📄 Spectrogram Event Based Feature Representation for Generalizable Automatic Music Transcription
#音乐信息检索 #时频分析 #跨乐器转录 #鲁棒性
✅ 7.5/10 | 前25% | #音乐信息检索 | #时频分析 | #跨乐器转录 #鲁棒性
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Penghao He(复旦大学计算机科学与人工智能学院)
- 通讯作者:Fan Xia(浙江音乐学院音乐工程系), Wei Li(复旦大学计算机科学与人工智能学院,上海智能信息处理重点实验室)
- 作者列表:Penghao He(复旦大学计算机科学与人工智能学院), Ganghui Ru(复旦大学计算机科学与人工智能学院), Mingjin Che(中央民族大学音乐学院), Fan Xia(浙江音乐学院音乐工程系), Wei Li(复旦大学计算机科学与人工智能学院,上海智能信息处理重点实验室)
💡 毒舌点评
亮点:该工作没有陷入“堆砌更大模型”或“设计更复杂损失函数”的窠臼,而是另辟蹊径,从信号处理层面重新思考“哪些信息是跨乐器通用的”,并将其提炼为“谱图事件”,这种第一性原理的思考方式值得肯定。短板:所提的“事件级数据增强”和“事件感知”模块数学描述略显复杂,但实验中似乎只用在了钢琴任务上,其在真正的跨乐器训练(而非仅跨乐器评估)中是否依然有效且高效,缺乏直接证据。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:论文中使用了公开数据集MAESTRO、MAPS、MusicNetEM、GuitarSet及一个民间乐器数据集(链接为
https://fd-lamt-dataset.github.io/fd-lamt-dataset),这些数据集均可获取。 - Demo:未提及在线演示。
- 复现材料:提供了部分训练硬件(RTX 4090/2080Ti)和时长信息,以及一些核心超参数。但未提供完整的配置文件、损失函数细节或训练日志。
- 引用的开源项目:提到了依赖的开源工具,如
mir eval(用于评估),以及基线模型HPPNet和Onsets and Frames。 - 总结:论文中未提及完整的开源计划。
📌 核心摘要
- 问题:当前基于深度学习的自动音乐转录(AMT)模型在训练数据分布之外(如不同钢琴音色、录音环境或未见过的乐器)表现严重下降,泛化能力不足。
- 方法核心:提出了一种基于谱图事件的特征表示方法(SEFR)。该方法首先定义了四个反映声音产生时谱图关键强度变化的“先验事件”(时域增强/减弱,频域局部峰值),并提取其分数。然后通过事件级数据增强、事件感知(选择最显著事件)、模糊表示(降低频率分辨率以鲁棒应对峰值偏移)和注意力融合,生成一个去除了乐器特异性纹理、专注于音高预测通用信息的特征图。
- 与已有方法相比新在哪里:不同于以往主要通过数据增强或设计特定于乐器的模型架构来提升泛化性,本文方法从特征表示源头入手,旨在提取跨乐器的、反映音高本质的谱图变化模式。该特征提取模块是即插即用的,可适配不同的下游转录网络。
- 主要实验结果:
钢琴转录泛化:在未使用MAPS数据集训练的情况下,SEFR在MAPS测试集上达到了Note F1 89.08%,Frame F1 87.41%,Note w/Offset F1 66.99%,优于包括HPPNet-sp在内的所有对比方法。结合数据增强和额外数据的SEFR版本在所有指标上取得SOTA(Note F1 90.54%, Frame F1 89.10%)。
- 跨乐器泛化:在GuitarSet(吉他)及三种民间乐器(dutar, satar, tanbur)的零样本评估中,SEFR在所有乐器的所有指标上均优于基线模型(Onsets & Frames),且性能提升显著。例如,在tanbur上,Note F1从55.4%提升至65.2%,Note w/Offset F1从38.4%提升至44.8%。
- 实际意义:为解决AMT模型在现实世界中因数据分布不同(如不同录音棚、不同演奏家的钢琴,或完全未见过的乐器)导致的性能衰减问题提供了有效的技术方案,有望推动AMT技术在低资源乐器和真实场景中的应用。
- 主要局限性:方法引入了多个模块(事件分数计算、感知、模糊表示),增加了特征提取阶段的复杂性和计算量。虽然论文声称方法模块化且可适配,但在跨乐器实验中仅与一个较简单的基线(O&F)对比,未验证其与当前最强钢琴转录模型(如SemiCRFV2)结合的效果。此外,损失函数等训练细节未在论文中充分说明。
🏗️ 模型架构
论文提出了名为Spectrogram Event Based Feature Representation (SEFR) 的特征提取模块,其整体结构如图1(a)所示。
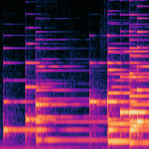
完整输入输出流程:
- 输入:常数Q变换(CQT)谱图,每半音4个频率bin。
- SEFR处理:经过一系列模块,输出一个“基于事件的特征图”(Event-based Feature Map)。
- 下游任务:该特征图可作为各种后续转录网络的输入,例如论文实验中使用的HPPNet-sp或Onsets & Frames。
主要组件与数据流:
- 事件分数提取 (Event Score Extraction):对CQT输入进行最小-最大归一化,然后沿时间轴和频率轴分别计算四个预定义事件的分数(
scorea,scoreb,scorec,scored),这些分数反映了局部强度变化的显著性。同时,应用两个指数(Aexp, Bexp)生成变换后的谱图xa和xb,以突出谱图模式。 - 事件级数据增强 (Event-Level Data Augmentation, ELDA):作用于归一化后的CQT输入。它将谱图视为时间和频率方向上的一系列值,并根据每个点与其邻居的大小关系(最大值、最小值、中值),在其取值范围内添加随机扰动(公式5,6),然后对奇偶点分别增强后加权融合。此操作在图1(b)中示意,旨在在保留事件结构的前提下增加输入多样性。
- 时间特征提取 (T-Feature Extraction):使用一维卷积网络(T-Conv)沿时间轴分别处理
xa和xb得到时间特征,同时两个频率事件共享一个卷积网络。 - 事件感知 (Event Perception):在频率轴上,对每个位置
f,在一个局部邻域(如上下各2个bin)内,通过一个基于伯努利分布的随机掩码选择若干邻居,从这些邻居的事件分数中选出最大值作为该位置的“显著事件”,生成“显著事件图”。图1(c)和图1(d) 可视化了分数图和感知选择过程。此步骤旨在聚焦于局部最强的通用响应,抑制乐器特异性细节。 - 模糊表示 (Fuzzy Representation):将频率分辨率减半。在8个bin的组内,将其随机分成4个部分,每个部分内的bin值进行随机加权求和。图1(e) 展示了这一过程。这相当于在频率轴上引入了随机的“展宽”或“收缩”,使模型对音高峰值的精确位置不敏感,提升鲁棒性。
- 注意力融合 (Attention Fusion Among Events):用2D卷积处理各事件特征图后,在它们之间计算注意力权重,进行加权融合,生成最终的事件特征图。图1(a) 右上部分展示了此结构。
关键设计选择:
- 动机:所有设计均围绕“保留音高相关信息,抑制乐器音色和录音环境干扰”这一目标。事件分数量化了最通用的变化;事件感知和模糊表示通过局部选择和随机融合来对抗分布偏移。
- 模块化:各模块(增强、感知、模糊表示、融合)独立且可替换,便于适配不同下游任务。
💡 核心创新点
- 定义并利用“谱图事件”作为通用特征基石:创新性地提出四个反映声音时频能量变化的“先验事件”,并计算其分数。这超越了直接使用原始谱图值,旨在提取跨乐器的、反映音高本质的动态模式。
- 事件级数据增强 (ELDA):提出一种新型的、基于局部序列数值关系的增强方法。它不是对谱图进行全局的、与事件无关的变换(如随机裁剪、频率遮罩),而是专门针对已定义的事件进行扰动,从而在增强多样性的同时,保留了对转录至关重要的事件结构。
- 事件感知与选择机制:设计了一个在频率轴上选择局部最显著事件的过程(公式7)。这不同于常规的池化或卷积,它直接基于预先计算的分数进行最大值选择,有目的地丢弃邻近的、可能属于“旁瓣”或“音色相关”的弱响应,实现特征的稀疏化和通用化。
- 模糊表示以提升鲁棒性:针对CQT谱图中音高峰值位置可能因音色和录音条件而偏移的问题,提出了通过随机分组加权求和来降低频率分辨率的“模糊化”策略。这是一种不同于平均池化的、具有随机性的降维方法,旨在模拟峰值位置的不确定性。
- 通用可适配的特征提取模块:SEFR被设计为一个独立的前端,其输出的特征图可以直接馈送入不同的下游转录网络(如HPPNet-sp, Onsets & Frames),实验验证了其在不同骨干网络上的有效性。
🔬 细节详述
- 训练数据:
钢琴转录实验:主要使用MAESTRO(v3) 数据集的训练集。增强版SEFR额外使用了MusicNetEM数据集中的钢琴录音。
- 跨乐器实验:使用MusicNetEM数据集(包含多种古典乐器)训练Onsets & Frames基线及SEFR变体。
- 测试集:MAPS(钢琴,OOD测试),GuitarSet(吉他,OOD),以及三种民间乐器数据集(dutar, satar, tanbur,OOD)。 数据增强:SEFR使用了[3]中提出的数据增强策略(可能包括音高偏移、均衡器、噪声、混响)。
- 损失函数:论文中未明确说明损失函数的具体形式,只提及训练框架与HPPNet-sp和Onsets & Frames一致。通常这类模型使用二元交叉熵损失。
- 训练策略:
- 优化器/学习率等:未明确说明,但提到与HPPNet-sp保持一致。
- 训练时长/硬件:钢琴实验:在单张RTX 4090 GPU上训练约4天。跨乐器实验:在单张RTX 2080Ti GPU上训练约1天,batch size为8,切片长度10秒,共100,000步。
- 关键超参数:
- 事件分数提取:指数
Aexp=2.8,Bexp=2.8(onset分支);Aexp=1.5,Bexp=1.0(frame和offset分支)。 - 事件级增强:扰动幅度
β=0.28。 - 事件感知:感知范围为自身及上下各2个bin;感知概率
p从近到远为[0.9, 0.3, 0.1]。 - 模型大小:SEFR模块参数为1.8M,相比HPPNet-sp(1.2M)略有增加。
- 事件分数提取:指数
- 训练硬件:如上所述。
- 推理细节:未说明特殊解码策略。
- 正则化技巧:未说明,但ELU激活函数被用于所有卷积层。
📊 实验结果
主要基准与指标:
- 钢琴转录泛化(MAPS测试集):主要对比指标为Note F1(%)、Frame F1(%)、Note w/Offset F1(%)。结果如表1所示。
| 方法 | 参数量 | Note P(%) | Note R(%) | Note F1(%) | Frame F1(%) | Note w/Offset F1(%) |
|---|---|---|---|---|---|---|
| TAPS(µG) | 26M | 85.50 | 78.50 | 81.70 | 81.90 | - |
| SemiCRFV2 | 12.9M | 84.31 | 88.10 | 86.10 | 85.08 | 64.61 |
| PARcompact | 2.7M | - | - | 82.00 | - | 60.30 |
| HPPNet-sp | 1.2M | 88.23 | 86.68 | 87.41 | 84.14 | 60.70 |
| SEFR (proposed) | 1.8M | 91.19 | 87.14 | 89.08 | 87.41 | 66.99 |
| Maman et al.* | - | 88.20 | 86.50 | 87.30 | 79.60 | - |
| YMT3+* | - | - | - | 88.73 | - | - |
| hFT* | 5.5M | 86.72 | 83.81 | 85.14 | 82.89 | 66.34 |
| SemiCRFV2* | 12.9M | 92.11 | 88.78 | 90.38 | 89.00 | 69.75 |
| HPPNet-sp* | 1.2M | 90.24 | 87.62 | 88.87 | 86.91 | 65.92 |
| SEFR* (proposed) | 1.8M | 92.67 | 88.61 | 90.54 | 89.10 | 70.42 |
结论:在无额外数据增强和外部数据时,SEFR在所有指标上均超越所有对比方法。使用额外数据增强和数据的SEFR*取得了SOTA性能。
- 跨乐器泛化:评估指标同上,测试集为未在训练中见过的乐器。结果如表2所示。
| 乐器 | 基线(O&F) | 数据增强 | SEFR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| N(%) | F(%) | O(%) | N(%) | F(%) | O(%) | N(%) | F(%) | O(%) | |
| guitar | 62.2 | 58.6 | 23.9 | 61.2 | 56.4 | 22.6 | 65.0 | 62.7 | 29.8 |
| dutar | 51.3 | 50.7 | 32.3 | 54.5 | 55.6 | 34.6 | 54.3 | 53.0 | 35.3 |
| satar | 46.0 | 48.1 | 29.7 | 46.0 | 46.3 | 29.0 | 53.6 | 58.0 | 37.5 |
| tanbur | 55.4 | 49.5 | 38.4 | 59.9 | 53.2 | 42.3 | 65.2 | 58.8 | 44.8 |
结论:SEFR在所有乐器上均显著优于基线和数据增强方法,证明了其跨乐器泛化能力。传统数据增强在跨乐器任务上可能无效甚至有害(如guitar, satar上的N(%)下降)。
- 消融研究:在钢琴转录任务上,逐一移除SEFR各组件进行实验,结果如表3所示。
| 模型变体 | Note P(%) | Note R(%) | Note F1(%) | Frame F1(%) | Note w/Offset F1(%) |
|---|---|---|---|---|---|
| w/o Event Perception | 89.96 | 86.60 | 88.20 | 86.20 | 64.90 |
| w/o Fuzzy Representation | 90.27 | 86.41 | 88.28 | 86.16 | 65.26 |
| w/o ELDA-T | 90.00 | 87.14 | 88.50 | 87.43 | 66.53 |
| w/o ELDA-F | 90.49 | 87.30 | 88.82 | 87.09 | 66.31 |
| w/o ELDA-TF | 89.52 | 86.85 | 88.13 | 87.16 | 66.05 |
| SEFR (All) | 91.19 | 87.14 | 89.08 | 87.41 | 66.99 |
结论:完整SEFR性能最优。移除任何组件都会导致至少一个关键指标下降,但不同指标对不同组件的敏感度不同,体现了模块化设计的灵活性。
⚖️ 评分理由
- 学术质量:6.5/7:论文创新点明确,从“谱图事件”这一新颖角度解决AMT的泛化问题,技术路线清晰且自洽。实验设计全面,不仅在标准OOD数据集(MAPS)上验证,还进行了更具挑战性的跨乐器零样本评估,结果显著且可信。消融实验支撑了每个模块的必要性。扣分点在于:1)部分训练细节(损失函数)缺失;2)跨乐器实验的基线选择相对较弱(O&F),未与当前最强通用转录模型对比。
- 选题价值:1.0/2:研究方向(提升AMT模型泛化性)是领域内公认的重要问题,具有明确的实际应用需求(如音乐信息检索、教育软件、低资源乐器研究)。论文提出的解决方案具有一定的通用性和启发性。选题本身虽非最前沿的大语言模型或生成模型方向,但在其垂直领域内价值显著。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重或训练脚本。虽然文中给出了部分关键超参数和硬件信息,但不足以让同行完全复现其结果。缺乏开源贡献限制了该工作的影响力和实用性。