32。
- 训练轮数:100个epoch。
- 训练硬件:NVIDIA GeForce RTX 3090 GPU。训练时长未说明。
- 关键超参数:
- 模型结构:4个Stage。Stage 1-3分别包含2、2、4个SW-Transformer层;Stage 4包含2个全局注意力层。
- 窗口长度:Stage 1-3分别为5、20、50。
- 块合并参数:Stage 1-3的特征聚合间隔分别为5、10、20帧;特征扩展因子分别为1、1、2。
- 推理细节:未明确说明,但分类器输出为概率预测,通常取最大概率类别。
📊 实验结果
论文提供了详细的对比实验和消融实验。
表1:IEMOCAP (5-fold) 和 MELD 数据集上的性能比较
| 方法 | IEMOCAP-5 WAR(%) | IEMOCAP-5 UAR(%) | MELD WF1(%) |
|---|---|---|---|
| Co-attention | 69.8 | 71.1 | 48.0 |
| Speechformer++ | 70.5 | 71.5 | 47.0 |
| DST | 71.8 | 73.6 | 48.8 |
| DWFormer | 72.3 | 73.9 | 48.5 |
| ENT | 72.4 | 73.9 | – |
| HTSW (ours) | 73.3 | 74.6 | 48.2 |
表2:IEMOCAP (10-fold) 和 CASIA 数据集上的性能比较
| 方法 | IEMOCAP-10 WAR(%) | IEMOCAP-10 UAR(%) | CASIA WAR(%) | CASIA UAR(%) |
|---|---|---|---|---|
| ATFNN | 73.8 | 64.5 | 48.8 | 48.8 |
| LGFA | 73.3 | 62.6 | 49.8 | 49.8 |
| TF-Transformer | 74.4 | 62.9 | 53.2 | 53.2 |
| SpeechSwin-TF | 75.2 | 65.9 | 54.3 | 54.3 |
| HTSW (ours) | 72.7 | 73.9 | 66.7 | 66.7 |
表3:不同窗口划分方法在 IEMOCAP (5-fold) 和 MELD 数据集上的比较
| 方法 | IEMOCAP-5 WAR(%) | IEMOCAP-5 UAR(%) | MELD WF1(%) |
|---|---|---|---|
| Fixed Window Transformer | 69.4 | 70.6 | 44.2 |
| Sparse Window Attention | 70.1 | 70.5 | 45.7 |
| HTSW (ours) | 73.3 | 74.6 | 48.2 |
关键结论:
- 在IEMOCAP (5-fold) 上,HTSW在WAR和UAR上均取得最佳结果,相比次优的DWFormer,UAR提升了0.7个百分点。
- 在CASIA数据集上,HTSW表现极为突出,WAR/UAR比次优的SpeechSwin-TF高出12.4个百分点,显示了该方法在小规模、干净数据集上的强大建模能力。
- 在IEMOCAP (10-fold) 上,HTSW的UAR远超其他方法(高出约8-11个百分点),说明其对类别不平衡数据的鲁棒性强,但WAR略低,表明整体准确率并非最优。
- 在MELD数据集上,HTSW的WF1与顶尖方法接近,但论文指出数据不平衡导致少数类识别差。
- 消融实验(表3)明确证明,所提的移位窗口策略(HTSW)显著优于固定窗口和稀疏窗口的基线方法。
实验图表:
- 混淆矩阵:论文提供了四个数据集的混淆矩阵图。
 结论:在IEMOCAP (5-fold) 和CASIA上,对“angry”和“sad”/“neutral”识别准确率高。MELD数据集上,少数类(如“fear”, “disgust”)识别率极低(<20%),证实了类别不平衡问题。
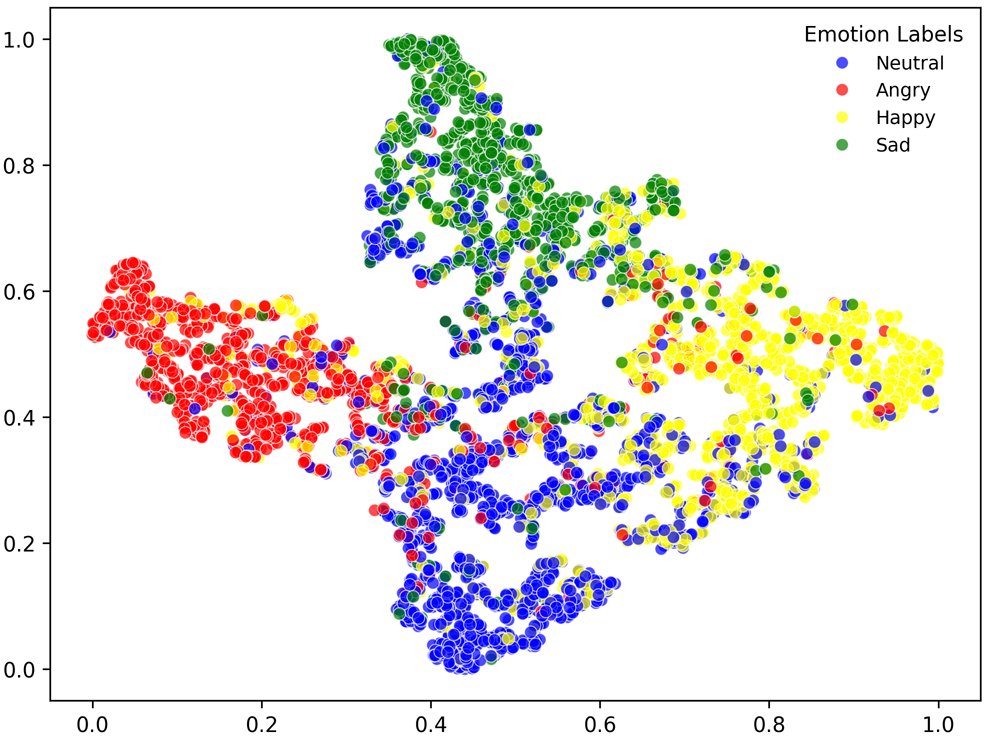
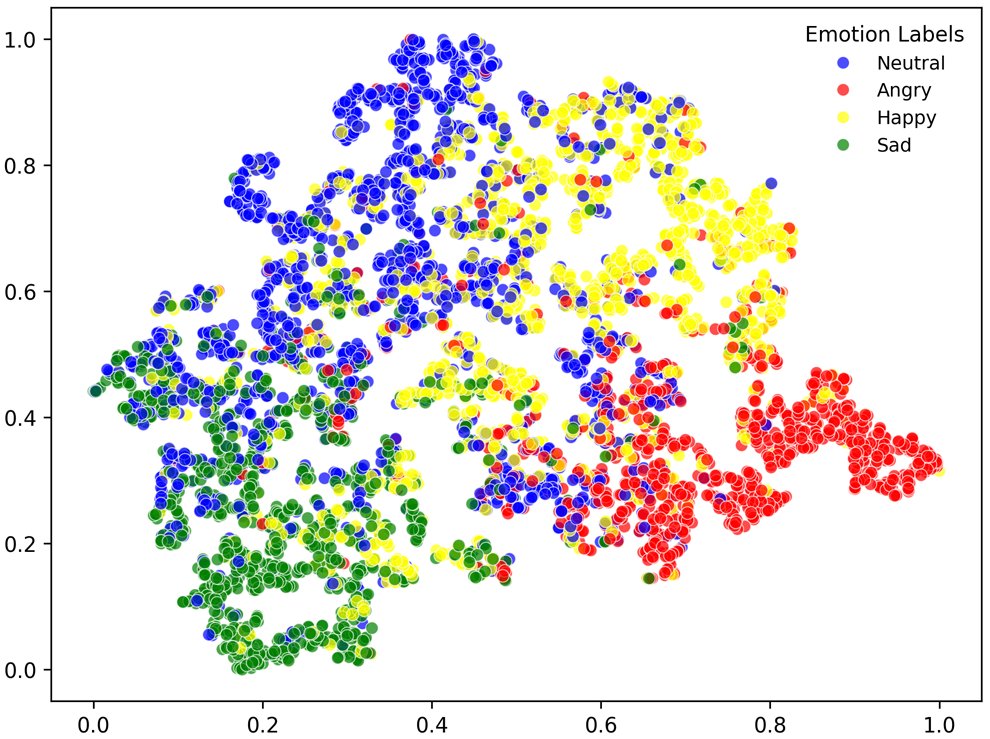
结论:在IEMOCAP (5-fold) 和CASIA上,对“angry”和“sad”/“neutral”识别准确率高。MELD数据集上,少数类(如“fear”, “disgust”)识别率极低(<20%),证实了类别不平衡问题。 - t-SNE可视化:论文在IEMOCAP数据集上对HTSW与Speechformer++、DST、DWFormer的特征进行了可视化对比。
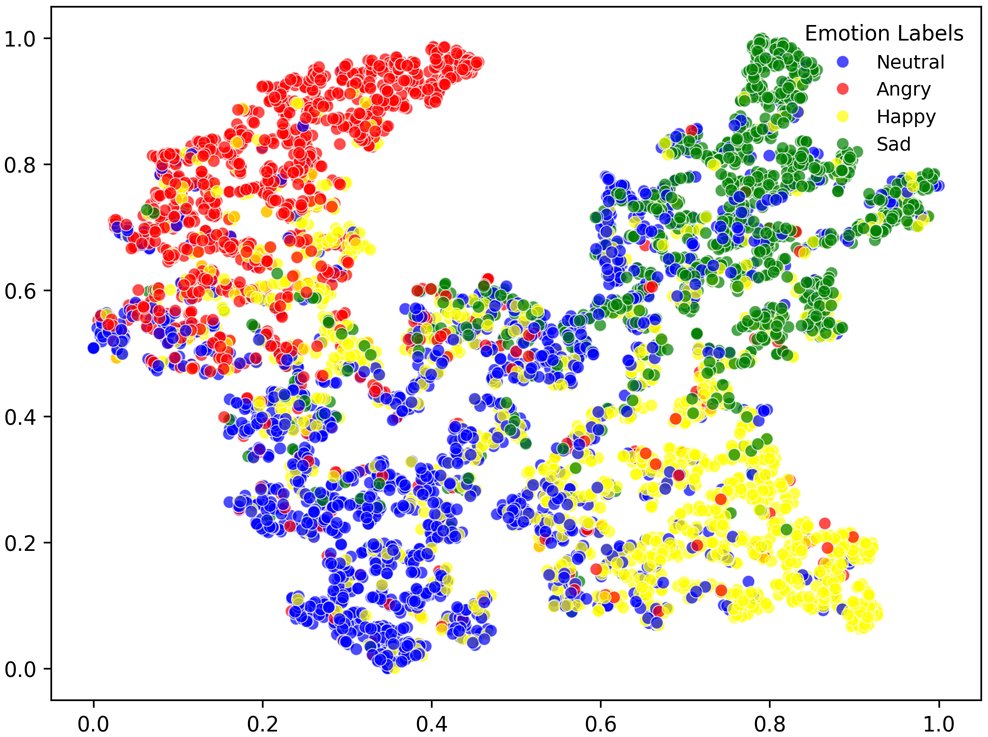 结论:HTSW(图d)生成的特征在同类中更紧凑,不同类之间分离度更清晰,直观地证明了其优越的特征判别能力。
结论:HTSW(图d)生成的特征在同类中更紧凑,不同类之间分离度更清晰,直观地证明了其优越的特征判别能力。
⚖️ 评分理由
- 学术质量:6.0/7。论文技术路线清晰,架构设计系统性强,将视觉领域的层次化Transformer成功迁移至语音情感识别,实验设计全面且结果显著。主要不足在于核心模块(如SWAttention)是对现有技术的组合与改进,原创性未达到最高水平;在MELD等复杂数据集上的性能未取得压倒性优势。
- 选题价值:1.5/2。语音情感识别是人机交互、情感计算领域的关键课题,持续具有研究价值。本文工作属于该领域内扎实的模型改进,对提升识别精度有实际帮助,但选题本身不涉及跨模态或生成式等更前沿的范式转变。
- 开源与复现加成:0.5/1。论文提供了公开的代码仓库链接,实验设置、超参数描述详尽,极大地方便了其他研究者复现和验证其工作,这是显著的加分项。但未提供预训练模型权重和详细的训练时间,因此未给满分。